






- 什么是爬虫
网络爬虫,是一种按照一点过规则,自动抓取互联网信息的程序或脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关文件网页并分析已成为如今主流的抓取策略。
- 爬虫可以做什么
可以抓取图片,爬取自己想看的视频等等,只要你你能通过浏览器访问的数据都可以通过爬虫获取。
- 爬虫的本质
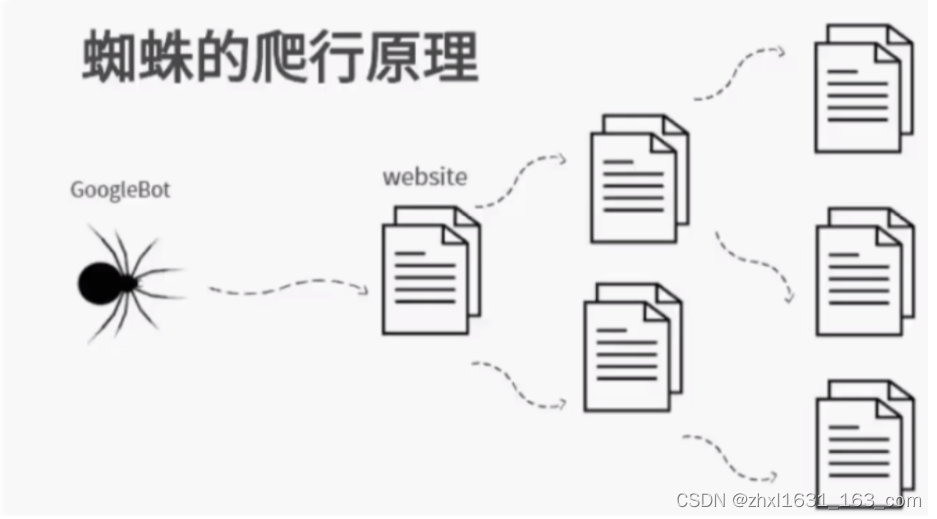
模拟浏览器打开网页,获取网页中我们想要的部分数据。
- 任务
爬取豆瓣电影Top250的基本信息,包括电影的名称,豆瓣评分,评价数据,电影概况,电影链接等。豆瓣电影 Top 250
- 基本步骤简解
- 获取数据
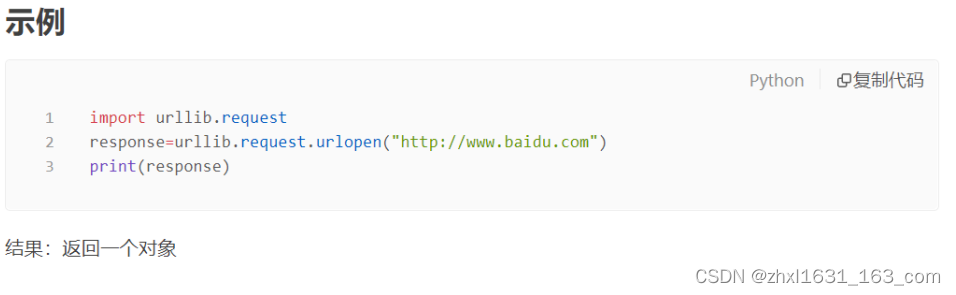
urllib.request 模块提供了最基本的构造 HTTP (或其他协议如 FTP)请求的方法,利用它可以模拟浏览器的一个请求发起过程。利用不同的协议去获取 URL 信息。它的某些接口能够处理基础认证 ( Basic Authenticaton) 、redirections (HTTP 重定向)、 Cookies (浏览器 Cookies)等情况。而这些接口是由 handlers 和 openers 对象提供的。
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
参数说明:
url:需要打开的网址 data: Post 提交的数据, 默认为 None ,当 data 不为 None 时, urlopen() 提交方式为 Post timeout:设置网站访问超时时间。urlopen 返回对象是 HTTPResposne 类型对象

-
- 解析内容
BeautifulSoup4简称bs4,将复杂的HTML文档转换成一个复杂的树形结构,每个结点都是python对象。BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
-
- 保存数据
保存数据一般有两种:保存为本地文件、保存到数据库。本文主要演示前者。
open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
参数说明:
name : 一个包含了你要访问的文件名称的字符串值。
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
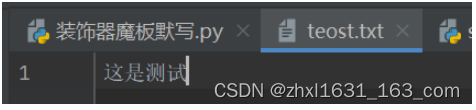
如下以w 模式往teost.txt下写入“这是测试”。

对应目录下写入文件。
- 实例
- 导入包
"""
我的一个简单爬虫
爬取豆瓣电影Top250的基本信息,包括电影的名称,豆瓣评分,评价数据,电影概况,电影链接等。
"""
import os
import time
import re
import urllib.request
from bs4 import BeautifulSoup-
- 获取数据
# 1. 获取数据
# url = "https://movie.douban.com/top250?start=0"
# 模拟浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/75.0.3770.100 Safari/537.36 "
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# print(response.read().decode('utf-8'))-
- 解析数据
# 2. 解析数据
soup = BeautifulSoup(response, 'html.parser')
lis = soup.select("ol li")
for li in lis:
index = li.find('em').text
title = li.find('span', class_='title').text
rating = li.find('span', class_='rating_num').text
strInfo = re.search("(?<=<br/>).*?(?=<)", str(li.select_one(".bd p")), re.S | re.M).group().strip()
infos = strInfo.split('/')
year = infos[0].strip()
area = infos[1].strip()
movie_type = infos[2].strip()-
- 保存数据
def write_fo_file(index, title, rating, year, area, type):
f = open('movie_info.csv', 'a')
f.write(f'{index},{title},{rating},{year},{area},{type}\n')
f.closed-
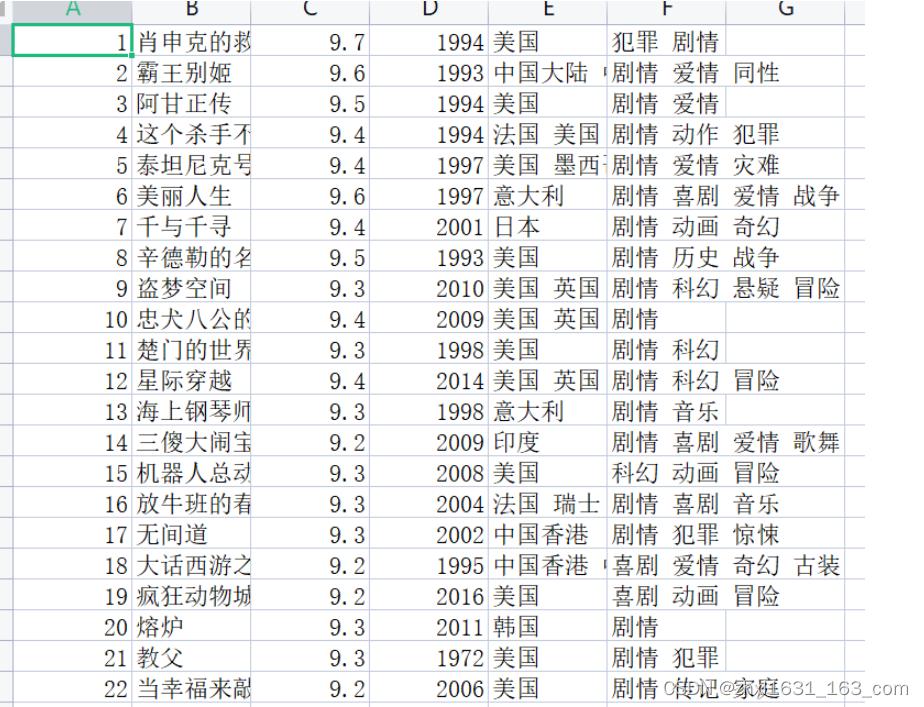
- 运行结果

保存数据到本地。

- 附件
完整代码。
"""
爬取豆瓣电影Top250
"""
import os
import re
import time
import urllib.request
from bs4 import BeautifulSoup
def download(url, page):
print(f"正在爬取:{url}")
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/75.0.3770.100 Safari/537.36 "
}
req = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, 'html.parser')
lis = soup.select("ol li")
for li in lis:
index = li.find('em').text
title = li.find('span', class_='title').text
rating = li.find('span', class_='rating_num').text
strInfo = re.search("(?<=<br/>).*?(?=<)", str(li.select_one(".bd p")), re.S | re.M).group().strip()
infos = strInfo.split('/')
year = infos[0].strip()
area = infos[1].strip()
type = infos[2].strip()
write_fo_file(index, title, rating, year, area, type)
page += 25
if page < 250:
time.sleep(2)
download(f"https://movie.douban.com/top250?start={page}&filter=", page)
def write_fo_file(index, title, rating, year, area, type):
f = open('movie_top250.csv', 'a')
f.write(f'{index},{title},{rating},{year},{area},{type}\n')
f.closed
def main():
if os.path.exists('movie_top250.csv'):
os.remove('movie_top250.csv')
url = 'https://movie.douban.com/top250'
download(url, 0)
print("爬取完毕。")
if __name__ == '__main__':
main()
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











