







论文地址:https://arxiv.org/abs/1911.11462
图神经网络博客地址:https://distill.pub/2021/gnn-intro/
Abstract
作者认为,目前的时序动作检测任务只关注了时间上下文信息但是忽略了语义信息。本文提出了一个图卷积网络(GCN)模型,自适应地将多层次的语义上下文合并到视频特征中,并将时间动作检测作为一个子图定位问题。
具体实现上来说,作者将视频片段表示为图节点,将片段-片段相关性表示为边,将与上下文相关的操作表示为目标子图。
以图卷积为基本操作,作者设计了一个名为GCNeXt的GCN块,它通过聚合每个节点的上下文来学习每个节点的特征,并动态更新图中的边。
Introduction
下图是一个视频可以构建的图。节点:视频片段(视频片段定义为短时间内的连续帧)。边:片段与片段之间的关联。子图:与上下文关联的操作。有4种类型的节点:动作、开始、结束和背景,用彩色的点表示。边有两种类型:(1)时间边,根据片段的时间顺序预定义;(2)语义边,从节点特征中学习。
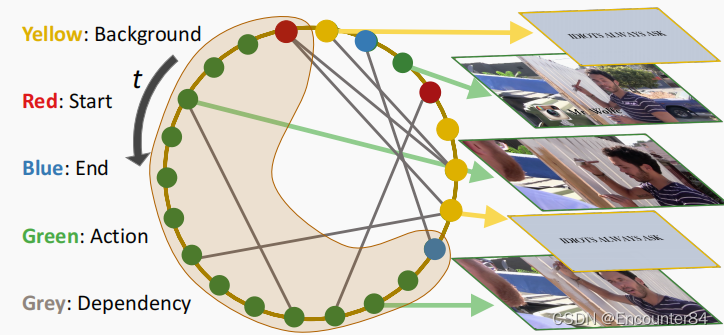
本文贡献有以下三点:
(1)提出了一种新的基于GCN的视频模型来充分利用视频上下文进行有效的时间动作检测。使用这个视频GCN表示,我们能够自适应地将多层次的语义上下文合并到每个代码片段的特征中。
(2)提出了一种新的G-TAD子图检测框架来定位视频图中的动作。G-TAD包括两个主要模块:GCNeXt和SGAlign。GCNeXt在视频图上执行图卷积,同时利用时间和语义上下文。SGAlign在一个适合于检测的嵌入式空间中重新排列子图特征。
(3)G-TAD在两个流行的动作检测基准测试上实现了最先进的性能。在ActivityNet-1.3上,其平均mAP为34.09%。在THUMOS14上,当与提案处理方法结合时,它在IoU@0.5时达到51.6%。
Proposed Method
视频特征表示方法和之前的模型表示方法一样:

G-TAD Architecture:
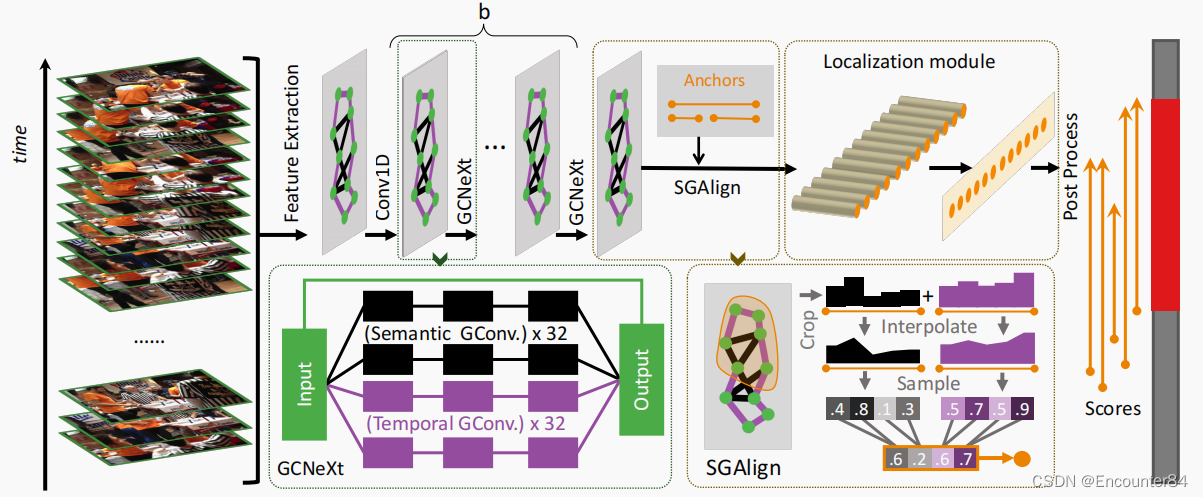
G-TAD的动作检测框架如上图所示。首先将片段特征输入到b个GCNeXt块中,(这是受ResNeXt的启发而设计的),以获得上下文感知特性。
每个GCNeXt包含两个图卷积流。一个流用于操作固定的时间顺序,而另一个流自适应地将语义上下文聚合为代码片段特征。两个流都采用分裂-变换-合并策略,使用多个卷积路径(路径数定义为基数)来生成更新的图,并聚合成一个图作为块输出。在所有b个GCNeXt块的末尾,作者基于预定义的时间锚点提取了一组子图。
然后用对齐层SGAlign用特征向量表示每个子图。最后使用多个全连通层来预测代表每个子图的特征向量和GT的IoU。
GCNeXt for Context Feature Encoding:
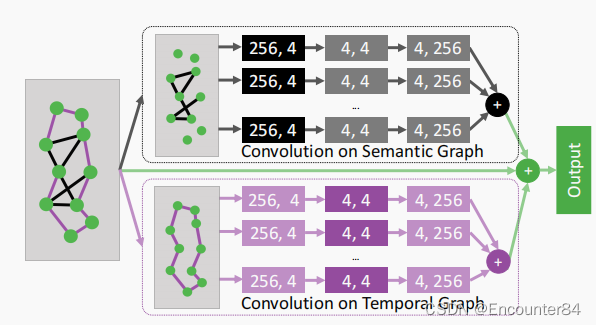 上图是GCNeXt块。输入特征由具有相同基数的时间流和语义流进行处理。黑色和紫色的盒子分别表示时间流和语义流中的操作,较深的颜色表示图形卷积,较浅的颜色表示1乘1的卷积。每个方框中的数字表示输入和输出通道。这两个流都遵循一个分裂转换-合并策略,每个策略都有32条路径,以增加转换的多样性。模块输出是两个流和输入的总和。
上图是GCNeXt块。输入特征由具有相同基数的时间流和语义流进行处理。黑色和紫色的盒子分别表示时间流和语义流中的操作,较深的颜色表示图形卷积,较浅的颜色表示1乘1的卷积。每个方框中的数字表示输入和输出通道。这两个流都遵循一个分裂转换-合并策略,每个策略都有32条路径,以增加转换的多样性。模块输出是两个流和输入的总和。
**Temporal Edges:**用来编码时间片段中的时序信息:

**Semantic Edges:**由动态边卷积来定义的,它根据图节点之间的特征距离动态地构造图节点之间的边。语义边的目标是从语义相关的代码片段中收集信息,我们为G中的每个节点vi定义语义边集Es如下:

Graph Convolution:
作者使用X=[x1,x2,……,xL]∈
R
C
×
L
R^{C×L}
RC×L来表示图中所有节点的特征,利用图的卷积运算F来对其进行变换,F有几个选择。为简单起见,使用一个单层边卷积作为图卷积操作:

Stream Aggregation:
GCNeXt输出是语义和时间流以及输入的聚合,可以表述为:

Sub-Graph of Interest Alignment (SGAlign):

**Sub-Graph Localization:**对于每个子图Ga,我们计算他和GT的交叉过联合(IoU)。我们在每个子图特征的SGAlign层上应用了三个全连接(FC)层。最后一个FC层有两个输出分数pcl和preg,它们分别使用分类和回归损失来匹配gc。















 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









