







海量数据分析:Sawzall并行处理(中文版论文)
Google的工程师为了方便内部人员使用MapReduce,研发了一种名为Sawzall的DSL,同时Hadoop也推出了类似Sawzall的Pig语言,但在语法上面有一定的区别。今天就给大家贴一下Sawall的论文,值得注意的是其第一作者是UNIX大师之一(Rob Pike)。
概要
超大量的数据往往会采用一种平面的正则结构,存放于跨越多个计算机的多个磁盘上。这方面的例子包括了电话通话记录,网络日志,web文档库等等。只要这些超大量的数据集不能装在单个关系数据库里边的时候,传统的数据库技术对于研究这些超大数据集来说那就是没有意义的。此外,对于这些数据集的分析可以展示成为应用简单的,便于分布式处理的计算方法:比如过滤,聚合,统计抽取,等等。我们在这里介绍这样一种这样的自动化分析系统。在过滤阶段,查询请求通过一种全新的编程语言来快速执行,把数据处理到聚合阶段。无论过滤阶段还是聚合阶段都是分布在上百台甚至上千台计算机上执行的。他们的结果通过比较并且保存到一个文件。这个系统的设计-包括分成两阶段,以及这种新式的编程语言,聚合器的特性-都是在数据和计算分布在很多台机器上的情况下,内嵌使用并行机制的。
1.介绍
有不少数据集都是超大的,或者非常动态,或者就是因为太笨拙了,而不能有效地通过关系数据库进行管理。典型的场景是一组大量无格式文件-有时候是上petabytes(2的50次方1,125,899,906,842,624)-分布在多个计算机上的多个磁盘上。这些文件都包含了无数的记录,这些记录是通常会通过一个轴来组织,比如通过时间轴或者地理轴进行组织。例如:这堆文件可能包含一个web网页仓库,用来构造internet搜索引擎的索引系统,或者这堆文件用来记录上千台在线服务器的健康日志,或者用来记录电话呼叫记录或者商业交易日至,网络包记录,web服务器查询记录,或者高级一点的数据比如卫星图像等等。但是对这些数据的分析经常可以表示成为简单的操作,远比普通SQL查询要简单得操作来完成。举一个例子,我们通常会统计满足某条件的记录数,或者抽取这些记录,或者查询异常记录,或者构造记录中某一个域值的频率柱状图。另一方面,查询也可能会较为复杂,但是这些查询依旧可以展示成为通过一系列简单查询来完成,这些简单查询都可以简单映射到这些文件的记录集上。
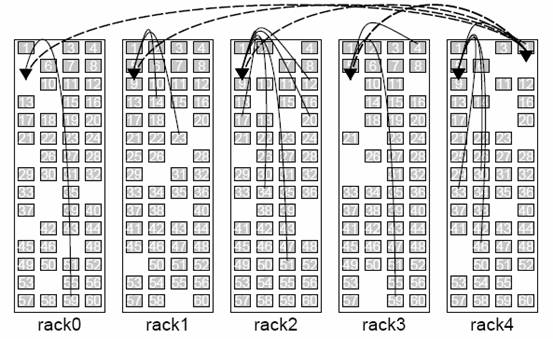
图1:5组机架,每组有50-55台计算机,每台计算机有4个磁盘。这样一个架构可以有到250TB的待分析数据量。我们可以在250台以上的计算机上分别执行过滤来极大的的提高并行度,并且把他们的结果通过网络汇聚到一起(参见弧线)
由于数据记录存放在多台计算机上,那么用这些计算机本身的能力来进行分析的方法就相当有效。特别是,当单独每一个步骤都可以表示成为每次对独立的记录进行操作的时候,我们就可以把计算分布到所有这些机器上,这样就能达到相当高的吞吐量。(前边提及的每个例子都有这样的特点)。这些简单操作都要求一个聚合的阶段。例如,如果我们统计记录数,我们需要把每一个机器统计出来的记录数相加,作为最终的输出结果。
所以,我们把我们的计算分成两个阶段。第一个阶段我们对每一条记录分别计算,第二个阶段我们聚合这些结果(图2)。本论文描述的系统更进一步考虑了这个问题。我们用一个全新的编程语言来进行第一个阶段的分析,从处理粒度上,它一次处理一条记录,并且在阶段2严格限制预先定义的处理阶段1产出物的聚合器处理的集合。通过约束本模式的计算量,我们可以达到非常高的吞吐量。虽然并非所有的计算都能适合这样的模式,但是仅仅通过不多的代码就能够驱动上千台机器并行计算还是很划算的。
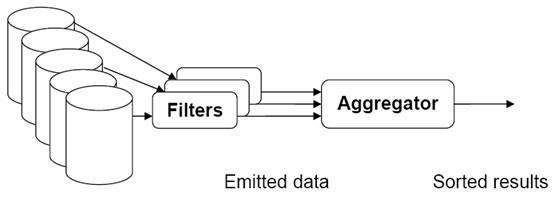
RAW DA
图2:总体数据流图,过滤,聚合和比较。每一步都比上一步产生更少的数据。
当然,我们还有很多小问题要解决。计算必须要分解成为小块并且分布到每一个存储数据的节点上进行执行,尽量让计算和数据在一台机器上以避免网络瓶颈。由于使用的机器越多,那么越有可能有机器会在运算中宕机,所以,必须系统必须要有容错能力。这些都是困难但是有趣的问题,但是他们都必须能够在没有人为干预的情况下完成。Google有好几个这样的基础架构,包括GFS[9]和MapReduce[8],通过容错技术和可靠性设计来提供了一个非常强大的框架,可以用来实现一个很大的,分布式处理的并行系统。因此我们着重于我们的目标:清晰的表达分析处理,并且迅速执行分析处理。
2.总览
简要而言,我们的系统通过处理用户提交的用特别设计的编程语言写成的查询,并发的在分布到大量机器上的记录集中,进行记录级别的查询,并且搜集查询结果,通过一组高性能的聚合器进行查询结果的汇聚。这两部发呢别执行,通常分布到不同的计算机集群上。
这样的处理典型类型是并发处理分布在成百上千台计算机上的gigabyte或者数Tbyte数据。一个简单的分析可能需要花去一个CPU好几个月的时间,但是通过上千台计算机的并行处理,只需要几个小时的时间就能处理完。
有两个条件决定着系统的设计。首先,如果查询操作是对记录间可交换的,就是说记录处理的先后顺序是不重要的。我们于是可以用任意的顺序来处理这个查询操作。第二,如果聚合操作是可交换的,中间结果的处理顺序是不重要的。此外,如果他们也是可结合的,中间处理结果可以被任意分组或者分成不同的步骤进行聚合。举一个例子,对于统计数量包括汇总数量来说,无论中间结果如何的累加或者分组结合累加,他们最终的结果都不会受到影响。这个交换性和结合性的约束并不算过分苛刻,他们可以提供很广阔的查寻范围,包括:统计,筛选,取样,柱状图,寻找常见项目,等等。
虽然聚合器组是有限的,但是对于查询阶段来说,应当包括更加通用的内容,我们介绍一种新的解释执行的程序语言Sawzall[1](解释语言的性能已经足够了:因为程序多数都是比较小的,而且他们需要处理的数据往往很大,所以往往是受I/O的限制,这在性能的章节有所讨论)
一个分析操作如下:首先输入被分解成为要被处理的数据小块,也许是一组独立的文件或者一组记录,这些记录或者文件分布于多个存储节点上。数据小块可以远远多于计算机的数量。
其次,Sawzall解释器开始处理每一个小块数据。这个处理跨越了大量机器,也许数据和机器绑定在一起,也可能数据在临近的机器上而不在一起。
Sawzall程序分别处理每一个输入记录。每一个记录的输出结果,0个或者多个中间结果值-整数,字串,key-value pairs,tuple等等-将和其他记录的输出值合并。
这些中间结果于是被发送到运行聚合器的进一步处理的结点上,这些节点比较和减少中间结果,并且构造终结结果。在一个典型的运行中,主要的计算机集群会运行Sawzall,并且小一点的集群会运行聚合器,这样的结构反映不仅是体现在计算量的差异,也体现在网络负载的均衡考虑;每一个步骤,数据流量都比上一个步骤要少(参见图2)。
当所有的处理都完成之后,结果将被排序,格式化,并且保存到一个文件。
3.例子
用这个简单的例子可以更清楚的表达这样的想法。我们说我们的输入是一个由浮点数记录组成的文件集合。这个完整的Sawzall程序将会读取输入并且产生三个结果:记录数,值得总合,并且值得平方和。
count: table sum of int;
total: table sum of float;
sum_of_squares: table sum of float;
x: float=input;
emit count<-1;
emit sum<-x;
emit sum_of_squares <- x*x;
前三行定义了聚合器:计数器,合计,平方和。关键字table定义了聚合器类型;在Sawzall中,即使聚合器可能是单例的,也叫做table。这些特定的table是属于合计的table;他们把输入的整数或者浮点数的值进行累加。
对于每一个输入的记录,Sawzall初始化预定义的变量input来装载尚未处理的输入记录二进制串。因此,行:
x: float = input;
把输入记录从它对外的表示转换成为内嵌的浮点数,并且保存在本地变量x。最后,三个emit语句发送中间结果到聚合器。
当程序执行的时候,程序对每一个输入记录只执行1次。程序定义的本地变量每次重新创建,但是程序定义的table会在所有执行中共享。处理过的值会通过全局表进行累加。当所有记录都处理了以后,表中的值保存在一个或者多个文件中。
接下来的几节讲述了本系统所基于的部分Google的基础架构:协议buffers,Google文件系统,工作队列,MapReduce。后续章节描述语言和其他系统的详尽部分。
4.协议Buffer
虽然在最开始已经考虑了定义服务器之间的消息通讯,Google的协议Buffer也同样用于描述保存在磁盘的持久化存储的记录格式。
这个协议Buffer的用处很类似XML,但是要紧凑的多,通过一个二进制的表示以及一个外部的数据描述语言(DataDescription Language DDL)是的协议编译器能够把协议编译成为各种语言的支持代码。
DDL构造一个清晰,紧凑,可扩展的针对二进制记录的描述,并且对记录的字段进行命名。虽然二进制格式已经是相当紧凑的,但是常常还会在保存到磁盘的时候再进行一个压缩,包裹一个压缩层。
协议编译器读取DDL描述并且产生用于对数据的:组织,访问,列集及散列处理的代码。编译时候的标志指定了输出的语言:C++,Java,Python,等等。这个产生的代码通过嵌入应用程序中,能够提供对数据记录高效简洁的访问。同时,也应该提供验证和调试保存的协议buffer的工具包
我们系统操作的大部分数据集都是按照协议buffer约定的格式存储的记录。协议编译器通过增加对Sawzall的扩展来提供在新语言下的协议buffer的高效IO性能。
5.Google文件系统(GFS)
我们系统访问的数据集通常保存在GFS内,就是Goole的文件系统[9]。GFS提供一个可靠的分布式存储系统,它可以通过分布在上千台计算机的64M”块”组织成为上Petabyte级别的文件系统。每一个块都有备份,通常是3个备份,在不同的计算机节点上,这样GFS可以无缝的从磁盘或者计算机的故障中容错。
GFS是一个应用级别的文件系统,有着传统的分级的命名机制。数据集本身通常用一个常规的结构存放,这些结构存放在很多独立的GFS文件中,每一个GFS文件大小接近1G。例如,一个文档仓库(web搜索器机器人探索结果),包含数十亿HTMLpages,可能会存放在上千个文件中,每一个文件压缩存放百万级别的文档,每个文档大概有数K字节大小。
6.工作队列和MapReduce
把工作安排到一组计算机集群上进行工作的处理软件叫做(稍稍有点容易误解)工作队列。工作队列很有效的在一组计算机及其磁盘组上创建了一个大尺度的分时共享机制。它调度任务,分配资源,报告状态,并且汇集结果。
工作队列和Condor[15]等其他系统比较类似。我们经常把工作队列集群和GFS集群部署在相同的计算机集群上。这是因为GFS是一个存储系统,CPU通常负载不太高,在CPU空闲阶段可以用来运行工作队列任务。
MapReduce[8]是一个运行在工作队列上的应用程序库。它提供三个主要功能。首先,它提供一个给予大量数据的并行处理的程序运行模式。第二,它把应用从运行在分布式程序的细节中隔离出来,包括类似数据分布,调度,容错等等。最后,当发现条件许可时,各个计算机或者存储自己的GFS数据节点上的应用程序可以执行计算,减少网络的流量。
就是MapReduce名字说明的含义,这个执行模式分成两个步骤:第一个步骤是把一个执行操作映射到数据集合的全部元素;第二个步骤是简化第一个步骤地输出结果,并且产生最终的应答。例如,一个使用MapReduce的排序程序将会映射一个标准的排序算法到数据集和的每一个文件上,接下来就是运行一个合并排序程序来简化第一个步骤出来的单独结果,并且产生最终地输出。在上千台机器的Cluster中,一个MapReduce程序可以用每秒排序1G数据的速度排序上TB的数据[9]。
我们的数据处理系统是基于MapReduce的最上层的。Sawzall解释器运行在映射步骤。这是在大量机器上并发完成的,每一个执行实例处理一个文件或者一个GFS块。Sawzall程序对每一个数据集的记录执行只执行一次。映射步骤地输出是一个数据项的集合,并且是交给聚合器去处理。聚合器在简化/减少的步骤运行来合并结果成为最终的输出结果。
接下来的章节讲述这些处理的细节。
7.Sawzall语言概览
作为一种查询语言,Sawzall是一种类型安全的脚本语言。由于Sawzall自身处理了很多问题,所以完成相同功能的代码就简化了非常多-与MapReduce的C++代码相比简化了10倍不止。
Sawzall语法和表达式很大一部分都是从C照搬过来的;包括for循环,while循环,if语句等等都和C里边的很类似。定义部分借鉴了传统Pascal的模式:
i: int ; # a simple integer declaration;
i: int=0; # a declaration with an initial value;
基本类型包括整数(int),是64位有符号值;浮点数(float),是一个double精度的IEEE浮点数;以及很类似整数的time和fingerprint。time是毫秒级别的时间,并且函数库包括了对这个类型的转换和操作。fingerprint是一个执行定义的hash值,可以很容易通过建立数据的fingerprint来构造聚合器索引。
同时,Sawzall也有两种基本的数组类型:bytes,类似C的unsigned char的数组;string,string用来存放UNICODE的字符串。在Sawzall中没有”字符”类型;byte数组和string的基本元素是int,而虽然int的容量远比字节或者字符串的基本元素来得大。
复合类型包括数组,maps(本文档中是可以重载概念),tuples。数组是用整数作为下标检索的,maps是结合了数组或者Python字典的类型,可以用任意类型检索,可以根据需要建立无序的索引。最后tuples是对数据的任意分组,类似C或者PASCAL的结构类型。任何类型都可以有一个正式的名字。
类型转换操作是把数据从一种类型转换成为另一种类型,并且Sawzall提供了很广泛的类型转换。例如,把一个字符串表示的浮点数转换成为一个浮点数:
f: float;
s: string = "1.234";
f = float(s);
部分转换是可以带参数的:
string(1234, 16)
就可以把一个整数转换成为一个16进制的字符串。并且:
string(utf8_bytes, "UTF-8")
转换一个UTF-8的byte数组成为一个unicode字符串。
为了方便起见,并且为了避免某些语言定义上的啰嗦,编译器可以在初始化定义的时候隐含的左适当的转换操作(使用缺省的转换参数)。因此:
b: bytes = "Hello, world!\n";
等价于显示的转换:
b: bytes = bytes("Hello, world!\n", "UTF-8");
任何类型的值都可以转换成为字符串,这是为了调试的方便考虑。
Sawzall最重要的转换是和协议buffer相关的。Sawzall有一个编译时刻参数:proto,有点类似C的#include指令,可以从一个定义了Sawzall tuple类型的文件加载DDL协议buffer。通过tuple描述,就可以转换输入的协议buffer到Sawzall的值了。
对于每一个输入记录,解释器都需要把这个由二进制数组表达的值初始化到特定的输入变量中,尤其是转换到协议buffer类型的输入变量中去。Sawzall程序对于每一个记录的执行都是由下边这条语句隐式执行的:
input: bytes = next_record_from_input();
因此,如果文件:some_record.proto包含了类型Record的协议buffer的定义,那么下边的代码会把每一个输入记录分析道变量r中:
proto "some_record.proto" # define ’Record’
r: Record = input; # convert input to Record
Sawzall有很多其他的传统特性,比如函数以及一个很广泛的选择基础函数库。在基础函数库中是给调用代码使用的国际化的函数,文档分析函数等等。
7.1.输入和聚合
虽然在语句级别Sawzall是一个很传统的语言,但是它有两个非常不寻常的特性,都在某种意义上超越了这个语言本身:
Sawzall程序定义了对于数据的单个记录的操作。这个语言没有提供任何可以同时处理多条记录的方法,以及没有提供通过一个输入记录的值来影响另一个记录的方法。
这个语言为一个输出时emit语句,这个语句发送数据到一个外部的聚合器来汇聚每一个记录的结果并且在聚合器进行结果的加工和处理。
因此普通的Sawzall程序行为是使用输入变量,用转换操作把输入的记录分析到一个数据结构,检查数据,并且处理成一些值。我们在第三节可以看到这种模式的一个简单例子。
下边是一个更有代表性的Sawzall程序例子。对于给定的我们原代码管理系统的源代码提交记录集合,这个程序会用分钟级别的分辨率,给出周的提交变化频率表。
proto "p4stat.proto"
submitsthroughweek: table sum[minute: int] of count: int;
log: P4ChangelistStats = input;
t: time = log.time; # microseconds
minute: int = minuteof(t)+60*(hourof(t)+24*(dayofweek(t)-1));
emit submitsthroughweek[minute] <- 1;
这个程序一开始从文件p4stat.proto引入了协议buffer描述。在这个文件中定义了类型: P4ChangelistSTats(程序员必须明确知道这个类型是从proto引入的,而且还要知道这个是由协议bufferDDL定义的)
接下来就是定义了submitsthroughweek。它定义了一个sum值得table,这个table使用一个整数minute作为下标。注意index值在table定义的时候是给出了一个可选的名字(minute)。这个名字没有任何语义,但是使得这个定义更容易理解,并且提供了一个聚合输出的域标签。
log的定义把输入的byte数组转换成为Sawzall的类型:P4ChangelistStats,这个转换是用(proto语句引入的代码转换的),这个类型是tuple类型,保存在输入变量log里边。接着我们把time值取出来,并且接着就保存到变量t中。
接下来的定义有着更复杂的初始化表达式,这个表达式使用了一部分内嵌的函数,用来从time值来计算基准的周分钟基线数字[2]。
最后,emit语句通过增加该分钟的数字来统计这个提交情况。
总结一下,这个程序,对于每一个记录,都取得时间戳,把时间转换成为本周的分钟数,然后在这周的对应分钟发生次数增加1。并且,隐式的,这个会重新取下一个记录进行循环处理。
当我们在全部的提交日志上运行这个程序,这个记录跨越了很多个月,并且输出结果,我们可以看到一个按照分钟区分的聚合的周活动趋势。输出结果可能像这样的:
submitsthroughweek[0] = 27
submitsthroughweek[1] = 31
submitsthroughweek[2] = 52
submitsthroughweek[3] = 41
…
submitsthroughweek[10079] = 34
当使用图像表达,那么这个图就像图三一样。
我们举这个例子要表达的意思当然不是说这个提交源码的频率数据如何如何,而是说这个程序怎样产生抽取这个数据出来。
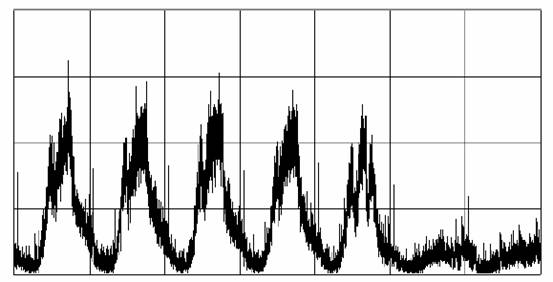
图3:周源代码提交频率。本图从周一早上凌晨0点开始。
7.2.聚合器补充说明
因为某些原因,我们在本语言之外完成聚合。应该由一个传统的语言来用语言处理能力本身来处理结果,但是由于聚合的算法可能会相当的复杂,最好用某种形式的机器语言来实现。更重要的是,虽然在语言层面上隐藏了并行的机制,但是在过滤阶段和聚合阶段划一条清晰的界限能够有助于更高级别的并行处理。在Sawzall中不存在记录的多样性的,在Sawzall典型任务就是在上百或者上千台机器上并发操作上百万条记录,
集中精力在聚合器上可以创造出很不寻常的聚合器。现在已经有许多聚合器;下边是一个不完整的列表:
● 搜集器
c: table collection of string;
一个简单的输出结果列表,这个结果在列表中是任意顺序的。
● 采样器
s: table sample(100) of string
类似搜集器,但是存的是无偏差的输出结构的采样值。这个采样的大小是用参数体现的。
● 累加
s: table sum of (count:int,revenue:float);
所有输出结果的合计。这个输出结果必须是算数的或者可以以算术为基础的(也就是可累加的,by 译者),就像例子中的tuple结构那样(也就是说一般可以是sum of int,也可以像上边说的一样,可以用sum of (count:int,revenue:float)这样的tuple结构。对于复合值,元素是按照内部的项进行累加的。在上边的例子,如果count始终为1,那么平均revenue可以在处理完和以后用revenue除以count来得到。
● 最大值
m: table maximum(10) of string weight length: int;
取得最大权重的值。每一个值都有一个权重,并且最终选择的值是根据最大权重来选择的。这个参数(例子中是10)规定了需要保留的最终输出的值数量。权重是以明确的keyword来描述的,并且它的类型(这里是int)是在这里定义的,它的值是emit语句给出的。对上边例子来说,emit语句如下:
emit m <- s weight len(s);
这样将会在结果中放置最长的字符串。
● 分位数
q: table quantile(101) of response_in_ms:int;
是用输出的值来构造一个每个概率增量分位数的累计概率分布(算法是一个Greenwald和Khanna的分布式算法[10])。这个例子可以用来查看系统的响应变化的分布情况。通过参数101,这个参数用来计算百分点。第50个元素是中间点的响应时间,第99个元素是99%的响应时间都小于等于第99个元素。
● 最常见
c: table top(10) of language: string;
top table评估这个值是否最常见(与之对应的,maximun table找到最高权重的值,而不是最常见的值)
例如:
emit t <- language_of_document(input);
将会从文档库中建立10个最常见的语言。对于很大的数据集来说,它可能需要花费过大的代价来找到精确的出席频率的order,但是可以有很有效的评估算法。top table是用了Charikar,Chen,Farach-Colton[5]的分布式算法。算法返回的最常见的频率是极为接近真实的出现频率。因为它的交换性和结合性也不是完全精确的:改变处理的输入记录先后顺序确实会影响到最终的结果。作为弥补措施,我们在统计元素个数之外,也要统计这些个数的误差。如果这个误差和元素个数相比比较小,那么结果的正确度就比较高,如果错误相对来说比较大,那么结果就比较差。对于分布不均匀的大型数据集来说,top table工作的很好。但是在少数情况下比如分布均匀的情况下,可能会导致工作的不是很成功。
● 取唯一
u: table unique(10000) of string;
unique table是比较特别的。它报告的是提交给他的唯一数据项的估计大小。sum table可以用来计算数据项的总和个数,但是一个unique table会忽略掉重复部分;最终计算输入值集合得大小。unique table同样特别无论输入的值是什么类型,它的输出总是一个count。这个参数是给出了内部使用的table大小,这个是用来内部作评估是用的内部表;10000的参数值会让最终结果有95%的概率正负2%的误差得到正确的结果(对于N,标准偏差是大概N*参数**(-1/2))
有时候也会有新的聚合器出来。虽然聚合器用处很大,但是增加一个新的聚合器还算容易。聚合器的实现复杂在需要支持所有解释器所支持的数据类型。聚合器的实现还需要效验某些类型(校验参数值和元素类型),并且对保存和读取数据作打包。对于简单的聚合器,类似sum,就没有什么其他的要求了。对于更复杂的聚合器,类似分位数和top,必须注意要选择一个符合交换律和结合律的算法,并且这个算法要在分布式处理上有足够的效率。我们最小的聚合器实现上大概只用了200行C++代码,最大的聚合器用了大概1000行代码。
有些聚合器可以作为map阶段来处理数据,这样可以降低聚合器的网络带宽。例如sum table可以本地作各个元素的累加,只是最后把本部分的小计发往远端的聚合器。用MapReduce的词语来说,这就是MapReduce的合并阶段,一种在map和reduce中间的优化阶段。
7.3.带索引的聚合器
聚合器可以是带索引的,这个可以使得每一个索引下标的值都有一个单独的聚合器。这个index可以是任意的Sawzall类型,并且可以是一个聚合器的多维的结构下标。
例如,如果我们检查web服务器的log,table:
table top(1000)[country:string][hour:int] of request:string;
可以用来找到每一个国家每一个小时的最常用的请求字串。
当新的索引值产生的时候,就会动态产生一个独立的聚合器,某种意义上比较类似map,但是是和所有运行的机器无关。聚合阶段会比较每一个索引下标对应的值,并且产生适当的聚合值给每一个索引值。
作为整理的一部分,数据值将按照索引排序,这样使得从不同机器上合并最终结果比较容易。当任务完成的时候,输出值就按照索引进行排序了,这就意味着聚合器的输出是索引顺序的。
index本身就是构造了一个有用的信息。就像上边讲述的web服务器的例子,当运行完以后,在country索引的记录中就构造了请求接收到的国家集合。另外,index的引入使得可以用index对结果集进行分类。table sum[country:string] of int产生的索引结果将会等同于去掉重复项以后的table collection of country:string的结果值。
8.System Model
下边介绍本语言的基本特性,通过对数据分析的建立,我们可以给出高级别的系统模式概览。
系统运行是基于一个批处理的模式的:用户提交一个工作,这个工作分布在一个固定的文件集合上,并且在执行完成以后搜集输出的结果。输入格式和数据源(通常是文件集)以及输出目标都是在程序语言外指定的,通过执行工作的参数形式来递交给系统进行执行。
当系统接收到一个工作请求,Sawzall处理器就开始效验这个程序是否语法正确。如果语法正确,源代码就发送给各个将被执行的机器,每一个机器就开始分析代码并且开始执行。
每一个执行的机器的输出都分不到一组文件中,每一个文件都部署在一个聚合器机器上。这个输出结果拆分到不同的机器上,是为了能让聚合器并行工作。我们给予特定的table和他上边的相关索引来确定这些分布在各个文件中的值。
基于table的类型,输入table的值可以是最终格式的值,也可以是某种中间结果的值,这些中间结果便于进行合并或者处理。这种合并处理必须能够良好的结合起来才能工作的一个步骤。某些工作由于十分巨大,而结合率允许他们拆成多个小块,并行运行,最后再合并在一起。(这是本系统的一个优势,优于平坦模式的MapReduce;因为MapReduce可能会在一个需要运行几天几周的任务上出问题)
通常,分解处理以后的数据要比输入要小得多,但是也会有某些关键的应用不是这样的。例如,我们的程序可以用一个带索引的collection table来对数据作多维的组织,在这样的情况下,输出结果就可能比输入要多。
Sawzall中一个常用的输入是把结果数据注入一个传统的关系数据库中,以备后续的分析。通常这些都是有不同的用户程序来注入,也许是用Python,它把数据转换成为通过SQL指令建立的表。我们以后也许会提供更多的直接方法来完成八结果注入到数据库的动作。
Sawzall的结果有时也用于其它Sawzall程序的输入,这个就是链式处理。链式处理的简单例子就是精确计算输出的”top 10”列表。Sawzall的top table虽然高效,但是他不精确。如果需要精确的结果,那么就需要分为两个步骤。第一步创建一个带索应的sum table来统计输入值得频率;第二个步骤是用一个maximum table来选择最常见的频率。这样可能有点笨,但是这种方法依旧是非常高效的方法来计算多维的table。
9.例子
这里是另外一个完整的例子,演示了Sawzall在实际中如何使用。这里是处理一个web文档库,并且产生一个结果:对于每一个web服务器,那一个page有着最高的Page Rank[13]?答曰来说,那一个是最多link指向的page?
proto “document.proto”
max_pagerank_uri:
table maximun(1)[domain:string] of url:string
weight pagerank:int;
doc: Document = input;
url: string = doc.url;
emit max_pagerank_url[domain(url)] <- url
weight doc.pagerank;
protocol buffer 的格式是在”document.proto”中定义的。这个table是max_pagerank_url,并且会纪录每一个索引中最高权重的值。这个索引是domain,值是URL,权重势document的PageRank。程序处理输入的纪录,解出URL,并且执行相关的emit语句。它会调用库函数 domain(url)来解出URL所对应的domain,并且使用这个domain作为index,把URL作为值,并且用这个document对应的PageRank作为权重。
当这个程序在一个数据仓库上运行的时候,输出对于大部分site,most-linked网页是www.site.com-真是令人惊讶。Acrobat 下载站点是adobe.com的top page,并且连接到banknotes.com的就是连接到连接最多的图库站点,并且bangkok-th.com是最多引用的夜生活page。
因为是用Sawzall能简单表达这样的计算,所以程序是又简洁又优美。即使用了MapReduce,等价的C++程序也要好几百行代码。
下边是一个例子,使用了多维索引的聚合器。我们目的是通过检索搜索log,建立一个查询发起点的世界地图。
proto “querylog.proto”
queries_per_degree: table sum[lat:int][lon:int] of int;
log_record: QueryLogProto = input;
loc: Location = locationinfo(log_record.ip);
emit queries_per_degreee[int(loc.lat)][int(loc.lon)] <- 1;
这个程序相当直接,我们引入查询log的DDL,定义一个用了经纬作索引的table,并且从log中解包查询。接着我们是用内嵌函数把这个IP地址对应到请求及其的位置(可能是ISP的位置),并且为每一个经纬点增加1。int(loc.lat)把loc.lat,一个浮点值转换成为一个整数,截断成为一个维数下标。对于高分辨的地图来说,可能要求更精细的计算。
这个程序的输出是一个数组,可以用来构造一个地图,参见图4。
10.执行模式
在语句级别,Sawzall是一个常规的语言,但是从更高的角度看,他有一些特点,所有的设计目的都是为了并行计算。
当然,最重要的是,一次处理一个纪录。这就意味着,其他纪录的处理将不消耗额外的内存(除了在语言本身外把结果提交给聚合器)。Sawzall在上千台机器上并行执行,是Sawzall的一个设计目的,并且系统要求这些机器之间没有额外的通讯。唯一的通讯就是从Sawzall的执行结果下载到聚合器。

图四:查询分布
为了强调这点,我们用计算输入记录数的数量来入手。就像我们之前看到的这个程序:
count: table sum of int;
emit count <- 1;
这个程序将完成统计记录数的工作。与之对比的是,如下的一个错误的程序:
count: int = 0;
count ++;
这个程序将不能统计记录数,因为,对于每一个记录来说,count都被设置成为0,然后再++,最后结果就扔掉了。当然,并行到大量机器上执行,扔掉count的效率当然很高。
在处理每一个记录之前,Sawzall程序都会回到初始的状态。类似的,处理完成一条记录,并且提交了所有的相关的数据给聚合器后,任何执行过程中使用到的资源—变量—临时空间等等—都可以被废弃。Sawzall因此使用的是一个arena allocator[11](单向递增分配,场地分配策略,就是说,从一个内存池中通过单向增加一个指针的方式来分配内存,类似零散内存的管理方式)。当一个记录都处理完成之后,就释放到初始状态。
在某些情况下,重新初始化是不需要的。例如,我们可能会创建一个很大的数组或者影射表来对每条记录进行分析。为了避免对每条记录都作这样的初始化,Sawzall有一个保留字static可以确保这个变量只初始化一次,并且是在处理每条记录的最开始的初始化的时候执行。这就是一个例子:
static CJK: map[string] of string = {
“zh” : “Chinese”,
“jp”:”Japanese”,
“ko”,”Korean”,
};
CJK变量会在初始化的时候创建,并且作为处理每条记录的初始化的时候都保留CJK变量的值。
Sawzall没有引用类型;它是纯粹值语义的。数组和maps也可以作为值来是用(实现的时候,在大部分情况下,用copy-on-write引用计算来提高效率)。某些时候这个比较笨拙-在一个函数中修改一个数组,那么这个函数必须返回一个函数-但是在典型的Sawzall程序中,这个并没有太大的影响。但是这样的好处,就可以使得并发处理记录的时候,不需要担心同步问题或者担心交叉使用的问题,虽然实现上很少会用到这个情况。
11.语言的Domain相关特性
为了解决domain操作的问题,Sawzall有许多domain相关的特性。有一部分已经讨论过了,本节讨论的是剩下的一部分。
首先,跟大部分”小语言”[2]所不同,Sawzall是一个静态类型语言。主要是为了可靠性的考虑。Sawzall程序在一次运行中,会是用数小时,乃至好几个月的CPU时间,一个迟绑定(late-arising)动态类型错误导致的代价就有可能太大。另外,还有一个潜在的原因,聚合器使用完整的Sawzall类型,静态类型会让聚合器的实现比较容易。类似的争议也在分析输入协议buffer上;静态类型可以精确检测输入的类型。同样的,也会因为避免了运行时刻动态类型检测而提高整个的性能。最后,便以时候类型检查和强制类型转换要求程序员精确的指出类型转换。唯一的例外是在变量初始化的时候,但是就算在这个时候,类型以就是清晰而且程序也是类型安全的。
从另外的角度上看,强类型保证了变量的类型一定可知,在初始化的时候容易处理。例如:
t: time=”Apr 1 12:00:00 PST 2005”;
这样的初始化就很容易理解,而且还是类型安全的。并且有一些基本类型的属性也是主机相关的。比如处理log记录的time stamps的时候,这个time基本类型就是依赖于log记录的time stamps的;对于它来说,如果要支持夏令时的时间处理就太过奢侈了。更重要的是(近来比较少见了),这个语言定义了用UNICODE表示string,而不是处理一组扩展字符集编码的变量。
由于处理大量数据集的需要,我们有赋予这个语言两个特性:处理未定义的值,处理逻辑量词。下两节详细描述这个特性。
11.1 未定义的值
Sawzall没有提供任何形式的异常处理机制。相反,他有自己的未定义值得处理概念,用来展示错误的或者不确定的结果,包括除0错,类型转换错误,I/O错误,等等。如果程序在初始化以外的地方,尝试去读一个未定义的值,它会崩溃掉,并且报告一个失败。
def()断言,用于检测这个值是否一定定义了;如果这个值是一个确定值,他返回true,否则返回false。他的通常用法如下:
v: Value = maybe_undefined();
if (def(v)) {
compute(v);
}
下面是一个必须处理未定义值得例子。我们在query-mapping程序中扩展一个时间轴。原始程序使用函数locationinfo()来通过外部数据库判定IP地址的位置。当IP地址不能在数据库中找到的时候,这个程序是不稳定的。在这种情况下,locationinfo()函数返回的是一个不确定的值,我们可以通过使用def()断言来防止这样的情况。
下边就是一个简单的扩展:
proto "querylog.proto"
static RESOLUTION: int = 5; # minutes; must be divisor of 60
log_record: QueryLogProto = input;
queries_per_degree: table sum[t: time][lat: int][lon: int] of int;
loc: Location = locationinfo(log_record.ip);
if (def(loc)) {
t: time = log_record.time_usec;
m: int = minuteof(t); # within the hour
m = m – m % RESOLUTION;
t = trunctohour(t) + time(m * int(MINUTE));
emit queries_per_degree[t][int(loc.lat)][int(loc.lon)] <- 1;
}
(注意,我们只是简单的扔掉我们不知道的位置,在这里是一个简单的处理)。在if后边的语句中,我们用了一些基本的内嵌函数(内嵌常数:MINUTE),来截断记录中的time stamp的微秒部分,整理成5分钟时间段。
这样,给定的查询log记录会扩展一个时间轴,这个程序会把数据构造多一个时间轴,这样我们可以构造一个动画来展示如何随着时间变化而查询位置有变化。
有经验的程序员会使用def()来保护常规错误,但是,有时候错误混杂起来会很怪异,导致程序员很难事先考虑。如果程序处理的事TB级别的数据,一般都会有一些数据不够规则;往往数据集的数据规则度超乎作分析程序的人的控制,或者包含偶尔当前分析不支持的数据。在Sawzall程序处理的情况下,通常对于这些异常数据,简单丢弃掉是最安全的。
Sawzall因此提供了一种模式,通过run-time flag的设置,可以改变未定义值得处理行为。通常,如果遇到一个未定义的值(就是说没有用def()来检测一下),将会终止程序并且会给出一个错误报告。当run-time flag设置了,那么,Sawzall简单的取消这个未定义的值相关的语句的执行。对于一个损坏的记录来说,就意味着对临时从程序处理中去除一样的效果。当这种情况发生的时候,run-time会把这个作为日志,在一个特别的预先定义的Collection table中记录。当运行结束的时候,用户可以检查错误率是否可以接受。对于这个flag的用法来说,还可以关掉这个flag用于调试-否则就看不到bug!-但是如果在一个大数据集上运行的时候,还是打开为妙,免得程序被异常数据所终止。
设置run-time flag的方法是不太常见的错误处理方法,但是在实际中非常有用。这个点子是和Rinard etal[14]在gcc编译器生成容错代码有点类似。在这样的编译器,如果程序访问超过数组下表的索引,那么生成的代码可以使得程序能够继续执行。这个特定的处理方式参考了web服务器的容错设计的模式,包括web服务器面临恶意攻击的健壮性的设计。Sawzall的未定义值得处理增加了类似的健壮性设计级别。
11.2 量词
虽然Sawzall是基于单个记录的操作,这些记录可能会包含数组或者结构,并且这些数组或者结构需要作为单个记录进行分析和处理。哪个数组元素有这个值?所有值都符合条件?为了使得这些容易表达,Sawzall提供了逻辑量词操作,一组特定的符号,类似”for each”,”for any”,”for all”量词。
在when语句的这种特定的构造中,可以定义一个量词,一个变量,和一个使用这个变量的布尔类型的条件。如果条件满足,那么就执行相关的语句。量词变量就像普通的integer变量,但是它的基础类型(通常是int)会有一个量词前缀。比如,给定数组a,语句:
when(i: some int; B(A[i]))
F(i);
就会当且仅当对于一些i的取值,布尔表达式B(a[i])为TRUE的情况下,执行F(i)。当F(i)执行了,他会被绑订到满足条件的值。对于一个when语句的执行来说,要求有求值范围的一个限制条件;在这个例子中,隐式的指出了关于数组的下标就是求值的范围。在系统内部实现上,如果需要,那么系统使用def()操作来检查边界。
一共有三个量词类型:some,当有任意值满足条件的时候执行(如果超过一个满足条件,那么就任选一个);each,执行所有满足条件的值;all,当所有的值都满足条件的时候执行(并且不绑定值到语句体)。
when语句可能包含多个量词,通常可能会导致逻辑编程的混淆[6]。Sawzall对量词的定义已经足够严格了,在实际运用中也不会有大问题。同样的,当多重变量出现的时候,Sawzall规定他们将按照他们定义的顺序进行绑定,这样可以让程序员有一定的控制能力,并且避免极端的情况。
下边是一些例子。第一个测试两个数组是否共享一个公共的元素:
when(i, j: some int; a1[i] == a2[j]) {
…
}
第二个例子扩展了这个用法。使用数组限制,在数组的下标中使用用:符号来限制,他测试两个数组中,是否共享同样的3个或者更多元素的子数组:
when(i0, i1, j0, j1: some int; a[i0:i1] == b[j0:j1] &&i1 >= i0+3) {
…
}
在类似这样的测试中,不用写处理边界条件的代码。即使数组小于三个元素,这个语句依旧可以正确执行,when语句的求值可以确保安全的执行。
原则上,when语句的求值处理是可以并行计算的,但是我们还没有研究这方面的内容。
12 性能
虽然Sawzall是解释执行的,但是这不是影响性能的主要因素。大部分Sawzall程序都只会带来很少一点的处理开销和I/O开销,而大部分的CPU时间都用于各种run-time的操作,比如分析protocol buffer等等。
不过,为了比较单CPU的Sawzall和其他解释语言的解释执行性能,我们写了一些小的测试程序。第一个是计算Mandelbrot的值,来测试基本的算术和循环性能。第二个测试函数用递归函数来计算头35个菲波纳契级数。我们在一个2.8G x86台式机上执行的测试。表1是测试结果,显示了Sawzall远比Python,Ruby或者Perl快,起码这些benchmarks上要快。另一方面,在这些测试上,Sawzall比解释执行的Java慢1.6倍,比编译执行的Java慢21倍,比C++编译的慢51倍。

表1:Microbenchmarks.第一个Mandelbrotset计算:500×500图像,每点最多500次叠代。第二个用递归函数计算头35个菲波纳契级数。
这个系统的性能关键并非是单个机器上的性能,而是这个性能在处理大数据量时,增加机器的时候性能增加曲线。我们使用了一个450GB的压缩后的查询log数据,并且在其上运行一个Sawzall程序来统计某一个词出现的频率。这个程序的核心代码是类似这样的:
result: table sum[key: string][month: int][day: int] of int;
static keywords: array of string =
{ "hitchhiker", "benedict", "vytorin",
"itanium", "aardvark" };
querywords: array of string = words_from_query();
month: int = month_of_query();
day: int = day_of_query();
when (i: each int; j: some int; querywords[i] == keywords[j])
emit result[keywords[j]][month][day] <- 1;
我们在50到600台2.4G Xeon服务器上执行了这个测试程序。测试的时间结果在图5体现了。在600台机器的时候,汇聚器大概可以每秒处理1.06G压缩后的数据,或者3.2G未压缩的数据。如果这个性能扩展能力是比较完美的,那么随着机器的增加处理性能能近似线形增长,这就是说,每增加一台机器,都能增加一台机器的完整处理性能。在我们的测试中,增加1台机器的效率增加大约是相当于增加0.98台机器。
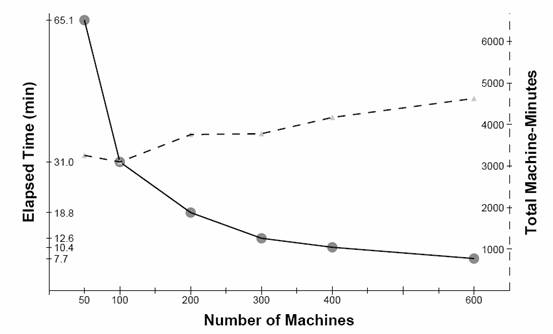
图5:当增加机器的时候性能变化曲线。实线是花费的时间,虚线是机器的工作时间产出。从50到600台机器的一个区间内,单机的性能产出仅仅下降了30%。
为什么需要一个新语言?
为什么我们需要在MapReduce之上增加一个新的语言?MapReduce已经很高效了;还少什么吗?为什么需要一个全新的语言?为什么不在MapReduce之上使用现成的语言比如Python?
这里给出了构造一个特殊目的语言的常见原因。为某一个问题领域构造特定的符号描述有助于程序清晰化,并且更紧凑,更有效率。在语言内嵌聚合器(包括在运行时刻内嵌聚合器)意味着程序员可以不用自己实现一个,这点不像使用MapReduce需要自己实现。同样的,它也更符合大规模并发处理超大数据集时候的处理思路,并且根据这个处理思路写出一流的程序。同样的,对协议栈buffer的支持,并且提供了平台相关的类型支持,在较低层面上简化了程序开发。总的来说,Sawzall程序要比基于MapReduce的C++小上10~20倍,并且更容易书写。
定制语言还有其他优势包括了增加平台相关的特性,定制的调试和模型界面,等等。
不过,制作这个Sawzall的原始动机完全不同:并行,拆分聚合器,并且提供不需要对记录内部作分析就可以最大程度的对记录进行并行处理。它也提供了一个分布式处理的模式,激励用户从另外的思维角度考察并行问题。在现成的语言中比如Awk[12],Python[1],用户可能要用这个语言书写聚合器,这就可能比较难以做到并行化处理。甚至就算在这些语言中提供了清晰的聚合器接口和函数库,经验老到的用户还有可能要实现他们自己的内容,用以大幅度提高处理性能。
Sawzall采用的模式已经被证明非常有效。虽然对于少数问题来说,这样的模式还不能有效处理,但是大部分海量数据的处理来说都已经很适用了,并且可以简单用程序实现,这就使得Sawzall成为google中很受欢迎的语言。
这个语言对用户编程方面的限制也带来额外的一些好处。因为用户程序的数据流是强类型化的,它很容易用来提供记录中的单独字段的访问控制。就是说,系统可以自动并且安全的在用户程序外增加一层,这个层本身也是由Sawzall实现的,它用来隐藏敏感信息。例如,产品工程师可以在不被授权业务信息的情况下,访问性能和监控信息数据。这个会在单独的论文中阐述。
14 工具
虽然Sawzall仅仅发布了18个月,他已经成为了google应用最广泛的语言之一。在我们的源码控制系统内已经有上千个Sawzall程序(虽然,天生这些程序就是短小精干的)。
Sawzall工具的一个衡量指标就是它所处理的数据量。我们监控了2005年3月的使用情况。在3月份,在一个有1500个XeonCPU的工作队列集群上,启动了32580个Sawzall job,平均每个使用220台机器。在这些作业中,产生了18636个失败(应用失败,网络失败,系统crash等等),导致重新运行作业的一部分。所有作业读取了大约3.2×10^15字节的数据(2.8PB),写了9.9×10^12字节(9.3TB)(显示了”数据合并”有些作用)。平均作业处理大概100GB数据,这些作业总共大约等于一个机器整整工作一个世纪的工作。
15 相关工作
传统的数据处理方式通常是通过关系数据库保存数据,并且通过SQL查询来进行查询。我们的系统有比较大的不同。首先,数据集通常过于巨大,不能放在关系型数据库里;而且文件直接在各个存储节点进行处理,而不用导入一个数据库服务器。同样的,我们的系统也没有预先设定的table或者索引;我们用构造一个特别的table和索引来进行这样的相关计算。
Sawzall和SQL完全不同,把高效的处理单个记录分析结果的聚合器接口结合到传统的过程语言。SQL有很高效的数据库join操作,但是Sawzall却不行。但是另一方面来说,Sawzall可以在上千台机器上运行处理超大数据集。
Brook[3]是另一个数据处理语言,特别适合图像处理。虽然在不同的应用领域,就像Sawzall一样,它也是基于一次处理一个元素的计算模式,来进行并行处理,并且通过一个聚合器内核来合并(reduce)输出。
另外一种处理大数据的方式是通过数据流的模式。这样的系统是处理数据流的输入,他们的操作是基于输入记录的顺序。比如,Aurora[4]就是一个流模式处理系统,支持单向数据流输入的数据集处理。就像Sawzall预定义的聚合器,Aurora提供了一个很小的,固定操作功能集合,两者都是通过用户定义的函数来体现的。这些操作功能可以构造很多有意思的查询。同Sawzall不同的是,部分Aurora操作功能是基于输入值得连续的序列,或者输入值得一个数据窗。Aurora只保存被处理的有限的一部分数据,并且不是为了查询超大的归档库设计的。虽然对Aurora来说,增加新的查询很容易,但是他们只能在最近的数据上进行操作。Aurora和Sawzall不同,Aurora是通过精心设计的运行时刻系统和查询优化器来保证性能,而Sawzall是通过强力的并行处理能力来保证性能。
另一种流模式处理系统是Hancock[7],对流模式的处理方式进行了扩展,提供了对每个查询的中间状态作保存。这个和Sawzall就完全不同,Sawzall完全不考虑每个输入记录的处理后的状态。Hancock和Aurora一样,专注于依靠提高单进程处理效率,而不是依靠大规模并行处理来提高性能。
16 展望
成百台机器并行处理的生产力是非常大的。因为Sawzall是一个大小适度的语言,用它写的程序通常比较小,并且是绑定I/O的。因此,虽然他是一个解释语言,实现上效率也足够了。但是,有些超大的,或者超复杂的分析可能需要编译成为机器码。那么编译器需要每台机器上执行一次,然后就可以用这些高速的二进制代码处理每条输入记录了。
有时候,程序在处理记录的时候需要查询外部数据库。虽然我们已经提供了对一些小型数据库的支持,比如什么IP地址信息之类的,我们的系统还是可以用一个接口来操作一个外部数据库。因为Sawzall对每条记录来说是单独处理的,所以当进行外部数据库操作的时候,系统会暂时停顿,当操作完成,继续处理记录。在这个处理过程中,当然有并行处理的可能。
有时候,我们对数据的分析需要多次处理,无论多次Sawzall处理或者从其他系统的处理而导致的多次Sawzall处理,比如从一个传统数据库来的,或者一个其他语言写的程序来的;由于Sawzall并不直接支持”chaining”(链式处理),所以,这些多重处理的程序很难在Sawzall中展示。所以,对这个进行语言方面的扩展,可以使得将来能够简单的表达对数据进行多次处理,就如同聚合器的扩展允许直接输出到外部系统一样。
某些分析需要联合从不同的输入源的数据进行分析,通常这些数据是在一次Sawzall处理或者两次Sawzall处理之后进行联合分析。Sawzall是支持这样的联合的,但是通常要求额外的链接步骤。如果有更直接的join支持会简化这样的设计。
更激进的系统模式可以完全消除这种批处理的模式。在激进的模式下,一个任务比如性能检测任务,这个Sawzall程序会持续的处理输入数据,并且聚合器跟进这个数据流。聚合器本身在一些在线服务器上运行,并且可以在任何时候来查询任何table或者table 条目的值。这种模式和流式数据库[4][7]比较类似,事实上这个也是基于数据流模式考虑的。不过,在研究这种模式以前,由Dean和Ghemawat构造的MapReduce库由于已经非常有效了,所以这样的模式还没有实现过。也许有一天我们会回到这样的模式下。
17 结束语
随着问题的增大,就需要有新的解决方案。为了更有效的解决海量数据集的大规模并发分析计算,就需要进一步限制编程模式来确保高并发能力。并且还要求不影响这样的并发模式下的展示/应用/扩展能力。
我们的觉得方法是引入了一个全新的语言叫做Sawzall。这种语言通过强制程序员每次考虑一条记录的方式来实现这样的编程模式,并且提供了一组强力的接口,这些接口属于常用的数据处理和数据合并聚合器。为了能方便写出能并发运行在上千台计算机上执行的简洁有效的程序,学一下这个新的语言还是很超值的。并且尤其重要的是,用户不用学习并发编程,本语言和底层架构解决了全部的并发细节。
虽然看起来在一个高效环境下使用解释语言有点夸张,但是我们发现CPU时间并不是瓶颈,语言明确指出,绝大部分程序都是小型的程序,并且大量的时间都耗费在I/O上以及run-time的本地代码。此外,解释语言所带来的扩展性是比较强大的,在语言级别和在多机分布式计算上的表达都是容易证明扩展能力。
也许对我们系统的终极测试就是扩展能力。我们发现随着机器的增加,性能增长是近似线性增长的。对于海量数据来说,能通过增加机器设备就能取得极高的处理性能。
18 致谢
Geeta Chaudhry写了第一个强大的Sawzall程序,并且给出了超强建议。Amit Pate,Paul Haahr,Greg Rae作为最早的用户给与了很多帮助。Paul Haahr创建了PageRank 例子。Dick Sites, Ren’ee French对于图示有贡献。此外Dan Bentley,Dave Hanson,John Lamping,Dick Sites,Tom Szymanski, Deborah A. Wallach 对本论文也有贡献。
19 参考资料
[1] David M. Beazley, Python Essential Reference, New Riders, Indianapolis, 2000.
[2] Jon Bentley, Programming Pearls, CACM August 1986 v 29 n 8 pp. 711-721.
[3] Ian Buck et al., Brook for GPUs: Stream Computing on Graphics Hardware, Proc. SIGGRAPH,Los Angeles, 2004.
[4] Don Carney et al., Monitoring Streams – A New Class of Da
http://www.cs.brown.edu/research/aurora/aurora tr.pdf.
[5] M. Charikar, K. Chen, and M. Farach-Colton, Finding frequent items in da
[6] W. F. Clocksin and C. S. Mellish, Programming in Prolog, Springer, 1994.
[7] Cortes et al., Hancock: A Language for Extracting Signatures from Da
[8] Jeffrey Dean and Sanjay Ghemawat, MapReduce: Simplified Da
[9] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, The Google File System, Proc. 19th Symposium on Operating System Principles, Lake George, New York, 2003, pp. 29-43.
[10] M. Greenwald and S. Khanna, Space-efficient on
[11] David R. Hanson, Fast allocation and deallocation of memory based on object lifetimes. Software–Practice and Experience, 20(1):512, January 1990.
[12] Brian Kernighan, Peter Weinberger, and Alfred Aho, The AWK Programming Language, Addison-Wesley, Massachusetts, 1988.
[13] Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd, The pagerank citation algorithm: bringing order to the web, Proc. of the Seventh conference on the World Wide Web, Brisbane, Australia, April 1998.
[14] Martin Rinard et al., Enhancing Server Reliability Through Failure-Oblivious Computing, Proc. Sixth Symposium on Operating Systems Design and Implementation, San Francisco, 2004, pp. 303-316.
[15] Douglas Thain, Todd Tannenbaum, and Miron Livny, Distributed computing in practice: The Condor experience, Concurrency and Computation: Practice and Experience, 2004.















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









