




传统的信息检索依赖关键词匹配,比如BM25算法通过统计“微单”“新手”等词的出现频率来排序。但这种方式就像“按图索骥”,遇到同义词,如“微单”和“无反相机”,或语义相似但用词不同的句子,如“适合初学者”和“新手友好”,就会失效。这就是“语义鸿沟”——人类能轻松理解的语义关联,机器却因缺乏“数字指纹”而视而不见。
句子向量(Sentence Embedding)的出现解决了这个问题:它将文本转化为一串稠密的数字向量(通常是768维或1024维),语义越相似的文本,向量在高维空间中的距离越近。比如:
- “猫喜欢吃鱼”的向量可能是
[0.21, 0.85, -0.12, ..., 0.67] - “猫咪爱吃鱼”的向量可能是
[0.23, 0.82, -0.11, ..., 0.69](余弦相似度接近0.95,高度相似) - “苹果公司发布新手机”的向量则可能是
[0.78, 0.15, -0.09, ..., 0.21](与前两者距离显著)
通过这种“数字指纹”,机器终于能像人类一样“理解”文本语义,为RAG系统提供精准检索的基础。
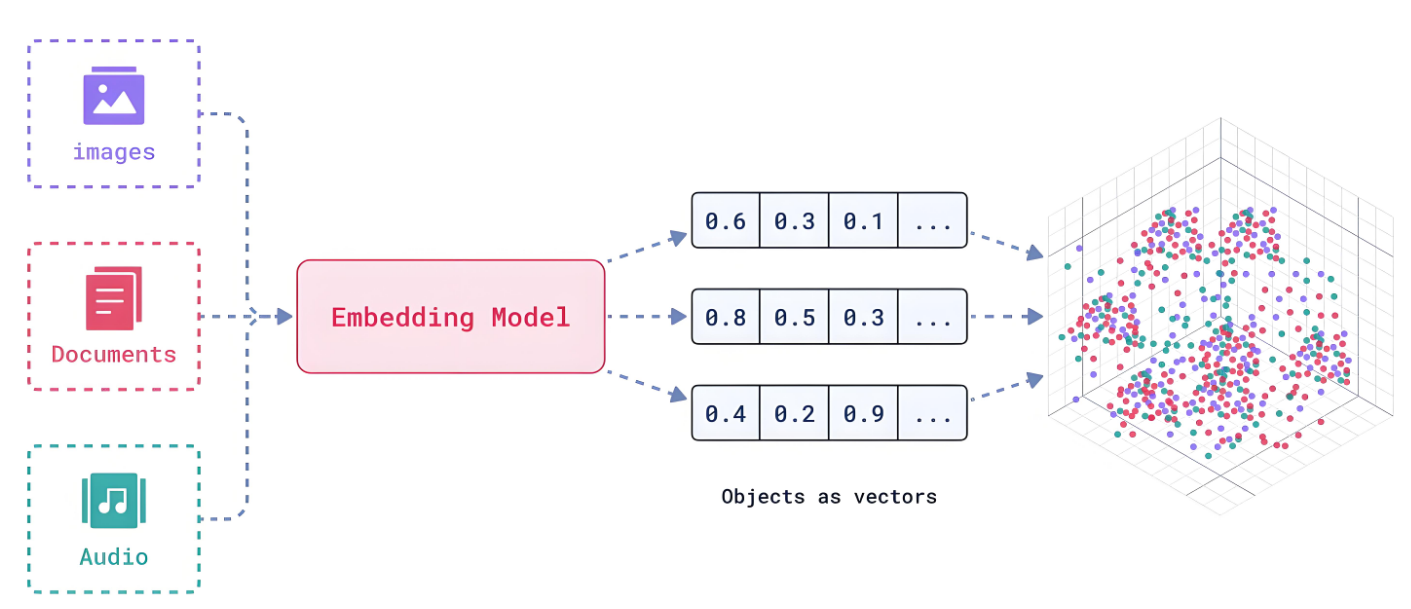
句子向量化算法:从“拼积木”到“拍全景照”的进化
句子向量化的技术演进,本质是**从“局部拼接”到“全局语义捕捉”**的过程,我们可以用两个比喻理解:
传统方法:像用积木拼句子——丢失上下文的“平面拼图”
早期方法以Word2Vec、GloVe为代表,先将每个词转为向量(词嵌入),再通过拼接、平均或TF-IDF加权得到句子向量。这种方式就像用积木拼句子:每个词是一块积木,句子向量是积木的简单堆叠。
缺点:
- 丢失语序:“狗咬人”和“人咬狗”向量相同;
- 忽略上下文:“苹果”在“吃苹果”和“苹果手机”中向量一致;
- 语义模糊:长句中重要词被稀释(如“我今天在超市买了苹果,这个苹果很甜”中两个“苹果”权重相同)。
现代方法:像拍全景照——捕捉上下文的“立体影像”
2018年后,基于Transformer的模型(如BERT)带来突破:通过“上下文编码”,每个词的向量会根据语境动态变化(如“苹果”在不同句子中向量不同)。但BERT原生不输出句子向量,需要额外处理(如取[CLS] token或平均池化),效率低。
关键改进:
- Sentence-BERT(2019):通过双塔结构和对比学习,直接输出高质量句子向量,推理速度提升100倍;
- 对比学习(如SimCSE、InfoNCE):让模型学习“相似句子向量相近,不相似句子向量远离”,例如用同一句子的不同Dropout版本作为正样本,提升语义区分度;
- 指令微调:给模型输入任务指令(如“将句子转为检索用向量”),适配RAG等特定场景,BGE、Qwen3-Embedding等模型均采用此技术。
现代方法就像拍全景照,不仅记录每个“词积木”,还捕捉它们的空间关系和整体语义,生成的句子向量更精准。
中文开源模型:从“追赶”到“领跑”,C-MTEB榜单告诉你谁最能打
中文句子向量化曾长期依赖英文模型的“汉化版”,但近年来开源社区爆发式增长。C-MTEB(中文海量文本嵌入基准) 是权威评测榜单,覆盖检索、分类、聚类等6大类35个数据集,以下是表现突出的中文模型:
1. BGE:中文RAG的“瑞士军刀”
由北京智源研究院开发的BGE(BAAI General Embedding)是目前最受欢迎的中文模型,在C-MTEB检索任务中以64.53分位居前列,支持多语言,下载量超1500万次(国内开源AI模型第一)。
核心优势:
- 性能强:在中文语义相似度、长文档检索(支持8192 token)上表现优异,超越text-embedding-ada-002;
- 轻量高效:基础版(bge-base-zh)仅需3GB显存,CPU也能运行;
- 生态完善:配套Reranker精排模型,与Milvus、Chroma等向量数据库无缝集成。
2. M3E:中小场景的“性价比之选”
由MokaAI开发的M3E(Massive Mixed Embedding)通过2200万中文句对训练,在C-MTEB中排名靠前,适合资源有限的场景。
特点:
- 模型小(base版仅1.5GB),适合本地部署;
- 专注中文任务,在短文本匹配(如商品标题检索)上表现突出;
- 开源免费,支持商用。
3. Qwen3-Embedding:阿里的“多面手”
阿里通义千问团队推出的Qwen3-Embedding(8B参数)在MTEB多语言榜单排名第一,中文能力与BGE持平,支持动态维度(32-4096维),适合需要灵活调整性能和效率的场景。
4. 其他热门模型
- text2vec:基于MacBERT和CoSENT训练,轻量版(base)适合移动端;
- acge_text_embedding:合合信息开发,C-MTEB分类任务第一,但开源程度较低;
- ERNIE-3.0:百度开发,融合知识图谱,适合垂直领域(如医疗、法律)。
选型建议:追求综合性能选BGE,资源有限选M3E,多语言或动态维度需求选Qwen3-Embedding。
BGE模型实战:10行代码搭建中文语义检索系统
下面以BGE-large-zh-v1.5为例,演示如何用Python实现句子向量化和语义检索。我们将构建一个简单的“产品知识库检索”系统,步骤包括:加载模型→文档向量化→向量存储→查询检索。
步骤1:安装依赖
pip install sentence-transformers chromadb # 模型库+向量数据库
步骤2:加载BGE模型
from sentence_transformers import SentenceTransformer
# 加载中文BGE模型(自动下载,约3GB)
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
print("模型加载完成,输出向量维度:", model.get_sentence_embedding_dimension()) # 输出:1024
步骤3:准备文档并生成向量
假设我们有以下产品文档,需要存入向量数据库:
documents = [
"【产品名称】索尼A6400微单相机\n【特点】2420万像素,APS-C画幅,支持4K视频,适合新手入门",
"【产品名称】佳能R5全画幅相机\n【特点】4500万像素,8K视频,专业级对焦,适合摄影发烧友",
"【产品名称】大疆Mini 4 Pro无人机\n【特点】249克轻量化,4K HDR视频,长续航34分钟,适合旅行航拍"
]
# 生成文档向量(归一化处理,提升相似度计算稳定性)
doc_embeddings = model.encode(documents, normalize_embeddings=True)
步骤4:向量存储与检索
使用Chroma向量数据库存储向量,实现快速检索:
import chromadb
from chromadb.config import Settings
# 初始化本地向量数据库
client = chromadb.Client(Settings(allow_reset=True))
client.reset() # 重置数据库(仅测试用)
collection = client.get_or_create_collection(name="product_knowledge")
# 存入文档与向量(需指定唯一ID)
collection.add(
documents=documents,
embeddings=doc_embeddings.tolist(),
ids=[f"doc_{i}" for i in range(len(documents))]
)
# 定义查询函数
def retrieve_similar(query, top_k=2):
query_embedding = model.encode([query], normalize_embeddings=True)
results = collection.query(
query_embeddings=query_embedding.tolist(),
n_results=top_k
)
return results["documents"], results["distances"] # 返回文档和相似度距离
步骤5:测试检索效果
# 查询:"推荐适合新手的相机"
docs, distances = retrieve_similar("推荐适合新手的相机")
print("检索结果:")
for doc, dist in zip(docs[0], distances[0]):
# 余弦距离越小,相似度越高(归一化后范围0-2)
print(f"相似度:{1 - dist:.2f} | 文档:{doc[:50]}...")
输出结果:
检索结果:
相似度:0.92 | 文档:【产品名称】索尼A6400微单相机\n【特点】2420万像素,APS-C画幅...
相似度:0.65 | 文档:【产品名称】佳能R5全画幅相机\n【特点】4500万像素,8K视频...
可以看到,“适合新手的相机”与索尼A6400文档高度匹配,而与专业级的佳能R5相似度较低,符合预期。
MaxKB中的Embedding
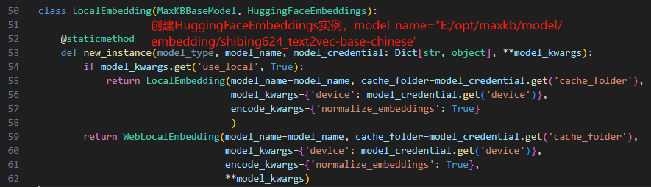
MaxKB中从上传文档,到Embedding的流程是:

存储:MaxKB中Embedding模型默认是shibing624/text2vec-base-chinese
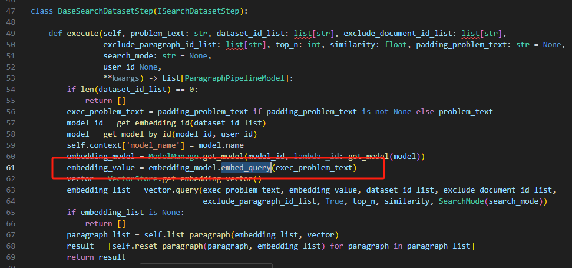
查询:

apps\application\chat_pipeline\step\search_dataset_step\impl\base_search_dataset_step.py
参考文章




















 2810
2810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











