






爬虫的基本原理
1.1爬虫的基本原理
1、什么是爬虫
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本
2、爬虫分类
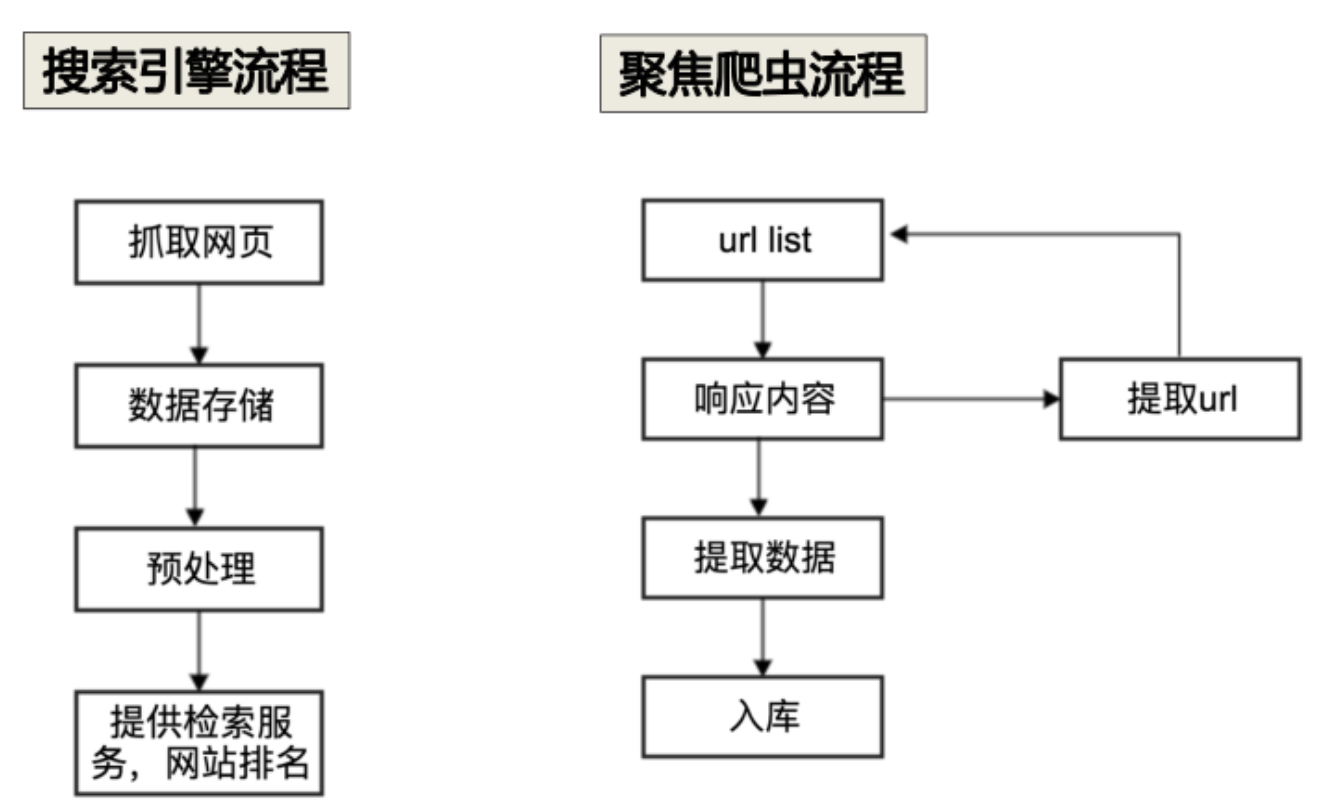
通用爬虫:通常指定搜索引擎的爬虫
聚焦爬虫:针对特定网站的爬虫
3、爬虫的工作流程
访问网页、获取信息的流程
发送请求——获取响应内容——解析相应内容——保存数据
4、Robots协议:
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,那些页面不能抓取
1.1爬虫的基本原理
1、什么是爬虫
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本
2、爬虫分类
通用爬虫:通常指定搜索引擎的爬虫
聚焦爬虫:针对特定网站的爬虫
3、爬虫的工作流程
访问网页、获取信息的流程
发送请求——获取响应内容——解析相应内容——保存数据
4、Robots协议:
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,那些页面不能抓取
 2820
2820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























