







MapReduce
1. 首先了解MapReduce的功能:一个分布式系统(Distribute System)是用来处理大计算量的数据,即当计算量在一台计算机无法处理的情况下,就通过把整个计算过程分成很多个小的计算块,通过Master分派给分布式系统中集群的Cluster,Cluster计算完成后结果返回给Master,如此迭代;在Hadoop模型中MapReduce即为实现.
MapReduce in MR v2执行流程:
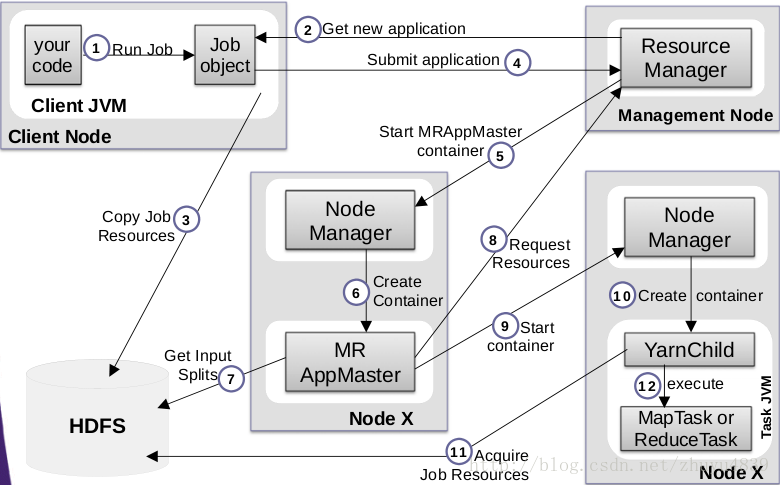
2. MapReduce in MR v2
先来看一下如下代码(文本文件使用空格分词,统计每个分词出现的次数):
public class MapClass extends Mapper<Object, Text, Text, IntWritable> {
private Text record = new Text();
private static final IntWritable recbytes = new IntWritable(1);
/**
* Construct of this class.
*/
public MapClass() {
System.out.println("mapper instance....");
}
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
// 没有配置 RecordReader,所以默认采用 line 的实现,
// key 就是行号,value 就是行内容,
if (line == null || line.equals(""))
return;
String[] words = line.split("\\s+");
for (int i = 0; i < words.length; i++) {
record.clear();
record.set(words[i]);
context.write(record, recbytes);
}
}
}
private IntWritable result = new IntWritable();
/**
* Construct of this class.
*/
public ReduceClass() {
System.out.println("reducer instance....");
}
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int tmp = 0;
for (IntWritable val : values) {
tmp = tmp + val.get();
}
result.set(tmp);
context.write(key, result);// 输出最后的汇总结果
}
} public class LogAnalysiser {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
if (args == null || args.length < 4) {
System.out.println("need inputpath and outputpath");
System.exit(1);
}
// 输入文件夹
String inputpath = args[0];
// 输出文件夹
String outputpath = args[1];
// 输入文件
String shortin = args[2];
// 输出文件
String shortout = args[3];
if (shortin.indexOf(File.separator) >= 0)
shortin = shortin.substring(shortin.lastIndexOf(File.separator));
if (shortout.indexOf(File.separator) >= 0)
shortout = shortout.substring(shortout.lastIndexOf(File.separator));
SimpleDateFormat formater = new SimpleDateFormat("yyyy.MM.dd.HH.mm");
shortout = new StringBuffer(shortout).append("-")
.append(formater.format(new Date())).toString();
shortin = inputpath + shortin;
shortout = outputpath + shortout;
File inputdir = new File(inputpath);
File outputdir = new File(outputpath);
if (!inputdir.exists() || !inputdir.isDirectory()) {
System.out.println("inputpath not exist or isn't dir!");
System.exit(1);
}
if (!outputdir.exists()) {
new File(outputpath).mkdirs();
}
Job job = Job.getInstance(new Configuration(), LogAnalysiser.class.toString());
job.setJarByClass(LogAnalysiser.class);
job.setJobName("analysisjob");
job.setOutputKeyClass(Text.class);// 输出的 key 类型,在 OutputFormat 会检查
job.setOutputValueClass(IntWritable.class); // 输出的 value 类型,在OutputFormat 会检查
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
job.setCombinerClass(ReduceClass.class);
job.setNumReduceTasks(2);// 强制需要有两个 Reduce 来分别处理流量和次数的统计
FileInputFormat.setInputPaths(job, new Path(shortin));// hdfs 中的输入路径
FileOutputFormat.setOutputPath(job, new Path(shortout));// hdfs 中输出路径
Date startTime = new Date();
System.out.println("Job started: " + startTime);
job.waitForCompletion(true);
Date end_time = new Date();
System.out.println("Job ended: " + end_time);
System.out.println("The job took "
+ (end_time.getTime() - startTime.getTime()) / 1000
+ " seconds.");
// 删除输入和输出的临时文件
// org.apache.hadoop.fs.FileSystem.get(new Configuration()).copyToLocalFile(new Path(shortout), new Path(outputpath + "/out"));
// fileSys.delete(new Path(shortin),true);
// fileSys.delete(new Path(shortout),true);
System.exit(0);
}
}
MapClass负责处理数据输入,在hadoop MapReduce(PartitionerClass)调度ReduceClass(对输入数据处理)同时处理.















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









