







目录
ASCII码表
-
ASCII美国信息交换编码标准,现在全球都在使用,它是一种8位二进制01符号的组合,PC机上的键盘输入的都是ASCII码。
-
十六进制是一种计数方式,如同我们熟悉的十进制一样,只不过十进制是逢十进一,而十六进制是逢十六进一。十进制计数要0 ~ 9十个符号来表示,十六进制计数需要0 ~ 15十六个符号来表示,所以十六进制的10~15这六个符号是借用英文字母ABCDEF(或abcdef)来表示的。
-
十六进制每一位数字需要4位二进制码来表示,ASCII是8位二进制编码,所以一个ASCII码可以用二位十六进制数表示;不过这并不是说它们之间有什么内在的关系,正如ASCII码也常用二位或三位十进制数表示一样
// 数字,字母对应的ascll码
数字(其实是字符)0 ~ 9对应的ASCII码(十进制)为“48”~“57”
大写字母A ~ Z对应的ASCII码(十进制)为“65”~“90”
小写字母a ~ z对应的ASCII码(十进制)为"97"~“122”
万物皆可(10/16进制)ASCII码表示,转化成对应的数字(其实是字符)和字符。
ASCII码大致由三部分组成:
参考地址:https://blog.csdn.net/sinat_28631741/article/details/80961033
ASCII打印字符表
数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。注:十进制32代表空格 ,十进制数字 127 代表 DELETE 命令。下面是ASCII码和相应数字的对照表:
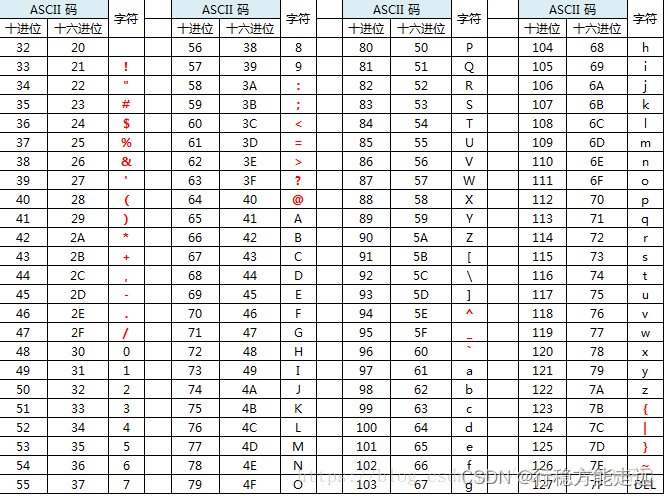
ASCII非打印控制字符表
ASCII 表上的数字 0–31 分配给了控制字符,用于控制像打印机等一些外围设备。例如,12 代表换页/新页功能。此命令指示打印机跳到下一页的开头。
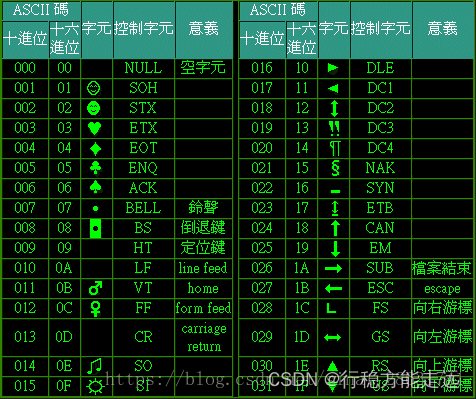
ASCII扩展打印字符表
扩展的 ASCII 字符满足了对更多字符的需求。扩展的 ASCII 包含 ASCII 中已有的 128 个字符(数字 0–32 显示在下图中),又增加了 128 个字符,总共是 256 个。即使有了这些更多的字符,许多语言还是包含无法压缩到 256 个字符中的符号。因此,出现了一些 ASCII 的变体来囊括地区性字符和符号。

C语言——转义字符
https://baike.baidu.com/item/%E8%BD%AC%E4%B9%89%E5%AD%97%E7%AC%A6/86397?fr=ge_ala#7
https://zhidao.baidu.com/question/134551888.html
https://blog.csdn.net/qq_45559559/article/details/126132152

C中定义了一些字母前加 " \ "来表示常见的那些不能显示的ASCII字符,如\0,\t,\n等,就称为转义字符,因为后面的字符,都不是它本来的ASCII字符意思了,即转义了。
例如: \r 表示回车,\n表示换行。
回车只是回到行首,不改变光标的纵坐标;换行只是换一行,不改变光标的横坐标。
例如:\ \ 用于表示一个反斜杠,防止它被解释为一个转义序列符
例如:像这样打印单引号时会造成编译器无法编译:
printf("%c",''');
在 ’ 前面加 \ 将它转义就可以打印出来了,
printf( "%c",' \' ');
例如:当你想打印一个文件路径时,如果直接这样写:
printf("c:\test\test.c");
那打印出来的结果将是这样的:
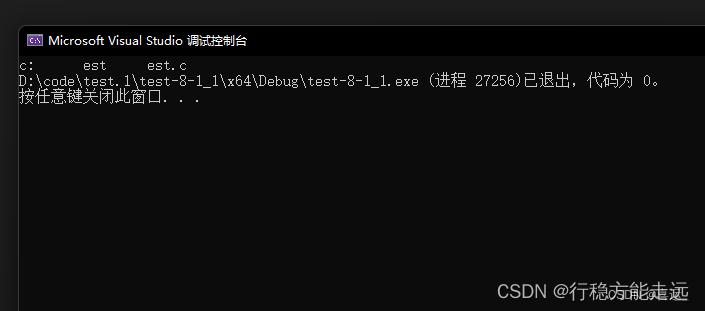
这是因为 \t 会被编译器解析为水平制表符,
正确的写法是在 \ 的前面加 \ 进行转义, 防止被解析为 \t,
printf("c:\\test\\test.c");
打印出来的结果是这样的:

C语言基本数据类型
参考:语言基本数据类型
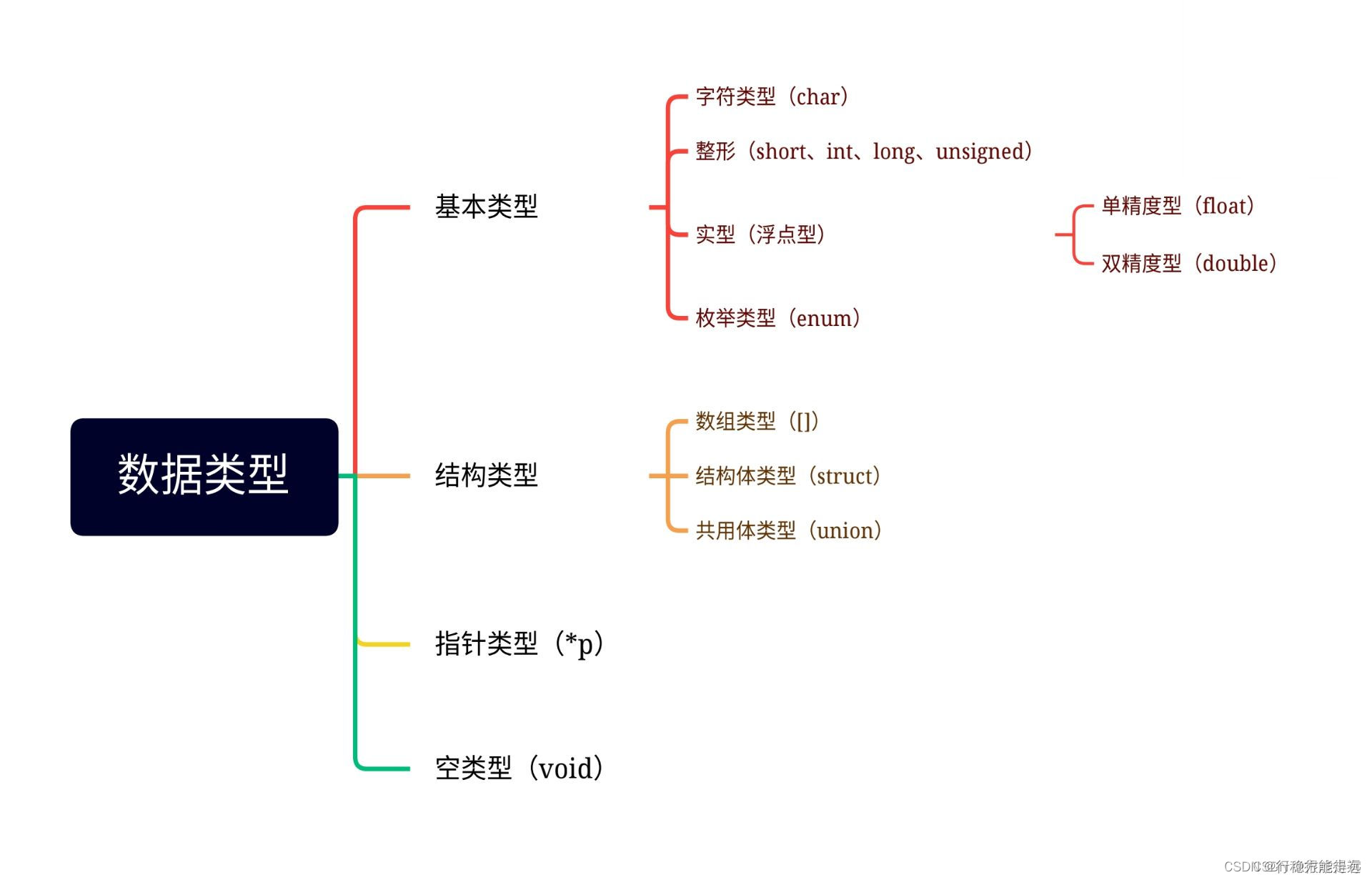
针对不同的数据,采取不同的存储方式和进行不同的处理。随着处理对象的复杂化,数据类型也要变得更丰富。数据类型的丰富程度直接反映了程序设计语言处理数据的能力。
C语言很重要的一个特点是它的数据类型十分丰富。因此,C语言程序数据处理功能很强。C语言丰富的数据类型可归纳如下:
整型变量
整数类型数据即整型数据,整型数据没有小数部分的数值。整型数据可分为:基本型、短整型、长整型和无符号型四种。
基本型:以int表示。
短整型:以short int表示。
长整型:以long int表示。
无符号型:存储单元中全部二进位用来存放数据本身,不包括符号。无符号型中又分为无符号整型、无符号短整型和无符号长整型,分别以unsigned int,unsigned short和unsigned long表示。
要注意的是,不同的计算机体系结构中这些类型所占比特数有可能是不同的,下面列出的是32位机中整型家族各数据类型所占的比特数。
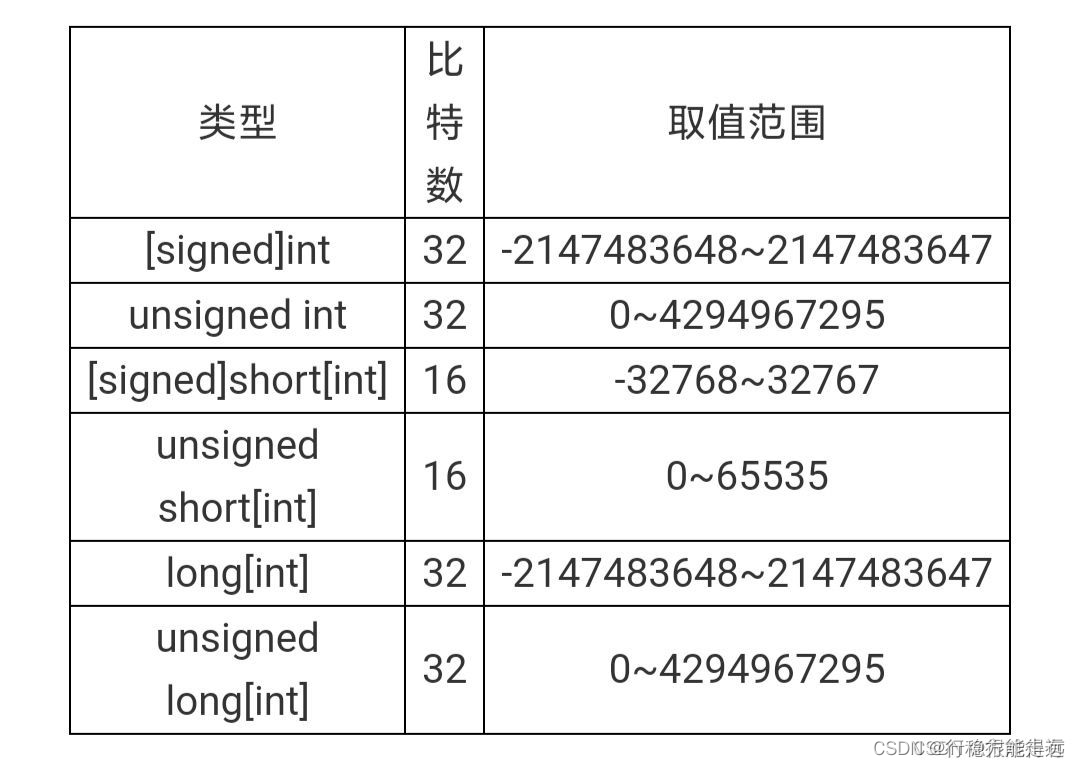
虽然int与unsigned int所占的位数一样,但int的最高位用作了符号位,而unsigned int的最高位仍为数据位,所以它们的取值范围不同。
若要查看适合当前计算机的各数据类型的取值范围,可查看文件“limits.h”(通常在编译器相关的目录下),如下是“limits.h”的部分示例。
#define CHAR_BIT 8 /* number of bits in a char */
#define SCHAR_MIN (-128) /* minimum signed char value */
#define SCHAR_MAX 127 /* maximum signed char value */
#define UCHAR_MAX 0xff /* maximum unsigned char value */
#ifndef _CHAR_UNSIGNED
#define CHAR_MIN SCHAR_MIN /* mimimum char value */
#define CHAR_MAX SCHAR_MAX /* maximum char value */
#else
#define CHAR_MIN 0
#define CHAR_MAX UCHAR_MAX
#endif /* _CHAR_UNSIGNED */
#define MB_LEN_MAX 2 /* max. # bytes in multibyte char */
#define SHRT_MIN (-32768) /* minimum (signed) short value */
#define SHRT_MAX 32767 /* maximum (signed) short value */
#define USHRT_MAX 0xffff /* maximum unsigned short value */
#define INT_MIN (-2147483647 - 1) /* minimum (signed) int value */
#define INT_MAX 2147483647 /* maximum (signed) int value */
#define UINT_MAX 0xffffffff /* maximum unsigned int value */
#define LONG_MIN (-2147483647L - 1) /* minimum (signed) long value */
#define LONG_MAX 2147483647L /* maximum (signed) long value */
#define ULONG_MAX 0xffffffffUL /* maximum unsigned long value */
在嵌入式开发中,经常需要考虑的一点就是可移植性的问题。通常,字符是否为有符号数会带来两难的境地,因此,最佳妥协方案就是把存储于int型变量的值限制在signed int和unsigned int的交集中,这可以获得最大程度上的可移植性,同时又不牺牲效率。
整型常量
C语言整型数据一般有十进制整数、八进制整数和十六进制整数三种表达形式。说明如下。
- 十进制整数的表示与数学上的表示相同,例如:256,-321,0
- 八进制整数的表示以数字0开头,例如:0234表示八进制整数(234)8,所对应的十进制数为 。2×82+3×81+4×80=156。
- 十六进制整数的表示以0x开头,例如:0×234表示十六进制整数(234)16。(应当注意的是十六进制数前导字符0x,x前面是数字(0)。
在一个整型数据后面加一个字母L或l(小写),则认为是long int型量。如342L、0L、78L等,这往往用于函数调用中。如果函数的形参为long int型,则要求实参也为long int型,此时需要用342L作实参。
实数(浮点)类型
1.实数(浮点)变量
实型变量又可分为单精度(float)、双精度(double)和长双精度(long double)3种。列出的是常见的32位机中实型家族各数据类型所占的比特数。
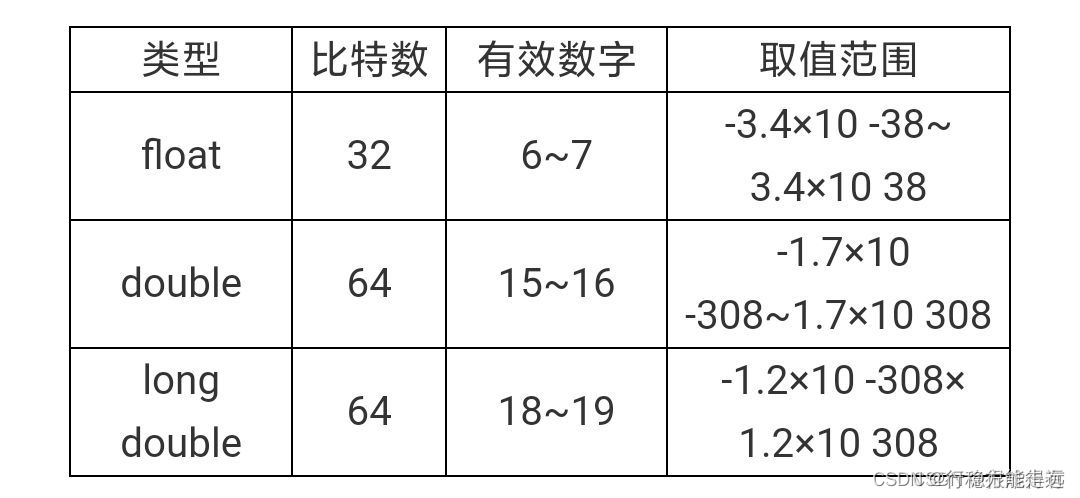
要注意的是,这里的有效数字是指包括整数部分+小数部分的全部数字总数。
小数部分所占的位(bit)越多,数的精度就越高;指数部分所占的位数越多,则能表示的数值范围就越大。下面程序就显示了实型变量的有效数字位数。
#include<stdio.h>
int main()
{
float a;
double b;
a = 33333.33333;
b = 33333.333333;
printf(" a = %f , b = %lf \n" , a , b );
return 0;
程序执行结果如下:
a=33333.332031 , b=33333.333333
可以看出,由于a为单精度类型,有效数字长度为7位,因此a的小数点后4位并不是原先的数据。而由于b为双精度类型,有效数字为16位,因此b的显示结果就是实际b的数值。
实型(浮点)常量
在C语言程序设计中,实型数据有以下两种表达形式。
- 十进制数形式。由正负号、数字和小数点组成。如5.734、一0.273、0.8、一224等都是十进制数形式。
- 指数形式。如546E+3或546E3都代表546×10 3。字母E(或e)之前必须有数字,E(或e)后面的指数必须为整数。
E8、4.6E+2.7、6e、e、9E7.5都是不合法的指数形式;
5.74E-7、-3E+6是合法的指数形式实型常量。
字符变量
字符变量可以看作是整型变量的一种,它的标识符为“char”,一般占用一个名节(8bit),它也分为有符号和无符号两种,读者完全可以把它当成一个整型变量。当它用于存储字符常量时,实际上是将该字符的ASCⅡ码值(无符号整数)存储到内存单元中。
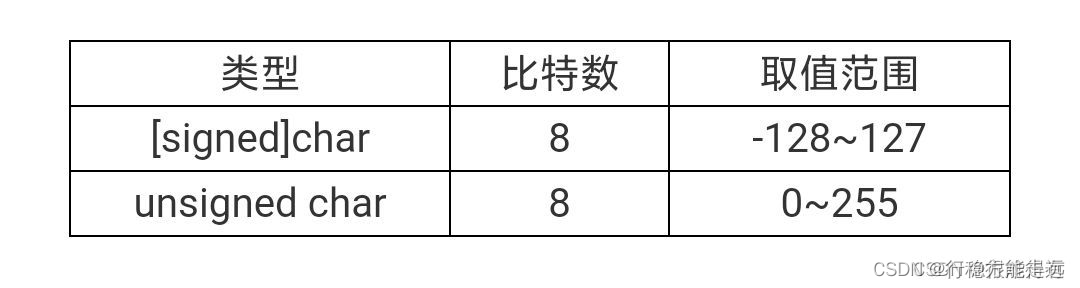
实际上,一个整型变量也可以存储一个字符常量,而且也是将该字符的ASCH码值(无符号整数)存储到内存单元中。但由于取名上的不同,字符变量则更多地用于存储字符常量。以下一段小程序显示了字符变量与整型变量实质上是相同的。
#include<stdio.h>
int main()
{
char a,b;
int c,d;
/*赋给字符变量和整型变量相同的整数常量*/
a=c=65;
/*赋给字符变量和整型变量相同的字符常量*/
b=d='a';
/*以字符的形式打印字符变量和整型变量*/
printf("char a=%c,int c = %c", a,c);
/*以整数的形式打印字符变量和整型变量*/
printf("char b=%d,int d=%d\n",b,d);
return 0;
程序执行结果如下:
char a=A,int c=A;
char b=97,int d=97;
由此可见,字符变量和整型变量在内存中存储的内容实质是一样的。
字符常量
字符常量是指用单引号括起来的一个字符,如:‘a’,‘5’,‘?’ 等都是字符常量。以下是使用字符常量时容易出错的地方,请读者仔细阅读。
- 字符常量只能用单引号括起来,不能用双引号或其他括号。
- 字符常量只能是单个字符,不能是字符串。
- 字符可以是字符集中任意字符。但数字被定义为字符型之后就不能参与数值运算。如’5’和5是不同的。‘5’是字符常量,不能直接参与运算,而只能以其ASCⅡ码值(053)来参与运算。
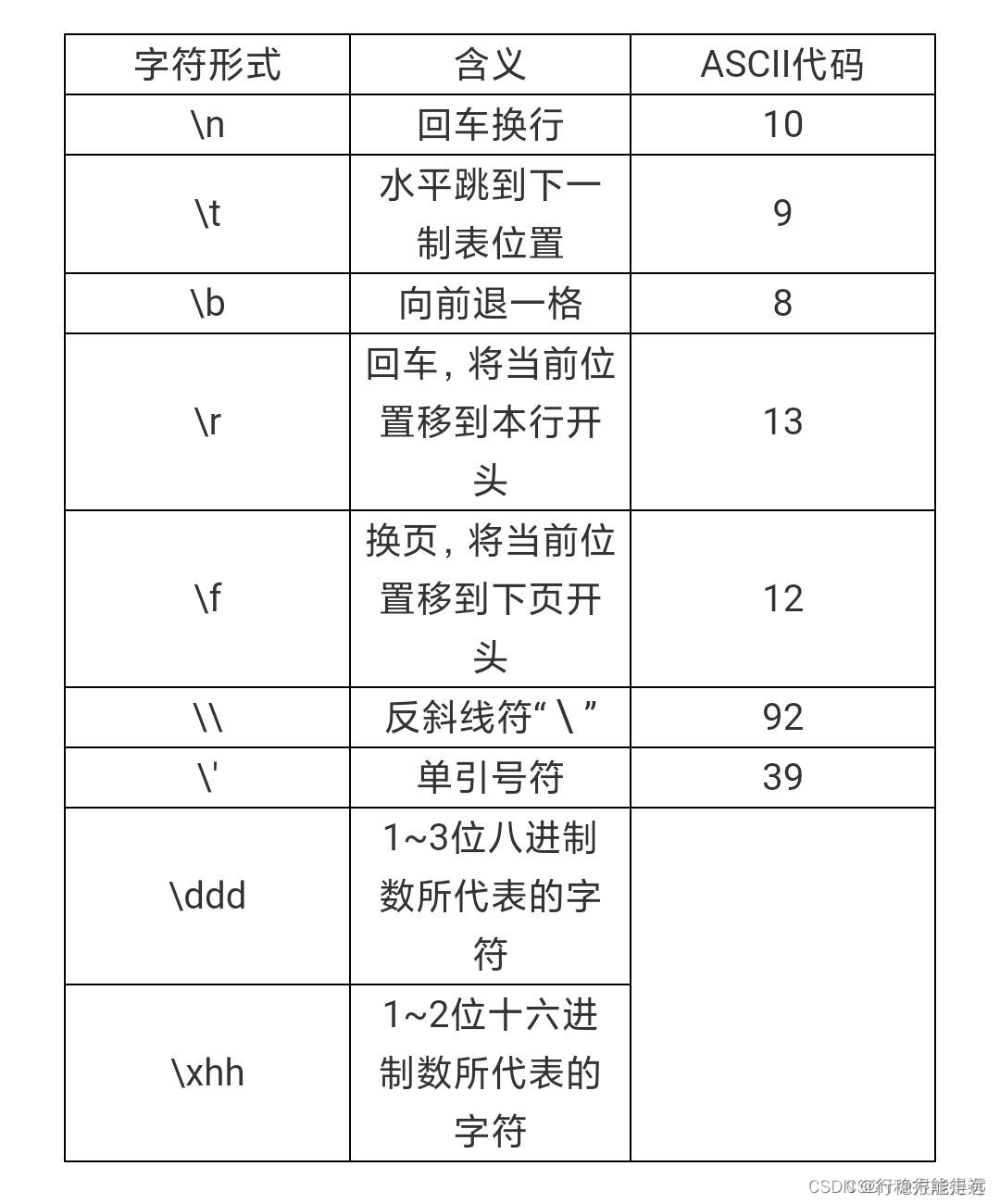
除此之外,C语言中还存在一种特殊的字符常量——转义字符。转义字符以反斜线“\”开头,后跟一个或几个字符。转义字符具有特定的含义,不同于字符原有的意义,故称“转义”字符。
例如,在前面各例题printí函数的格式串中用到的“\n”就是一个转义字符,其意义是“回车换行”。转义字符主要用来表示那些用一般字符不便于表示的控制代码。
常见的转义字符以及它们的含义。
‘0’ 的ASCII码 48,‘A’ 的ASCII码 65,‘a’ 的ASCCII码 97
C语言中printf格式符打印
%2d,%-2d,%.2d,%02d,%ld,%lld
%d:普通的输出,是几位数就输出几位数。
%2d:按宽度为2输出,右对齐方式输出。若不够两位,左边补空格。
%02d:同样宽度为2,右对齐方式。位数不够,左边补0。
%.2d:从执行效果来看,与%02d一样。
%-2d:-号表示右边补空格
%ld:输出long
%lld:输出long long (在32位编译器上,int=long=32bit;long long=64bit)
#include<stdio.h>
int main()
{
int a = 1;
printf("%d\n",a);
printf("%2d\n",a);
printf("%02d\n",a);
printf("%.2d\n",a);
printf("%-2d\n",a);
return 0;
}
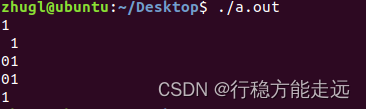
%f, %.nf, %m.nf
%f:不限制宽度和小数点后面的位数
%5.2lf:表示限制数据输出宽度为5,小数点后保留2位。不足宽度的前面补空格。超过宽度的数据正常输出。
%.2f:表示小数点后面保留两位小数。
%.6f:表示小数点后面保留六位小数。
#include<stdio.h>
int main()
{
double num;
num = 3.1415;
printf("%f\n",num);
printf("%5.2lf\n", num);
printf("%.2lf\n", num);
printf("%.6lf\n", num);
return 0;
}
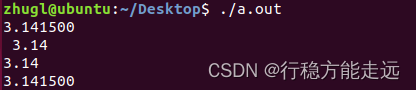
%*s, %.*s
- *由参数指定。
- %* s表示至少* 个字符,不足补空白。
- %.* s表示最多* 个字符,多了截断。 同理,%*.*f
宽度和精度格式参数
- 可以省略
- 或者嵌入到格式字符串中(如%8s,%9.2f)。
- 或者在格式字符串中由*指示,此时作为另一个函数参数传递。
例如,printf(“%*d”, 5, 10) 将打印 10,总宽度为 5 个字符。
而 printf(“%.*s”, 3, “abcdef”) 将打印abc。
%*s
#include <stdio.h>
int main(void)
{
char buf[]="ABCDEFG123456789";
printf("%*s", 10, buf);
return 0;
}
运行结果
ABCDEFG123456789
此时,*s表示s是一个长度可变的,必须由其后第一个参数指明其长度,第二个参数指明其内容。
- 表示打印长度可变
- 后面第一个参数指明其长度
- 第二个参数指明其内容
%.*s
#include <stdio.h>
int main(void)
{
char buf[]="ABCDEFG123456789";
printf("%.*s", 10, buf);
return 0;
}
运行结果
ABCDEFG123
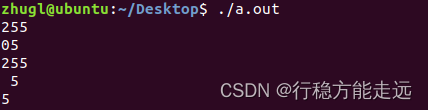
%2x, %02x, %-2x, %.2x
x:表示以十六进制形式输出,
%02x: 表示不足两位,前面补0输出;如果超过两位,则实际输出
%.2x:效果和%02x相同 (%02x=%.2x)
%2x:表示数据不足两位时,前面补空格; 如果超过两位,则实际输出
%-2x:表示数据不足两位时,后面补空格; 如果超过两位,则实际输出
#include<stdio.h>
int main()
{
printf("%02X\n", 0x255);
printf("%02X\n", 0x5);
printf("%2X\n", 0x255);
printf("%2X\n", 0x5);
printf("%-2X\n", 0x5);
return 0;
}
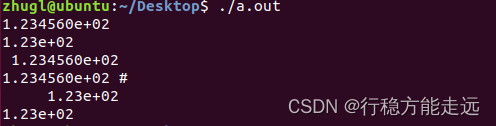
%e, %.2e,%3.2e
%e : 以指数形式打印数字 在不指定输出宽度的情况下默认数字部分小数点6位,指数占4位。 注意:小数点不算小数部分,指数e与 + / -都算指数位数。
% m.ne : m表示输出列数,n表示有几位小数 当输入列数 > m时按原数据输出 当 < m时前补空格输出
% -m.ne:表示后面补空格。
% .2e:表示不限制输出列数,小数部分保留2位。
#include<stdio.h>
int main()
{
printf("%e\n", 123.456);
printf("%.2e\n", 123.456);
printf("%13e\n", 123.456);
printf("%-13e#\n", 123.456);
printf("%13.2e\n", 123.456);
printf("%-13.2e\n", 123.456);
return 0;
}
Docker
鉴权(鉴定是否有权访问)
百度百科:https://baike.baidu.com/item/%E9%89%B4%E6%9D%83/10857773?fr=aladdin
鉴权(authentication)是指验证用户是否拥有访问系统的权利。传统的鉴权是通过密码来验证的。这种方式的前提是,每个获得密码的用户都已经被授权。在建立用户时,就为此用户分配一个密码,用户的密码可以由管理员指定,也可以由用户自行申请。这种方式的弱点十分明显:一旦密码被偷或用户遗失密码,情况就会十分麻烦,需要管理员对用户密码进行重新修改,而修改密码之前还要人工验证用户的合法身份。
为了克服这种鉴权方式的缺点,需要一个更加可靠的鉴权方式。主流鉴权方式是利用认证授权来验证数字签名的正确与否。
逻辑上,授权发生在鉴权之后,而实际上,这两者常常是一个过程。
我们常用的鉴权有四种:
- 1、HTTP Basic Authentication
- 2、session-cookie
- 3、Token 验证
- 4、OAuth(开放授权)
数字签名
AWS IOT Device C SDK 使用(阿里云一机一密、一型一密、公钥、私钥、CA、根证书、签名、验签、哈希、X.509)
Cookie、Session、Token(令牌)之间的区别
抖音程序员Rita讲的很简洁明了:Token的意思是令牌,是用户第一次登录时服务器生成的一段加密字符串,然后返回给客户端,后面客户端每次向服务端请求资源的时候只需要带上Token不用再带着用户名和密码去请求。用户登录成功后后续需要反复到服务器获取数据,服务器对每一次请求都要去验证是哪个用户发送的,用户是否合法,这样反复查询数据库会对数据库造成过大的压力,当后续请求都带上Token后服务器直接解密Token就可以知道用户的相关信息,省去了查询数据库的操作,减轻数据库的压力,这就是Token的作用。又由于基本所有请求都需要携带Token,那么总不能每一次都手动配置吧,所以在请求拦截器中统一封装,让每个请求都能带上Token。
Cookie、Session、Token之间的区别:https://v.douyin.com/MpqohSr/
- 1、存储的位置不同,cookie数据它是保存在客户端里面的,Session数据它是存储在服务器中,服务器存储相对于客户端来说是更为安全的;
- 2、存储的数据类型不同,两者虽然都是key value的数据结构,Cookie的value它只能是字符串的类型,session的value它可以是object类型,就是所有的数据类型它都能支持;
- 3、存储的数据大小不同,cookie的大小会受到浏览器的限制,一般限制在4k的大小,而Session理论上来说他只受内存的限制;
- 4、生命周期的区别,cookie的生命周期就是浏览器如果关闭的话他就会消亡,而且他还有对应的超时限制,就是你无论有没有访问,只要超时时间一到,它就一定会过期。Session是取决于服务端的一个设定,它可以设置成用户持续访问,他就不永远不会失效,和浏览器的开关是没有关系的。
- 5、有的面试官他可能关注这个点,Cookie、Session之间它是有什么样的联系?首先你们要知道Cookie它是Session的一种应用,FTP、HTTP是无状态的,服务器他只能获取到请求来源的IP,它是获取不到用户身份信息的,服务器它可以用Session存储用户的数据,一般客户都会写一个Session_ID存放在那个cookie里面,比方说这样的数据:set-cookie:session_id=123456;expires=12351233。
- 6、token也是写在cookie上的,存储在客户端,服务端会校验token的正确性。
Cookie、Session、Token之间的区别: https://v.douyin.com/MpXrCFu/
首先来讲,为什么会有cookie、session、token这样的东西,我们先来讲这个HTTP的无状态连接的概念,HTTP网络协议下所有的请求,他都是无状态连接的。所谓的无状态连接就是我A接口的请求跟B接口的请求,他们彼此之间是没有任何的关系。我每一个接口的请求业务,他都是独立化存在的,比如说我们访问了一个登录接口,在我提示到登录成功的这个信息获取成功以后,当我系统反馈到一个你已经登陆成功了,这个时候我们再来去操作其他内容的时候呢,系统会返回一个新的返回结果,告诉我们说请登录,比如我们先登录,登录完了之后我们去查询我们的用户信息,这个时候你会遇到一个问题,就是你登录它提示你登录成功,但是你在查询信息的时候,他会告诉你请登录之后再来尝试,或者说诸如此类的这种提示。这是为什么呢?就是因为HTTP是无状态连接的特性。这个特性意味着我们的登录接口跟获取用户信息的接口,两者没有任何的关系,对于系统而言,它是两个完全独立,没有关联的两次不同的请求,我分别对他们来进行处理。这个处理过程中,我不会因为他们两个接口本身业务有关联,我就把它关联起来,因为对于系统来讲,它就是两个单独独立存在化的个体。
但是有同学可能就会说,我自己在做这个系统的测试的时候,我在用户登录之后,系统是保存了我的登录信息的。系统它显示我一直处于登录状态,而且我在操作过程中,我也并没有出现到你所讲到的这种无状态的情况,我只执行了一次登录,我能够通过这次登陆之后,我能够去获取用户信息,我能调用用户数据,我能基于这个用户去干很多很多的业务场景。这个是为什么呢?这个就必须讲到的第二点,就是我们接口的鉴权机制(参考上面词条解释)。为了满足整个系统中数据交互的一个合理化,我们需要考虑用一些特定的手段去解决掉HTTP网络协议的无状态属性。为什么说HTTP它本身不会自己解决这个问题,很简单,因为HTTP目前被认定为是人机交互下效率最高的一种传输协议,他是人机交互之间传输速率最高的一种传输协议。这个协议之所以效率最高,就是因为它的无状态连接。所以说这个东西是没有办法去取消的,而我们在业务的实现过程中,我们想要去一次登录,让用户这个能够成功的登陆,并且能够持续的访问我们的系统的话,我们就要考虑在接口的业务处理上面增加一个鉴权机制,健全机制就是说当我用户登录成功以后,我去做其他的操作的时候,我的系统就会通过这个健全机制来鉴定该用户,或者说当前的这个产生提交数据的这个行为的用户,他是否具备有这样的一个权限来做接下来你想要的操作。比如我们的这些视频平台的VIP,你如果没有开通VIP的话,有些视频是看不了的,或者说你需要额外付费才能看到,当你是VIP之后,你才可以去看,这个就是一个典型的鉴权机制。那这个接口下的这个健全,就是上面讲到的cookie session 和 token。
Cookie的这种模式,就是我们服务器在处理运算数据之后,它会生成一批的响应结果,这个响应结果同时呢,它会包括包括一个叫做响应头的,在响应头中会定义一个叫set cookie的字段,服务器返回来的所有的数据包当中。set cookie当中所明确标志的内容就是你需要存入到cookie当中的东西,你必须要存储到用户端的本地,这个存放是以键值对,也就是key value的这种格式进行保存的一种文本信息,就是cookie。那么这个cookie有什么用呢?在我们第一次访问完了系统中生成了一批量的cookie数据,保存到我的用户端的本地之后,当我下次再在我的这个本地的用户去访问这个系统的时候,就可以把这些cookie所带有的这些文本信息直接带上一并传递过去。然后系统通过你的cookie传递过来的这些数值,来判定你这个用户之前是否有访问过我的系统,你这个用户访问系统的时候,你具备一些什么样的权限,就可以在cookie当中去添加这样的一些权限码。这个权限码就包括我们接下来讲的session和token,我们都可以通过cookie来进行保存,这个东西是在用户本地的。
session,中文名字叫做临时会话。本身是一个临时会话的机制,你的HTTP是无状态的连接,我在用户端访问到服务端的时候,我就建立一个类似于会话窗的这样一个窗体,类似于一个一对一的聊天框,当我们建立了这个聊天框之后,我与服务器之间的沟通和数据的交互都通过这个聊天框来进行。我有这个聊天框存在,我就可以不停的给服务端发送数据,服务端也可以不停的给我发送数据,这个就是聊天框在中间的作用。session就是这个聊天框,它有这样的一个空间啊,开辟出了一个临时会话的空间,在这个空间当中相当于建立了用户与服务端之间的这个联系。所有的数据交互都通过这个空间来进行处理。服务器这边大家可以想啊,我有1万个用户来访问的服务端,服务端就有1万个session的这个空间,那么这么多的空间我该怎么去管理,我怎么能够对应到哪个用户是使用的哪一个session的会话框呢?很简单,我们在session的这个机制当中,我们给每一个会话框,我们标了一个类似于ID这样的一个数值,叫做session ID,我们就通过用session ID去标记每一个不同的会话框,这样子就可以清楚地去区分到1万个用户。
token,其实就是一个身份牌,是由服务端在进行用户的数据提交的时候,比如说我向服务端请求一些数据,我们去登录,服务端这边,他就基于我提交的信息去做他的业务逻辑的查询啊,去做业务逻辑的这些处理和运算,然后返回一个成功的结果,与此同时会生成一个叫做token的身份牌,这个身份牌就类似于说我的个人认证啊,我在这个系统当中所谓的一个用户具备有权限的,这个被系统认可的权限的。我只要拿着这个token的身份牌,就可以一直在这个系统里面访问。像是这些视频网站,百度搜索这样的一些网站,我们搜索完了之后进入到这个系统进行登录,登录完成之后,我们做一系列所有操作,等到我们把浏览器关掉,再重新开启浏览器的时候,浏览器一直显示的依旧是我们的一个已登录的状态。这个登录状态是凭什么来的呢?就凭我的这个token,而前面我们所讲到的cookie,这个通用服务端返回cookie,然后这个token保存在了cookie当中,把这个token的值保存进来,当启动浏览器访问我系统的时候,我的本地cookie,我就把这个token就带着一起来访问到我的服务端,服务端接收到这个存在,就默认他为存在的用户,然后它的用户的对应的信息内容是什么,我就把它显示出来,所以我们可以每次打开浏览器都可以有一个默认已登陆的状态,这个就是因为cookie加token在中间起到的作用,这个就是三者的一个基本的作用。
Cookie这个东西它好在什么地方呢?它是以纯文本的形态去保存,保存在用户本地,以键值对的形态去管理它,那我们不同的域啊,就是不同的这个系统在访问的时候,不同的URL去访问的时候。我们的这个不同的URL下面有不同的cookie文件,这些文件呢它就可以很好的去保存每一个域下面的所有的资料啊这些需要被加载的这些cookie的资料他都可以去保存,服务端就不用去管理了,所有东西都在用户端去管理,服务端的压力会很轻松。
但是他有个很大的问题就是因为它是在用户本地以文本的形式保存的这种cookie文件,所以它很容易遭到窃取和手动的修改,那么出现这种情况提交到服务端之后你的账户相关的一些cookie信息,比如说我现在访问了服务端我生成了一个cookie文件,这个cookie文件被人盗用了然后放到他那边的电脑上面,然后他通过这个cookie文件去访问到这个系统就可以获取到我的数据。Session的优劣是什么呢?我们通过一个ID的形式去有序地管理所有的session会话,这样用户可以保持长时间的跟系统之间的数据交互,是非常方便的一个操作。
但同样的这个东西会有一些不太好的问题啊。比如说第一个这个画框如果他长时间的去保存,但是用户与服务端之间又不进行通信的话,那么这个资源就浪费在这里了,我们需要专门开辟一个空间来做服务端与用户端的一个交互。慢慢你服务端的资源他就不够用了啊,它会占据你很多服务端的资源。另外随着用户的使用数量越来越多,我们需要同时去为一些非常非常多的session,这个时候对于服务端来讲,他是要分出很大一部分的资源来管理所有的session,就是我们服务端的资源也无形中就被压榨了很多啊,这就会极大地影响到我们服务端的这个资源啊。为什么会这么讲呢?因为我要开辟出来这个空间,放到这里去交互,那所有的内容都是由我服务端去管理的,而对于你用户端而言,你用户端只需要带着一个session ID来请求我,我就根据你请求过来session ID,我就在这个session的会话框的这个集群里面,我就开始找这个ID匹配的是哪一个啊,匹配到了,我们就继续。那所有的资源都是在服务端管理的,所以他对于服务端的花费是非常非常大的。Token的好处就在于我们服务端生成一个token字段,我不需要通过session的会话了,我就只需要生成一个token字段,这个token字段生成之后,传递给到了用户端,用户端在他本地以K V的这种键值对的形态保存在cookie当中,那么用户拿着这个tooken来访我的系统,系统通过一个算法的解析,把这个token的这个值解析完之后,确保你这个用户是存在的,是正确的,我就给到你一个对应的数据的交互,那么这个时候我就不需要有session,我也不需要去管理这个session的空间,那由此我服务端就把所有的压力给到了用户端,用户端其实也没有什么压力啊,就是保持一个token字段而已,但对于服务端来讲呢,它就不需要再去额外开辟空间去管理所有的session,他只需要提供一个tooken进来的这个解析和识别和校验的这种处理手段就可以。
还有另外一个比较优秀的事情是什么呢,就是我们通过session呢他从服务层的啊,服务器的架构层级上面啊,就是在传统的cookie session token的这个基础上面啊,咱们做一个稍微的升级,我们的session这套机制在管理用户信息的时候呢,它会有一个非常大的弊端,是在架构层级的弊端,就是当你采用集群分布式或者说微服务架构的这种形态来做这个用户的session管理的时候。他往往会出现一个问题,什么问题?如果说我有三个登录服务器,我用户是跟A登录服务器来进行交互生成的这个session呢,那么这个session的管理呢,就会在A服务器上,对于B和C呢,它是没有管理的,那可能有些人会说,那我们给B、C做个同步不就好了吗?那你们想啊,我1万个用户,我之所以做成这种集群的形态,就是为了去减轻服务器的压力,对吧?我1万个用户,3万在这里,3万在这里,3万在这里,OK,我的用户就均摊了。那如果说我要把session做同步的话,那相当于说我每台服务器只有3万个用户在访问,但实际上我三台服务器开辟了9万个session的管理空间。因为你要同步嘛,那么二。这个模块下面就要把一和三的这些session的空间全部都要同步到二里面,那这时候其实二它本身只有3万个用户在使用,但是我要开辟9万个session的空间去管理。是不是无形中资源又有了一个大的耗费,当然这个行不行呢,这个也行啊,但这样子的话,对于资源的浪费比较大。所以说这个是session当中存在有一个非常非常大的问题。我们换另外一种处理模式,我们返回一个token,我这个a服务器他挂掉了啊,我还有B和C服务器,但是我带有这个token,我进到这个服务器里面,我们的算法校验token的机制都是一样的,我这个二服务器也好,三号服务器也好,我用户带着这个token访问进来之后,我只需要去解析你的token就能够无缝对接。因为他们这边提供的就只是一个算法来解析你的token字段,所有的数据都不是保存在某一台服务器上。对吧,那这个时候我们的token,他的一个优势就非常非常明显了。然后同样的token的这种形态,它可以很好的很轻易的就把用户的所有信息在整个服务器集群里给关联起来,这时候它能够带来一个非常非常好的优势。那你说那是不是所有都token可能也不一定。这个还是结合到业务来走,有些东西可能还是用session,有些东西呢,我们会用到token。token这个东西,它随着现在的发展,早期我们的token管理它是这样子的,早期我们是直接把这个数据存放到一个数据库里面,就是DB,在数据库里面生成一个临时表,叫做token的表,因为他们是有时效性的,我们生成token之后,就临时存在这个数据库的这个临时表当中。当我的token进来之后,我就到这个数据库当中获取我本来保存的token,然后跟他去对比,看是否有匹配的,有匹配就通过没匹配,就就提示你重新登陆。但是我们每一次的请求,因为是无状态嘛,每一次请求我们都要把这个内容给传进来,然后在物理数据库当中去寻找,这个速度就会非常慢,所以由此我们就进阶到了基于redis啊走缓存数据库这种形式来做,他就不再需要调动到我的物理数据库,我把这个token的字段全部存放到redis当中去啊,专门开放一个空间去管理他,这个阶段呢,它相较于DB这种数据库的形态更好一些,但是还是会有问题啊,因为你token越来越多,我这个空间占用就会越来越大,我这个总要开辟空间去管理所有的,有100万个用户来访问,那我就升成100万个token,而且这个我还不能随便删,token还有个时效性,可能是一个星期,可能是30天,可能是一年,这个时效性存在的时间内,我都不敢删掉他。那么到了这里怎么办呢?他又会占有很多空间,由此我们就做了一个算法啊。一个math数学的算法,这个算法就是当我的token传进来之后,我不再通过缓存数据库,我也不再通过我的数据库,我通过一个算法接收到这个token,我去做一个正向的加密计算,我基于本地,你token这边带过来的其他的这些数据,我生成对应的一个token,我来比对你传过来的token跟我生成的这个token是否一致,如果是一致的,咱们就认为你是成功的,如果不一致,咱们就认为你的token有问题,那就提示你重新登陆。
cookie只是作为一个本地的键值对的文本信息的保存和管理的,用于将服务端这边指定要保存的这些文本信息保存在客户本地的一个机制而已,session就是临时会话,token就是临时身份令牌啊,三者的区别就非常明显了。
token有多种意思:1、作为计算机术语时,是指令牌,是一种能够控制站点占有媒体的特殊帧,以区别数据帧及其他控制帧;
1、作为计算机术语时,是“令牌”的意思
token是计算机术语:令牌,令牌是一种能够控制站点占有媒体的特殊帧,以区别数据帧及其他控制帧。token其实说的更通俗点可以叫暗号,在一些数据传输之前,要先进行暗号的核对,不同的暗号被授权不同的数据操作。基于 Token 的身份验证方法
使用基于 Token 的身份验证方法,在服务端不需要存储用户的登录记录。大概的流程是这样的:
1.客户端使用用户名跟密码请求登录
2.服务端收到请求,去验证用户名与密码
3.验证成功后,服务端会签发一个 Token,再把这个 Token 发送给客户端
4.客户端收到 Token 以后可以把它存储起来,比如放在 Cookie 里或者 Local Storage 里
5.客户端每次向服务端请求资源的时候需要带着服务端签发的 Token
6.服务端收到请求,然后去验证客户端请求里面带着的 Token,如果验证成功,就向客户端返回请求的数据
C库与操作系统POSIX库
参考:https://blog.csdn.net/weixin_47139576/article/details/132484371
C库与posix库
C库(C Standard Library)是一组用于C编程语言的标准函数和宏的集合,旨在为程序员提供常见任务的功能支持。这些函数和宏在C语言标准中定义,并且几乎所有的C编译器都会提供对这些标准库函数的实现。C库提供了许多常见的操作,如字符串处理、内存管理、数学计算等。
POSIX(Portable Operating System Interface)是一组操作系统API的标准,旨在提供操作系统功能的可移植性。这些API涵盖了文件操作、进程管理、线程、信号处理、套接字编程等领域,以确保在不同的操作系统和平台上,应用程序能够以一致的方式进行编程。
C库与POSIX的区别:
范围和领域:
C库是与编程语言本身相关的,提供了通用的函数和宏来支持常见的编程任务。它涵盖了字符串处理、内存管理、数学计算等领域。
POSIX是与操作系统相关的,提供了操作系统功能的可移植性。它涵盖了文件操作、进程管理、线程、信号处理、套接字编程等操作系统层面的功能。
可移植性:
C库函数在几乎所有支持C编程的平台上都有实现,但某些特定的功能可能因平台而异。
POSIX标准旨在提供在不同操作系统之间移植应用程序的一致性。但是,操作系统之间的差异可能会导致某些API的行为略有不同。
目标:
C库旨在为编程任务提供通用功能,无论是在底层的嵌入式系统还是在高级的服务器应用中。
POSIX旨在为开发人员提供在不同操作系统上编写可移植的系统级代码的标准接口。
功能:
C库涵盖了诸如字符串操作(如strlen)、内存分配(如malloc)、文件I/O(如fopen、fprintf)等通用的编程功能。
POSIX涵盖了文件操作(如open、read、write)、进程管理(如fork、exec)、线程(如pthread_create)等系统级的功能。
Posix相关规范
POSIX.1(IEEE 1003.1):
这是最基本的POSIX规范,定义了标准C库函数和系统调用。它包括文件I/O、进程控制、文件和目录操作等。
POSIX.1b(IEEE 1003.1b):
也称为POSIX实时扩展,增加了对实时性和多线程编程的支持,包括实时调度、线程创建、同步和信号量等。
POSIX.1c(IEEE 1003.1c): 这个标准涵盖了 POSIX.1 和 POSIX.1b 中的内容,并加入了国际化支持。
POSIX.1d(IEEE 1003.1d): 这个标准包括了分布式计算环境下的POSIX扩展,但并没有广泛采用。
POSIX.1-2001(IEEE 1003.1-2001): 这是对早期 POSIX.1 标准的修订,加入了一些新特性和更正。
POSIX.1-2008(IEEE 1003.1-2008):
这个标准进一步修订了POSIX.1,引入了新特性和更正,包括一些已经存在但未在之前版本中定义的函数和工具。
POSIX.2(IEEE 1003.2): 这个标准扩展了
POSIX.1,添加了一些额外的实用工具和Shell命令,如awk、sed、make、sh等。
POSIX.4(IEEE 1003.4): 这个标准涵盖了实时操作系统的API,定义了实时调度、时钟和定时器等功能。
POSIX.12(IEEE 1003.12): 这个标准定义了计算机环境中的系统管理命令和工具。
为什么IP数据报使用分片偏移来标识分段,而不直接采用序号
你要理解在什么情况下IP报文会进行分片。IP报文不是在发送方主机上进行分片的,而是在路由器上进行分片。
发送一个IP报文,可能经过多个路由器,两两路由器之间是不同的物理网络,这些物理网络能支持的最大报文长度(MTU)是不同的。当一个较大的报文发送到MTU较小的网络上时,路由器就会对这个报文进行分片。到了下一跳路由器不会立即对分片报文重组,因为后续还有可能经过MTU较小的网络,而是留给接受方主机进行重组。
假设报文分片时用的是序号,一个1500字节的报文发到一个MTU=620的网络上,路由器把它分成3片,序号分别是0、1、2。然后分片报文到达下一个路由器,发现下一段网络MTU=256,需要把0号分片再分成3片。这时就会发现,如果上一跳分片不是连续编号就好了,上一跳序号是0、3、6的话,现在就可以把第0片分成0、1、2三片了。
这样,如果不是用连续的序号表示分片,而是用偏移来表示,就可以完美的解决这个问题。
3G < LTE < 4G 其中 LTE: CAT.M < CAT.1 < CAT.4
3G、4G是通信技术
3GPP是标准制定者
LTE是3G到4G的过渡技术
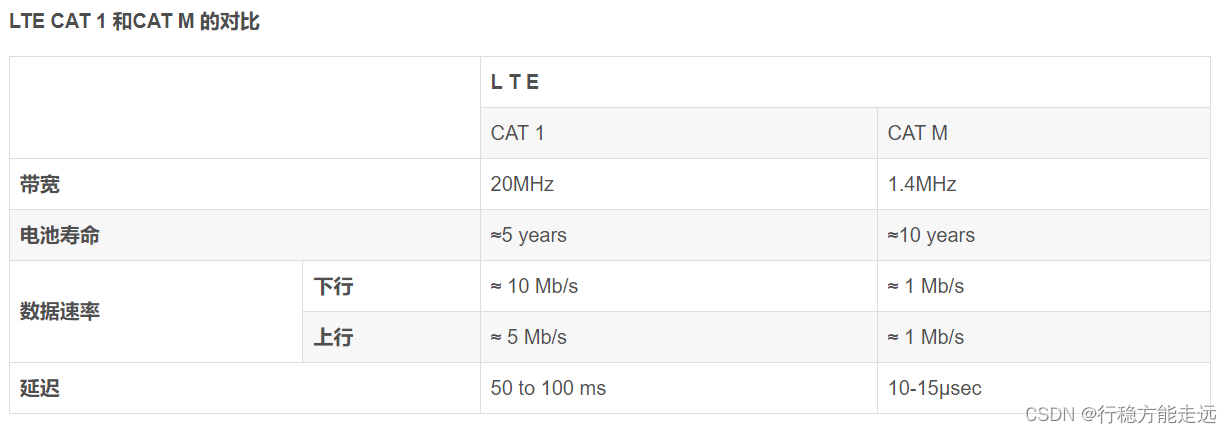
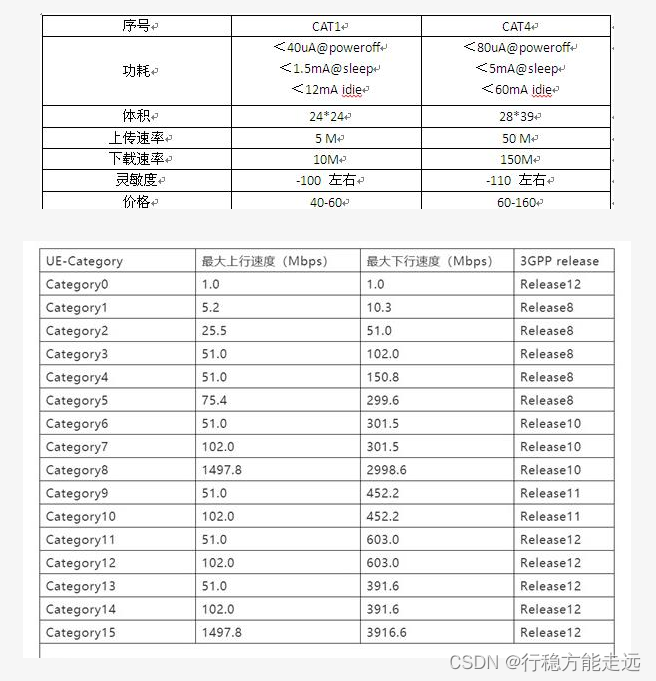
Cat.1、Cat.1与Cat.4参数对比:主要是速率与成本的区别:
Cat.4 和 Cat.1 都是4G通信LTE网络下用户终端类别的一个标准,国内目前不支持CAT.M。
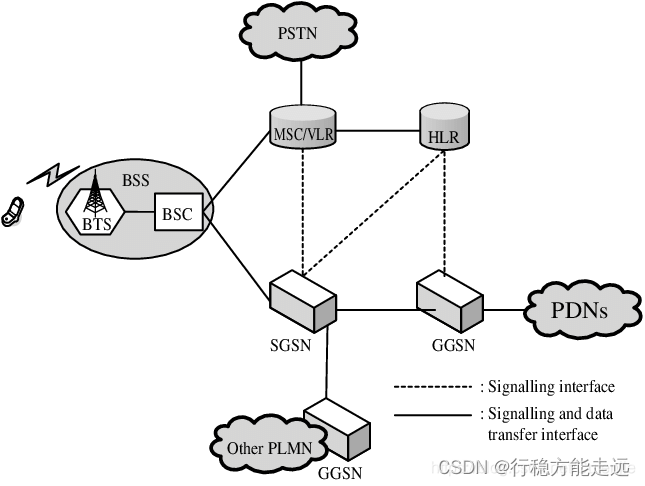
GPRS简介和PDP激活
摘自:物联网-GPRS简介和PDP激活
其他相关博文:
APN PDP PPP解释
GPRS PDP APN
黑莓断网 思考 apn激活pdp整个过程
1. GPRS简介
GPRS(General Packet Radio Service)即通用分组无线服务,是移动电话用户可以使用的一种移动数据业务。
GPRS有别于旧的电路交换连接,在旧的电路交换连接系统中,一个数据连接要创建并保持一个电路连接,在整个连接过程中这条电路将被独占,直到连接被解除。
GPRS基于无线分组交换技术,使多个用户可以共享传输信道,共享带宽。WEB浏览、收发电子邮件和即时消息都是能有效利用共享带宽的间歇传输数据的服务。
2. GPRS的实现原理
GPRS网络是基于现有的GSM网络实现的。在现有的GSM网络中增加一些节点,如GGSN(Gateway GPRS Support Node,GPRS网关支持节点)和SGSN(Serving GSN,GPRS服务支持节点)。GGSN主要是起网关作用,它可以和不同的数据网络连接,如ISDN(综合业务数据网)、LAN(局域网)等。SGSN主要用于记录移动终端的当前位置信息,并且在移动终端和GGSN之间完成移动分组的数据发送与接受。HLR (Home Location Register),是GSM网络中的一个核心网元,其记录着手机用户的签约消息及位置信息。
3. PDP简介
PDP(Packet Data Protocol)即分组数据协议,是GPRS接口所用的网络协议。
PDP上下文包含: APN、QoS、PDP类型、PDP地址等信息。
PDP存在以下几个状态:
- PDP附着
- PDP激活
- PDP更新
- PDP去激活
PDP附着(PDP-Attach)是让终端登录到PS域里,就是登记到SGSN/PDSN的数据库,同时在HLR里进行PS域的location update,此时是control-plane还没有流量,相当于拨号成功。
PDP激活(PDP-activation)就是开始进行数据流通了,也就是开始打开网页上网了,此时有userplane流量了。
4. 移动终端通过GPRS上网过程
移动终端开机连接到运营商上网,主要包括以下三个过程:
(1) PDP附着。附着的目的是系统根据移动终端的签约数据确定是否允许移动终端在当前请求的GPRS路由区域中进行数据业务访问。
终端可以在开机通过无线接入鉴权获得无线信道后即向SGSN发起“附着请求”消息,SGSN得到终端IMSI标识后,向HLR中请求进行认证,并根据HLR下达的用户签约数据对终端进行鉴权,同时SGSN将终端的当前位置信息上传HLR。鉴权通过后,SGSN就会向终端返回“接受附着”消息。
(2)PDP上下文激活。通过PDP上下文激活过程,用户获得相应的GGSN的鉴权许可,分配相应的IP地址,建立终端与基于GPRS的数据通道。PDP激活过程由用户终端发起,终端首先向SGSN发起“激活PDP上下文请求”消息,消息中携带APN(服务访问点名称),服务质量等信息;SGSN根据消息中携带的APN向HLR中查寻相应的GGSN的地址,获得GGSN地址后,再向GGSN发送“创建PDP上下文请求”;GGSN可以通过本地/DHCP/RADIUS对终端进行签权并分配IP地址或者地址前缀,以及其他参数,如QoS参数等,并将鉴权结果以及各项参数携带在“响应创建PDP上下文请求”消息中,发送给SGSN,由SGSN再向终端发送“接受激活PDP上下文请求”消息,将各参数配置传递给用户终端,从而完成PDP激活过程。
注:
APN指一种网络接入技术,是通过手机上网时必须配置的一个参数,它决定了手机通过哪种接入方式来访问网络,用来标识GPRS的业务种类。
APN分为两大类:
- WAP业务
- WAP以外的服务,比如:连接因特网
(3)业务访问。在PDP激活之后,从终端到系统分组域的IP应用数据通道已经打开。如果终端访问系统外的业务服务器,就需要保持系统分组域与外部网络直到业务服务器之间的转发路径通畅。















 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











