







1. Spark Streaming本质
官网URL:
http://spark.apache.org/docs/latest/streaming-programming-guide.html
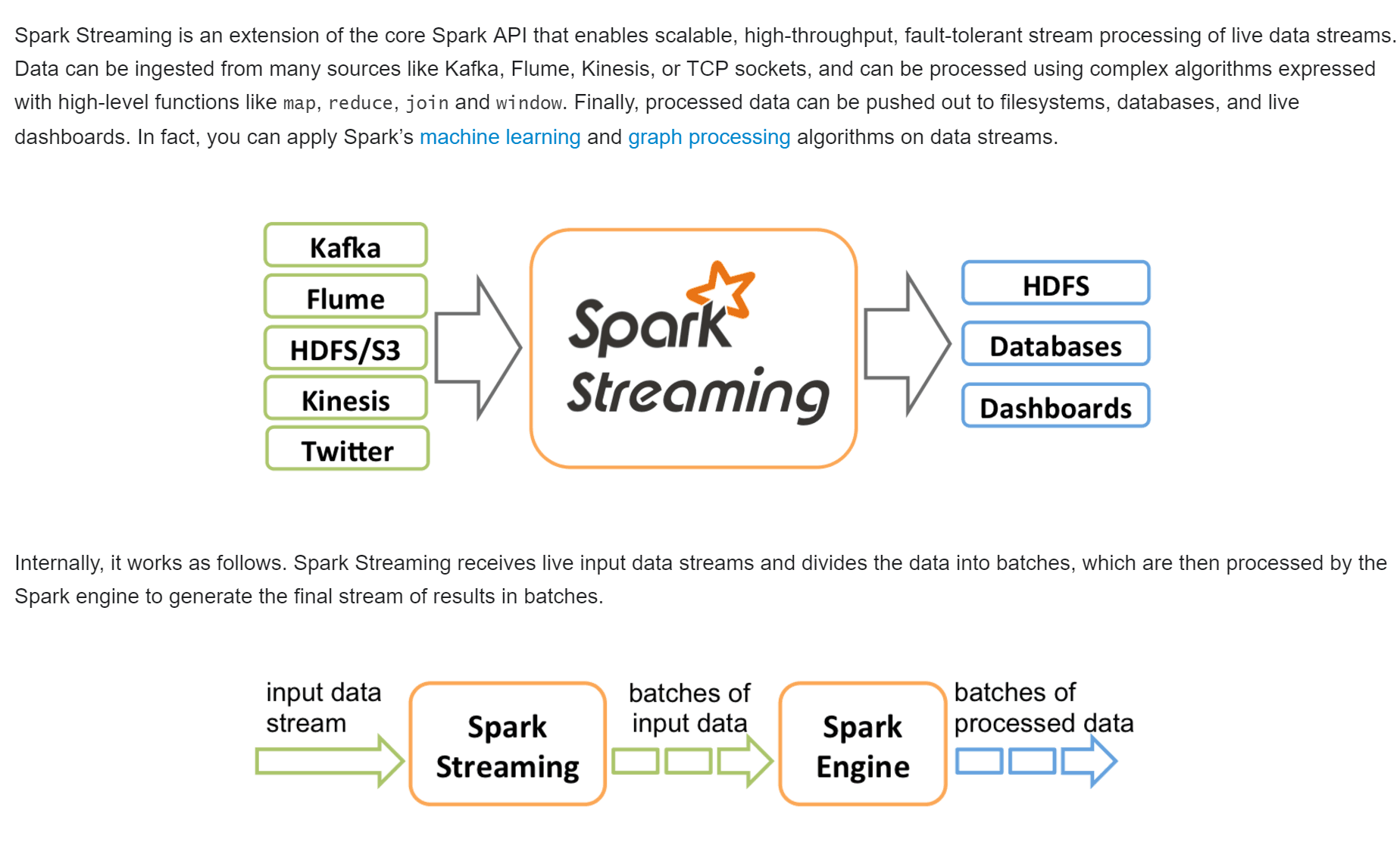
流处理作为一个处理引擎,一定有输入数据和输出数据,也就是:Input和Output,在Spark2.0是Input Table、Output Table。
1.1 输入数据源:
流处理的数据来源可以是:
- Kafka(90%把它作为输入数据来源)
- Flume
- HDFS/S3
- Kinesis( 是Amazon 的一种云服务,可以通过Kinesis实时收集并处理数据)
1.2 流处理:
Spark Streaming作为流处理处理引擎,会根据输入数据来源发生Computation。
计算是针对具体的代码业务逻辑,Spark Streaming的流处理是基于时间间隔(Batch Interval)进行的批处理。时间在不断流逝,按指定间隔的时间单位进行数据处理,期间数据不断流进来,但是在指定间隔的时间内,处理的数据是不变的,跟RDD数据不变性原则是一致的。
Spark Streaming的流处理就是不断进行的批处理,加上了时间维度,一个批处理结束之后,继续下一个批处理。在一个时间间隔内接收了多少数据,就处理多少数据。
1.3 输出数据
流出输出结果可以保持于:
- HDFS
- Databases
- Dashboards(仪表盘)
2. NetworkWordCount示例
网络单词统计,该示例为官方自带示例:
http://spark.apache.org/docs/latest/streaming-programming-guide.html#setting-the-right-batch-interval
Before we go into the details of how to write your own Spark Streaming program, let’s take a quick look at what a simple Spark Streaming program looks like. Let’s say we want to count the number of words in text data received from a data server listening on a TCP socket. All you need to do is as follows.
package org.apache.spark.examples.streaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
*
* Usage: NetworkWordCount <hostname> <port>
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
*
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999`
*/
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}运行示例:
1)在TERMINAL 1运行NetCat:
$ nc -lk 9999
…
hello world
…
2)在TERMINAL 2执行示例Job
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
…
=================
Time: 1357008430000 ms
=================
(hello,1)
(world,1)
…
3)代码解读
根据应用程序和可用的群集资源的延迟要求,必须设置批处理间隔。本示例中batch interval设置为1秒。
Advanced Sources:
- Kafka
- Flume
- Kinesis
3. Discretized Streams (DStreams)
Spark Streaming提供的基本抽象,内部由一系列连续的RDD表示,每个RDD包含了一个时间间隔的数据,如下图所示:

任何应用于DSream上的操作会转换成在底层的RDD上的操作。flatMap作用于每个lines DStream下的RDD上,然后生成words DStream下的RDD,例如下图所示:
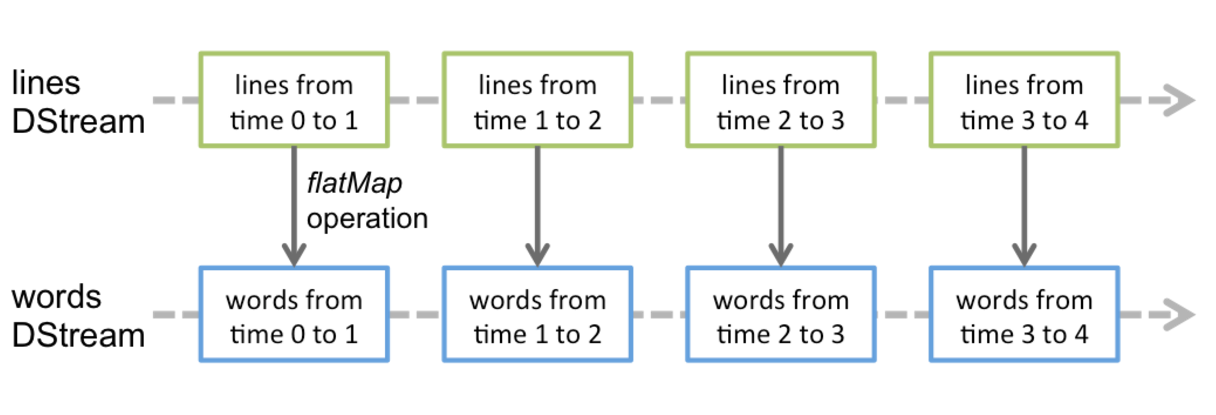
底层的RDD transformations操作被Spark engine操作,DStream操作隐藏了这些细节,提供了开发者更高级别的API,使开发更加便捷。
4. Input DStreams and Receivers
每一个input DStream(除了file stream)会和Receiver相关联,Receiver接收数据并把它存储在Spark的内存中以供计算。
Spark Streaming provides two categories of built-in streaming sources.
- Basic sources:
Sources directly available in the StreamingContext API. Examples: file systems, and socket connections. - Advanced sources:
Sources like Kafka, Flume, Kinesis, etc. are available through extra utility classes. These require linking against extra dependencies as discussed in the linking section.
在一个streaming application中,可以创建多个input DStreams,来并行的接收多个流数据。这样会创建多个receivers同时接收数据流。需要注意的是一个Worker/executor是一个长期运行的task,于是它占有一个core,因此要记得分配足够的cores(如果是local模式,就是线程)
注意:
local模式下,不要使用”local”或者”local[1]”作为master URL,否则会只有一个线程被用来running task locally。如果使用了一个基于receiver(e.g. sockets,kafka,flume,etc.)的input DStream,那么这个单线程会用来运行receiver,就没有线程用来运行处理received data的程序,所以一般使用”local[n]” as the master URL,n大于需要运行的receivers的数量!
同样的,运行在集群上时cores的数量必须大于receivers的数量,否则系统只会接受数据,不会处理数据。
4.1 Basic Sources
We have already taken a look at the ssc.socketTextStream(…) in the quick example which creates a DStream from text data received over a TCP socket connection. Besides sockets, the StreamingContext API provides methods for creating DStreams from files as input sources.
1) File Streams
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)Spark Streaming will monitor the directory dataDirectory and process any files created in that directory (files written in nested directories not supported). Note that
- The files must have the same data format.
- The files must be created in the dataDirectory by atomically moving or renaming them into the data directory.
- Once moved, the files must not be changed. So if the files are being continuously appended, the new data will not be read.
For simple text files, there is an easier method streamingContext.textFileStream(dataDirectory). And file streams do not require running a receiver, hence does not require allocating cores.
2) Streams based on Custom Receivers:
DStreams can be created with data streams received through custom receivers. See the Custom Receiver Guide and DStream Akka for more details.
3) Queue of RDDs as a Stream:
For testing a Spark Streaming application with test data, one can also create a DStream based on a queue of RDDs, using streamingContext.queueStream(queueOfRDDs). Each RDD pushed into the queue will be treated as a batch of data in the DStream, and processed like a stream.
4.2 Advanced Sources
Some of these advanced sources are as follows.
- Kafka、
- Flume、
- Kinesis
不能在Spark shell中测试,除非下载相关的依赖包,并且加到classpath中。
4.3 Custom Sources
Input DStreams can also be created out of custom data sources. All you have to do is implement a user-defined receiver (see next section to understand what that is) that can receive data from the custom sources and push it into Spark. See the Custom Receiver Guide for details.
4.4 Transformations on DStreams
Similar to that of RDDs, transformations allow the data from the input DStream to be modified. DStreams support many of the transformations available on normal Spark RDD’s. Some of the common ones are as follows.
- map
- flatMap
- repartition
- ……
- updateStateByKey
- transform
其中,updateStateByKey 和 transform更值得详细谈论。
4.5 Transformations on DStreams
Spark Streaming还提供了窗口的计算,它允许你请求变换一个滑动窗口的数据。下图说明了这个滑动窗口。
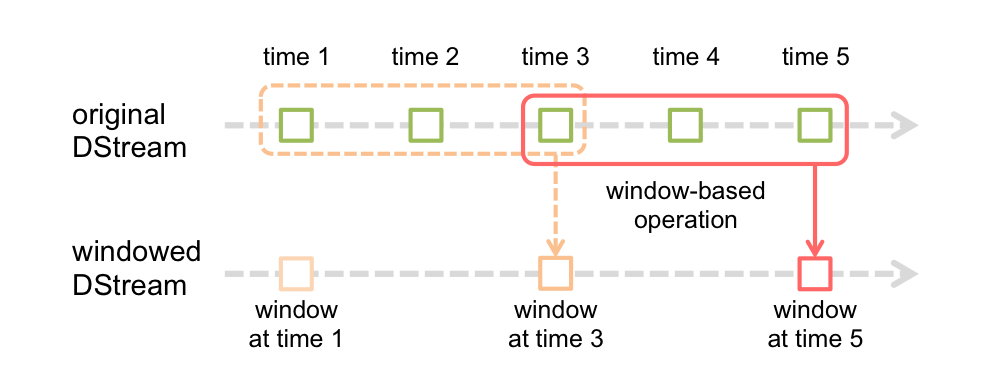
如图所示,每次窗口在源DStream上滑动,合并和操作落入窗内的源RDDs,产生窗口化的DStream的RDDs。
在这个具体示例中,操作被应用在最近3个时间单位的数据上,并且每2个时间单位滑动一次。这表明,任何窗口操作都需要指定两个参数。
- 窗口长度:窗口的持续时间(图上是3).
- 滑动的时间间隔:窗口操作执行的时间间隔 (图上是2).
5. Output Operations on DStreams

8、Structured Streaming本质
Input Table 和 Output Table
Output Table
Structured Streaming预计在Spark 2.3的时候成熟















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









