






 该研究提出了一种端到端网络,结合分类流和强度学习流,利用无监督的对抗性适应来处理用户生成视频中的情绪识别。网络通过从图像情感数据集迁移情感信息,提取帧级特征和情感强度,减少了源数据集与视频帧之间的域差异,提高了视频情绪识别的性能。在VideoEmotion-8和Ekman-6数据集上的实验显示了优于现有方法的结果。
该研究提出了一种端到端网络,结合分类流和强度学习流,利用无监督的对抗性适应来处理用户生成视频中的情绪识别。网络通过从图像情感数据集迁移情感信息,提取帧级特征和情感强度,减少了源数据集与视频帧之间的域差异,提高了视频情绪识别的性能。在VideoEmotion-8和Ekman-6数据集上的实验显示了优于现有方法的结果。
摘要——用户生成视频中的情绪识别引起了相当大的研究关注。 大多数现有方法都侧重于学习帧级特征,而没有考虑对视频表示至关重要的帧级情绪强度。 在这项研究中,我们旨在通过从图像情感数据集中传输情感信息来提取帧级特征和情感强度。 为了实现这一目标,我们提出了一个端到端的网络,用于联合情绪识别和强度学习,具有无监督的对抗性适应。 所提出的网络由分类流、强度学习流和对抗性适应模块组成。 分类流用于通过类激活映射方法生成伪强度图,以训练强度学习子网络。 强度学习流建立在改进的特征金字塔网络之上,其中来自不同尺度的特征是交叉连接的。 采用对抗性适应模块来减少源数据集和目标视频帧之间的域差异。 通过对齐跨域特征,我们使我们的网络能够在源数据上学习,同时泛化到视频帧。 最后,我们将加权和池化方法应用于帧级特征和情感强度以生成视频级特征。 我们在两个基准数据集(即 VideoEmotion-8 和 Ekman-6)上评估了所提出的方法。实验结果表明,与以前的最先进方法相比,所提出的方法实现了改进的性能。 索引词——对抗域适应、情绪强度学习、视频情绪识别。
主要贡献如下:
我们提出了一个端到端网络,用于通过从大规模图像情感数据集中转移知识来提取帧级特征和情感强度。 所提出的网络共同学习对图像情感进行分类,并通过无监督的对抗性适应来学习强度。 通过对齐跨域特征,我们使我们的网络能够在源数据上学习,同时泛化到视频帧。 与大多数以前的研究相比,我们的方法有助于解决帧级特征提取中的域偏移问题,并且可以通过关注重要帧来学习改进的视频级表示。 我们在两个基准数据集(即 VideoEmotion-8 和 Ekman-6)上通过实验验证了所提出的方法。 实验结果表明,我们的方法提高了视频中情绪识别的最先进性能。
方法
我们旨在通过从图像情感数据集中传输情感信息来提取帧级特征和情感强度。 为此,我们提出了一个端到端的网络,用于联合情绪识别和强度学习,具有无监督的对抗性适应。 所提出的网络由分类流、情绪强度图预测流和对抗性适应模块组成。 拟议网络的概述如图 1 所示。强度预测流建立在改进的 FPN 之上,其中来自不同尺度的特征是交叉连接的。 CAM 方法用于从分类流生成伪强度图,以训练强度学习子网络。 对抗性适应模块用于减少源域数据和视频帧之间的域差异。 在本节中,我们首先介绍 IFPN。 然后,我们介绍了所提出的用于联合情感识别和强度学习的无监督域适应网络。 最后,我们提出了视频级情感表示和分类的方法。 A. 改进的 FPN 如图 2(a) 所示,典型的特征金字塔网络包含两条路径:自下而上的路径和自上而下的路径。 自下而上的路径是一个主干网络,例如 ResNet,它产生一组多尺度特征图 {H1, H2, H3, H4}。 在自上而下的路径中,粗分辨率的特征图被上采样到高空间大小的 2 倍,并通过横向连接与自下而上的方式生成的相应特征图合并。 这个过程可以表述如下:
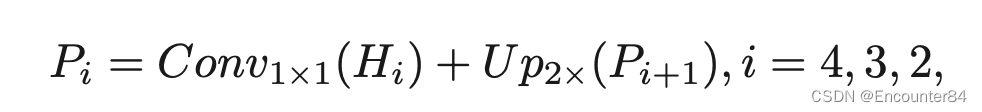
其中 U p2× 表示上采样,因子为 2。为了使 加法运算有效,通道数等于 Hi−1 的 1×1 卷积应用于 Hi。 P5直接由横向卷积产生。 尽管 FPN 已被证明是有效的,但它可能不是最佳结构。 我们假设跨尺度连接可能更有效。 在这个假设下,我们放宽了构建 FPN 的约束。 如图 2(b) 所示,一个节点连接到从其所有先前节点中选择的两个节点:
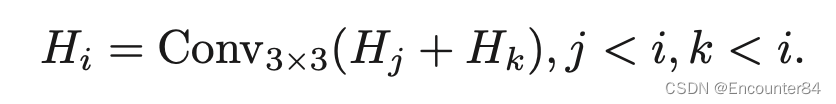

















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









