 网络查重实践
网络查重实践




 本文介绍了一个简单的网络查重功能实现过程,包括使用Selenium和BeautifulSoup进行网页爬取、处理不同网页结构和编码问题,以及利用余弦相似度进行文本比对。
本文介绍了一个简单的网络查重功能实现过程,包括使用Selenium和BeautifulSoup进行网页爬取、处理不同网页结构和编码问题,以及利用余弦相似度进行文本比对。
最近做项目有一个小功能是对用户上传的文章进行简单的网络查重。就是搜索特定主题,用这个关键词去在网上搜索文章再爬取。其中也借鉴了其他大佬的代码和文章,文章中会贴出。自己记录以下,以免日后遗忘。主要分为以下部分:
目录
chrome驱动安装
要实现自动搜索关键词需要安装chrome或firefox驱动,这里我安装的是chrome驱动,主要参考了这篇文章:chrome驱动安装。这篇文章当中安装地址啥的写的很详细,我就再记录几个需要注意的点:
- 驱动版本要和自己电脑上的谷歌版本要对应,大版本一定要相同,小版本可以不同
- 要将chromedriver.exe放到和当前环境相同的地址下(和python.exe一个路径)
保存特定主题下搜索出来文章的url
这部分代码参考:自动化测试
上述文章讲了一个比较完整的python网络爬虫过程,但是我没跑起来,就只借鉴了自动化测试部分的代码
例如我要搜索爱国主题下的演讲稿
from selenium import webdriver
from bs4 import BeautifulSoup
import time
url='https://www.baidu.com'
driver=webdriver.Chrome()
driver.get(url)
input=driver.find_element_by_id('kw')
input.send_keys('关于爱国的演讲稿')
search_btn=driver.find_element_by_id('su')
search_btn.click()
time.sleep(2)#在此等待 使浏览器解析并渲染到浏览器
html=driver.page_source
soup = BeautifulSoup(html, "html.parser")
search_res_list=soup.select('.t')
real_url_list=[]
# print(search_res_list)
for el in search_res_list:
js = 'window.open("'+el.a['href']+'")'
driver.execute_script(js)
handle_this=driver.current_window_handle#获取当前句柄
handle_all=driver.window_handles#获取所有句柄
handle_exchange=None#要切换的句柄
for handle in handle_all:#不匹配为新句柄
if handle != handle_this:#不等于当前句柄就交换
handle_exchange = handle
driver.switch_to.window(handle_exchange)#切换
real_url=driver.current_url
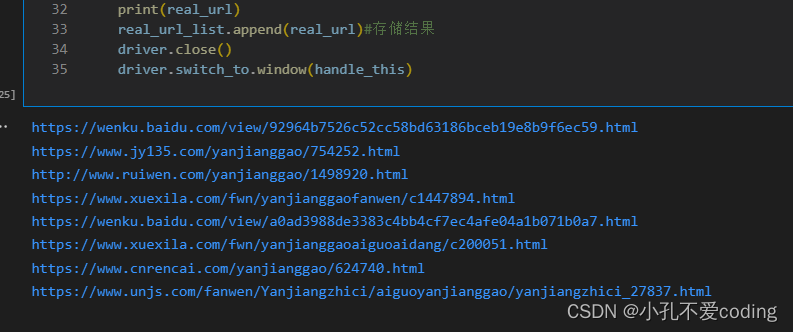
print(real_url)
real_url_list.append(real_url)#存储结果
driver.close()
driver.switch_to.window(handle_this)
最终返回结果是一个url列表
根据URL进行网络爬虫爬取文章保存为txt
我们获取了url后,就要对这些url进行爬取
from urllib import response
import requests
from bs4 import BeautifulSoup
import datetime
import chardet #字符集检测
import urllib
from urllib.request import urlopen
# 根据url获取内容
def get_content(url_list):
from urllib import response
import requests
from bs4 import BeautifulSoup
import chardet #字符集检测
from urllib.request import urlopen
import re
# 存储爬取的文本内容
content_list = []
for i in range(len(url_list)):
try:
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
url = url_list[i]
response = requests.get(url, headers=header)
# 判断网页编码格式
content = urlopen(url).read()
result = chardet.detect(content)
response.encoding = result['encoding']
print(response.status_code)
html = response.text
soup = BeautifulSoup(html,'lxml')
data = soup.find_all('p')
# 临时存储单个结构
temp_list = []
for x in data:
if len(x.text) == 0:
continue
text = x.text
# print(text)
temp_list.append(text)
pass
content_list.append(temp_list)
except:
# 跳过该url的操作
continue
# 将列表展开
flat_list = [item for sublist in content_list for item in sublist]
# 转换为字符串
str_content = ''.join(flat_list)
# 剔除Unicode分隔符空格符等
s = re.sub(r'[\u2002\u3000\n\xa0]+', '', str_content)
return s
封装成了一个函数,需要传入的参为url列表。写入方式为追加写,所有url的爬取内容均放在一个文件当中
爬取时遇到的问题及解决方案
不同网页的网页结构不一致问题
刚开始自己只打开了一个网页结构进行查看并编码,但是在输入其他url时就会报错,找不到这个标签之类的,后来发现所有网页的文字段都在<p></p>标签内,所以在解析网页时仅仅
soup.find_all('p')
就可以爬取文字了。
不同网页的编码格式不一致问题
在找到p标签爬取之后发现有不少乱码,肯定是编码格式的问题,所以我就查看了几个网页的编码格式,确实不一样
import chardet
import urllib
from urllib.request import urlopen
def automatic_detect(url):
content=urlopen(url).read()
result=chardet.detect(content)
encoding=result['encoding']
return encoding
for url in url_list:
print(automatic_detect(url))
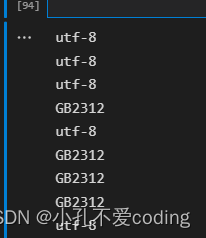
可以看到编码格式有utf8和GB2312,所以在上面的代码中可以看到多了两行置顶编码格式的代码
content = urlopen(url).read()
result = chardet.detect(content)
response.encoding = result['encoding']
添加之后,爬取的汉字中文均正常,没有乱码问题
txt文本分割
若是保存了一个大的文件。我想把它再分成几个小文件,查重的时候分别匹配查重
这部分代码主要参考python文本分割,自己做了一点微调方便函数的调用
def split_By_size(filename,size=4000):
txt_list = []
with open(filename,'r', encoding='utf8') as fin:
buf = fin.read(size)
sub = 1
while len(buf)>0:
[des_filename, extname] = os.path.splitext(filename)
new_filename = des_filename + '_' + str(sub) + extname
print( '正在生成子文件: %s' %new_filename)
txt_list.append(new_filename)
with open(new_filename,'w', encoding='utf8') as fout:
fout.write(buf)
sub = sub + 1
buf = fin.read(size)
print("ok")
return txt_list
传入的参数是文件名或路径,和分割单个文件的大小。最终返回的是一个小文件名字的列表
字符串分割
2023年1月6日修改。我把爬取的内容都放在了一个列表,按照列表的切片操作再进行分割
# content为爬取的内容
# text为之后要查重的文本
length = len(content)
# 存储分割后的结果
split_list = []
start = 0
while start < len(text):
split_list.append(text[start:start+length])
start += length
余弦相似度查重
爬取了文章那就可以开始匹配查重了
这一部分没有自己的修改,是借鉴了某个大佬的代码,👉python余弦相似度
import jieba
import math
import re
#读入两个txt文件存入s1,s2字符串中
# s1 = open('../文本分析/text/2020.txt','r').read()
# s2 = open('../文本分析/text/2021.txt','r').read()
s1 = open('荷塘月色.txt','r').read()
s2 = open('背影.txt','r').read()
#利用jieba分词与停用词表,将词分好并保存到向量中
stopwords=[]
fstop=open('stopwords.txt','r',encoding='utf-8-sig')
for eachWord in fstop:
eachWord = re.sub("\n", "", eachWord)
stopwords.append(eachWord)
fstop.close()
s1_cut = [i for i in jieba.cut(s1, cut_all=True) if (i not in stopwords) and i!='']
s2_cut = [i for i in jieba.cut(s2, cut_all=True) if (i not in stopwords) and i!='']
word_set = set(s1_cut).union(set(s2_cut))
#用字典保存两篇文章中出现的所有词并编上号
word_dict = dict()
i = 0
for word in word_set:
word_dict[word] = i
i += 1
#根据词袋模型统计词在每篇文档中出现的次数,形成向量
s1_cut_code = [0]*len(word_dict)
for word in s1_cut:
s1_cut_code[word_dict[word]]+=1
s2_cut_code = [0]*len(word_dict)
for word in s2_cut:
s2_cut_code[word_dict[word]]+=1
# 计算余弦相似度
sum = 0
sq1 = 0
sq2 = 0
for i in range(len(s1_cut_code)):
sum += s1_cut_code[i] * s2_cut_code[i]
sq1 += pow(s1_cut_code[i], 2)
sq2 += pow(s2_cut_code[i], 2)
try:
result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 3)
except ZeroDivisionError:
result = 0.0
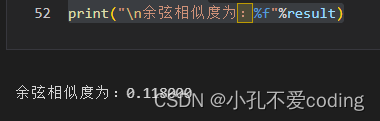
print("\n余弦相似度为:%f"%result)
自己记录一下,若能给其他人带来帮助就更好咯~
我的邮箱:k1933211129@163.com,CSDN私信很少看,欢迎各位大佬不吝赐教~

















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









