







1、准备
1)、安装scala(略)
2)、安装mesos,参见
《mesos 1.1.0集群搭建》
2、安装
2、安装
# mkdir /usr/local/spark
# cd /usr/local/spark
# wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.7.tgz
# tar -zxvf spark-2.0.1-bin-hadoop2.7.tgz
# cd /usr/local/spark/spark-2.0.1-bin-hadoop2.7/conf
# cat spark-defaults.conf.template > spark-defaults.conf
# vim spark-defaults.conf
spark.io.compression.codec lzf
# cat spark-env.sh.template > spark-env.sh
# vim spark-env.sh
export MESOS_NATIVE_JAVA_LIBRARY=/usr/local/mesos/mesos/lib/libmesos.so
export SPARK_EXECUTOR_URI=/usr/local/spark/spark.tar.gz
#export SPARK_EXECUTOR_URI=hdfs://spark.tar.gz
3、启动
# cd cd /usr/local/spark/spark-2.0.1-bin-hadoop2.7/sbin
# ./start-mesos-dispatcher.sh --master mesos://192.168.30.97:5050#cd /usr/local/spark/spark-2.0.1-bin-hadoop2.7/bin
#./spark-shell --master mesos://192.168.30.97:5050
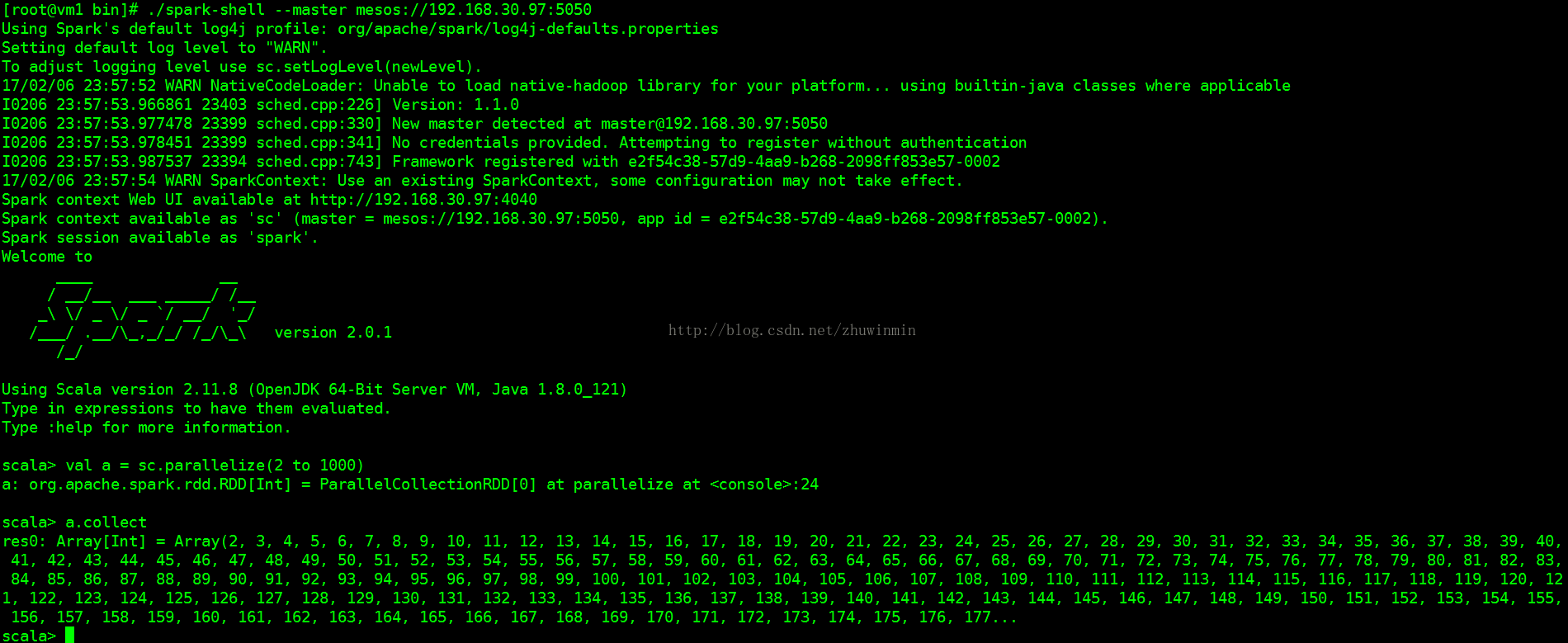
scala> val a = sc.parallelize(2 to 1000)
scala> a.collect



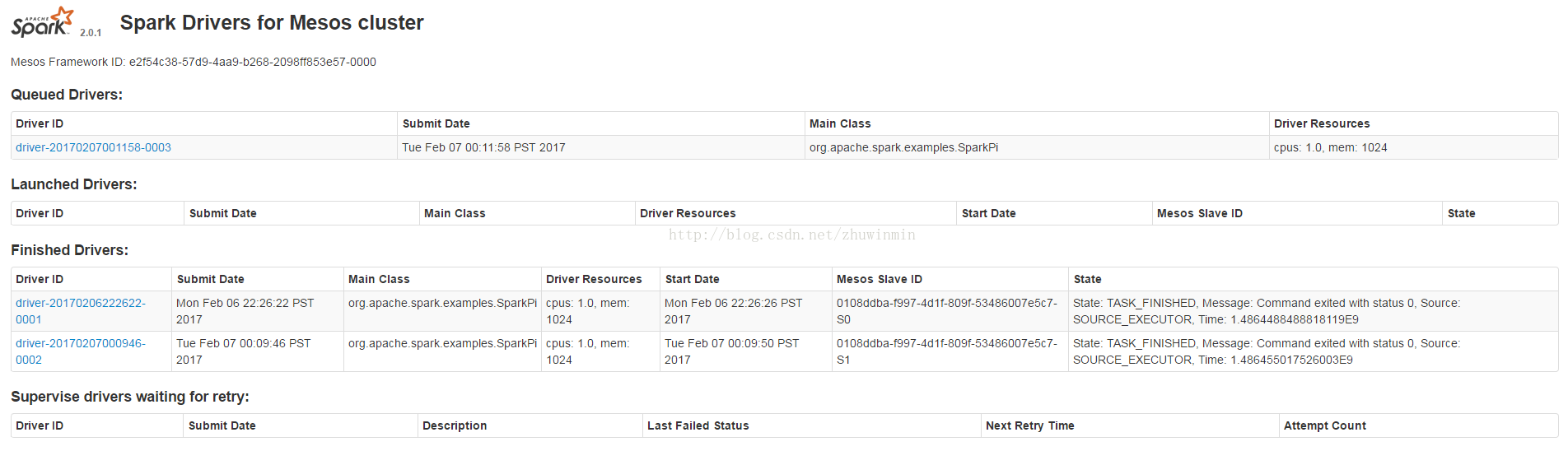
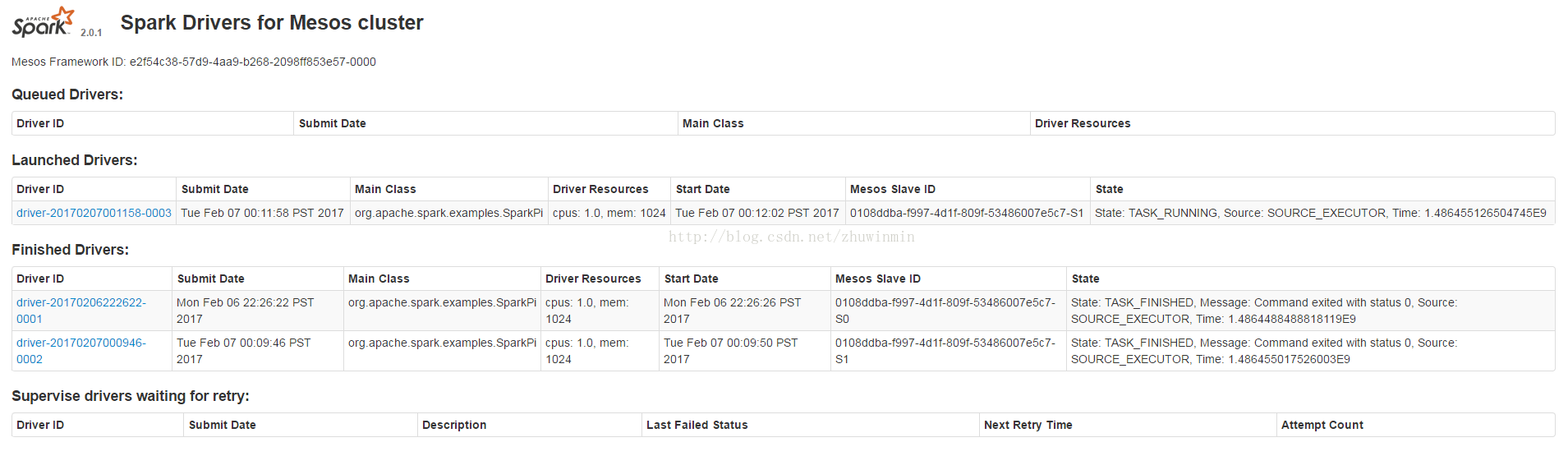
可以看到在tasks、frameworks、agents中分配到资源了(动态分配的,如果是在排队中,则没有分配到资源)。
#./spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://192.168.30.97:7077 \
--deploy-mode cluster \
/usr/local/spark/spark-2.0.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.0.1.jar \
100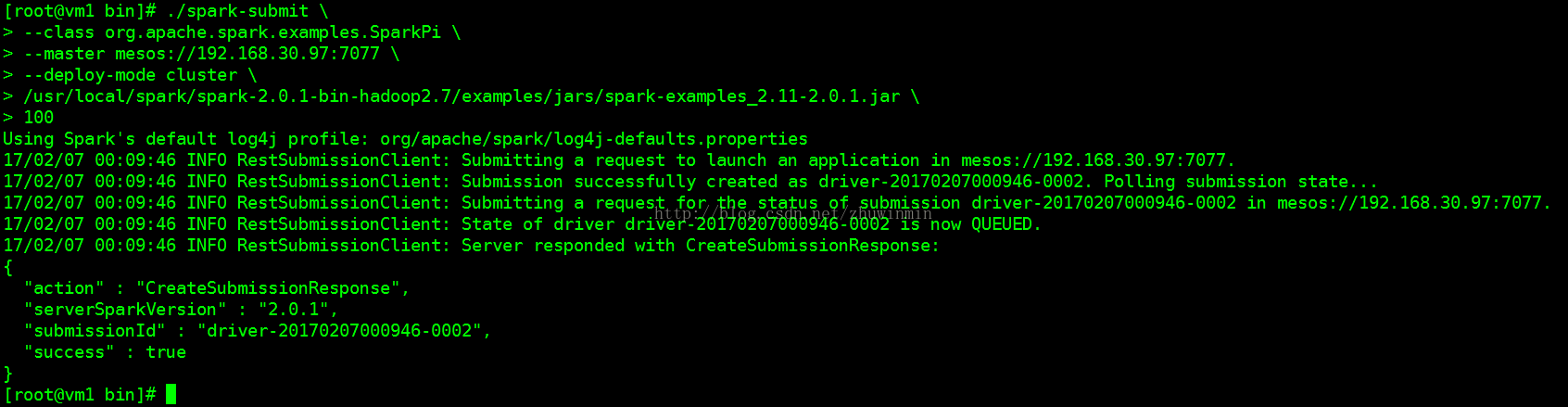















 4746
4746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









