









对于那些具有相同元素或零元素在矩阵中分布具有一定规律的矩阵,被称之为特殊矩阵。对于那些零元素数据远远多于非零元素数目,并且非零元素的分布没有规律的矩阵称之为稀疏矩阵。
1、存储格式
稀疏矩阵,由于矩阵中大部分的值都是0,存储这些0值数据会耗费大量的存储空间,并且计算时也需要浪费大量的时间。
为了提升稀疏矩阵的运算效率,这里有几个稀疏矩阵存储格式。
COO(Coordinate,坐标的形式)
sparse.coo_matrix((data, (row, col)), shape=shape)COO格式是将矩阵中的非零元素以坐标的方式存储。例如下面的矩阵:

COO格式即将非零元素的行,列,值三个元素记录下来形成下面的表格。

因此可以用两个长为nnz(非零元素的个数)整数数组分别表示行列指标,用一个实数数组表示矩阵元。
CSR(Compressed Sparse Row,以行压缩的形式存储)
对于COO格式的一种改进就是CSR格式,这种格式要求矩阵元按行顺序存储,每一行中的元素可以乱序存储。那么对于每一行,就不需要记录所有元素的行指标。只需要用一个指针表示每一行元素的起始位置即可。依然以上面的矩阵为例,如下图所示。
rowptr 0 2 3 5 6 8
col__ 1 4 3 0 4 3 1 4
value_ 1 1 3 4 -1 7 2 10可以这么理解,rowptr是按行存储的,所以指针指向的就是每一行非零元素第一个节点的位置,比如这里第一个是0,对应的就是value = 1这就是第一行,第二个是2,对应的是value = 3这就是第二行的。
实际上CSR格式仅仅把矩阵元的行指标进行压缩,存储效率高于COO。
那就会有人问,如果存在全是0的一行,那该怎么表示:
例如,假设要表示一个5x5的稀疏矩阵,其中第2行全是0,那么在CSR表示中,相关数组的示例如下:
value = [a, b, c, d, e, f, g, h]
row_ptr = [0, 3, 3, 7, 8, 8]
col_index = [0, 1, 2, 0, 1, 2, 3, 4]其中,value数组中的元素为非零元素的值,row_ptr数组以及col_ind数组描述了矩阵中非零元素的位置信息。在这个示例中,第2行全是0,在value数组中没有相应的元素,而row_ptr数组体现了该行的存在,并且col_ind数组中对应的元素可以为空。
CSC(Compressed Sparse Column,以列压缩的形式存储)
这种格式和CSR相同,只是矩阵元按列压缩存储。
BCSR(Block CSR)

上图是BCSR的示例
BCSR是最流行的块稀疏矩阵格式之一。在BCSR中,所有的块都有相同的大小。为了理解这种格式,想象一个块大小为1的稀疏矩阵。在这种情况下,CSR和BCSR矩阵表示是等效的。块大小的增加不会影响列指针数组和行指针数组。相反,它只是扩展了values数组。也就是说,列和行指针数组包含块的值。块连续地存储在值数组中,极大地降低了内存空间需求。
CSR5(极致负载均衡的方案)
出自“CSR5:An Efficient Storage Format for Cross-Platform Sparse Matrix-Vector Multiplication”
为了避免格式转换的开销,一些算法集中于使用行块方法或分段求和方法来加速基于csr的SpMV。然而,这两种方法都有各自的缺点。对于行块方法,尽管它们对规则矩阵有很好的性能,但由于不可避免的负载不平衡,它们对不规则矩阵的性能可能很低。相比之下,分段求和方法可以实现近乎完美的负载平衡,但由于更多的全局同步和全局内存访问,开销很高。此外,上述工作都不能避免预处理的开销.CSR5格式使CSR格式的三个数组中的一个保持不变,将另外两个数组以原位排列的顺序存储,并添加两组额外的辅助信息。从CSR到CSR5的格式转换只需要两个调优参数:一个与硬件相关,另一个与稀疏性相关(但与结构无关)。由于添加的两组信息通常比CSR格式中的原始三组信息短得多,因此需要的额外空间非常有限。此外,CSR5格式是SIMD友好的,因此可以很容易地在所有带有SIMD单元的主流处理器上实现。基于csr5的SpMV算法由于具有结构独立性和SIMD利用率,无论对规则矩阵还是不规则矩阵都能带来稳定的高吞吐量。
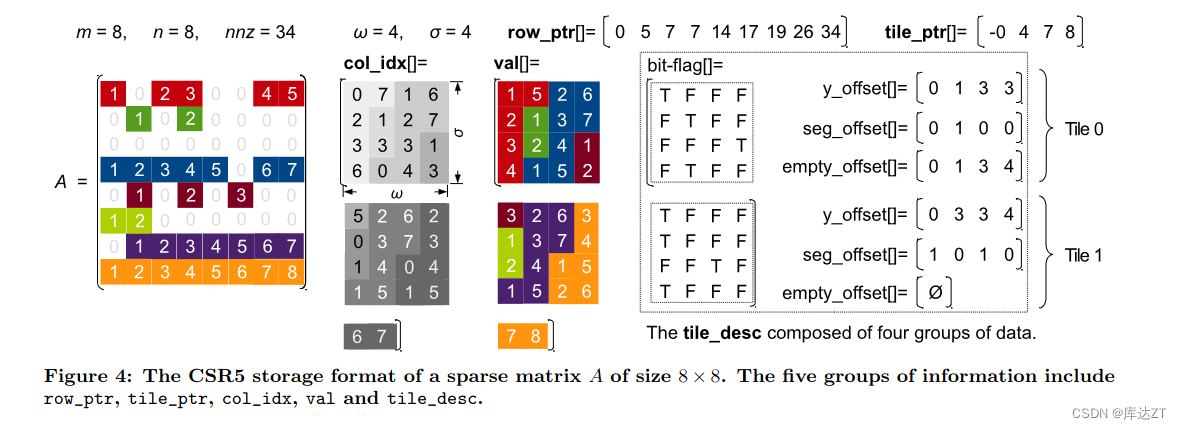
上图是CSR5的储存格式:
主要思路:将非零的元素按照行方向的顺序依次放入多个tile中,tile为的2D矩阵。这部分大小可以自己调优。
row_ptr:与我们之前的CSR中的代表非零行索引不同,这里的row_ptr主要表示的是该行之上的非零元素之和。
- tile_desc之y_offset:大小为列数,通过bit_flag数组中的T数量(每个tile的bit_flag的第一个条目被设置为TRUE)。数组第i个的值为前i行所拥有的T数量(i从0开始),用来定位存储位置。换句话说,每个列在数组y_offset中有一个条目作为同一列中所有段的起始偏移量。通过计算tile_ptr[tid] + y_offset[i]该列知道自己在y中的起始位置
- tile_desc之seg_offset:大小为列数,因为有些行非零元素过多,导致一个tile中,多列的数据其实还是同一行的,所以为了快速求分段和(不是很明白),就设计了该数组。数组第i个的值为该列的右列有多少列为全F。为了生成seg_offset,我们让每个列搜索它的右邻居列,并计算其bit_flag中没有任何true的连续列的数量。以Tile 0为例,它的第二列有且只有一个右邻居列(第三列),其bit_flag中没有任何true。因此,第二列的seg_offset值为1。
- tile_dsec之empty_offset:大小不确定,可能为0或者tile中segment的数量,即bit_flag中T的数量。当tile中没有空行,大小就为0。当有空行,即y_offset记录了不正确的偏移量,empty_offset代表了每个T所在第几行,即偏移值。
2、SPMV算法:
行段算法:

for (int row = 0 , row < row_num , row++){
float acsum = 0;
int row_start = row_ptr( row ) , row_end = row_ptr ( row + 1 );
for(int elem = row_start ; elem < row_end ; elem++){
acsum += value[elem]*X[col_index[elem]];
}
y[row] += acsum;
}segment_sum算法:


在SpMV操作中,分段和将每个矩阵行视为一个段,并为每行中生成的入口乘积计算部分和。使用分段求和方法的SpMV操作包括四个步骤:
(1)从row_ptr数组生成一个大小为nnz的辅助bit_flag数组。如果bit_flag中的条目与一行的第一个非零条目匹配,则标记为TRUE,否则标记为FALSE,
(2)计算大小为nnz的数组的所有中间条目(即入口积),
(3)执行数组的并行分段和,
(4)收集结果向量y的所有部分和,如果一行不为空。
下面是分段和的示例:
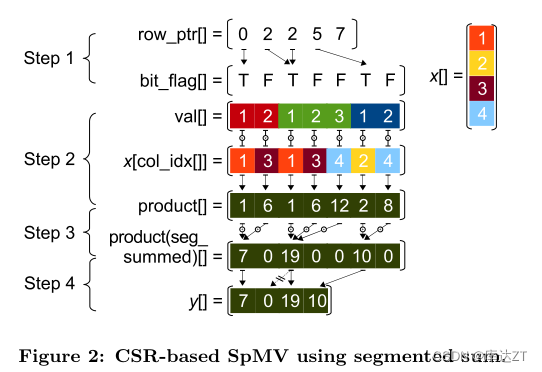
这里的分段(segment)是将矩阵的行分成多个较小的片段,以便并行计算。通常,分段的大小取决于任务的性质和计算节点的数量。每个计算节点被分配一个或多个连续的矩阵行,它们在计算过程中只负责处理这些行的乘积和。
具体来说,每个计算节点执行以下步骤:
-
获取分配给该节点的矩阵行的范围。这个范围可以由初始索引和结束索引来定义,表示计算节点负责计算的矩阵行的起始位置和结束位置。
-
遍历分配给该节点的矩阵行。对于每一行,执行以下步骤:
a. 计算该行与稠密向量的乘积,并将结果累加到本地的乘积和变量中。
b. 继续处理下一行。
-
将本地的乘积和变量发送给中央节点或主节点。
-
中央节点或主节点负责将所有计算节点的乘积和结果进行求和,得到最终的计算结果。
通过将矩阵的行分成多个片段并分配给不同的计算节点,分段求和算法实现了计算的并行化。每个计算节点只负责计算分配给它的矩阵行的乘积和,而不需要考虑其他节点的工作。最终,各个节点的乘积和结果会被汇总,得到整个矩阵向量乘积的最终结果。这样可以提高计算效率,并充分利用分布式计算环境的资源。
BCSR的BSpMV算法:
CSR5 fast_segment 算法:http://t.csdn.cn/XWpOT
3、并行SPMV
所谓并行就是将最外层的循环交给线程
__global__ void SpMV_CSR(int num_rows, float *data, int *col_index, int *row_ptr, float *x, float *y){
int row = threadIdx.x + blockDim.x*blockIdx.x;
if(row<num_rows){
int row_start = row_ptr[row], row_end = row_ptr[row + 1];
float dot = 0;
for (int elem = row_start; elem < row_end; elem++)
{
dot += data[elem] * x[col_index[elem]];
}
y[row] += dot;
}
}这个 kernel 与上面的串行代码几乎一样,也很简单,但是它有两个缺点:
- 不能合并访存,不能有效利用存储器带宽。
- 所有 warp 都有控制流分支。每个线程执行循环的次数由分配给那一行中元素的数量,数量很可能不同,就会造成控制流分支。
#include <bits/stdc++.h>
#include <cuda.h>
#include "device_launch_parameters.h"
#include <time.h>
#include <sys/time.h>
#include <cuda_runtime_api.h>
//Example: Application using C++ and the CUSPARSE library
//-------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include "cuSparse.h"
#include <cusparse.h>
__global__ void SpMV_CSR(int num_rows, const float *data, const int *col_index,const int *row_ptr, const float *x, float *y){
int row = threadIdx.x + blockDim.x*blockIdx.x;
if(row<num_rows){
int row_start = row_ptr[row], row_end = row_ptr[row + 1];
float dot = 0;
for (int elem = row_start; elem < row_end; elem++)
{
dot += data[elem] * x[col_index[elem]];
}
y[row] += dot;
}
}
int main()
{
// 创建 cuSPARSE 句柄
cusparseHandle_t handle;
cusparseCreate(&handle);
// 定义稀疏矩阵和向量的参数
const int N = 4; // 矩阵尺寸
const int nnz = 9; // 非零元素数目
const int rowPtr[N+1] = {0, 3, 5, 7, 9}; // 行指针数组
const int colInd[nnz] = {0, 2, 3, 1, 2, 0, 3, 1, 3}; // 列索引数组
const float values[nnz] = {1.0f, -2.0f, 3.0f, -4.0f, 5.0f, -6.0f, 7.0f, -8.0f, 9.0f}; // 非零元素值
const float x[N] = {1.0f, 2.0f, 3.0f, 4.0f}; // 输入向量
// 创建并填充设备上的稀疏矩阵和向量
cusparseMatDescr_t descr;
cusparseCreateMatDescr(&descr);
float *d_values, *d_x, *d_y;
int *d_rowPtr, *d_colInd;
cudaMalloc((void**)&d_values, nnz * sizeof(float));
cudaMalloc((void**)&d_x, N * sizeof(float));
cudaMalloc((void**)&d_rowPtr, (N+1) * sizeof(int));
cudaMalloc((void**)&d_colInd, nnz * sizeof(int));
cudaMemcpy(d_values, values, nnz * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_x, x, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_rowPtr, rowPtr, (N+1) * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_colInd, colInd, nnz * sizeof(int), cudaMemcpyHostToDevice);
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// 执行稀疏矩阵向量乘法
const float alpha = 1.0f; // 矩阵乘法的缩放因子
const float beta = 0.0f; // 输出向量的缩放因子
float y[N] = {0}; // 输出向量初始化为零
float yA[N] = {0}; // 输出向量初始化为零
cudaMalloc((void**)&d_y, N * sizeof(float));
float *d_yA;
cudaMalloc((void**)&d_yA, N * sizeof(float));
int count = 100000;
cudaEventRecord(start, 0);
for (int i = 0; i < count; i++)
{
SpMV_CSR<<<dim3(1),dim3(4)>>>(N, values , colInd , rowPtr , x,d_yA );
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
// 计算 GPU 执行时间
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
// 输出时间结果
printf("SPmv 执行时间: %.5f 毫秒\n", elapsedTime);
cudaMemcpy(yA,d_yA, N * sizeof(float), cudaMemcpyDeviceToHost);
cudaEventRecord(start, 0);
for (int i = 0; i < count; i++)
{
cusparseScsrmv(handle, CUSPARSE_OPERATION_NON_TRANSPOSE, N, N, nnz, &alpha,
descr, d_values, d_rowPtr, d_colInd, d_x, &beta, d_y);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
// 计算 GPU 执行时间
elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
// 输出时间结果
printf("SPmv 执行时间: %.5f 毫秒\n", elapsedTime);
// 将结果从设备复制到主机
cudaMemcpy(y, d_y, N * sizeof(float), cudaMemcpyDeviceToHost);
// 打印结果
printf("Result vector:\n");
float eps = 1e-6;
int a = 1;
for (int i = 0; i < N; i++) {
if(yA[i] - y[i] >= eps){
a= 0;
}
}
printf("%d\n" , a);
// 释放内存和销毁 cuSPARSE 句柄
cudaFree(d_values);
cudaFree(d_x);
cudaFree(d_rowPtr);
cudaFree(d_colInd);
cusparseDestroyMatDescr(descr);
cusparseDestroy(handle);
return 0;
}
4、summary
GPU上SpMV要解决的几个问题:线程负载均衡、显存对齐访问、降低空间复杂度
分块主要是根据结构分块,也可以根据非零元密度分块
无论是分块还是元素,其都需要在某种程度上与行索引和列索引相对应,有些索引是记录在存储中,然后查出来的;有些索引是根据当前块或者行在连续存储空间中的位置算出来的。
所有的非零元最终都是存在内存的一维连续空间中
逻辑数据结构的设计是一回事,数据在线程中的分配是一回事,逻辑数据结构在物理的线性地址空间的分配是一回事
对每一个索引的压缩通常会导致SpMV只能并行化这个索引的遍历,或者就要引入复杂的同步机制。索引的压缩是负载不均衡的最主要推手。
负载均衡优先的数据分配通常是遍历值的数组,所以需要一种手段,引入尽可能少的索引结构,构建从值到行号列号的反查手段,可以让一个线程知道自己是不是算到了行的边界,以及自己具体在算哪一行,并且要如何解决多个层次的同步问题和线程临时结果的规约问题。
归约
SpMV有乘法和加法两个过程,其实可以分开对待,即“乘”是完全并行的过程,“加”(归约)是需要同步的过程。即便将矩阵分块,并且为每个线程分配非零元之后,乘是没有分歧的难度的,算法的设计主要在加(归约)上。归约存在不同的时机:每个线程处理完自己负责的内容时先进行一次归约,每个wrap执行完之后进行一次归约,每个block执行执行完之后进行一次归约,全局都执行玩之后执行一次归约。其中,这几种归约的时机可以叠加,但是全局规约是必须的。归约是对中间结果的按行叠加,可以在不同的位置:共享内存,显存。
对于wrap、block、乃至全局层次,归约可以用不同的方式:原子操作的方式,全局同步的方式。原子操作实现比较简单,而且省空间,但是有争用。全局的方式同步就是,将需要归约的所有数据先存下来,然后用一个或者多个线程统一加(归约)到一起,这种方式需要额外的存储空间,但是完全不会在同一个存储的位置上出现“写争用”。
此外,规约的算法也有不同:可以一个线程规约一行的数据,也可以多个线程树状规约。
对齐
在稀疏矩阵非零元与线程的分配中,对齐决定了中间计算结果的处理方式。对齐有不同的方向,分成不同的层次,主要体现在稀疏矩阵行与不同计算单元粒度之间的关系上:线程、wrap、线程块。
对齐的不同方向主要是两个方向,比如行与线程对齐(数据与不同粒度的计算资源的对齐),就是一行中的非零元不能横跨多个线程,行与线程不对齐代表了不同线程产生的结果需要进行归约,反之行与wrap、行与线程块之间也一样,主要是体现了中间结果规约的范围。
不同粒度计算资源与数据之间也存在对齐,比如一个线程与行的对齐,就是一个线程的处理的非零元只能都在一个行内。如果不同粒度的计算资源与行不对齐,那么对应粒度的计算资源就会产生多个中间结果。比如,如果线程与行的不对齐,代表了一个线程的中间结果可能来自于不同行,从而需要引入更多的索引和元数据。这会导致更复杂的内核实现和数据结构设计。
当然也有两个方向都不对齐的情况,一行可能被多个线程处理,并且一个线程同时处理多行在一个矩阵中同时存在,那就非常复杂了,CSR5、yaSpMV与HCC这类完全按照非零元数量为线程(wrap、线程块)分配任务,从而保证绝对负载均衡的工作就是这一类。他们完全不考虑对齐的问题,所以同步过程非常复杂,数据结构的设计、kernal的实现也非常复杂。
两个方向全都不对齐格式有:yaSpMV,CSR5,HCC,Merge-based
负载均衡
SpMV分为并行乘和规约加两个部分,其中乘阶段的线程间负载均衡是很好保证的,难是难在归约加的负载均衡上。通常来讲,为了保证归约加的负载均衡,大多数文章都采用线程和数据完全都不对齐的方式来处理,这些方式有的仅仅考虑按照非零元数量的平均分配,有的综合考虑了非零元的数量和所包含的行的数量。
采用负载均衡的方式几乎必然导致线程和数据两个方向的完全不对齐,这导致线程所负责非零元的逻辑索引必须只能是连续的,虽然在实际的执行中,可以通过预处理去做个转置,通过改变物理索引使其支持合并访存,但是这也有额外的预处理开销。
至于为什么预处理做转置可以减少开销:
原来的CSR
Values: [2, 1, 3, 4, 5]
Column Indices: [0, 2, 1, 0, 2]
Row Offsets: [0, 1, 3, 5]
转置后:
Values: [2, 4, 1, 5, 3]
Column Indices: [0, 0, 2, 2, 1]
Row Offsets: [0, 2, 3, 5]
以上就是从行主序变为列主序,在一维层面修改了,所以可以做到合并访问
本文部分参考:https://www.zhihu.com/question/36513265/answer/2425877344














 1724
1724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









