







论文地址:https://arxiv.org/abs/2103.15233
Abstract
在本文中,作者引入了一种新的低保真度(LoFi)视频编码器优化方法。我们建议在时间、空间或时空分辨率方面减少小批量组成,以便联合优化视频编码器和TAL头,而不是在TAL学习中总是使用完整的训练配置。至关重要的是,这使得梯度能够在TAL监督损失条件下通过视频编码器,有利地解决任务差异问题,并提供更有效的特征表示。大量的实验表明,所提出的LoFi优化方法可以显著提高现有的TAL方法的性能。令人鼓舞的是,即使在一个RGB流中使用了基于轻量级的ResNet18的视频编码器,我们的方法也超过了基于双流(RGB+光流)ResNet50的替代方案,通常有很好的优势。
Introduction
一个典型的TAL模型是基于深度卷积神经网络(CNNs),由两个模块组成:一个视频编码器和一个TAL头。视频编码器通常通过不同的TAL方法共享(例如,G-TAD,BC-GNN)
在TAL模型的标准优化中,通常涉及到两个阶段的迁移学习pipline:1,首先,视频编码器在一个大型源视频分类数据集(如Kinetics)上进行优化,在动作分类监督下,对目标数据集的修剪版本进行细化;2,其次,在TAL任务监督下,冻结视频编码器,并在目标动作定位数据集(如ActivityNet,HACS)上的TAL头进行优化。
在广泛使用的TAL训练pipline中,视频编码器只适用于动作分类,而不是目标TAL任务。具体来说是这样的:视频编码器被训练为使动作序列中的不同短片段被映射到相似的输出,这导致了编码器对动作的时间边界不敏感。这对于TAL模型来说是不合适的,因此,最终的TAL模型可能存在性能次优的问题。
针对上述问题,作者在这项工作中做出了以下贡献。(1)研究了TAL模型的标准优化方法的局限性,并认为任务差异问题阻碍了现有TAL模型的性能。尽管视频编码器优化是一个重要的成分,但它在很大程度上被现有的TAL方法忽略。(2)为了改进TAL模型的训练水平,作者提出了一种新颖、简单、有效的低保真度(LoFi)视频编码器优化方法。它是专门为解决TAL模型的视频编码器的任务差异问题而设计的。大量的实验表明,所提出的LoFi优化方法在与现成的TAL模型(如G-TAD)结合时,产生了新的最先进的性能。重要的是,该方法实现了优越的效率/精度的权衡。
Method
下图是本文所提出的TAL模型训练程序的示意图概述。模型训练涉及三个阶段:(1)在辅助视频数据集(如Kinetics)的动作分类任务监督下对视频编码器进行预训练;(2)在目标数据集的TAL任务监督下,低保真度(在训练视频的空间、时间或时空分辨率上的低小批量配置)优化;这是本文在不增加内存开销的情况下解决任务差异问题的关键阶段。(3)在目标数据集的TAL任务监督下,以全保真配置训练TAL头。
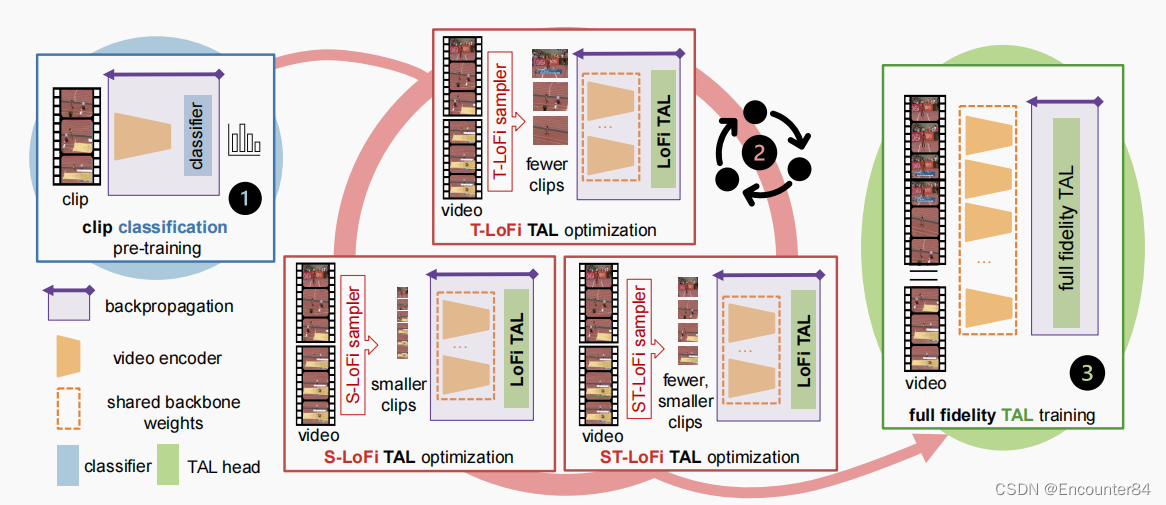
Model Training Procedure:
如上图所示,该训练过程包含三个阶段(1)首先,通过在一个大型视频数据集上的动作分类监督来对视频编码器进行预训练。(2)其次,我们对目标数据集上具有TAL头的视频编码器进行低保真度(LoFi)优化。(3)最后,我们冻结了已经完成的端到端优化的视频编码器,并在全空间和时间分辨率下从目标数据集上从头开始训练选择的TAL头。
Low-Fidelity Training Configurations:
在形式上,我们将一个小批量的全保真度配置定义为:
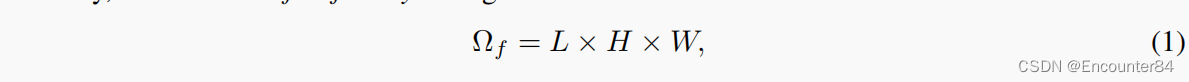
其中L为时间分辨率,H×W为2维空间分辨率。在全保真度机制和一定的内存大小约束下,只有TAL头可以被训练,同时使视频编码器冻结。为了使视频编码器在TAL任务的监督下与TAL头一起进行端到端优化,我们为小批量设计了四种低保真度配置。
(I) Spatial Low-Fidelity (S-LoFi):
在第一种配置中,我们将输入视频在两个空间维度上的空间分辨率都降低了一个rs倍,如下:

使用更小的空间特征图,这可以有效地减少视频编码器的特征图的内存消耗,从而创造空间,使视频编码器的学习。
(II) Temporal Low-Fidelity (T-LoFi):
在第二种配置中,我们将以以下形式考虑时间分辨率的降低:

其中rt>1是缩放因子。这对应于TAL头输入的片段数量较少,在每个时间位置保持候选位置相同的情况下,最终输出较少的预测。这减少了视频编码器和时间定位头的记忆需求。
(III) Spatio-Temporal Low-Fidelity (ST-LoFi):
在第三种配置中,我们同时应用时间和空间分辨率(通常较小的)减少,表述为:

在这个设置中,内存可以在时间维度和空间维度之间共享。
(IV) Cyclic Low-Fidelity (C-LoFi):
上述三种LoFi配置都是单独使用的。为了进一步探索它们的互补优势,我们建议以一种结构化的方式应用所有它们.具体来说,我们用三种LoFi配置形成一个采样网格,并反复循环通过它们。
值得注意的是,它与原来的多网格训练的一些实际差异。首先,与原来的多网格方法相反,我们在时间维度和空间维度之间降低了输入分辨率,使每个视频内存的使用保持(近似)不变。因此,批处理的大小也始终保持不变,这简化了训练。其次,在视频编码器训练期间,都不使用全分辨率设置(即全保真度)。
An Instantiation of LoFi:
现成的TAL模型:在不失一般性的前提下,本研究采用了G-TAD,一种最先进的TAL方法,作为我们的时间定位模块。该方法基于图卷积网络,G-TAD由一堆GCNeXt块组成,以获得上下文感知的特征。在每个GCNeXt块中,有两个图卷积流来建模两种类型的上下文信息。一个流与时间上下文一起操作,而另一个流自适应地在代码片段特征空间中聚合语义邻居。
在最后一个GCNeXt块的最后,G-TAD基于预定义的时间锚点提取了一组子图。利用兴趣对齐层的子图SGAlign,它使用一个特征向量表示每个子图,并进一步作为多个全连接层的输入来预测最终的动作预测。为了用我们的LoFi训练G-TAD,我们选择了其中一个提出的低保真度变体,并应用原始的TAL损失函数来优化视频编码器和TAL头。
硬件和软件设置:我们使用PyTorch 1.8和CUDA 10.1实现了我们的方法。对于LoFi训练,我们使用4个NVIDIA V100gpu,每个gpu都有32GB的内存。在此设置下,内存约束为128GB。在补充材料中,我们进一步测试了表B中使用单个V100 GPU的低成本设置。















 1636
1636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









