









2.1 Linux 内存管理的基本框架
1. i386 CPU 中的内存管理的基本思路
通过页面目录和页面表分为两个层次, 实现从线性地址到物理地址的映射。 这种模式在大多数的情况下面可以节省页面表所占用的空间, 因为很多时候, 我们的进程是用不到整个虚存空间的。
但是Linux 内核设计需要考虑在不同CPU上面的实现, 既要兼容 i386 又要兼容 64 bit的 CPU。因此, Linux 内核的映射机制实际上是设计成 3 层的, 他在页面目录和页面表中间增设了一层 “中间目录”。
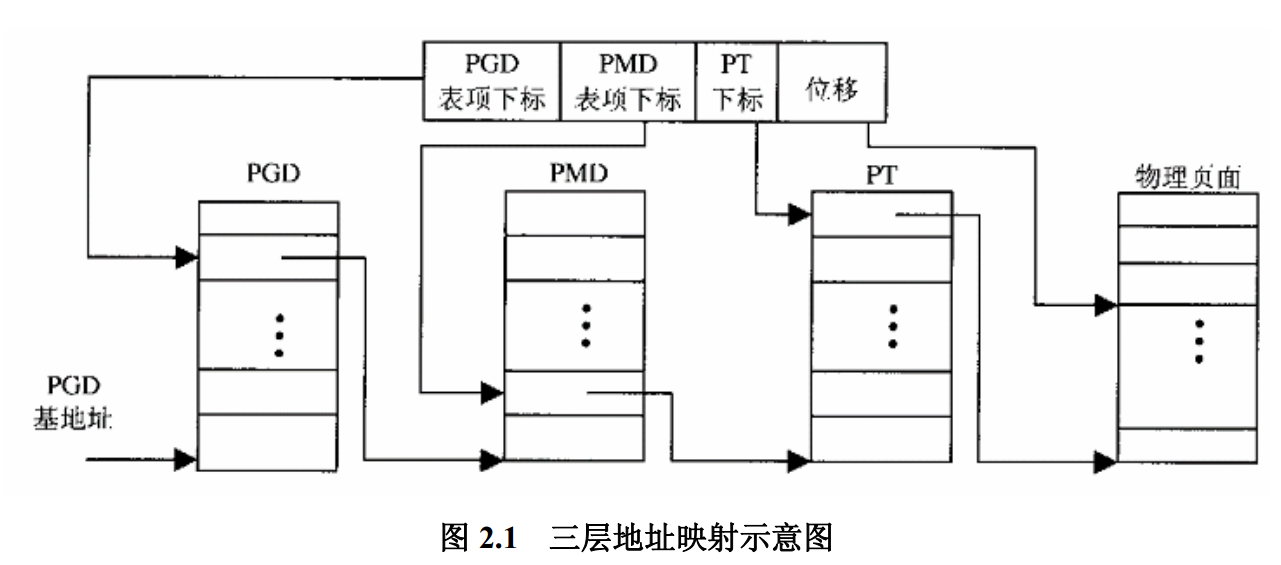
由于在 pentium pro 之后的cpu, intel 引入了PAE, 允许将地址宽度从32bit 提高到 36bit, 于是, linux 就相应的根据 CONFIG_X86_PAE 自主的选择 3层映射 或者 2层映射。
为了支持 i386 的两层映射, linux 实际上做了一个trick
4 /*
5 * traditional i386 two-level paging structure:
6 */
7
8 #define PGDIR_SHIFT 22
9 #define PTRS_PER_PGD 1024
10
11 /*
12 * the i386 is two-level, so we don't really have any
13 * PMD directory physically.
14 */
15 #define PMD_SHIFT 22
16 #define PTRS_PER_PMD 1
17
18 #define PTRS_PER_PTE 1024线性地址的高10bit 作为 PGD, 每个PGD 有 1024 项, 逻辑上指向相应的PMD, 然而, PMD 的宽度被设置为 0, 也就是说, PGD 所指向的PMD 又立即指向了 PT, 逻辑上是 3 层映射, 实际上只有两层, 中间的 PMD 实际上没有起到任何作用!!!
通过这个技巧, ie, 将PMD 宽度设置为 0, 实现对 i386 的支持。
2. 进程的虚拟空间
32bit 地址对应了 4G 字节的虚拟地址空间, Linux 内核将这4G 字节的空间分成了两个部分: 最高的1G 空间(0xC0000000~0xFFFFFFFF), 用于内核本身, 剩余的3G 用作 用户空间。
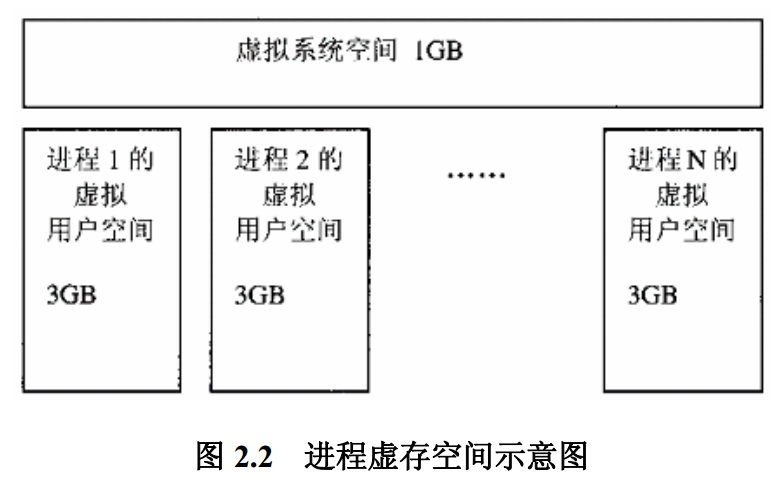
对内核而言, 他的地址的映射是非常简单的线性映射, 0xC0000000 作为他的偏移量。
linux 中 page.h
定义了两个宏, __pa(x) 由虚拟内存 获取 物理内存, __va(x)正好相反
为什么会有这两个宏呢?
在切换进程的时候, cpu 中 放置的是虚拟地址, 而这时候需要用到 CR3 寄存器来指向新进程的页面目录PGD, 而CR3 中存放的是物理地址, 所以需要 这两个宏 协助进行转换。
2.2 地址映射的全部过程
1. i386 的特殊性
Linux 内核采用的是页式存储管理。
相比于段式存储管理, 页式存储管理有诸多好处。 首先, 页面时固定的, 便于管理。 同时, 当需要将一部分物理空间的内容换出到磁盘的时候, 段式存储管理需要将整个段(通常很大, 还不规则)都换出去, 而页式只需要按页执行, 效率要高出很多。
由于段式和页式对硬件的要求不同, 一个cpu 只要支持其中一个就可以了。而我们的i386的页式内存管理是在段式存在了很久的基础上才发展起来的, 这就决定了 i386 中对程序中的地址 一定是先进行段式映射, 然后才是页式映射
于是, 有人也将这种管理方式成为段页式。
2. linux 中的地址映射过程
总的来说, linux中的段式映射过程实际上基本不起什么作用。
在linux中, 我们可以使用gcc 和 ld (编译和链接)得到最终的目标代码, 使用 objdump 可以查看相应的汇编代码。
和书本上的反汇编代码不太一样, 毕竟现在内核已经是 3 开头的了。(可以使用 uname -a 查看内核版本信息)
2.1 段式映射阶段
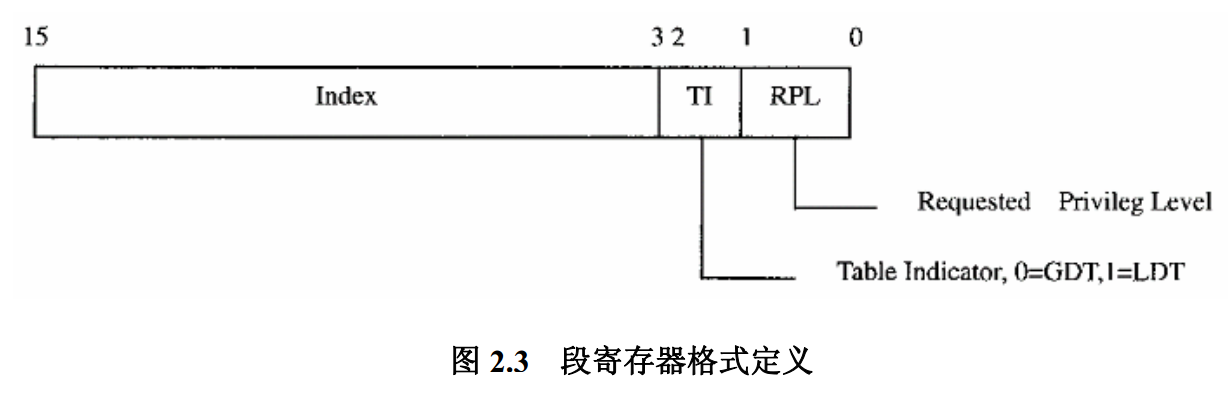
intel 的设计意图是希望内核来使用 GDT 表, 而各个进程使用 LDT 表。 然而, linux 不管这些。
==================== include/asm-i386/processor.h 408 417 ====================
408 #define start_thread(regs, new_eip, new_esp) do { \
409 __asm__("movl %0,%%fs ; movl %0,%%gs": :"r" (0)); \
410 set_fs(USER_DS); \
411 regs->xds = __USER_DS; \
412 regs->xes = __USER_DS; \
413 regs->xss = __USER_DS; \
414 regs->xcs = __USER_CS; \
415 regs->eip = new_eip; \
416 regs->esp = new_esp; \
417 } while (0)也就是说, 除了CS 被设置成了 USER_CS 之外, 其他的段寄存器全变成了 USER_DS. 虽然, intel 打算将一个进程的映像分成代码段, 数据段和堆栈段, 但是linux 中 不区分堆栈段 和数据段
==================== include/asm-i386/segment.h 4 8 ====================
4 #define __KERNEL_CS 0x10
5 #define __KERNEL_DS 0x18
6
7 #define __USER_CS 0x23
8 #define __USER_DS 0x2B在 segment.h 文件中, linux 给出了这几个用到的段寄存器的值, 两个用于内核, 两个用于所有进程。但是这个数据不直观, 将他写成二进制的形式,并对照段寄存器的定义就可以知道:
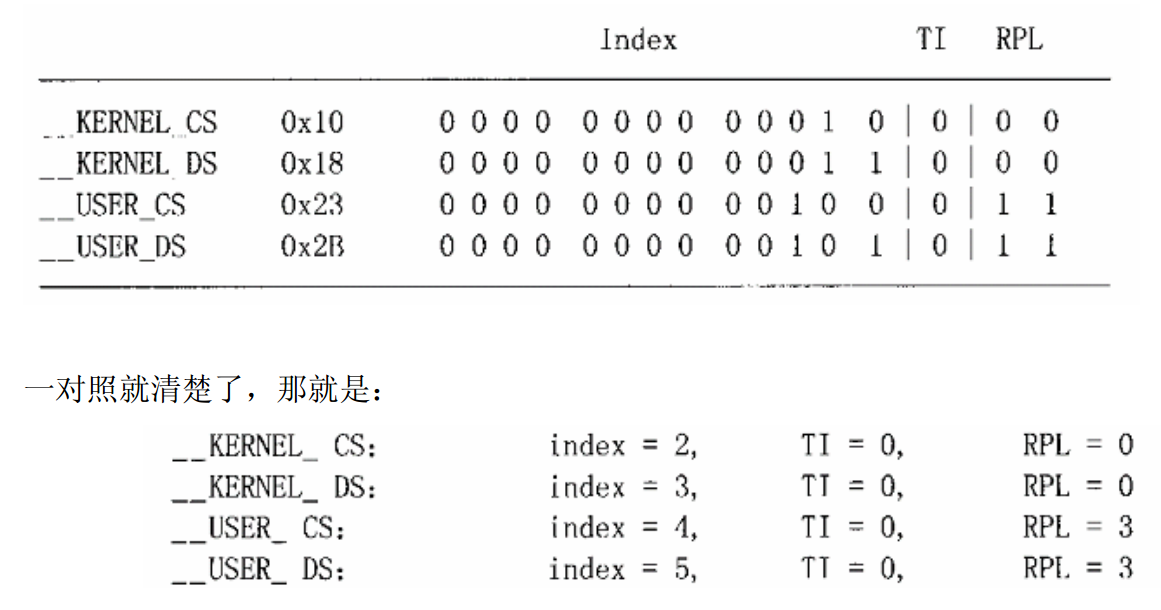
所有的TI 都是0, 全部都是使用 GDT 表, 实际上, 在linux 内核中基本不适用 LDT 表, LDT 只是在模拟windows 或者 dos 的时候才会用到。
并且 RPL 只有 0 和 3 两个级别。
因为 i386 的段式寻址方式是, 段寄存器中屏蔽最后3bit 之后的值 加上 GDT / LDT 表中相应的 基地址的值, 才得到段式寻址之后的地址。
于是, 我们现在来看这个GDT 表的定义:
==================== arch/i386/kernel/head.S 444 458 ====================
444 /*
445 * This contains typically 140 quadwords, depending on NR_CPUS.
446 *
447 * NOTE! Make sure the gdt descriptor in head.S matches this if you
448 * change anything.
449 */
450 ENTRY(gdt_table)
451 .quad 0x0000000000000000 /* NULL descriptor */
452 .quad 0x0000000000000000 /* not used */
453 .quad 0x00cf9a000000ffff /* 0x10 kernel 4GB code at 0x00000000 */
454 .quad 0x00cf92000000ffff /* 0x18 kernel 4GB data at 0x00000000 */
455 .quad 0x00cffa000000ffff /* 0x23 user 4GB code at 0x00000000 */
456 .quad 0x00cff2000000ffff /* 0x2b user 4GB data at 0x00000000 */
457 .quad 0x0000000000000000 /* not used */
458 .quad 0x0000000000000000 /* not used */写成二进制形式描述: (不同部分已经标记出来了)
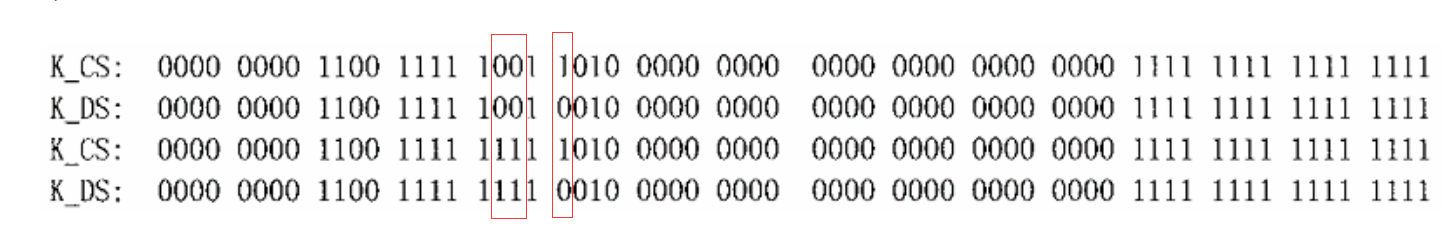
对照段描述项的定义
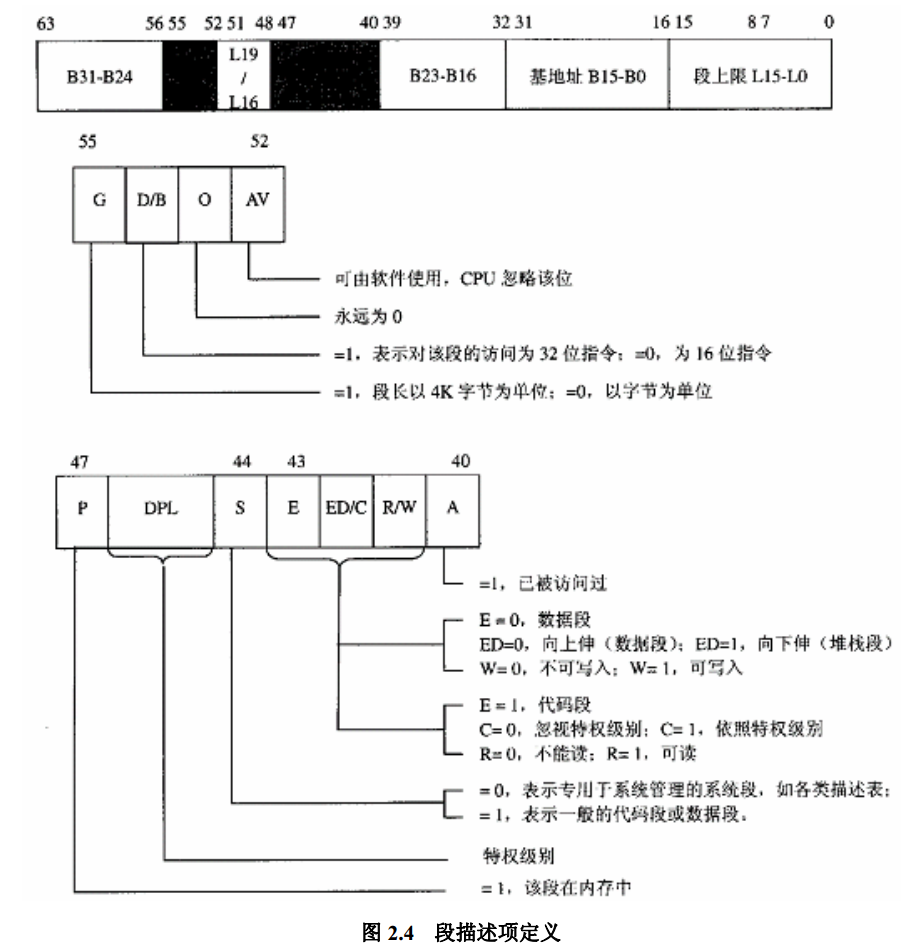
我们发现这么一个结论:
每个段都是从0 地址开始的整个4GB 虚存空间,虚地址到线性地址的映射保持原值不变
区别仅仅在于, DPL 特权级别不同, 内核为 0, 用户为 3, 另一个是 段的类型, 代码段 还是 数据段。这是 CPU 在映射过程中需要加以检查的。 由于这部分检查其实在页式映射中还是需要进行的, 这里就显得有些多余, 但是没办法, 这里必须要糊弄一下i386 CPU 处理他的检查比对。
而真正的重点是在页式映射阶段!!!
处理完段式映射, 我们发现, 由于GDT 中的基地址是0, 于是, 整个的地址其实没有发生任何改变, 绕了一圈, 又回来了。
2.2 页式映射的过程
由于每个进程都拥有他们自己的页面目录PGD, 并且在每个进程的 mm_struct 结构中, 保存了指向这个目录的指针。
每当调度一个进程运行的时候, 内核都需要为即将运行的进程设置好控制寄存器 CR3, MMU 硬件从 CR3 获取相应指向PGD 的指针, 这里由于cpu 使用虚拟地址计算, 而CR3 存放实际物理地址, 就涉及到上文提到的 __pa()地址转换宏了。
需要注意的是,当进程进入到内核的时候, 就进入到了系统空间, 这里有着相同的页面映射。
书本上举了一个线性地址映射的例子,
这里描述一下他的基本流程:
1. 取出线性地址的高10bit , 以这个值作为下标去查找 CR3 所指向的 PGD 页面目录, 得到一个新的值
这个新值的前20bit 指向一个页面表, cpu 在这20bit 后面添加12 bit 的0 得到页面表的基地址。这是因为, 我们的页面表是占一个页面的, 4K字节对齐, 所以低12 bit 一定是0, 这12bit 通常被用作表示其他信息, 比如最后一位 表示页面是否存在在内存中。
2. 然后取出线性地址的中间10bit, 同样的以他为下标找到, 物理内存页面的起始地址, 加上偏移量之后(线性地址的后12bit) 得到物理地址
总的来说, i386cpu 需要访问内存3次, 页面目录 ==> 页面表 ==> 真正目标。 这里就需要高速缓存的协助了。
3 linux 仿真段式存储管理的windows 或者 dos
modify_ldt, 和 vm86
这里不再过多叙述了。















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









