






CUDA sample中0_Introduction里包含CUDA基础的sample,clock这个sample展示了如何使用 clock() 函数来准确地衡量kernel中一组block的性能。Blocks是并行执行且无序执行的。由于blocks之间没有同步机制, 我们会测量每个block的时钟。
这个sample中有一些注释,注释中说明通过调整block的数量和线程的数量, 如何来保持GPU硬件的忙碌状态。
注释中给出了开发在G80 GPU上的一些测试数据:
当block数为1时,花费3096个时钟周期
当block数为8时,花费3232个时钟周期
当block数为16时,花费3364个时钟周期
当block数为32时,花费4615个时钟周期
当block数为64时,花费9981个时钟周期
从这些数据可以看出:
当block数小于16时,一些多处理器处于空闲状态,无法充分利用硬件资源。
当block数大于16时,可以充分利用所有多处理器,但每个多处理器只有一个block,无法掩盖内存访问延迟。
当block数大于32时,性能呈线性提升,这样可以更好地隐藏内存访问延迟。
总之,通过调整block和线程的数量,可以更好地利用GPU硬件资源,从而提高程序的性能。
// System includes
#include <assert.h>
#include <stdint.h>
#include <stdio.h>
// CUDA runtime
#include <cuda_runtime.h>
// helper functions and utilities to work with CUDA
#include <helper_cuda.h>
#include <helper_functions.h>
// This kernel computes a standard parallel reduction and evaluates the
// time it takes to do that for each block. The timing results are stored
// in device memory.
__global__ static void timedReduction(const float *input, float *output,
clock_t *timer) {
// __shared__ float shared[2 * blockDim.x];
extern __shared__ float shared[];
const int tid = threadIdx.x;
const int bid = blockIdx.x;
if (tid == 0) timer[bid] = clock();
// Copy input.
shared[tid] = input[tid];
shared[tid + blockDim.x] = input[tid + blockDim.x];
// Perform reduction to find minimum.
for (int d = blockDim.x; d > 0; d /= 2) {
__syncthreads();
if (tid < d) {
float f0 = shared[tid];
float f1 = shared[tid + d];
if (f1 < f0) {
shared[tid] = f1;
}
}
}
// Write result.
if (tid == 0) output[bid] = shared[0];
__syncthreads();
if (tid == 0) timer[bid + gridDim.x] = clock();
}
#define NUM_BLOCKS 64
#define NUM_THREADS 256
int main(int argc, char **argv) {
printf("CUDA Clock sample\n");
// This will pick the best possible CUDA capable device
int dev = findCudaDevice(argc, (const char **)argv);
float *dinput = NULL;
float *doutput = NULL;
clock_t *dtimer = NULL;
clock_t timer[NUM_BLOCKS * 2];
float input[NUM_THREADS * 2];
for (int i = 0; i < NUM_THREADS * 2; i++) {
input[i] = (float)i;
}
checkCudaErrors(
cudaMalloc((void **)&dinput, sizeof(float) * NUM_THREADS * 2));
checkCudaErrors(cudaMalloc((void **)&doutput, sizeof(float) * NUM_BLOCKS));
checkCudaErrors(
cudaMalloc((void **)&dtimer, sizeof(clock_t) * NUM_BLOCKS * 2));
checkCudaErrors(cudaMemcpy(dinput, input, sizeof(float) * NUM_THREADS * 2,
cudaMemcpyHostToDevice));
timedReduction<<<NUM_BLOCKS, NUM_THREADS, sizeof(float) * 2 * NUM_THREADS>>>(
dinput, doutput, dtimer);
checkCudaErrors(cudaMemcpy(timer, dtimer, sizeof(clock_t) * NUM_BLOCKS * 2,
cudaMemcpyDeviceToHost));
checkCudaErrors(cudaFree(dinput));
checkCudaErrors(cudaFree(doutput));
checkCudaErrors(cudaFree(dtimer));
long double avgElapsedClocks = 0;
for (int i = 0; i < NUM_BLOCKS; i++) {
avgElapsedClocks += (long double)(timer[i + NUM_BLOCKS] - timer[i]);
}
avgElapsedClocks = avgElapsedClocks / NUM_BLOCKS;
printf("Average clocks/block = %Lf\n", avgElapsedClocks);
return EXIT_SUCCESS;
}
归约
在CUDA内核中实现"归约(reduction)"操作来查找最小值的两种方法:顺序归约和并行归约。
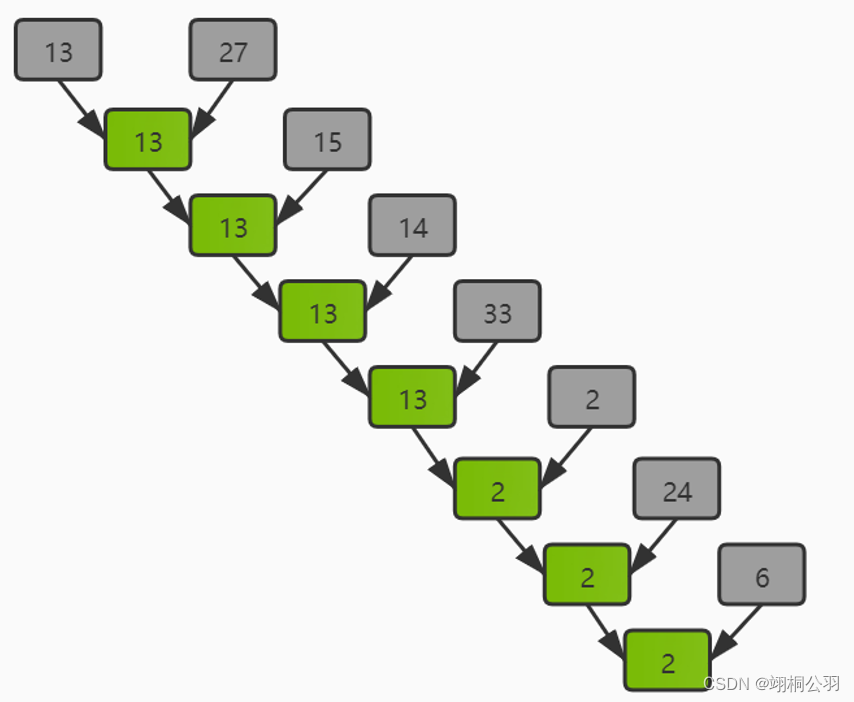
顺序归约:
- 每个线程读取一个数据元素,并将其存储在共享内存中。
- 线程以串行方式逐步合并数据,直到得到最终的最小值。
- 最终的最小值被写回到全局内存中。
这种方法简单直观,但效率较低,因为线程必须串行执行归约操作。具体执行过程见下图:
并行归约:
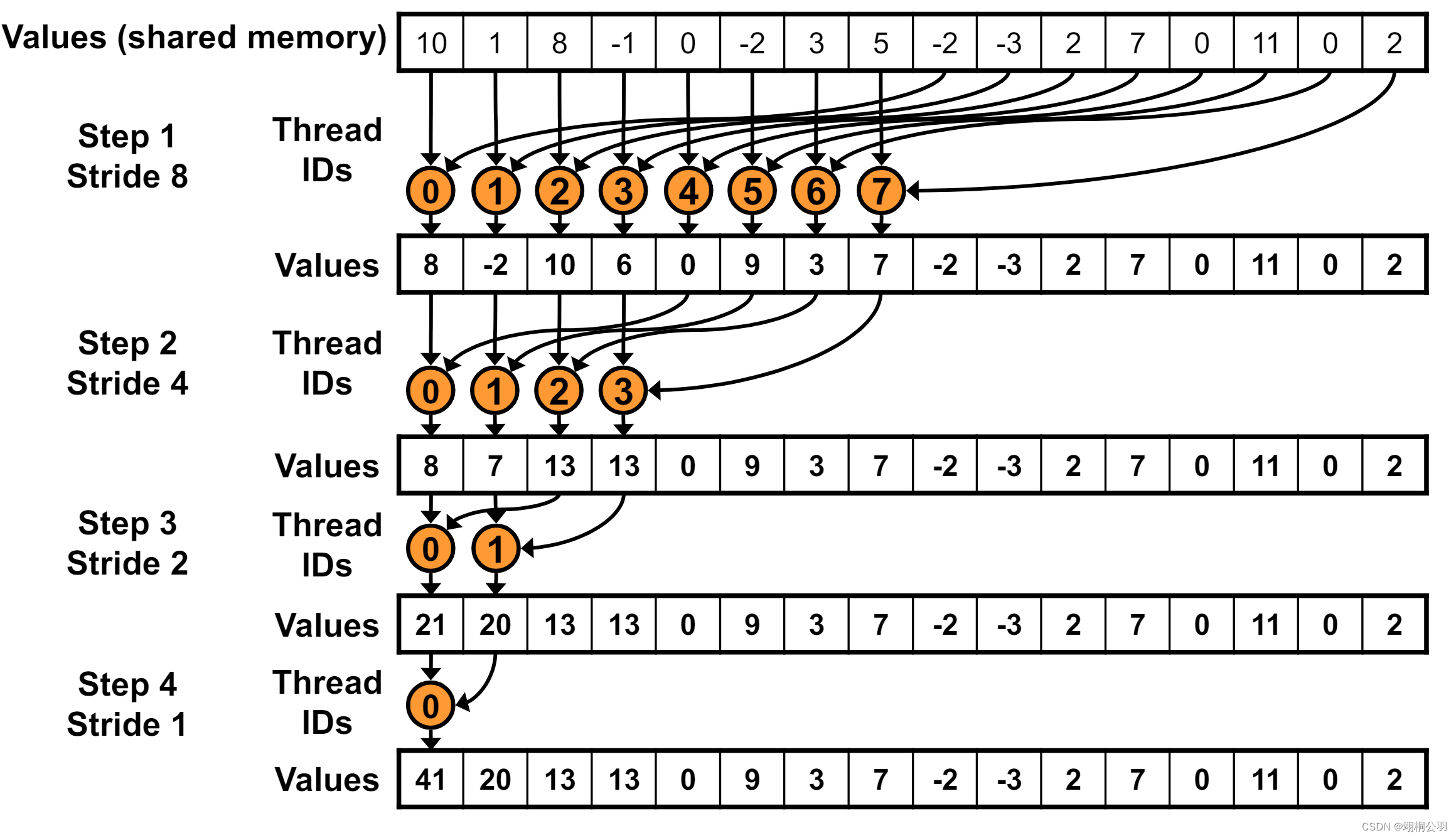
- 每个线程读取一组数据元素,并将其存储在共享内存中。
- 线程以并行方式进行多轮归约操作,每轮将第i个和第i+threadnum个值进行比较并将较小的值保留在shared memory中。
- 每轮归约后,active线程数量减半。
- 最终得到的最小值被写回到全局内存中。
这种并行归约方法可以充分利用GPU的并行计算能力,效率更高。关键在于巧妙地组织线程合作,通过多轮并行比较来快速找到最终的最小值。下图是并行归约的图例:
总之,这两种方法展示了在CUDA内核中实现归约操作的不同思路,可以根据具体需求选择合适的方法。核心代码如下,每次比较前需要进行__syncthreads():
shared[tid] = input[tid];
shared[tid + blockDim.x] = input[tid + blockDim.x];
// Perform reduction to find minimum.
for (int d = blockDim.x; d > 0; d /= 2) {
__syncthreads();
if (tid < d) {
float f0 = shared[tid];
float f1 = shared[tid + d];
if (f1 < f0) {
shared[tid] = f1;
}
}
}Kernel解读
这个kernel执行一个标准的并行化归约(parallel reduction)操作,并且评估每个block的执行时间。时间测量结果被存储在设备内存中。在kernel中, 首先在第一个线程中使用clock()记录当前时钟值到timer数组中。
if (tid == 0) timer[bid] = clock();
然后通过归约查找最小值。接着在最后一个线程中再次记录时钟值。
if (tid == 0) timer[bid + gridDim.x] = clock();
这样在Main中时间相减可以获取每个block的时间:
timer[i + NUM_BLOCKS] - timer[i]
Main函数
-
在main中,首先分配所需的设备内存,并将输入数据拷贝到设备内存中。然后启动内核函数,并将执行时间从设备内存拷贝回主机内存。
-
最后计算每个block的平均执行时钟数,并打印出来,用这个值来衡量kernel的性能。
for (int i = 0; i < NUM_BLOCKS; i++) {
avgElapsedClocks += (long double)(timer[i + NUM_BLOCKS] - timer[i]);
}
avgElapsedClocks = avgElapsedClocks / NUM_BLOCKS;
printf("Average clocks/block = %Lf\n", avgElapsedClocks);运行结果:
#define NUM_BLOCKS 64
测试结果如下:
CUDA Clock sample
GPU Device 0: "Ada" with compute capability 8.9
Average clocks/block = 21373.421875#define NUM_BLOCKS 65535
测试结果如下:
CUDA Clock sample
GPU Device 0: "Ada" with compute capability 8.9
Average clocks/block = 26153.397559可以看出性能有所提升。















 2036
2036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









