







实际上,数据的封帧与解帧本身虽然实现起来十分简单,但它们在本质上仍然是数据的一种编解码。
那么它们相比之前介绍的数据编解码有什么区别呢?单从编码目标看,之前介绍的数据编解码是为了对用户的数据对象进行传输。
封帧与解帧则是为了在进行传输后,让接收方能轻松辨别每个对象。
网络编程为什么需要进行消息的定界
封帧一般是指在一段数据的前后分别添加首部和尾部,从而形成数据帧。
对于数据帧来说,首部和尾部的重要作用之一就是进行消息的定界。
因此,封帧本身就是消息定界方式中的一种,在了解具体的封帧技术之前,我们先了解一下为什么需要进行消息的定界。
追根溯源,应用层传输的对象虽然是逐个发送的,但是在经过传输层传输之后,对象不见得能被辨别出来。
正因为如此,我们才需要对消息进行定界。下面我们基于传输层的两种最流行的协议进行具体分析。
TCP
TCP是流式协议,就像水流一样,本身并无界限。
考虑一下,既然我们的可操作对象己经被序列化(编码)成字节流并通过TCP进行传输,那么如何从没有界限的“水流"中识别出各个对象便成为一个迫切需要解决的问题。
初学者往往会产生一些困惑,比如,假设对象不是连续发送的,而是每隔1s才发送一个,那么是不是就不需要封帧了?因为此时的对象似乎就是通过时间分割的字节流。
其实不然,当我们在TCP网络中传输对象时,很多时候都难以避免出现一些不够完整的现象,如半包、黏包等。
什么是黏包和半包
下面通过一个具体的例子来介绍一下黏包和半包的概念。如图所示,假设发送了两条消息——-ABC和DEF 此时,对方有可能一次性就接收到这两条消息(ABCDEF),也有可能分了好几次才接收完。
换言之,接收到的消息可能是零散的(如AB CD EF) 前面那种一次性接收到多条消息的现象称为黏包,而后面那种分好几次接收到不完整消息的现象称为半包。

产生黏包和半包现象的原因
- 产生黏包现象的原因
产生黏包现象的主要原因在于每次写入的数据比较少,比如远小于套接字缓冲区的大小。
此时,网卡往往不会立马发送,而是将数据合并后一起发送,这样效率会高一些。
但是,对方接收到的可能就是黏包。另外,如果接收方读取数据不够及时,也会产生黏包现象。
- 产生半包现象的原因
相较于黏包,产生半包现象的原因更多且更难克服。
例如,当发送方发送的数据大于套接字缓冲区的大小时,数据在底层必然会分多次发送,因此接收方收到的可能就是半包。
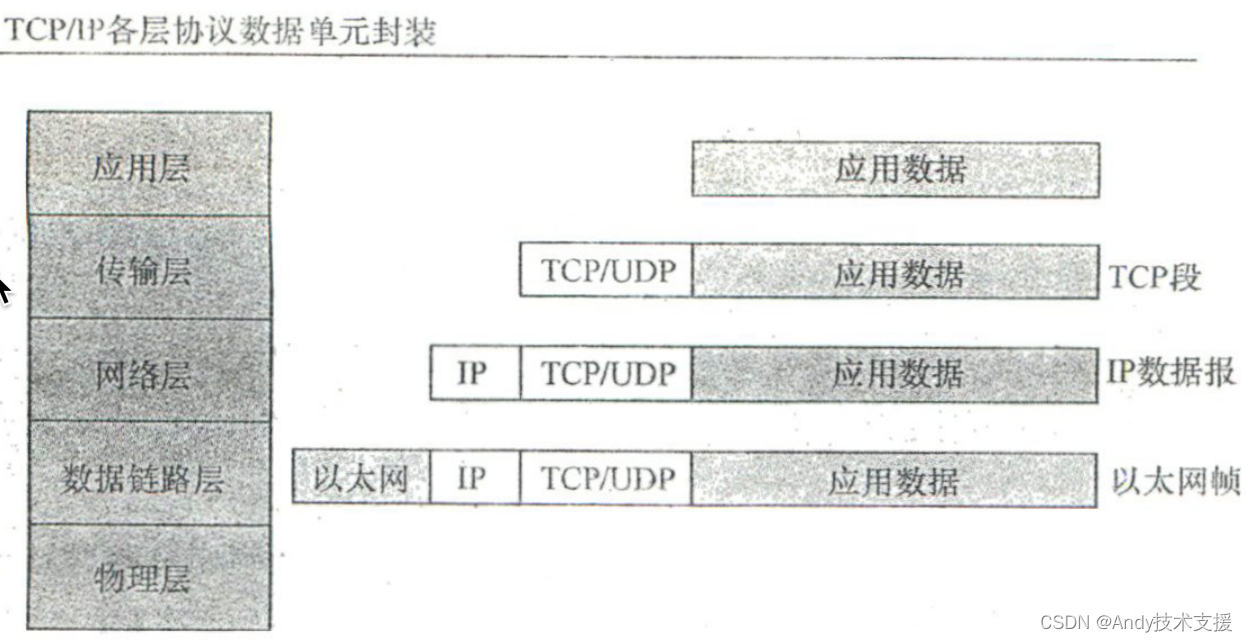
另外一个非常重要的因素就是最大传输单元(Maximum Transmission Unit, MTU) 数据是按TCP/IP逐层封装后传输的。
应用层数据在作为数据部分传递给数据链路层之前,需要加上传输层的头,才能逐层封装传递。
既然要封装,就必然涉及数据内容的大小控制,否则就不存在封装的概念了。
各层协议中报文内容的大小就由MTU控制。
当发送的数据大于协议各层的MTU时,就必须拆包,这是我们必须面对的现实。
以网络层为例,对于IPv4, MTU限制了数据内容最多64 K,对于Ethernet V2,MTU则限制数据内容最多1500字节。
综合来看,只要传输的数据超出各层MTU的限制,就必然需要对数据进行拆包。

UDP
相比TCP, UDP是无连接的传输协议,不存在黏包和半包等问题。
发送者不会计较发送内容是否成功。接收者接收的都是完整的包,不存在只有一半的包或者一个大包中有多个小包的情况。
因此,在使用UDP时,封帧问题不需要考虑,传输效率比较高。
当然,代价也是有的,就是UDP保证不了可靠性,因而不适用于对可靠性传输要求较高的场合。
总之,对于TCP而言,单从收发角度看,一次发送的内容可能分多次接收,多次发送的内容也可能一次接收。
从传输角度看,一次发送可能占用多个包,多次发送也可能共用同一个包。
出现黏包和半包现象的根本原因就在于此。
因为需要解决黏包和半包问题,所以我们才需要对消息进行定界。
常见的消息定界方式
TCP短连接方式
当使用TCP进行传输时,消息之所以不好区分,原因就在于发送的消息汇聚成了消息流。
假设我们每发送一个请求就断掉连接,那么肯定可以轻松地界定消息:从建立连接到释放连接
这段时间内发送的内容就可以表示一条完整的消息。
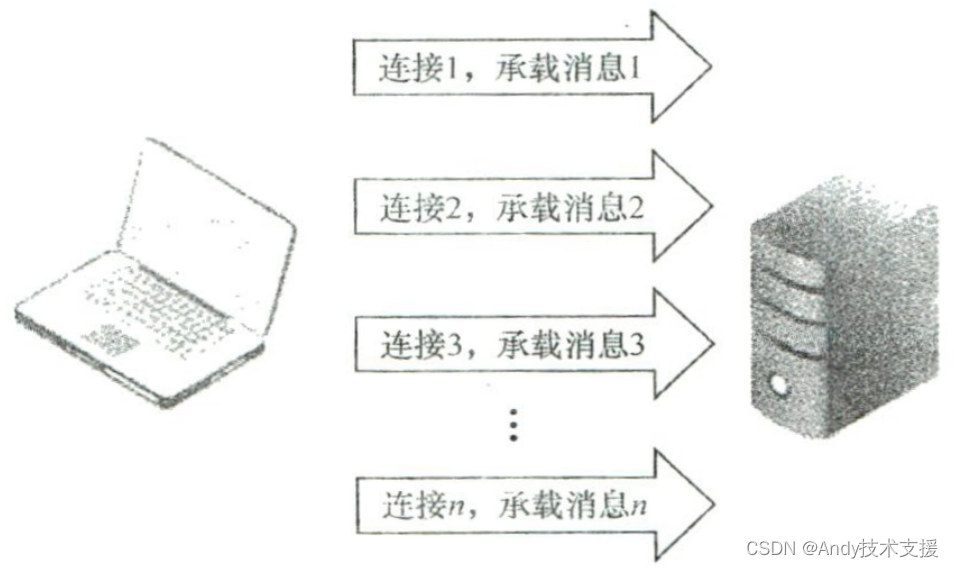 这种方式的优点在于比较简单,缺点是效率比较低。
这种方式的优点在于比较简单,缺点是效率比较低。
因为发送消息时需要频繁地创建和释放连接,所以开销非常大。这种方式没有充分利用TCP的面向连接优势。
固定长度方式
我们可以采用固定的长度作为消息的界定标准。
例如,对于原始消息ABC DEF,如果以固定长度(如3字节)作为消息的界定标准,就可以得到ABC和DEF两条消息。
这种方式的效率较高,并且易于实现,但缺点十分致命,需要消息本身就是固定长度的, 这明显不切实际。
当消息不满足长度要求时,就需要通过填充占位符来满足长度要求,因而显然要浪费不少空间。
例如,若以3字节作为固定长度,而需要传输的消息只有1字节,就需要额外补2字节。因此,我们并不推荐使用这种方式。
封帧
封帧(framing)是TCP消息界定的方式之一,它实际上可以通过多种不同的方式会实现,比如定界符方式、显式长度方式等。
定界符方式
顾名思义,就是使用定界符作为消息的划分边界。
例如,对于消息ABC和DEF,我们在发送时,可以添加定界符(/),因此发出去的消息就变成了 ABC/DEF,这样对方只要以“/”为界就可以找出ABC和DEF,这种方式较简单,但是对空间仍有浪费,比如需要添加定界符。
另外,如果消息本身就带有定界符,那么还需要对消息本身的定界符进行“转义”。
不言而喻,当使用这种方式对消息进行界定时,我们需要扫描传输的每个字符,效率并不高。
综合来看,这种方式可以用,但是不推荐。
显式长度方式
显式长度方式更灵活,也是目前使用最多且最推崇的方式之一。
具体思路如下。 在编码时将消息的长度计算出来,然后将消息的长度信息存放到一个长度固定的额外字段中,在解码时,先获取那个额外字段,再从中获取消息的长度信息,并按指定的长度读取消息。
以上描述可能仍然有些抽象,下面举例说明。
在发送消息ABC和DEF时,定义一个长度固定(例如1字节)的字段作为额外字段,并在其中存储消息的长度信息,这样接收方在进行处理时,首先从那个1字节的额外字段中获取消息的长度信息,然后根据得到的长度信息读取消息即可。

这种方式能够精确定位数据内容,并且不用转义字符,但是数据内容的长度在理论上是有限制的,需要预测可能的最大长度,从而定义长度字段占用的空间大小。
如果不进行估算就直接将长度字段定义得特别大,那么在消息本身不长的情况下,长度字段将会浪费不少空间。
例如,假设所有消息的长度都在128字节以内,但我们使用4字节来存储消息的长度信息,那么明显存在空间浪费情况。综合来看,预测消息的最大长度是十分有必要的。
Netty如何支持封帧

在实现上,它们都继承自抽象类ByteToMessageDecoder,这个抽象类要做的核心工作就是处理黏包、半包问题。
而作为子类,FixedLengthFrameDecoder、DelimiterBasedFrameDecoder 和 LengthFicldBasedFrameDecoder
只关注如何界定和解析出一条完整的消息。
另外,为什么在Netty中只有显式长度方式拥有对应的编码程序,而其他两种方式没有呢?
因为显式长度方式提供了对许多额外参数的控制,相比前两种方式要复杂一些,前两种方式基本上不提供任何逻辑或额外控制,开发者完全不需要借助Netty来完成,因此Netty只内置了一种稍微复杂些的专用于显式长度方式的编码器。
接下来,我们以最简单的FixedLengthFrameDecoder为例,看—下Netty如何找出消息边界并解决黏包和半包问题。
当消息到来时,触发 FixedLengthFrameDecoder 的父类 ByteToMessagcDecoder 中的 channelRead方法,从而对消息进行解析。
//ByteToMessageDecoder.java
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 接收到数据时调用
if (msg instanceof ByteBuf) {
// 标记channelRead是否由当前解码器触发
selfFiredChannelRead = true;
// 创建一个新的解码输出列表
CodecOutputList out = CodecOutputList.newInstance();
try {
// 是否为第一次解码
first = cumulation == null;
// 将接收的数据进行累积解码
cumulation = cumulator.cumulate(ctx.alloc(),
first ? Unpooled.EMPTY_BUFFER : cumulation, (ByteBuf) msg);
// 解码并将结果添加到输出列表
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
try {
if (cumulation != null && !cumulation.isReadable()) {
// 清零读取计数
numReads = 0;
try {
// 释放累积缓冲区中的数据
cumulation.release();
} catch (IllegalReferenceCountException e) {
//noinspection ThrowFromFinallyBlock
throw new IllegalReferenceCountException(
getClass().getSimpleName() + "#decode() might have released its input buffer, " +
"or passed it down the pipeline without a retain() call, " +
"which is not allowed.", e);
}
cumulation = null;
} else if (++numReads >= discardAfterReads) {
// 已经读取足够的数据,尝试丢弃一些字节以避免内存溢出
// 参见 https://github.com/netty/netty/issues/4275
numReads = 0;
discardSomeReadBytes();
}
// 获取输出列表中的元素个数
int size = out.size();
// 判断输出列表是否需要重新插入已回收的元素
firedChannelRead |= out.insertSinceRecycled();
// 触发ChannelRead事件
fireChannelRead(ctx, out, size);
} finally {
// 重用输出列表
out.recycle();
}
}
} else {
// 将消息传递给通道事件处理程序
ctx.fireChannelRead(msg);
}
}
数据流向可以参考下图,核心步骤如下。
- 追加数据。
- 尝试解析出消息对象。
- 传递解析出的消息对象。
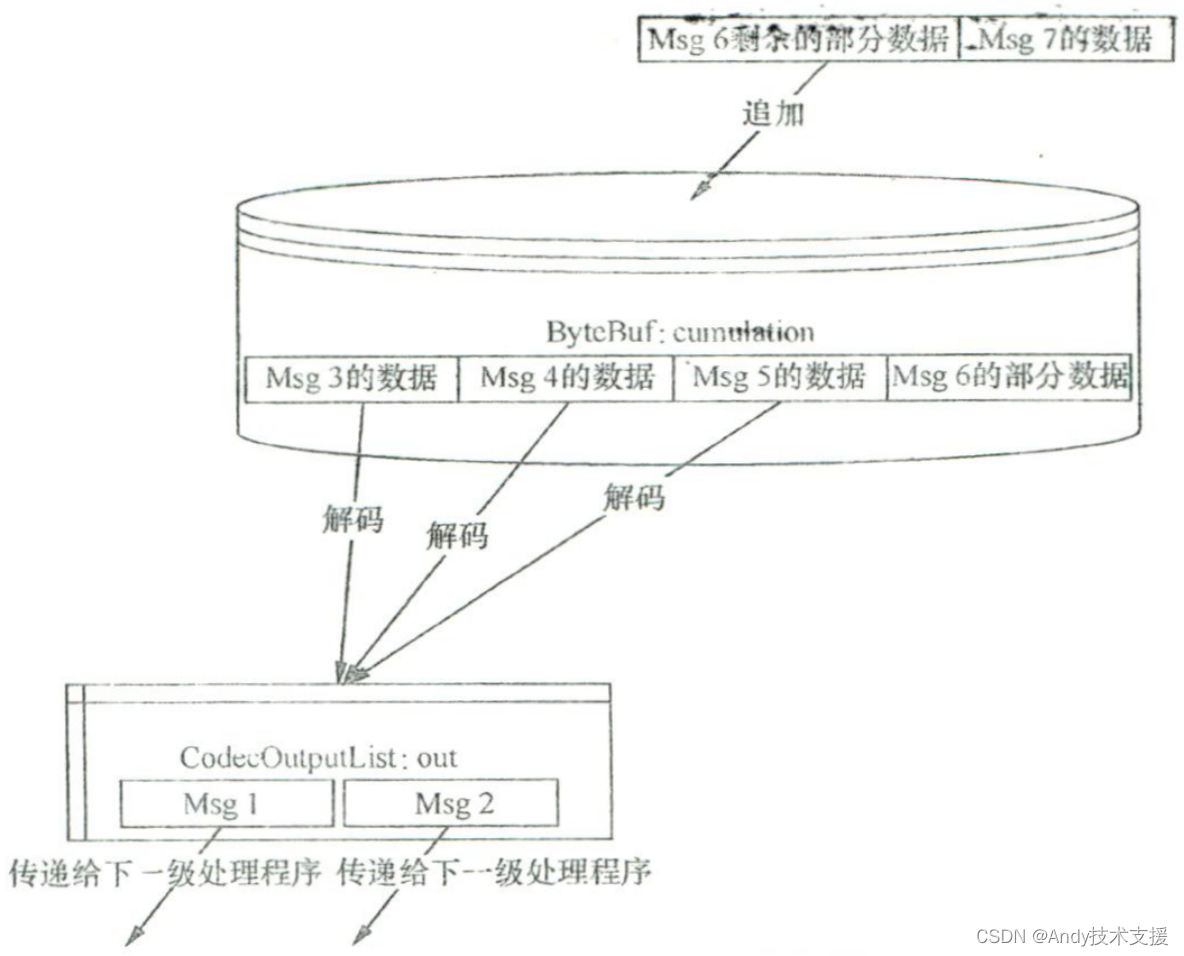
追加数据
首先,新来的消息会被追加到ByteBuf中,追加过程可参考如下代码。
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
其中,累积器(cumulator)有两种实现方式,默认使用的是内存复制方式。
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
/**
* 合并累积器,用于将输入的数据合并到累积缓冲区中
*
* @param alloc 缓冲区分配器
* @param cumulation 累积缓冲区
* @param in 输入缓冲区
* @return 合并后的缓冲区
*/
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
if (cumulation == in) {
// 如果 cumulation 和 in 相等,则释放 in,并返回 cumulation
in.release();
return cumulation;
} else if (!cumulation.isReadable() && in.isContiguous()) {
// 否则,如果 cumulation 无法读取且 in 是连续的,则释放 cumulation,并返回 in
cumulation.release();
return in;
} else {
ByteBuf var5;
try {
// 否则,进行以下操作
int required = in.readableBytes();
if (required <= cumulation.maxWritableBytes() && (required <= cumulation.maxFastWritableBytes() || cumulation.refCnt() <= 1) && !cumulation.isReadOnly()) {
// 如果所需字节数小于等于 cumulation 的可写入字节数,并且所需字节数小于等于 cumulation 的快速可写入字节数,或者 cumulation 的引用计数小于等于 1,并且 cumulation 不是只读的
cumulation.writeBytes(in, in.readerIndex(), required);
// 将 in 的数据写入 cumulation 中,从 in 的读取索引开始写入,并写入所需字节数
in.readerIndex(in.writerIndex());
// 设置 in 的读取索引为与写入索引相同
var5 = cumulation;
// 将 cumulation 赋值给 var5,并返回 var5
return var5;
}
var5 = ByteToMessageDecoder.expandCumulation(alloc, cumulation, in);
// 否则,调用 ByteToMessageDecoder.expandCumulation 方法来扩展 cumulation,并将扩展后的结果赋值给 var5
} finally {
// 无论以上条件是否满足,最后释放 in
in.release();
}
return var5;
// 返回 var5
}
}
};
执行完这一步之后,ByteBuf中将包含之前可能残余的数据(半包数据)以及新来的数据。
尝试解析出消息对象
在有了通过上一步得到的“所有尚未找出消息的”的ByteBuf之后,执行callDecode以尝试找出对象,并把解析结果(界定出来的完整消息)存放到out (CodecOutputList)中。callDecode最终会调用decode 抽象方法(可能调用多次,取决于cumulation中有多少个完整的对象)。
/**
* 调用解码方法
* @param ctx Channel上下文
* @param in 输入ByteBuf
* @param out 输出列表
*/
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
while (true) {
// 检查输入ByteBuf是否有可读数据
if (in.isReadable()) {
int outSize = out.size();
// 如果输出列表不为空
if (outSize > 0) {
// 调用fireChannelRead方法处理输出列表中的数据
fireChannelRead(ctx, out, outSize);
// 清空输出列表
out.clear();
// 如果Channel上下文被移除,则返回
if (ctx.isRemoved()) {
return;
}
}
int oldInputLength = in.readableBytes();
// 进行解码操作
this.decodeRemovalReentryProtection(ctx, in, out);
// 如果Channel上下文未被移除
if (!ctx.isRemoved()) {
if (out.isEmpty()) {
// 如果输出列表为空,且输入ByteBuf的可读字节数与上一次不同,则继续循环
if (oldInputLength != in.readableBytes()) {
continue;
}
} else {
// 如果输出列表不为空,且输入ByteBuf的可读字节数与上一次相同,则抛出DecoderException异常
if (oldInputLength == in.readableBytes()) {
throw new DecoderException(StringUtil.simpleClassName(this.getClass()) + ".decode() did not read anything but decoded a message.");
}
// 如果解码模式不是单个解码
if (!this.isSingleDecode()) {
// 继续循环
continue;
}
}
}
}
// 循环结束,返回
return;
}
} catch (DecoderException var6) {
// 抛出DecoderException异常
throw var6;
} catch (Exception var7) {
// 抛出DecoderException异常
throw new DecoderException(var7);
}
}
FixedLengthFrameDecoder对父类中decode()方法的实现情况
//FixedLengthFrameDecoder.java
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
out.add(decoded);
}
}
/**
* 从ByteBuf中创建一个帧并返回它。
*
* @param ctx 这个ByteToMessageDecoder所属的ChannelHandlerContext
* @param in 从中读取数据的ByteBuf
* @return frame 表示帧的ByteBuf,如果无法创建帧,则返回null。
*/
protected Object decode(
@SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception {
// 如果输入流的可读字节数少于帧的长度,则返回null
if (in.readableBytes() < frameLength) {
return null;
} else {
// 否则从输入流中读取一个保留的字节数组切片
return in.readRetainedSlice(frameLength);
}
}
很明显,当尝试解析出消息对象时会遇到两种情况:
- 如果累积的数据充足(大于或等于frameLength),那么至少一个消息对象可以解析出, 于是读取数据(readRetainedSlice),解析出消息对象并存放到out中。另外,读取工作本身会改变待累积数据的可读范围。
- 如果累积的数据不够,那么返回null,不再读取数据,于是累积的数据保持不变。
传递解析出的消息对象
执行完上一步之后,out中可能保存了一些完整的消息对象。为了把这些消息对象传递出去,执行如下语句:
fireChannelRead(ctx, out, size);
fireChannelRead方法的实现非常简单。
//ByteToMessageDecoder.java
static void fireChannelRead(ChannelHandlerContext ctx, CodecOutputList msgs, int numElements) {
// 遍历输出列表中的元素,并调用ChannelHandlerContext的fireChannelRead方法逐个发送给通道
for(int i = 0; i < numElements; ++i) {
// 调用CodecOutputList的getUnsafe方法获取元素,并将其作为参数传递给ChannelHandlerContext的fireChannelRead方法
ctx.fireChannelRead(msgs.getUnsafe(i));
}
}
定义封帧
我们首先进行客户请求的封帧和解帧。封帧主要是将客户请求封装成可以分清“界限”的数据。
客户请求实现编码器
public class OrderFrameEncoder extends LengthFieldPrepender {
/**
* 订单帧编码器
*/
public OrderFrameEncoder() {
/**
* 父类LengthFieldPrepender的构造函数调用
*/
super(2);
}
}
上述代码使用显式长度方式来封帧:位置是从0开始的,用来存储消息长度的固定字段的大小为2字节。
客户请求发出后,服务器会返回响应。对于响应,要实现对应的解码器。
客户请求实现解码器
public class OrderFrameDecoder extends LengthFieldBasedFrameDecoder {
/**
* 订单帧解码器
*/
public OrderFrameDecoder() {
/**
* 构造函数调用父类 LengthFieldBasedFrameDecoder 的构造函数
* 参数依次为:最大帧长度、帧长度字段的位置、帧长度字段的长度、帧长度调整量、帧长度字段的小端/大端标识
*/
super(Integer.MAX_VALUE, 0, 2, 0, 2);
}
}
将编码器和解码器添加到处理器流水线中
// 创建一个ChannelInitializer实例,用于初始化NioSocketChannel的ChannelPipeline
bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// 获取ChannelPipeline实例
ChannelPipeline pipeline = ch.pipeline();
// 向ChannelPipeline中添加一个OrderFrameDecoder实例
pipeline.addLast(new OrderFrameDecoder());
// 向ChannelPipeline中添加一个OrderFrameEncoder实例
pipeline.addLast(new OrderFrameEncoder());
}
});
至此,我们完成了客户请求的封帧和解帧。
对于服务器,我们也需要编码器与解码器。
解码器用来解析客户发来的请求,代码与客户端的响应的解码器相同。
编码器则用来编码响应,并且与客户用来发送请求的编码器是一致的。
需要说明的是,以上情况建立在请求和响应的编码方式都相同的前提之下。
如果编码方式不同,那么编码器与解码器也将不一样。
常见疑问解析
累积器的两种实现方式之间的区别与选择依据
累积器有两种实现方式,并且默认使用的是内存复制方式(使用System.arraycopy()) 实际上,它还有另一种实现方式——组合视图方式。
//ByteToMessageDecoder.java
// 定义一个 Cumulator 接口的静态常量 COMPOSITE_CUMULATOR,使用匿名内部类实现
public static final Cumulator COMPOSITE_CUMULATOR = new Cumulator() {
/**
* 将传入的两个 ByteBuf 合并为一个 ByteBuf
*
* @param alloc ByteBuf 的分配器
* @param cumulation 已有的 ByteBuf
* @param in 新的 ByteBuf
* @return 合并后的 ByteBuf
*/
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
if (cumulation == in) {
// 当 in 缓冲区与 cumulation 相同时,它将被保留两次,释放一次
in.release();
return cumulation;
}
if (!cumulation.isReadable()) {
cumulation.release();
return in;
}
CompositeByteBuf composite = null;
try {
if (cumulation instanceof CompositeByteBuf && cumulation.refCnt() == 1) {
composite = (CompositeByteBuf) cumulation;
// 当我们要在末尾添加新组件时,Writer index 必须等于 capacity
if (composite.writerIndex() != composite.capacity()) {
composite.capacity(composite.writerIndex());
}
} else {
// 如果 cumulation 不是 CompositeByteBuf 类型或者引用计数不为 1,则创建一个新的 CompositeByteBuf
composite = alloc.compositeBuffer(Integer.MAX_VALUE).addFlattenedComponents(true, cumulation);
}
// 将新的 ByteBuf 添加到 CompositeByteBuf 中
composite.addFlattenedComponents(true, in);
in = null;
return composite;
} finally {
if (in != null) {
// 如果所有权没有被转移,我们必须释放 in 缓冲区,否则可能会导致内存泄漏
in.release();
// 如果 composite 不是 cumulation,并且在 finally 代码块中创建了新的 buffer,则释放该 buffer
if (composite != null && composite != cumulation) {
composite.release();
}
}
}
}
};
从上述代码可以看出,这种方式不需要复制内存,而是通过CompositeByteBuf提供的组合视图方式将消息“连接”到一起。
那么为什么Netty没有默认选择这种方式呢?
我们无法证明组合视图方式的性能在所有场景下都比内存复制方式好(毕竟组合视图方式的指针维护更复杂一些。当然,如果解码时将组合拆开后就能用,那么性能明显会好很多,但是现有的测试只表明性能好了一点点而己),因此Netty自然默认选择内存复制方式。
不过,Netty提供了 setCumulator()方法,使得用户可以在这两种方式之间自由进行切换,从而提高了灵活性。
显式长度方式如何处理消息很长的情况
显式长度方式使用的LengthFieldBasedFrameDecoder对长度字段的定义是以字节为单位的, 比如1字节、2字节等。因此,实际消息的长度必须在长度字段允许的最大范围之内。
例如,当长度字段为1字节时,允许的最大消息长度为256字节。
但是,如果某个网络应用程序的最大消息长度为200字节,那么我们肯定会指定LengthFieldBasedFrameDecoder的maxFrameLength参数为200 (这个参数必须设置)。
当由亍异常导致传递的消息长于200字节时,程序最终会执行fail 方法并抛出TooLongFrameException异常。
至于TooLongFrameException异常如何处理(如断开连接、返回错误码等),则交由用户通过 ChannelHandler#exceptionCaught 方法来控制。
忽略字节序的大端模式和小端模式
在开发网络应用程序时,我们很容易忽略字节序的问题。
字节序是指多字节数据在计算机内存中存储或进行网络传输时各字节的存储顺序。
字节序有大端模式和小端模式两种。
具体使用哪一种方式和CPU有很大的关系。
就CPU本身而言,CPU分为Motorola的PowerPC系列和Intel的x86系列。
前者采用大端(big endian)模式存储数据,也就是在低地址存放最高有效字节。
后者则采用小端(little endian)模式存储数据,也就是在低地址存放最低有效字节。

从CPU市场角度看,目前流行的毫无疑问是小端模式。
但是,为了保证网络传输的一致性,ISO规定网络必须采用大端模式,这就是LengthFieldBasedFrameDecoder等解码程序默认使用ByteOrder.BIG_ENDIAN的原因所在。
另外,Java屏蔽了平台的细节,默认使用的也是大端模式。














 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









