







获取页面
curl http://www.baidu.com
存下http结果,保存在终端运行的当前目录下
curl -o page.html http://www.baidu.com
-O 可以按照服务器上的文件名,自动存在本地
curl -O www.baidu.com
还可以用正则表达式,下载~zzh和nick 001 ~ 202图片
$ curl -O http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
设置代理及端口123.45.67.89:1080
curl -x 123.45.67.89:1080 www.baidu.com
-D 白http的response里面的cookie保存在一个特别的文件中
curl -D cookie0001.txt http://www.baidu.com
-A 指定自己这次访问所宣称的自己浏览器信息
curl -A "Mozilla/4,0(compatibel; MSIE 6.0; Windows NT 5.0)" www.baidu.com
另外一个服务器端常用的限制方法,就是检查http访问的referer。比如你先访问首页,再访问里面所指定的下载页,这第二次访问的 referer地址就是第一次访问成功后的页面地址。这样,服务器端只要发现对下载页面某次访问的referer地址不是首页的地址,就可以断定那是个盗 连了 ~
幸好curl给我们提供了设定referer的option: -e
$ curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -e "mail.linuxidc.com" -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,就可以骗对方的服务器,你是从mail.linuxidc.com点击某个链接过来的了,呵呵呵
-T 上传 PUT
可以向ftp传一个文件,http服务器也可以
curl -T localfile -u "name:passwd" ftp://bababa
-d POST模式
curl -d "user=name&password=1234" http://www.baidu.com
用curl命令,post提交带空格的数据
curl -d "username=abcdef" -d "password=abc efg" http://login.xxx.com/
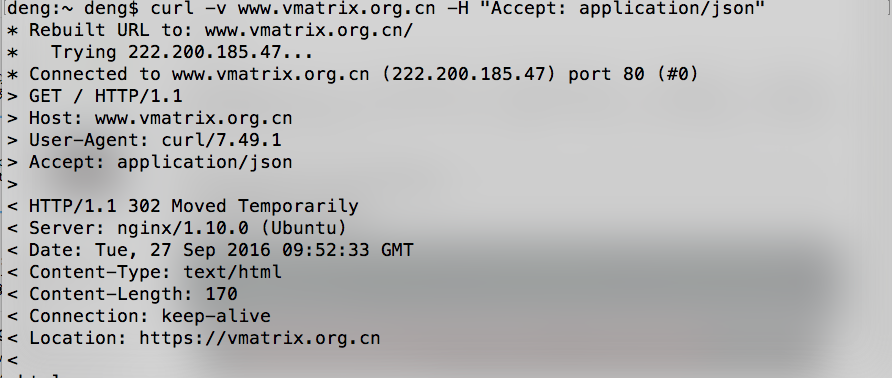
当你使用curl向一个URL发送HTTP请求的时候,它会使用一个默认只包含必要的头部字段(如:User-Agent, Host, and Accept)的HTTP头。
-H 可以定义HTTP头部信息
-b 设置Cookie字段















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









