






摘要
【摘要】:视频情感识别是情感计算领域的一个重要分支。 然而,传统的识别工作主要集中在人的特征上,而忽略了视频场景和物体的上下文线索。 在我们的工作中,我们提出了一个用于双模态视频情感识别的上下文感知框架。 与直接提取整个视频帧的特征的现有方法不同,我们提取视频的关键帧和关键区域以获得视频场景和对象中包含的情感线索。 具体来说,对于视觉流,应用分层双向长短期记忆(Bi-LSTM)来总结视频场景并找到对视频情感贡献最大的关键帧; 同时,我们引入区域提议网络(RPN)来提取视频帧中对象区域的相应特征并构建情感相似度图。 在使用前馈神经网络(FNN)为不同的区域分配不同的权重系数后,图卷积网络(GCN)用于推理关键区域之间的连接。 此外,帧级 Log-Mel 频谱片段的上下文信息补充了视觉信息。 最后,我们通过自适应门控多模态融合模块融合视觉和声学特征,用于视频情感分类。 我们对 Video Emotion-8 和 Ekman-6 数据集进行了实验。 实验结果表明,我们的模型比几个基线模型具有更好的分类精度。 索引词——多模态情感识别,视频场景摘要,关系推理,图卷积网络
本文的贡献总结为:1)视觉特征提取。 我们提出了一个双流编码网络来探索场景和视频对象中包含的情感线索。 子网络使用分层 Bi-LSTM 来总结视频场景,过滤掉视频中提供的背景信息以理解视频情感,并找出视频的关键帧。 另一个使用 RPN 来查找包含对象的区域建议。 2)情感关系推理。 我们首次结合 GCN 和注意机制来推理视频中包含的对象之间的情感关系。 3)特征融合。 为了学习不同模态之间的关联,我们引入了一个门控融合单元来自适应融合提取的音频和视频特征。 门控融合单元可以很容易地与其他神经网络架构耦合。
方法
A. 概述
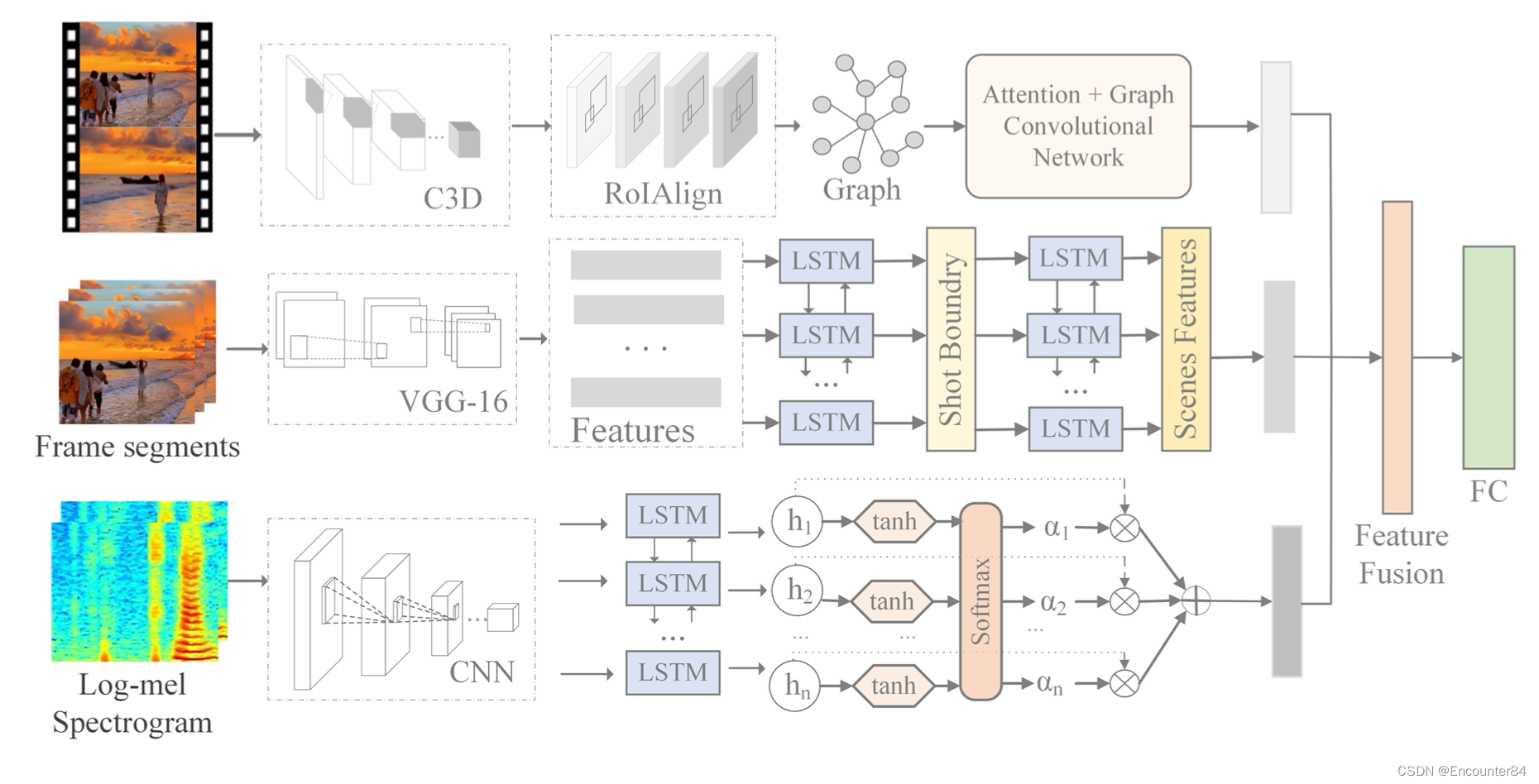
由于视频中的场景和对象包含丰富的情感线索,如图 1 所示,我们提出了一个时空网络来分别利用场景和对象信息。 具体来说,我们引入分层 Bi-LSTM 来总结视频场景,并将注意力机制与 GCN 相结合来挖掘不同对象之间的情感关系。 此外,Bi-LSTM 用于从帧级 Log-Mel 频谱图片段中提取上下文信息以补充视觉信息。 然后,我们引入了一种自适应门控多模态融合模型,对声学和视觉特征进行特征级融合,融合后的特征将用于视频情感分类。
B. 视频场景摘要的结构
自适应心理学家发现,情绪通常是由多个对象在特定场景中执行特定事件触发的。场景。 因此,我们通过提取视频场景信息来分析视频情感。 众所周知,帧构成镜头,镜头构成视频 [30],因此我们使用分层结构自适应双 LSTM [29] 进行视频场景摘要。 层次结构的两层分别用于检测镜头边界和总结视频场景。 首先,我们使用 VGG-16 [31] 提取视频序列特征(v1,v2,…,vk),然后我们引入第一个双向 LSTM 层,通过以下公式对序列特征进行操作


最后,当计算完所有的视频帧后,我们将得到所有的镜头特征序列(s1, s2, …, sn)。 在提取镜头边界特征后,我们引入 Bi-LSTM 网络来总结可以表达的场景视频情绪。 具体计算过程与第一层类似。

其中h2,f和h2,b表示 两个tt方向的隐藏层状态,Ws⃗h和W⃗h⃗h是可学习的权重矩阵。 该层的输出是通过以下公式计算视频摘要的镜头特征的可能性
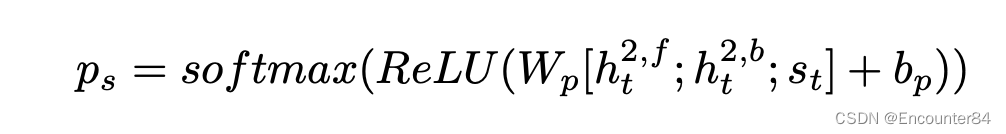
最后的输出是 总结了能够反映视频情感的场景和相应的镜头特征序列。 C. 基于GCN 的对象关系推理视频中的对象包含丰富的情感线索,例如,花通常带来积极的情绪,而血液可能代表悲伤和恐惧。 为了计算不同对象之间的情感关系,我们结合注意力机制和 GCN 来寻找对视频内容的情感分析最有贡献的区域。 a) 视频的图表示提取:我们的目标是构建一个情感关系图来推理视频中不同对象之间的情感关系。 为了从视频中学习视觉表示,我们使用 3D 卷积神经网络 (C3D) [32] 来提取视频的不同级别的时空特征,获得的特征图的维度为 T × H × W × d 。 为了获得节点特征表示,我们引入了 RPN [33] 来生成区域建议,然后应用 RoIAlign [34] 来提取包含对象的特征。
b) 情感关系图:在获得节点特征后,我们构建了一个相似度图[23]来衡量对象之间的情感强度,相似度图不仅学习了同一帧中不同提议之间的情感关系,而且还捕捉了情感 不同视频帧中相同提议的关联。 具体来说,我们将每个提案的特征视为一个节点,并通过测量对象之间的相似性来构建相似度图。 情感关系图的邻接矩阵的非零元素为1,表示该节点的所有相邻节点,可以用来衡量两个节点表达相同情感的可能性。 但并非每个节点对情感分析的贡献都相同,为了找到对视频情感分析贡献最大的节点,我们引入了一种注意力机制,为连接到节点 i 的每条边分配一个权重系数。 权重系数由前馈神经网络(FNN)获得。















 2387
2387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









