







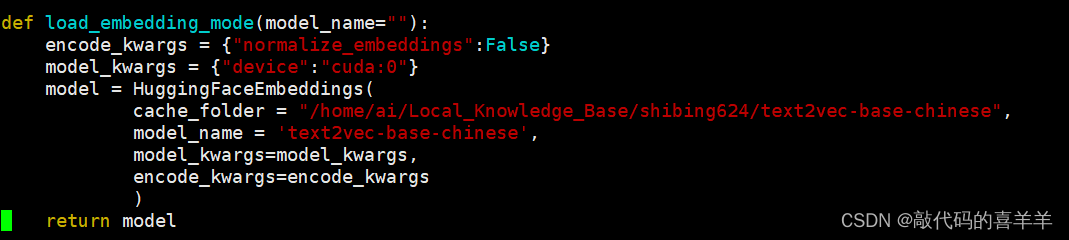
由于服务器是离线的,因此我先在本地到huggingface官网下载模型text2vec,然后上传到服务器上运行,报错:
(MaxRetryError('HTTPSConnectionPool(host=\'huggingface.co\', port=443): Max retries exceeded with url: /api/models/sentence-transformers/text2vec-base-chinese/revision/main (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7f12ebf56350>: Failed to resolve \'huggingface.co\' ([Errno -3] Temporary failure in name resolution)"))'), '(Request ID: d787098f-eabd-4f11-8150-623bd99a55e2)')
An error happened while trying to locate the files on the Hub and we cannot find the appropriate snapshot folder for the specified revision on the local disk. Please check your internet connection and try again.
huggingface_hub.utils._errors.LocalEntryNotFoundError: Cannot find an appropriate cached snapshot folder for the specified revision on the local disk and outgoing traffic has been disabled. To enable repo look-ups and downloads online, pass 'local_files_only=False' as input.
HuggingFaceEmbeddings它识别不了这个路径下的文件,因此我将cache_folder的值换成'shibing624/text2vec-base-chinese'依然报相同的错误。
然后我去官网看如何调用这个模型,选择了下面这种方式:
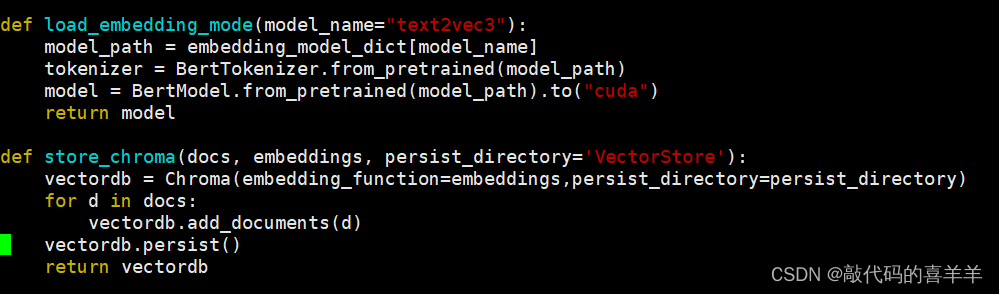
再次报错:
db = store_chroma(documents,embeddings)
AttributeError: 'BertModel' object has no attribute 'embed_documents'
也就是说加载完向量化模型后,我初始化了Chroma向量数据库,然后对传入的doc文档数据进行向量化,它会提示找不到embed_documents这个属性。本身BertModel是没有这个属性的,但是Chroma却需要调用这个属性来实现文档向量化(通过HuggingFaceEmbeddings来加载模型就不会报错,但是离线服务器上用不了)。因此,自己写一个embed_documents来实现就好啦,如下所示:
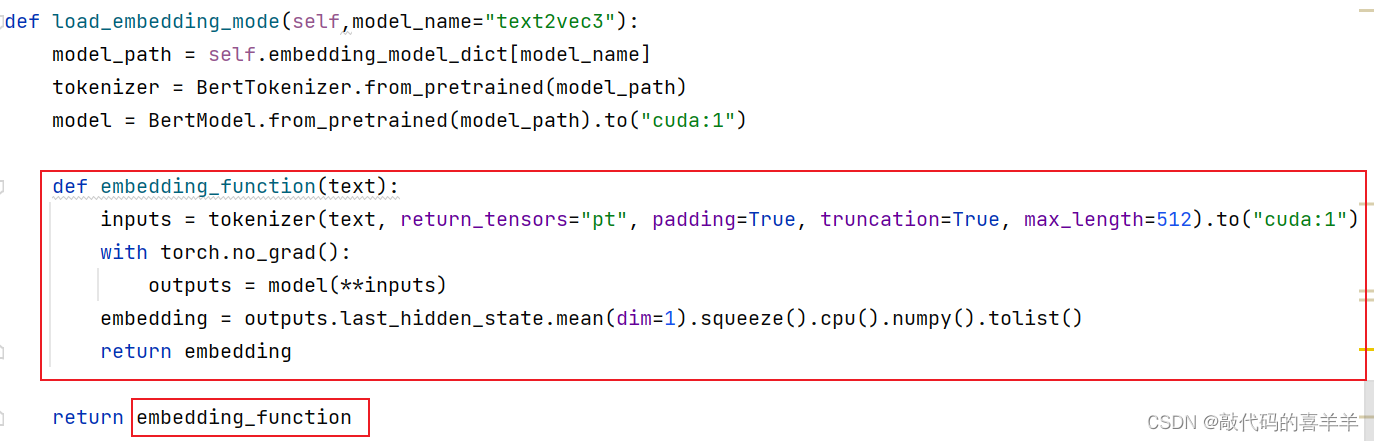
先在load_embedding_mode里面添加一个方法embedding_function,然后再建立一个类:

最后再调用这个类,就能正常对文档进行向量化和本地持久化了。
embedding_function = EmbeddingFunction(load_embedding_mode()) db = Chroma(embedding_function=embedding_function, persist_directory='VectorStore')


















 3828
3828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









