







本文是总结系列文章的第二篇,主要介绍涉及到的聚类方法和深度学习方法的基本原理,以及应用时的操作。
由于传统基于模型方法的缺陷,机器学习方法是目前用于IDS的突出方法。基于机器学习的网络流量数据分类大概可分为三种:
(1)聚类:无监督学习,如K-Means,FCM等;
(2)传统机器学习分类方法:半监督学习,如SVM,RF,GBT等;
(3)深度学习:监督学习,如DNN,CNN,RNN等;
此处介绍聚类方法,以K-Means和FCM为例,以及深度学习方法,以RNN,IRNN,LSTM,GRU和DBN为例。
目录
一、聚类方法
1.1 聚类方法简介
(1)聚类的定义
聚类是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
(2)聚类和分类的区别
聚类是一种无监督学习算法,不关心数据的标签,目标是把相似的数据聚合在一起;分类是监督学习算法,目的是把不同的数据划分开,通过训练数据集获得分类器,然后取分类数据。
(3)聚类的一般过程
① 数据准备:特征标准化和降维;
② 特征选择:从最初的特征中选择有效的特征,并存储在向量中;
③ 特征提取:通过对选择的特征进行转换形成新的突出特征;
④ 聚类:基于某种距离函数进行相似性度量,获取簇;
⑤ 聚类结果评估:分析聚类结果,如距离误差和SSE等。
(4)聚类方法分类
主要有四类:划分式聚类方法,基于密度的聚类方法,层次化聚类方法等。
——划分式聚类:需要事先指定簇类的数目或者聚类中心,通过反复迭代,直至最后达到目标函数最小。代表方法有K-Means及其各种变体;
——基于密度的聚类:对于非凸形状的数据点,K-Means无能为力,如环形数据的聚类。基于密度通过定义两个参数:密度的邻域半径和邻域密度阈值。如DBSCAN等;
——层次化聚类:为了解决前两种方法的链式效应,层次聚类将数据划分为一层一层的簇,后面一层生成的簇基于前面一层的结果。
上述方法为硬聚类,每个数据只能被归为一类。模糊聚类作为聚类分析中的一个广泛分支,通过隶属函数来确定每个数据隶属各个簇的程度,而不是将一个数据对象硬性的归类到某一簇中。已经有很多模糊聚类算法被提出,如FCM等。
1.2 K-Means
k-means算法目标是,以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。
k-means算法的处理过程如下:首先,随机地选择k个对象,每个对象初始地代表了一个簇的平均值或中心;对剩余的每个对象,根据其与各簇中心的距离,将它赋给最近的簇;然后重新计算每个簇的平均值。 这个过程不断重复,直到准则函数收敛。通常,采用平方误差准则,其定义如下:
这里E是数据库中所有对象的平方误差的总和,p是空间中的点,mi是簇Ci的平均值。该目标函数使生成的簇尽可能紧凑独立,使用的距离度量是欧几里得距离,当然也可以用其他距离度量
算法流程如下:
(1)任意选择k个点作为初始质心(通常随机选择);
(2)计算每个数据点到中心点的距离,数据点距离哪个中心点最近就划分到哪一类中。
(3)对每个簇,计算簇中所有点的均值并将均值作为新的质心;
(4) 重复以上步骤,直到每一类中心在每次迭代后变化不大为止。也可以多次随机初始化中心点,然后选择运行结果最好的一个。
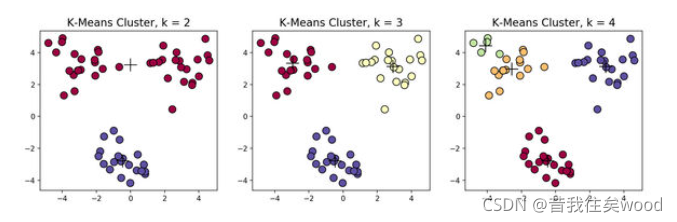
优点:简单直接,易于理解,低维数据上效果不错;
缺点:高维数据计算速度慢,且需提前确定k值,对初始质心点敏感,对异常数据敏感。
1.3 FCM
模糊聚类方法基于模糊数学理论进行聚类。
模糊c均值聚类(FCM)算法是一种以隶属度来确定每个数据点属于某个聚类程度的算法。该聚类算法是传统硬聚类算法的一种改进。
设数据集,它的模糊c划分可用模糊矩阵
表示,矩阵U的元素表示第 j ( j=1, 2, …, n ) 个数据点属于第i (i=1, 2, …, c )类的隶属度,满足如下条件:
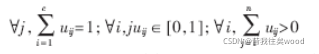
目前广泛使用的聚类准则为取类内加权误差平方和的最小值:
![]()
其中V为聚类中心,m为加权指数:
![]()
算法流程:
(1)标准化数据矩阵;
(2)建立模糊相似矩阵,初始化隶属矩阵;
(3)算法开始迭代,直到目标函数收敛到极小值;
(4)根据迭代结果,由最后的隶属矩阵确定数据所属的类,显示最后的聚类结果。
优点:相比起前面的”硬聚类“,FCM方法会计算每个样本对所有类的隶属度,这给了我们一个参考该样本分类结果可靠性的计算方法,若某样本对某类的隶属度在所有类的隶属度中具有绝对优势,则该样本分到这个类是一个十分保险的做法,反之若该样本在所有类的隶属度相对平均,则我们需要其他辅助手段来进行分类。
k-means聚类算法的初始点选择不稳定,是随机选取的,这就引起聚类结果的不稳定,FCM对初始聚类中心敏感,需要人为确定聚类数,容易陷入局部最优解。
二、深度学习方法
主要有以下几种方法:
(1)提取特征后,每个特征输入一个神经元,利用DNN或者ANN等利用多个全连接层进行分类;
(2)利用RNN及其变种LSTM,GRU,Seq2Seq等提取记录的时间序列特性;
(3)CNN和RNN组合方法,利用CNN提取高级特征,然后连接RNN进一步识别进行分类;
2.1 关于深度学习方法的阐述
从计算性质来看,深度学习方法的计算本质就是线性的矩阵乘法和加法组合而成的复杂运算,为了非线性化又引入激活函数,组合运算达到了提取数据复杂特征和序列特征的功能。
总的来说,深度学习方法大概分为两大类,即CNN和RNN。MLP是学习深度学习方法的基础。
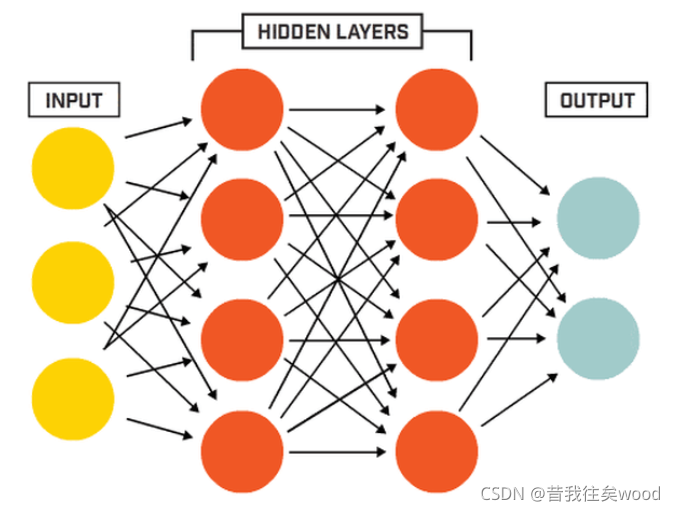
2.2 MLP
最简单的神经网络,也是所有神经网络的基础。简单来说,就是节点代表值,每层之间用一个矩阵连起来,进行矩阵乘法,加上节点的值,并经过节点的激活函数进行非线性变化。然后经过反向传播算法和梯度下降进行调参。
2.3 CNN
见博客:(62条消息) 【神经网络】学习笔记四—卷积神经网络CNN简介1.0_杨的博客-CSDN博客
2.4 RNN
见博客:(62条消息) 【神经网络】学习笔记五—循环神经网络RNN简介1.0_杨的博客-CSDN博客_rnn全称
三、设计实验
设计三个实验,分别是CNN+IRNN,DBN和改进的FCM。
3.1 CNN+IRNN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









