









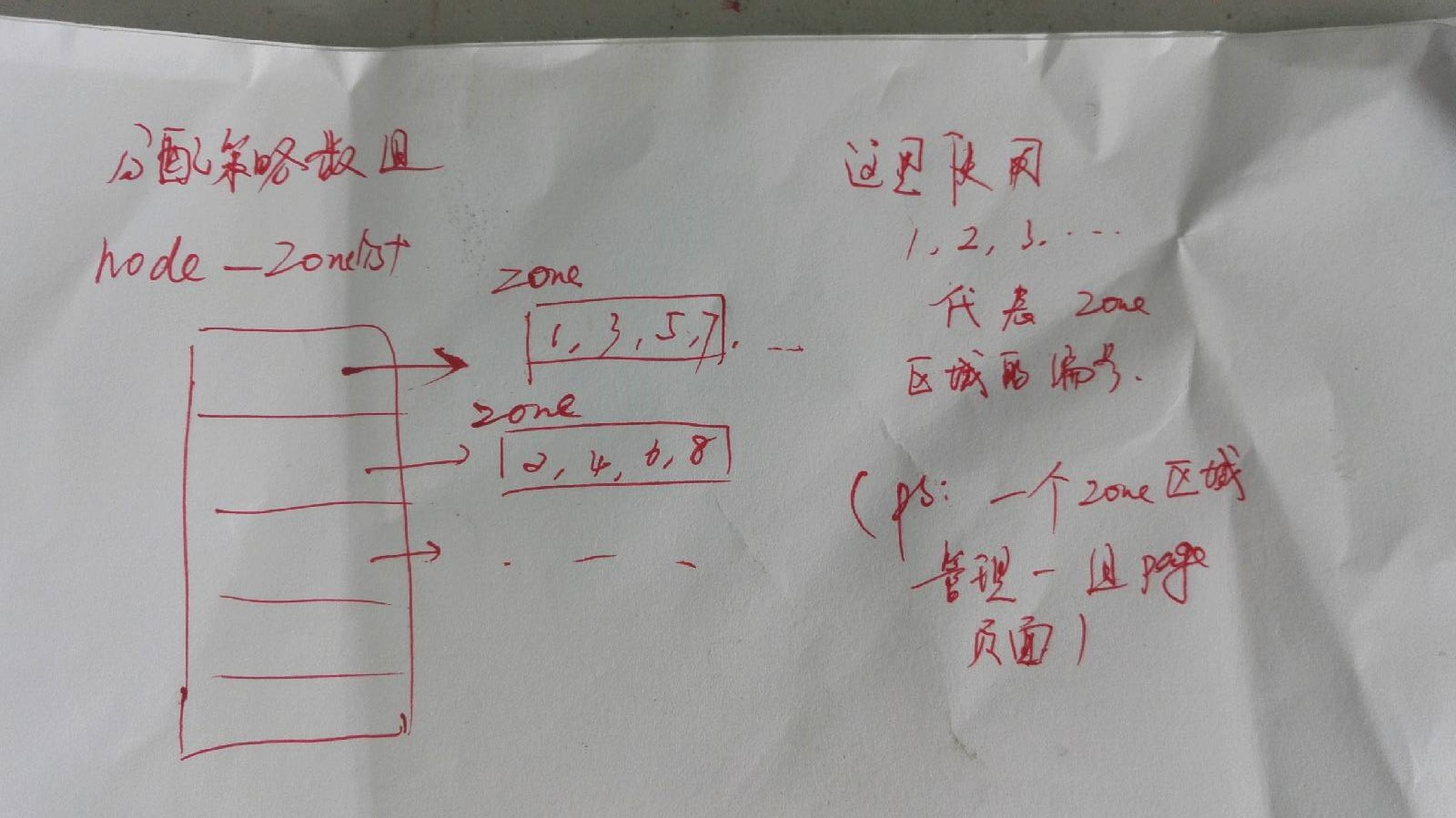
物理页面分配
linux 内核 2.4 中有 2 个版本的物理页面分配函数 alloc_pages()。 一个在 mm/numa.c 中, 另一个在 mm/page_alloc.c 中, 根据条件编译选项 CONFIG_DISCONTIGMEM 决定取舍。
1. NUMA 结构中的alloc_pages
==================== mm/numa.c 43 43 ====================
43 #ifdef CONFIG_DISCONTIGMEM
==================== mm/numa.c 91 128 ====================
91 /*
92 * This can be refined. Currently, tries to do round robin, instead
93 * should do concentratic circle search, starting from current node.
94 */
95 struct page * alloc_pages(int gfp_mask, unsigned long order)
96 {
97 struct page *ret = 0;
98 pg_data_t *start, *temp;
99 #ifndef CONFIG_NUMA
100 unsigned long flags;
101 static pg_data_t *next = 0;
102 #endif
103
104 if (order >= MAX_ORDER)
105 return NULL;
106 #ifdef CONFIG_NUMA
107 temp = NODE_DATA(numa_node_id());
108 #else
109 spin_lock_irqsave(&node_lock, flags);
110 if (!next) next = pgdat_list;
111 temp = next;
112 next = next->node_next;
113 spin_unlock_irqrestore(&node_lock, flags);
114 #endif
115 start = temp;
82
116 while (temp) {
117 if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))
118 return(ret);
119 temp = temp->node_next;
120 }
121 temp = pgdat_list;
122 while (temp != start) {
123 if ((ret = alloc_pages_pgdat(temp, gfp_mask, order)))
124 return(ret);
125 temp = temp->node_next;
126 }
127 return(0);
128 }- 通过设置 CONFIG_DISCONTIGMEM 这个条件编译选项之后, 这段代码才能得到编译。
我们可以把 不连续的物理存储空间 看做是一种广义的 NUMA, 两块内存之间的孤岛看成是非均质的。这样, 在处理不连续的物理空间的时候, 也需要像处理 NUMA 一样划分出若干连续且均匀的 “存储节点”, 因而, 也有一个 pg_data_t 的数据结构的队列。 - 调用参数中的 gfp_mask, 他是一个整数代表着一种分配策略。它对应的实际上是给定节点中数组node_zonelist[] 的下标, 而这个node_zonelist[] 表征的是物理内存页面分配时候的一个策略。 在node_zonelist 中, 维护了一个zone_t 的数组, 这个数组就用来表征 分配物理页面的时候, 先到 zone[i]管理区尝试分配, 如果不行, 转到zone[i + 1]。由于, 有多种分配的策略, 因而, 定义了一个node_zonelist[] 的分配策略数组。
- 第二个参数 order 表征所需要的物理块的大小,可以看到他是一个unsigned long 类型。计算机中是采用二进制形式的, 我们分配页面的时候, 也是按照 2n 的形式来进行分配。很容易可以想到, 这个order 就代表了需要分配 空间 大小 中 2 的幂次的形式。 ie, 分配的页面大小为 2order 。
- 对于 NUMA 结构的系统而言, 我们可以通过NUMA_DATA 和 numa_node_id() 找到cpu 所在节点的pg_data_t 的数据结构队列。
- 对于 非连续的 UMA 结构, 也有一个pgdat_list 的结构。我们可以这么理解他, UMA 相当于NUMA 中所有区域的材质变成一致时候的特殊情形, ie, pgdat_list 的长度为 1.
- 也就是说, 代码的106 ~ 114 实际上获取到了一个 pgdat_t 节点的指针。然后, 115 ~ 126 遍历这个pgdat_list 所在的pgdat_list 链表中的每个pgdat_t 节点, 试图在这些存储节点上分配所需的物理页面。为什么是两个while 呢, 因为我们一开始拿到的pgdat_t 存储节点 可能只是这个链表中间的某一节点而已。
1.1. alloc_pages_pdat
==================== mm/numa.c 85 89 ====================
85 static struct page * alloc_pages_pgdat(pg_data_t *pgdat, int gfp_mask,
86 unsigned long order)
87 {
88 return __alloc_pages(pgdat->node_zonelists + gfp_mask, order);
89 }可以看到,在每个pgdat_t 节点上, 分配页面的时候, 都是调用了 __alloc_pages 函数。
2. UMA 中的 alloc_pages
==================== include/linux/mm.h 343 352 ====================
343 #ifndef CONFIG_DISCONTIGMEM
344 static inline struct page * alloc_pages(int gfp_mask, unsigned long order)
83
345 {
346 /*
347 * Gets optimized away by the compiler.
348 */
349 if (order >= MAX_ORDER)
350 return NULL;
351 return __alloc_pages(contig_page_data.node_zonelists+(gfp_mask), order);
352 }这个函数比较简单, 他只有在 CONFIG_DISCONTIGMEM 没有定义的时候才会编译, ie, 他处理UMA 均质连续时候的物理页面分配。
其实, 个人感觉这两段代码, 逻辑上是统一的,因为之前也说过, UMA 可以看成是 NUMA 的一种特例情形,在UMA 中 pgdat_list 的长度缩小到 1。因而, 就不需要再去遍历 这个 pgdat_list 了, 或者说相当于 遍历过程只执行了1 次。
3. __alloc_pages
这段代码有些长, 分段来看:
3.1 part 1
==================== mm/page_alloc.c 270 315 ====================
[alloc_pages()>__alloc_pages()]
270 /*
271 * This is the 'heart' of the zoned buddy allocator:
272 */
273 struct page * __alloc_pages(zonelist_t *zonelist, unsigned long order)
274 {
275 zone_t **zone;
276 int direct_reclaim = 0;
277 unsigned int gfp_mask = zonelist->gfp_mask;
278 struct page * page;
279
280 /*
281 * Allocations put pressure on the VM subsystem.
282 */
283 memory_pressure++;
284
285 /*
286 * (If anyone calls gfp from interrupts nonatomically then it
287 * will sooner or later tripped up by a schedule().)
288 *
289 * We are falling back to lower-level zones if allocation
290 * in a higher zone fails.
291 */
292
293 /*
294 * Can we take pages directly from the inactive_clean
295 * list?
296 */
297 if (order == 0 && (gfp_mask & __GFP_WAIT) &&
298 !(current->flags & PF_MEMALLOC))
299 direct_reclaim = 1;
300
301 /*
302 * If we are about to get low on free pages and we also have
303 * an inactive page shortage, wake up kswapd.
304 */
305 if (inactive_shortage() > inactive_target / 2 && free_shortage())
306 wakeup_kswapd(0);
307 /*
308 * If we are about to get low on free pages and cleaning
309 * the inactive_dirty pages would fix the situation,
310 * wake up bdflush.
311 */
312 else if (free_shortage() && nr_inactive_dirty_pages > free_shortage()
313 && nr_inactive_dirty_pages >= freepages.high)
314 wakeup_bdflush(0);
315- 我们的第一个参数 zonelist 指向一个代表着一个具体分配策略的zonelist_t 的数据结构, order 和前面一样, 表征需要分配页面的大小。
- gfp_mask 表征的是具体分配策略中用于控制目的的标志位。
- 如果要求分配单页 (order = 0), 并且是等待分配完成(__GFP_WAIT), 同时, 不是内存分配者(PF_MEMALLOC), 就把 局部量 direct_reclaim 设置为 1。表示, 我们可以从相应的页面管理区中的 不活跃干净页面 的缓冲队列中进行回收。 上一章中讲到, 这种页面的内容已经写入到了交换设备中, 只是还是保留着页面的内容而已。由于这些页面不一定是连续的, 所以, 只有需要单页的时候, 才从这里回收分配。
- 当内存页面短缺的时候, 会唤醒kswapd 和 bdflush 两个内核线程, 获取更多的内存页面, 进行分配。
3.2 part 2
==================== mm/page_alloc.c 316 340 ====================
[alloc_pages()>__alloc_pages()]
316 try_again:
317 /*
318 * First, see if we have any zones with lots of free memory.
319 *
320 * We allocate free memory first because it doesn't contain
321 * any data ... DUH!
322 */
323 zone = zonelist->zones;
324 for (;;) {
325 zone_t *z = *(zone++);
326 if (!z)
327 break;
328 if (!z->size)
329 BUG();
330
331 if (z->free_pages >= z->pages_low) {
332 page = rmqueue(z, order);
333 if (page)
334 return page;
335 } else if (z->free_pages < z->pages_min &&
336 waitqueue_active(&kreclaimd_wait)) {
337 wake_up_interruptible(&kreclaimd_wait);
338 }
339 }
340上面一段代码, 会对我们所设定的分配策略数组 zone[] 中的每个管理区 zone 进行遍历,如果发现 管理区中 空闲页面的数量, 高于设定的管理区中最少需要保留的页面的数量 pages_low的时候, 就调用 requeue 试图分配页面。否则要是发现空闲页面, 比设定的最小的页面数量 pages_min 还少,并且, kreclaimd 处于睡眠状态, 就唤醒他, 让他回收一些页面备用。
3.2.1 rmqueue
==================== mm/page_alloc.c 172 211 ====================
[alloc_pages()>__alloc_pages()>rmqueue()]
172 static struct page * rmqueue(zone_t *zone, unsigned long order)
173 {
174 free_area_t * area = zone->free_area + order;
175 unsigned long curr_order = order;
176 struct list_head *head, *curr;
177 unsigned long flags;
178 struct page *page;
179
180 spin_lock_irqsave(&zone->lock, flags);
181 do {
182 head = &area->free_list;
183 curr = memlist_next(head);
184
185 if (curr != head) {
186 unsigned int index;
187
188 page = memlist_entry(curr, struct page, list);
189 if (BAD_RANGE(zone,page))
190 BUG();
191 memlist_del(curr);
192 index = (page - mem_map) - zone->offset;
193 MARK_USED(index, curr_order, area);
194 zone->free_pages -= 1 << order;
195
196 page = expand(zone, page, index, order, curr_order, area);
197 spin_unlock_irqrestore(&zone->lock, flags);
198
199 set_page_count(page, 1);
200 if (BAD_RANGE(zone,page))
201 BUG();
202 DEBUG_ADD_PAGE
203 return page;
204 }
205 curr_order++;
206 area++;
207 } while (curr_order < MAX_ORDER);
208 spin_unlock_irqrestore(&zone->lock, flags);
209
210 return NULL;
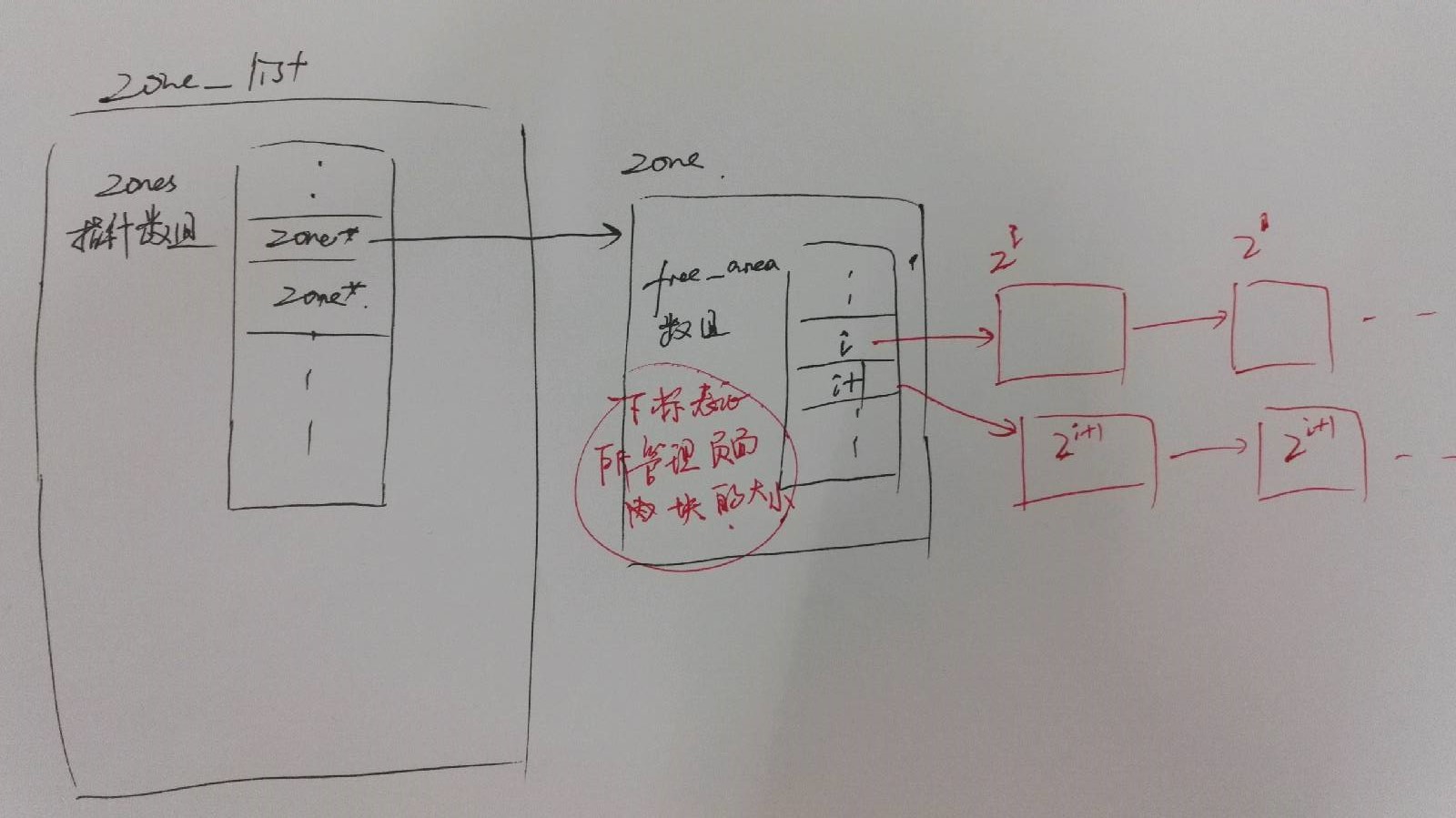
211 }- 这个函数试图从一个页面管理区中分配若干连续的内存页面。
- 由于代表物理页面的page 数据结构, 是通过双向链表的形式连接在管理区的某个空闲队列中的, 分配页面, 就是将他们从队列中摘除的过程。 大概这就是这个函数命名为 rmqueue 的原因吧。
- zone 管理区中的free_area 是个结构数组。
- 通过 zone->free_area + order 可以找到free_area 所管理的 2order 大小的页面块的链表的入口。
- 我们通过 memlist_next 获取第一个页面上 list_head 结构的地址, 然后通过调用 memlist_entry (在chap 1中 C 语言部分 有介绍)获取list_head 所在页面 page 的地址信息。并将该段页面空间 使用 memlist_del 进行移出free_area 所管理的队列。
- index 表示分配的页面在 zone 中的位置
- 如果一个 order 所对应的页面块队列中没有可以分配的页面块, 就移动到下一个更大的order + 1 所对应的页面块队列中尝试分配。如果, 在更大的页面块中成功分配了页面, 就调用expand 将剩余的页面空间分解成小的块连入到相应的队列中。
3.2.2 expand
==================== mm/page_alloc.c 150 169 ====================
[alloc_pages()>__alloc_pages()>rmqueue()>expand()]
150 static inline struct page * expand (zone_t *zone, struct page *page,
151 unsigned long index, int low, int high, free_area_t * area)
152 {
153 unsigned long size = 1 << high;
154
155 while (high > low) {
156 if (BAD_RANGE(zone,page))
157 BUG();
158 area--;
159 high--;
160 size >>= 1;
161 memlist_add_head(&(page)->list, &(area)->free_list);
162 MARK_USED(index, high, area);
163 index += size;
164 page += size;
165 }
166 if (BAD_RANGE(zone,page))
167 BUG();
168 return page;
169 }- 调用参数中的low 表征需要的页面块的大小, high 表示 实际满足要求的物理块的大小。
- 当 high > low 的时候, 将 2high−1 的区块, 连入到high - 1 对应的free_list 中去, 利用 memlist_add_head; 同时设置位图, 直到全部处理完毕。
3.3 part 3
从part2 部分的代码中, 我们知道, 我们现在当前管理区zone 的free_list 中进行分配, (遍历该区域所有不同大小的页面块), 如果还是失败的话, 就进入到下一个zone 进行分配。如果分配成功, page 结构中的引用计数通过 set_page_count 被设置为 1。 但是,如果没有分配成功呢?
这时候, 我们需要加大分配的力度:
1. 降低对 zone 管理区中 保持 page_low 的要求
2. 将缓冲在管理区中的 不活跃干净页面, 也加入考虑分配的范围。
==================== mm/page_alloc.c 341 364 ====================
[alloc_pages()>__alloc_pages()]
341 /*
342 * Try to allocate a page from a zone with a HIGH
343 * amount of free + inactive_clean pages.
344 *
345 * If there is a lot of activity, inactive_target
346 * will be high and we'll have a good chance of
347 * finding a page using the HIGH limit.
348 */
349 page = __alloc_pages_limit(zonelist, order, PAGES_HIGH, direct_reclaim);
350 if (page)
351 return page;
352
353 /*
354 * Then try to allocate a page from a zone with more
355 * than zone->pages_low free + inactive_clean pages.
356 *
357 * When the working set is very large and VM activity
358 * is low, we're most likely to have our allocation
359 * succeed here.
360 */
361 page = __alloc_pages_limit(zonelist, order, PAGES_LOW, direct_reclaim);
362 if (page)
363 return page;
364先后使用 pages_high 和 pages_low 来尝试分配。
3.3.1 __alloc_pages_limit
==================== mm/page_alloc.c 213 267 ====================
[alloc_pages()>__alloc_pages()>__alloc_pages_limit()]
213 #define PAGES_MIN 0
214 #define PAGES_LOW 1
215 #define PAGES_HIGH 2
88
216
217 /*
218 * This function does the dirty work for __alloc_pages
219 * and is separated out to keep the code size smaller.
220 * (suggested by Davem at 1:30 AM, typed by Rik at 6 AM)
221 */
222 static struct page * __alloc_pages_limit(zonelist_t *zonelist,
223 unsigned long order, int limit, int direct_reclaim)
224 {
225 zone_t **zone = zonelist->zones;
226
227 for (;;) {
228 zone_t *z = *(zone++);
229 unsigned long water_mark;
230
231 if (!z)
232 break;
233 if (!z->size)
234 BUG();
235
236 /*
237 * We allocate if the number of free + inactive_clean
238 * pages is above the watermark.
239 */
240 switch (limit) {
241 default:
242 case PAGES_MIN:
243 water_mark = z->pages_min;
244 break;
245 case PAGES_LOW:
246 water_mark = z->pages_low;
247 break;
248 case PAGES_HIGH:
249 water_mark = z->pages_high;
250 }
251
252 if (z->free_pages + z->inactive_clean_pages > water_mark) {
253 struct page *page = NULL;
254 /* If possible, reclaim a page directly. */
255 if (direct_reclaim && z->free_pages < z->pages_min + 8)
256 page = reclaim_page(z);
257 /* If that fails, fall back to rmqueue. */
258 if (!page)
259 page = rmqueue(z, order);
260 if (page)
261 return page;
262 }
263 }
264
265 /* Found nothing. */
266 return NULL;
267 }- 在这里放宽了对分配时候要求zone 管理区保留的页面的限制, 现在只要求 空闲区页面数量 加上 所管理的不活跃干净页面的数量 能够达到分配要求的 water_mark 就可以再次尝试分配了。
- 这里, 我们先前设置的direct_reclaim 局部变量就可以起作用了。 他使得我们在空闲页面与要求的zone 的page_min 差距小于 8 的时候, 可以直接 使用reclaim_page 从inactive_clean_list 中回收页面。
- 如果没有找到相应的page, 就再对这个zone 进行尝试分配, 不行转下一个zone (虽然这个操作, 我们之前已经做过了, 不过万一呢?)
3.4 part 4
如果上述操作, 还是不成功的话, 就表明zone 中的页面已经是严重短缺了。
==================== mm/page_alloc.c 365 399 ====================
[alloc_pages()>__alloc_pages()]
365 /*
366 * OK, none of the zones on our zonelist has lots
367 * of pages free.
368 *
369 * We wake up kswapd, in the hope that kswapd will
370 * resolve this situation before memory gets tight.
371 *
372 * We also yield the CPU, because that:
373 * - gives kswapd a chance to do something
374 * - slows down allocations, in particular the
375 * allocations from the fast allocator that's
376 * causing the problems ...
377 * - ... which minimises the impact the "bad guys"
378 * have on the rest of the system
379 * - if we don't have __GFP_IO set, kswapd may be
380 * able to free some memory we can't free ourselves
381 */
382 wakeup_kswapd(0);
383 if (gfp_mask & __GFP_WAIT) {
384 __set_current_state(TASK_RUNNING);
385 current->policy |= SCHED_YIELD;
386 schedule();
387 }
388
389 /*
390 * After waking up kswapd, we try to allocate a page
391 * from any zone which isn't critical yet.
392 *
393 * Kswapd should, in most situations, bring the situation
394 * back to normal in no time.
395 */
396 page = __alloc_pages_limit(zonelist, order, PAGES_MIN, direct_reclaim);
397 if (page)
398 return page;
399- 我们唤醒内核线程kswapd, 让他设法在换出一些页面出来。
- 如果是一定要等待到分配的页面的话, 就让系统进行调度, schedule, 为kswapd 让路。
- 然后再次尝试分配。
3.5 part 5
==================== mm/page_alloc.c 400 477 ====================
[alloc_pages()>__alloc_pages()]
400 /*
401 * Damn, we didn't succeed.
402 *
403 * This can be due to 2 reasons:
404 * - we're doing a higher-order allocation
405 * --> move pages to the free list until we succeed
406 * - we're /really/ tight on memory
407 * --> wait on the kswapd waitqueue until memory is freed
408 */
409 if (!(current->flags & PF_MEMALLOC)) {
410 /*
411 * Are we dealing with a higher order allocation?
412 *
413 * Move pages from the inactive_clean to the free list
414 * in the hope of creating a large, physically contiguous
415 * piece of free memory.
416 */
417 if (order > 0 && (gfp_mask & __GFP_WAIT)) {
418 zone = zonelist->zones;
419 /* First, clean some dirty pages. */
420 current->flags |= PF_MEMALLOC;
421 page_launder(gfp_mask, 1);
422 current->flags &= ~PF_MEMALLOC;
423 for (;;) {
424 zone_t *z = *(zone++);
425 if (!z)
426 break;
427 if (!z->size)
428 continue;
429 while (z->inactive_clean_pages) {
430 struct page * page;
431 /* Move one page to the free list. */
432 page = reclaim_page(z);
433 if (!page)
434 break;
435 __free_page(page);
436 /* Try if the allocation succeeds. */
437 page = rmqueue(z, order);
438 if (page)
439 return page;
440 }
441 }
442 }
443 /*
444 * When we arrive here, we are really tight on memory.
445 *
446 * We wake up kswapd and sleep until kswapd wakes us
447 * up again. After that we loop back to the start.
448 *
449 * We have to do this because something else might eat
450 * the memory kswapd frees for us and we need to be
451 * reliable. Note that we don't loop back for higher
452 * order allocations since it is possible that kswapd
453 * simply cannot free a large enough contiguous area
454 * of memory *ever*.
455 */
456 if ((gfp_mask & (__GFP_WAIT|__GFP_IO)) == (__GFP_WAIT|__GFP_IO)) {
457 wakeup_kswapd(1);
458 memory_pressure++;
459 if (!order)
460 goto try_again;
461 /*
462 * If __GFP_IO isn't set, we can't wait on kswapd because
463 * kswapd just might need some IO locks /we/ are holding ...
464 *
465 * SUBTLE: The scheduling point above makes sure that
466 * kswapd does get the chance to free memory we can't
467 * free ourselves...
468 */
469 } else if (gfp_mask & __GFP_WAIT) {
470 try_to_free_pages(gfp_mask);
471 memory_pressure++;
472 if (!order)
473 goto try_again;
474 }
475
476 }
477- 这是非内存分配者来进一步尝试分配页面的情形
- 这里采用的方式是, 尝试将不活跃脏页面中的内容写入交换区, 将他变为不活跃干净页面, 参与页面分配。
- 如果回收之后, 还是不行, 两种途径: 要么唤醒 kswapd ,自己休眠等待, 在kswapd完成一轮操作之后, 在让他唤醒自己, 如果要求分配单个页面的话, 就重新执行try_again 部分。 或者调用 try_to_free_pages 获取一部分由脏页面转化过来的干净页面进行分配。
- 为什么这里只有当要求单个页面, 才重新执行try_again 部分呢?个人的理解: 将脏页面转化成干净页面后, 不能保证页面的连续性, 所以只能处理单个页面的情形。我们认为系统中管理的页面块大小是不一样的
3.6 part 6
我们前面的分配过程, 都是留了一点后路的, 每个zone 规定保留的水位 还是要高于 pages_min 的。这次我们决定榨干他。
==================== mm/page_alloc.c 478 521 ====================
[alloc_pages()>__alloc_pages()]
478 /*
479 * Final phase: allocate anything we can!
480 *
481 * Higher order allocations, GFP_ATOMIC allocations and
482 * recursive allocations (PF_MEMALLOC) end up here.
483 *
484 * Only recursive allocations can use the very last pages
485 * in the system, otherwise it would be just too easy to
486 * deadlock the system...
487 */
488 zone = zonelist->zones;
489 for (;;) {
490 zone_t *z = *(zone++);
491 struct page * page = NULL;
492 if (!z)
493 break;
494 if (!z->size)
495 BUG();
496
497 /*
498 * SUBTLE: direct_reclaim is only possible if the task
499 * becomes PF_MEMALLOC while looping above. This will
500 * happen when the OOM killer selects this task for
501 * instant execution...
502 */
503 if (direct_reclaim) {
504 page = reclaim_page(z);
505 if (page)
506 return page;
507 }
508
509 /* XXX: is pages_min/4 a good amount to reserve for this? */
510 if (z->free_pages < z->pages_min / 4 &&
511 !(current->flags & PF_MEMALLOC))
512 continue;
513 page = rmqueue(z, order);
514 if (page)
515 return page;
516 }
517
518 /* No luck.. */
519 printk(KERN_ERR "__alloc_pages: %lu-order allocation failed.\n", order);
520 return NULL;
521 }- 这里做的事情就是直接进入到zone 中进行分配, 不在考虑 zone 的水位保持的问题了。
- 如果这个操作也失败了, 那就没办法了。
4. 主要的分配流程小结
- 在每个存储节点上 pgdat_t 上尝试分配
- 根据分配策略 zonelist 在每个管理区zone 上尝试分配 (__alloc_pages)
- 在zone 管理区 的free_area 区域尝试直接分配
- 在zone管理区 尝试利用 free_area 和 inactive_clean_list 尝试分配, 并降低对水位的要求
- 利用kswapd 交换出一些页面来尝试分配
- 将inactive_dirty_list 数据写入交换区, 再尝试分配
- 利用kswapd 释放些页面出来, 尝试分配单个页面
- 如果上面都不行, 不考虑水位要求, 直接在zone 上尝试分配
- 根据分配策略 zonelist 在每个管理区zone 上尝试分配 (__alloc_pages)

















 8906
8906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









