









简介
lmkd(Low Memory Killer Daemon)是低内存终止守护进程,用来监控运行中android系统内存的状态,通过终止最不必要的进程来应对内存压力较高的问题,使系统以可接受的水平运行。
背景
之前Android 使用内核中的 lowmemorykiller 驱动程序来监控系统内存压力,该驱动程序是一种依赖于硬编码值的严格机制。从内核 4.12 开始,lowmemorykiller 驱动程序已从上游内核中移除,用户空间 lmkd会执行内存监控以及进程终止任务。
用户空间 lmkd 可实现与内核中的驱动程序相同的功能,但它使用现有的内核机制检测和估测内存压力。这些机制包括使用内核生成的 vmpressure 事件或压力失速信息 (PSI) 监视器来获取关于内存压力级别的通知,以及使用内存 cgroup 功能限制分配给每个进程的内存资源(根据每个进程的重要性)。
相关配置属性
| 属性 | 说明 | 默认值 |
|---|---|---|
| ro.config.low_ram | 在低内存和高性能设备之间进行选择 | false |
| ro.lmk.use_minfree_levels | 使用可用内存和文件缓存阈值来做出进程终止决策(即匹配内核中的 lowmemorykiller 驱动程序的功能) | true |
| ro.lmk.low | 在低 vmpressure 级别下被终止的进程的最低 oom_adj 得分 | 1001(已停用) |
| ro.lmk.medium | 在中等 vmpressure 级别下被终止的进程的最低 oom_adj 得分 | 800(非必需的进程) |
| ro.lmk.critical | 在严重 vmpressure 级别下被终止的进程的最低 oom_adj 得分 | 0(任意进程) |
| ro.lmk.critical_upgrade | 能够升级到严重级别 | false |
| ro.lmk.upgrade_pressure | 由于系统交换(swap)次数过多,将在该级别升级的 mem_pressure (swap交换比例)上限 | 100(已停用) |
| ro.lmk.downgrade_pressure | 由于有足够的可用内存,将在该级别忽略 vmpressure 事件的 mem_pressure 下限 | 100(已停用) |
| ro.lmk.kill_heaviest_task | 终止符合条件的最重要任务(最佳决策)与任何符合条件的任务(快速决策) | true |
| ro.lmk.kill_timeout_ms | 从某次终止后到其他终止完成之前的持续时间(以毫秒为单位) | 0(已停用) |
| ro.lmk.debug | 启用lmkd的调试日志 | false |
| 四、相关概念简介-PSI | ||
| Android 10 及更高版本支持新的 lmkd 模式,它使用内核压力失速信息 (PSI) 监视器来检测内存压力。上游内核中的 PSI 补丁程序集(反向移植到 4.9 和 4.14 内核)测量由于内存不足而导致任务延迟的时间。由于这些延迟会直接影响用户体验,因此它们代表了确定内存压力严重性的便捷指标。上游内核还包括 PSI 监视器,该监视器允许特权用户空间进程(例如 lmkd)指定这些延迟的阈值,并在突破阈值时从内核订阅事件。 |
- PSI监视器与vmpressure信号
由于 vmpressure 信号(由内核生成,用于内存压力检测并由 lmkd 使用)通常包含大量误报,因此 lmkd 必须执行过滤以确定内存是否真的有压力。这会导致不必要的 lmkd 唤醒并使用额外的计算资源。使用 PSI 监视器可以实现更精确的内存压力检测,并最大限度地减少过滤开销。 - 如何使用PSI监视器
要使用 PSI 监视器(而不是 vmpressure 事件),需要配置 ro.lmk.use_psi属性。默认值为 true,使得 PSI 监视器成为 lmdk 内存压力检测的默认机制。由于 PSI 监视器需要内核支持,因此内核必须包含 PSI 向后移植补丁程序,并在启用 PSI 支持 (CONFIG_PSI=y) 的情况下进行编译。
相关代码梳理
lmkd是系统一个非常重要的服务,开机是由init进程启动,相关代码如下所示:
system/core/lmkd/lmkd.rc
service lmkd /system/bin/lmkd
class core
user lmkd
group lmkd system readproc
capabilities DAC_OVERRIDE KILL IPC_LOCK SYS_NICE SYS_RESOURCE BLOCK_SUSPEND
critical
socket lmkd seqpacket 0660 system system
writepid /dev/cpuset/system-background/tasks
服务启动后,入口在system/core/lmkd/lmkd.c文件的main函数中,主要做了如下几件事:
1、读取配置参数
2、初始化 epoll 事件监听
3、锁住内存页
4、设置进程调度器
5、循环处理事件
int main(int argc __unused, char **argv __unused) {
...
//读取配置参数
/* By default disable low level vmpressure events */
level_oomadj[VMPRESS_LEVEL_LOW] = property_get_int32("ro.lmk.low", OOM_SCORE_ADJ_MAX + 1);
level_oomadj[VMPRESS_LEVEL_MEDIUM] = property_get_int32("ro.lmk.medium", 800);
level_oomadj[VMPRESS_LEVEL_CRITICAL] = property_get_int32("ro.lmk.critical", 0);
debug_process_killing = property_get_bool("ro.lmk.debug", false);
/* By default disable upgrade/downgrade logic */
enable_pressure_upgrade = property_get_bool("ro.lmk.critical_upgrade", false);
......
/* Loading the vendor library at runtime to access property value */
.....
/* Load IOP library for PApps */
......
//初始化 epoll 事件监听
if (!init()) {
if (!use_inkernel_interface) {
......
/* CAP_IPC_LOCK required */
//锁住内存页
if (mlockall(MCL_CURRENT | MCL_FUTURE | MCL_ONFAULT) && (errno != EINVAL)) {
ALOGW("mlockall failed %s", strerror(errno));
}
/* CAP_NICE required */
// 设置进程调度器
if (sched_setscheduler(0, SCHED_FIFO, ¶m)) {
ALOGW("set SCHED_FIFO failed %s", strerror(errno));
}
}
// 循环处理事件
mainloop();
}
epoll的初始化由init()函数完成:
static int init(void) {
......
struct epoll_event epev;
epollfd = epoll_create(MAX_EPOLL_EVENTS);/* MAX_EPOLL_EVENTS:3 memory pressure levels, 1 ctrl listen socket, 2 ctrl data socket */
......
ctrl_sock.sock = android_get_control_socket("lmkd");
......
ret = listen(ctrl_sock.sock, MAX_DATA_CONN);
epev.events = EPOLLIN;
// 当 socket lmkd 有客户连接时,对应的回调函数
ctrl_sock.handler_info.handler = ctrl_connect_handler;
....
// INKERNEL_MINFREE_PATH: /sys/module/lowmemorykiller/parameters/minfree
has_inkernel_module = !access(INKERNEL_MINFREE_PATH, W_OK);
// enable_userspace_lmk:ro.lmk.enable_userspace_lmk
use_inkernel_interface = has_inkernel_module && !enable_userspace_lmk;
if (use_inkernel_interface) {
ALOGI("Using in-kernel low memory killer interface");
} else {
if (!init_monitors()) {
return -1;
}
........
}
static bool init_monitors() {
/* Try to use psi monitor first if kernel has it */
use_psi_monitors = property_get_bool("ro.lmk.use_psi", true) &&
init_psi_monitors();
/* Fall back to vmpressure */
if (!use_psi_monitors &&
(!init_mp_common(VMPRESS_LEVEL_LOW) ||
!init_mp_common(VMPRESS_LEVEL_MEDIUM) ||
!init_mp_common(VMPRESS_LEVEL_CRITICAL))) {
ALOGE("Kernel does not support memory pressure events or in-kernel low memory killer");
return false;
}
if (use_psi_monitors) {
ALOGI("Using psi monitors for memory pressure detection");
} else {
ALOGI("Using vmpressure for memory pressure detection");
}
return true;
}
// psi监控初始化
/* memory pressure levels */
enum vmpressure_level {
VMPRESS_LEVEL_LOW = 0,
VMPRESS_LEVEL_MEDIUM,
VMPRESS_LEVEL_CRITICAL,
VMPRESS_LEVEL_COUNT
}
static struct psi_threshold psi_thresholds[VMPRESS_LEVEL_COUNT] = {
{ PSI_SOME, 70 }, /* 70ms out of 1sec for partial stall */
{ PSI_SOME, 100 }, /* 100ms out of 1sec for partial stall */
{ PSI_FULL, 70 }, /* 70ms out of 1sec for complete stall */
};
init_psi_monitors() --->init_mp_psi(enum vmpressure_level level)
static bool init_mp_psi(enum vmpressure_level level) {
// init_psi_monitor:往该节点(/proc/pressure/memory)写入stall_type、threshold_ms 、PSI_WINDOW_SIZE_MS
int fd = init_psi_monitor(psi_thresholds[level].stall_type,
psi_thresholds[level].threshold_ms * US_PER_MS,
// 窗口大小时间(1000ms),PSI监视器监控窗口大小,在每个窗口最多生成一次事件,因此在PSI窗口大小的持续时间内轮询内存状态
PSI_WINDOW_SIZE_MS * US_PER_MS);
.......
vmpressure_hinfo[level].handler = use_new_strategy ? mp_event_psi : mp_event_common;
vmpressure_hinfo[level].data = level;
if (register_psi_monitor(epollfd, fd, &vmpressure_hinfo[level]) < 0) {
.......
}
static void mainloop(void) {
......
while (1) {
if (polling) {
/* Wait for pidfds notification or kill timeout to expire*/
nevents = (delay > 0) ? epoll_wait(epollfd, events, maxevents, delay) : 0;
....
}
...
if (evt->data.ptr) {
handler_info = (struct event_handler_info*)evt->data.ptr;
...
call_handler(handler_info, &poll_params, evt->events);
}
.....
}
// lmkd进程的客户端是ActivityManager,通过socket(dev/socket/lmkd)跟 lmkd 进行通信,
// 当有客户连接时,就会回调ctrl_connect_handler函数。
static void ctrl_connect_handler(int data __unused, uint32_t events __unused) {
.........
// ctrl_sock上调用accept接收客户端的连接
data_sock[free_dscock_idx].sock = accept(ctrl_sock.sock, NULL, NULL);
ALOGI("lmkd data connection established");
......
/* use data to store data connection idx */
data_sock[free_dscock_idx].handler_info.data = free_dscock_idx;
// 客户连接对应的处理函数
data_sock[free_dscock_idx].handler_info.handler = ctrl_data_handler;
......
}
客户端建立连接后,通过socket给lmkd发送命令,命令的执行操作在函数ctrl_data_handler中处理的。
static void ctrl_data_handler(int data, uint32_t events) {
if (events & EPOLLIN) {
ctrl_command_handler(data);
}
}
lmkd支持的命令有如下五种:
enum lmk_cmd {
LMK_TARGET = 0, /* Associate minfree with oom_adj_score */ // 将minfree与oom_adj_score关联起来
LMK_PROCPRIO, /* Register a process and set its oom_adj_score */ // 注册进程并设置oom_adj_score
LMK_PROCREMOVE, /* Unregister a process */ // 注销进程
LMK_PROCPURGE, /* Purge all registered processes */ // 清除所有已注册的进程
LMK_GETKILLCNT, /* Get number of kills */ // 获取被杀的次数
};
/* LMK_TARGET packet payload */
struct lmk_target {
int minfree;
int oom_adj_score;
};
/* LMK_PROCPRIO packet payload */
struct lmk_procprio {
pid_t pid;
uid_t uid;
int oomadj;
};
/* LMK_PROCREMOVE packet payload */
struct lmk_procremove {
pid_t pid;
};
/* LMK_GETKILLCNT packet payload */
struct lmk_getkillcnt {
int min_oomadj;
int max_oomadj;
};
static void ctrl_command_handler(int dsock_idx) {
......
switch(cmd) {
case LMK_TARGET:
// 解析socket packet里面传过来的数据,写入lowmem_minfree和lowmem_adj两个数组中,
// 用于控制low memory的行为;
// 设置sys.lmk.minfree_levels,比如属性值:
// [sys.lmk.minfree_levels]: [18432:0,23040:100,27648:200,85000:250,191250:900,241920:950]
cmd_target(targets, packet);
case LMK_PROCPRIO:
// 设置进程的oomadj,把oomadj写入对应的节点(/proc/pid/oom_score_adj)中;
// 将oomadj保存在一个哈希表中。
// 哈希表 pidhash 是以 pid 做 key,proc_slot 则是把 struct proc 插入到以 oomadj 为 key 的哈希表 procadjslot_list 里面
cmd_procprio(packet);
case LMK_PROCREMOVE:
// 解析socket传过来进程的pid,
// 通过pid_remove 把这个 pid 对应的 struct proc 从 pidhash 和 procadjslot_list 里移除
cmd_procremove(packet);
case LMK_PROCPURGE:
cmd_procpurge();
case LMK_GETKILLCNT:
kill_cnt = cmd_getkillcnt(packet);
........
}
当监听到系统内存压力过大时,会通过/proc/pressure/memory上报内存压力,由于配置的是some 60、some 100、full70,当一秒内内存占用70ms\100ms时会上报内存压力,上报压力后,会根据是否使用ro.lmk.use_new_strategy属性来决定是否使用最新的策略,如果未配置情况下,会使用low_ram_device和use_minfree_levels是否配置
bool use_new_strategy =
property_get_bool(“ro.lmk.use_new_strategy”, low_ram_device || !use_minfree_levels);
当系统内存不足时,将会触发 mp 事件,此时 lmkd 就会通过杀死一些进程来释放内存页了。
- mp_event_common流程
static void mp_event_common(...) {
...
if (meminfo_parse(&mi) < 0 || zoneinfo_parse(&zi) < 0) {
ALOGE("Failed to get free memory!");
return;
}
...
if (use_minfree_levels) { //系统属性值,使用系统剩余的内存页和文件缓存阈值作为判断依据。
int i;
//other_free 表示系统可用的内存页的数目,从meminfo和zoneinfo中参数计算
// nr_free_pages为proc/meminfo中MemFree,当前系统的空闲内存大小,是完全没有被使用的内存
// totalreserve_pages为proc/zoneinfo中max_protection+high,其中max_protection在android中为0
other_free = mi.field.nr_free_pages - zi.field.totalreserve_pages;
//nr_file_pages = cached + swap_cached + buffers;有时还会有多余的页(other_file就是多余的),需要减去
if (mi.field.nr_file_pages > (mi.field.shmem + mi.field.unevictable + mi.field.swap_cached)) {
//other_file 基本就等于除 tmpfs 和 unevictable 外的缓存在内存的文件所占用的 page 数
other_file = (mi.field.nr_file_pages - mi.field.shmem - mi.field.unevictable - mi.field.swap_cached);
} else {
other_file = 0;
} //由此计算出 other_free 和 other_file
//遍历oomadj和minfree数组,找出other_free对应的minfree和adj,作为min_score_adj
min_score_adj = OOM_SCORE_ADJ_MAX + 1; //综合other_free,other_file 和 lowmem_minfree计算
for (i = 0; i < lowmem_targets_size; i++) {
//根据 lowmem_minfree 的值来确定 min_score_adj,oomadj小于 min_score_adj 的进程在这次回收过程中不会被杀死
minfree = lowmem_minfree[i];
if (other_free < minfree && other_file < minfree) {
min_score_adj = lowmem_adj[i];
// Adaptive LMK
if (enable_adaptive_lmk && level == VMPRESS_LEVEL_CRITICAL && i > lowmem_targets_size-4) {
min_score_adj = lowmem_adj[i-1];
}
break;
}
}
if (min_score_adj == OOM_SCORE_ADJ_MAX + 1) {
if (debug_process_killing) {
ALOGI("Ignore %s memory pressure event "
"(free memory=%ldkB, cache=%ldkB, limit=%ldkB)",
level_name[level], other_free * page_k, other_file * page_k,
(long)lowmem_minfree[lowmem_targets_size - 1] * page_k);
}
return;
}
goto do_kill;
}
...
do_kill:
..
pages_freed = find_and_kill_process(min_score_adj, -1, NULL, &mi, &curr_tm);
..
}
通过以上逻辑,lmkd就能确定一个变量值:min_score_adj,这个是在实际杀进程时的查杀水线值。LMKD将会查杀adj值 大于 min_score_adj 的进程,回收其内存。直接调用find_and_kill_process()函数查找对应的进程进行查杀,此时传入的参数就包括之前确定的查杀水线值:min_score_adj,在确定了min_score_adj值之后,就会跳转到do_kill部分进行处理
lowmem_minfree就是lowmem_targets的minfree值
lowmem_minfree和lowmem_adj其实就是AMS传过来的lmkd水线值,分开adj和minfree存放,保存在sys.lmk.minfree_levels中,在函数cmd_target()中更新的,也就是从AMS传过来的水线参数,cmd_target()函数对应的信息处理逻辑是来自updateOomLevels()方法[ProcessList.java]
- mp_event_psi主要调用流程如下所示:(不使用use_minfree_level且使用zone_watermark监测)
mp_event_psi(..) {
//判断last_kill_pid_or_fd节点是否存在,存在则为true
bool kill_pending = is_kill_pending();
//进程已死或杀死超时结束,停止等待。 如果支持pidfds,并且死亡通知已经导致等待停止,这将没有影响
stop_wait_for_proc_kill(!kill_pending);
// 解析/proc/vmstat
vmstat_parse(...);
// 解析/proc/meminfo并匹配各个字段的信息,获取可用内存页信息:
meminfo_parse(...)
...
// 计算
if (swap_free_low_percentage) {
// 计算swap_low_threshold=SwapTotal*10/100
//swap_free_low_percentage从ro.lmk.swap_free_low_percentage获取,默认为10
if (!swap_low_threshold) {
swap_low_threshold = mi.field.total_swap * swap_free_low_percentage / 100;
}
//当swap可用空间低于ro.lmk.swap_free_low_percentage属性定义的百分比时,设置swap_is_low = true
swap_is_low = mi.field.free_swap < swap_low_threshold;
}
// 通过判断pgscan_direct/pgscan_kswapd字段较上一次的变化,
//确定内存回收的状态是直接回收(DIRECT_RECLAIM)还是通过swap回收(KSWAPD_RECLAIM),
// 如果都不是(NO_RECLAIM),说明内存压力不大,不进行kill,否则获取thrashing值(通过判断refault页所占比例)
if (vs.field.pgscan_direct > init_pgscan_direct) {
...
}
...
in_reclaim = true;
// 解析/proc/zoneinfo并匹配相应字段信息,
// 获取保留页的大小:zi->field.totalreserve_pages += zi->field.high;(获取可用内存)
//并计算min/low/hight水位线, zmi->nr_free_pages - zmi->cma_free和watermarks比较
zoneinfo_parse(...)
calc_zone_watermarks(...);
//判断当前所处水位
wmark = get_lowest_watermark(&mi, &zone_mem_info);
//根据水位线、thrashing值、压力值、swap_low值、内存回收模式等进行多种场景判断,并添加不同的kill原因
if (cycle_after_kill && wmark <= WMARK_LOW) {
...
} }else if (level >= VMPRESS_LEVEL_CRITICAL && (events != 0 || wmark <= WMARK_HIGH)) {
...
}
...
// 如果任意条件满足,则进行kill操作
pages_freed = find_and_kill_process(min_score_adj, kill_reason, kill_desc, &mi,
&curr_tm);
}
内存节点
/proc/vmstat
取得虚拟内存统计信息
| 字段 | 说明 |
|---|---|
| nr_free_pages 39019 | 当前剩余内存页数 |
| nr_zone_inactive_anon 128030 | zone的非活动匿名页页数 |
| nr_zone_active_anon 478302 | zone的活动匿名页页数 |
| nr_zone_inactive_file 262605 | zone的非活动文件页页数 |
| nr_zone_active_file 191815 | zone的活动文件页页数 |
| nr_zone_unevictable 23900 | zone的不能pageout/swapout的内存页页数 |
| nr_zone_write_pending 171 | zone的正在回写的内存页数 |
| nr_page_table_pages 38979 | 内存页表的页数 |
| nr_free_cma 0 | 剩余的DMA内存 |
| nr_inactive_anon 128030 | 非活动匿名页数 |
| nr_active_anon 478302 | 活动匿名页数 |
| nr_inactive_file 262605 | |
| nr_active_file 191815 | |
| nr_unevictable 23900 | |
| nr_slab_reclaimable 28936 | 可回收的slab内存页数 |
| nr_slab_unreclaimable 97844 | 不可回收的slab内存页数 |
| nr_isolated_anon 0 | 被隔离的匿名页页数 |
| nr_isolated_file 0 | 被隔离的文件页页数 |
| nr_anon_pages 538657 | 匿名页总页数 |
| nr_mapped 252342 | 用于映射的内存页数 |
| nr_file_pages 588227 | 文件页总页数 |
| nr_dirty 171 | 脏页总页数 |
| nr_writeback 0 | 回写的页数 |
| nr_shmem 15307 | 分配给共享内存的页数 |
| nr_file_hugepages 0 | 大页面 |
| nr_unreclaimable_pages 171949 | 不可回收的页面 |
| nr_dirty_threshold 95180 | 脏页页数阈值 |
| workingset_refault 5650768 | 文件缓存中的页面在被回收后,短时间内又被重新访问的次数 |
| pgpgin 9074412 | 从启动到现在读入的内存页数 |
| pgpgout 1363544 | 写入到交换分区的页数 |
| pgfree 19221712 | 从启动到现在释放的页数 |
| pgactivate 3371926 | 从启动到现在激活的页数 |
| pgdeactivate 911218 | 从启动到现在去激活的页数 |
| pgfault 2840084 | 从启动到现在二级页面错误数 |
| pgmajfault 529083 | 从启动到现在一级页面错误数 |
| pgscan_kswapd 2001927 | kswapd后台进程扫描的页面数 |
| pgscan_direct 370102 | 直接回收扫描的页面数 |
| pgscan_direct_throttle 0 | 普通存储区被直接回收的页面数 |
| pgsteal_kswapd 1468243 | kswapd的回收量 |
| pgsteal_direct 56948 | 直接回收量 |
| kswapd_low_wmark_hit_quickly 942 | 达到low水线的次数 |
| kswapd_high_wmark_hit_quickly 329 | 达到quickly水线的次数 |
| slabs_scanned 1797488 | 从启动到现在被扫描的切片数 |
| kswapd_inodesteal 191278 | 从启动到现在由kswapd回收用于其它目的的页面数 |
| pageoutrun 920 | 从启动到现在通过kswapd调用来回收的页面数 |
| pgskip_normal 0 | pgskip 表示在内存回收过程中被跳过的页面数量。这些页面通常是因为某些原因(如页面正在使用或锁定)而无法被回收。 |
| pgskip_movable 0 | 同上 |
workingset_refault
workingset_refault 是 Linux 内核中用于衡量文件缓存(page cache)抖动(thrashing)的一个关键指标。它表示文件缓存中的页面在被回收后,短时间内又被重新访问的次数。workingset_refault 的值越高,说明文件缓存的抖动越严重,系统的内存压力越大。
含义:
- 文件缓存的生命周期
文件缓存中的页面在被访问时会被标记为活跃(active)。
如果系统内存不足,内核会回收一些非活跃(inactive)的文件缓存页面。
如果这些被回收的页面在短时间内又被访问,就会触发 重新故障(refault)。- 抖动的表现
抖动(Thrashing):指系统频繁地在内存和磁盘之间交换数据,导致性能下降。
workingset_refault 的值越高,说明文件缓存中的页面被频繁回收和重新加载,系统的抖动越严重。- 内存压力的指示
workingset_refault 是系统内存压力的一个重要指标。
如果 workingset_refault 的值持续较高,说明系统的内存不足,无法有效缓存文件数据,导致频繁的磁盘 I/O 操作。workingset_refault 的值由内核维护,其计算逻辑如下:
页面回收:
当系统内存不足时,内核会回收文件缓存中的非活跃页面。
这些页面会被标记为“已回收”,并从活跃链表移动到非活跃链表。页面重新访问:
如果这些被回收的页面在短时间内又被访问,就会触发缺页异常(page fault)。
内核会将这些页面重新加载到内存中,并增加 workingset_refault 的计数。统计更新:
内核会定期更新 /proc/vmstat 文件中的 workingset_refault 字段,反映系统近期的抖动情况。
reclaim计算
// 如果 pgscan_direct 或 pgscan_kswapd 的值增加,说明系统正在执行内存回收
if (vs.field.pgscan_direct > init_pgscan_direct) {
init_pgscan_direct = vs.field.pgscan_direct;
init_pgscan_kswapd = vs.field.pgscan_kswapd;
reclaim = DIRECT_RECLAIM;
} else if (vs.field.pgscan_kswapd > init_pgscan_kswapd) {
init_pgscan_kswapd = vs.field.pgscan_kswapd;
reclaim = KSWAPD_RECLAIM;
} else if (vs.field.workingset_refault == prev_workingset_refault) {
/* Device is not thrashing and not reclaiming, bail out early until we see these stats changing*/
goto no_kill;
}
- pgscan_direct
含义:表示系统在 直接内存回收(Direct Reclaim)过程中扫描的页面数量。
触发条件:
当进程请求分配内存时,如果系统空闲内存不足,内核会立即触发直接内存回收。
直接内存回收是同步的,会阻塞当前进程,直到回收足够的内存。由于是同步操作,会阻塞当前进程,影响系统性能- pgscan_kswapd
含义:表示系统在 kswapd 内存回收(Kswapd Reclaim)过程中扫描的页面数量。
触发条件:
当系统空闲内存低于一定阈值时,内核会唤醒 kswapd 线程,异步地回收内存。由于是异步操作,不会阻塞进程,对系统性能影响较小。但是回收时,会占用一个CPU核
kswapd 是内核中的一个后台线程,负责在系统空闲内存不足时回收内存。
pgscan_direct 和 pgscan_kswapd 分别统计了直接内存回收和 kswapd 内存回收扫描的页面数量。
通过这两个字段,可以了解系统内存回收的行为和频率,判断系统是否处于内存压力状态。
pgskip_normal
- 内存区域
Linux 内核将系统的物理内存划分为多个区域(Zone),常见的区域包括:
Normal Zone:普通内存区域,用于分配大多数用户空间进程的内存。
DMA Zone:用于直接内存访问(DMA)的内存区域。
HighMem Zone:高端内存区域,用于分配超过 896MB 的物理内存(在 32 位系统中)。- pgskip 的含义
pgskip 表示在内存回收过程中被跳过的页面数量。这些页面通常是因为某些原因(如页面正在使用或锁定)而无法被回收。
pgskip_normal 是 pgskip 的一个子集,专门统计在 普通内存区域(Normal Zone)中,内存回收过程中被跳过的页面数量。- pgskip_normal 的作用
反映内存回收效率: pgskip_normal 的值越高,说明在普通内存区域中,内存回收的效率越低。这可能是因为该区域中的页面被频繁使用或锁定,导致无法被回收
检测内存压力: 如果 pgskip_normal 的值持续较高,说明普通内存区域的内存压力较大,系统可能需要采取措施(如杀死进程或增加内存)来缓解内存压力- pgskip_normal 的计算
当系统内存不足时,内核会触发内存回收,扫描非活跃页面(Inactive Pages)并尝试回收它们。
如果页面无法被回收(如页面正在使用或锁定),则会被跳过,并增加 pgskip 的计数
/proc/meminfo
取得物理内存信息
/proc/meminfo信息打印的地方在[kernel/msm-5.4/fs/proc/meminfo.c]的meminfo_proc_show函数当中;其中主要是调用show_val_kb()函数将字符串和具体的数值凑成一个字符串,然后把这些字符串打印出来。
- MemTotal
物理内存大小。MemTotal并不等于所有内存条内存容量之和,是因为在系统加电之后,firmware和kernel本身需要占用一些内存,这些占用的内存不会被统计到meminfo文件当中,因此MemTotal表示的内存大小是去掉了这些内存之后剩余可供系统使用的物理内存总大小,在系统运行过程中,MemTotal的值固定不变。- MemFree
当前系统的空闲内存大小,是完全没有被使用的内存- MemAvailable
可用内存大小。MemFree表示的是当前系统的空闲内存大小,而MemAvailable表示的是当前系统的可用内存大小,这两个的含义是不同的。MemFree表示完全没有被使用的内存。但是实际上来说我们能够使用的内存不仅仅是现在还没有被使用的内存,还包括目前已经被使用但是可以被回收的内存,这部分内存加上MemFree才是我们实际可用的内存,cache、buffer、slab等其中都有一部分内存可以被回收,MemAvailable就是MemFree加上这部分可回收的内存之后的结果,当然因为这部分可回收的内存当前还没有被回收,因此只能够通过算法来估算出这部分内存的大小,所以MemAvailable是一个估算值,并不是真实的统计值。- Buffers
直接对块设备进行读写操作使用的缓存。主要包括:直接读写块设备,文件系统元数据(比如superblock,不包括文件系统中文件的元数据)。它与Cached的区别在于,Cached表示的普通文件的缓存。
Buffers占用的内存存在于lru list中,会被统计到Active(file)或者Inactive(file)中。- Cached
Cached是所有的文件缓存,Cached是Mapped的超集。Cached中不仅包含了mapped的页面,也包含了unmapped的页面。当一个文件不再和进程关联之后,在pagecache中的页面不会被马上回收,仍然存在于Cached中,还保留在lru list上,但是Mapped不再统计这部分内存。
Cached还包含tmpfs中文件,以及shared memory,因为shared memory在内核中也是基于tmpfs来实现的。- SwapCached
匿名页在必要的情况下,会被交换到Swap中,shared memory和tmpfs虽然不是匿名页,但是它们没有磁盘文件,所以也是需要交换分区的,为了方便说明,在这里我们将匿名页、shared memory和tmpfs统称为匿名页。因此SwapCached中可能包含有AnonPages和Shmem。SwapCached可以理解为是交换区设备的page cache,只不过page cache对应的是一个个的文件,而swapcached对应的是一个个交换区设备。
并不是每一个匿名也都在swap cache中,只有以下情况中匿名页才在swap cache中:
1)匿名页即将被交换到swap分区上,这只存在于很短的一个时间段中,因为紧接着就会发生pageout将匿名页写入交换分区,并且从swap cache中删除;
2)曾经被写入到swap分区现在又被加载到内存中的页会存在与swap cache,直到页面中的内容发生变化,或者原来用过的交换分区空间被回收。
SwapCached实际的含义是:系统中有多少匿名页曾经被swap-out,现在又被swap-in并且swap-in之后页面中的内容一直没有发生变化。也就是说,如果这些页需要被重新swap-out的话,是不需要进行IO操作的。
需要注意的是,SwapCached和Cache是互斥的,二者没有交叉。当然SwapCached也是存在于lru list中的,它和AnonPages或者Shmem有交集。- Active
lru list组中active list对应的内存大小,这主要包括pagecache和用户进程的内存,不包括kernel stack和hugepages。active list中是最近被访问的内存页。
Active(anon)和Active(file)分别对应LRU_ACTIVE_ANON和LRU_ACTIVE_FILE这两个lru list,分别表示活跃的文件内存页和匿名页,它们的加和等于Active。文件页对应着进程的代码、映射的文件,匿名页对应的是如进程的堆、栈等内存。文件页在内存不足的情况下可以直接写入到磁盘上,直接进行pageout,不需要使用到交换分区swap,而匿名页在内存不足的情况下因为没有硬盘对应的文件,所以只能够写入到交换区swap中,称为swapout。- Inactive
lru list组中inactive list对应的内存大小,也是包括pagecache和用户进程使用的内存,不包括kernel stack和hugepages。Inactive list中是最近没有被访问的内存页,也是内存自动回收机制能够回收的部分。
Inactive(anon)和Inactive(file)分别对应LRU_INACTIVE_ANON和LRU_INACTIVE_FILE这两个例如list,分别表示最近一段时间没有被访问的匿名页和文件页内存,他们的加和等于Inactive。- Unevictable
Unevictable对应的是LRU_UNEVICTABLE链表中内存的大小,unevictable lru list上是不能够pageout和swapout的内存页。- Mlocked
Mlocked统计的是被mlock()系统调用锁定的内存大小,被锁定的内存因为不能够pageout/swapout,它是存在于LRU_UNEVICTABLE链表上。当然LRU_UNEVICTABLE链表上不仅包含Mlocked的内存。- Dirty
Dirty并未完全包括系统中所有的dirty pages,系统上所有的dirty pages应该还包括NFS_Unstable和Writeback,NFS_Unstable是发送给了NFS Server当时没有写入磁盘的缓存页,Writeback是正准备写磁盘的缓存。- AnonPages
AnonPages统计了匿名页。需要注意的是,shared memory和tmpfs不属于匿名页,而是属于Cached。Anonymous pages是和用户进程相关联的,一旦进程退出了,匿名页也就被释放了,不像是page cache,进程退出后仍然可以存在于缓存中。
AnonPages中包含了THP使用的内存。- Mapped
Mapped是Cached的一个子集。Cache中包含了文件的缓存页,这些缓存页有一些是与正在运行的进程相关联的,如共享库、可执行文件等,有一些是当前不在使用的文件。与进程相关联的文件使用的缓存页就被统计到Mapped中。
进程所占的内存分为anonymous pages和file backed pages,所以理论上来讲:
所有进程占用的PSS之和 = Mapped + AnonPages- Shmem
Shmem统计中的内存是shared memory和tmpfs、devtmpfs之和,所有的tmpfs文件系统使用的空间都算入共享内存中。devtmpfs是/dev文件系统类型,也属于一种内存文件系统。
shared memory存在于shmget、shm_open和mmap(…MAP_ANONYMOUS|MAP_SHARED…)系统调用。
由于shared memory也是基于tmpfs实现的,所以这部分内存不算是匿名内存,虽然mmap使用了匿名内存标识符,因此shmem这部分内存被统计到了Cached或者Mapped中。但是shmem这部分内存存在于anon lru list中或者在unevictable lru list中,而不是在file lru list中,这一点需要注意。- Slab
Slab是分配块内存时使用的,详细的slab信息可以在/proc/slabinfo中看到,SReclaimable和SUnreclaim中包含了slab中可回收内存和不可回收内存,它们的加和应该等于Slab的值。- KernelStack
KernelStack是操作系统内核使用的栈空间,每一个用户线程都会被分配一个内核栈,内核栈是属于用户线程的,但是只有通过系统调用进入内核态之后才会使用到。KernelStack的内存不在LRU list中管理,也没有包含进进程的RSS和PSS中进行统计。- PageTables
PageTables用于记录虚拟地址和物理地址的对应关系,随着内存地址分配的增多,PageTables占用的内存也会增加。- NFS_Unstable
NFS_Unstable记录了发送给NFS server但是还没有写入硬盘的缓存。- Bounce
有些老设备只能够访问低端内存,比如16M以下的内存,当应用程序发出一个IO请求,DMA的目的地址却是高端内存时,内核将低端内存中分配一个临时buffer作为跳转,把位于高端内存的缓存数据复制到bounce中,这种额外的数据拷贝会降低性能,同时也会占用额外的内存。- AnonHugePages
AnonHugePages统计的是THP内存,而不是Hugepages内存。AnonHugePages占用的内存是被统计到进程的RSS和PSS中的。- CommitLimit
Commit相关内存涉及到进程申请虚拟内存溢出的问题。
当进程需要使用物理内存的时候,实际上内核给分配的仅仅是一段虚拟内存,只有当进程需要对内存进行操作的时候才会在缺页中断处理中对应分配物理内存,进程使用的物理内存是有限的,虚拟内存也是有限的,当操作系统使用了过多的虚拟内存的时候,也会差生问题,这个时候需要通过overcommit机制来判断。在/proc/sys/vm/下面有几个相关的参数:
overcommit_memory:overcommit情况发生时的处理策略,可以设置为0,1,2
0:OVERCOMMIT_GUESS 根据具体情况进行处理
1:OVERCOMMIT_ALWAYS 无论进程使用了多少虚拟内存都不进行控制,即允许overcommit出现
2:OVERCOMMIT_NEVER 不允许overcommit出现
在overcommit_memory中如果设置为2,那么系统将不会允许overcommit存在,如何判断当前是否发生了overcommit呢?就是判断当前使用内存是否超过了CommitLimit的限制。
当用户进程在申请内存的时候,内核会调用__vm_enough_memory函数来验证是否允许分配这段虚拟内存- Committed_AS
当前已经申请的虚拟内存的大小。- VmallocTotal:可用虚拟内存总大小,内核中常量
- VmallocUsed:内核常量0
- VmallocChunk:内核常量0
可以在/proc/vmallocinfo中看到所有的vmalloc操作。一些驱动或者模块都有可能会使用vmalloc来分配内存。
grep vmalloc /proc/vmallocinfo | awk ‘{total+=$2}; END {print total}’- HardwareCorrupted
当系统检测到内存的硬件故障时,会把有问题的页面删除掉,不再使用,/proc/meminfo中的HardwareCorrupted统计了删除掉的内存页的总大小。相应的代码参见 mm/memory-failure.c: memory_failure()- AnonHugePages
AnonHugePages统计的是透明大页的使用。它和大页不同,大页不会被统计到RSS/PSS
中,而AnonHugePages则存在于RSS/PSS中,并且它完全包含在AnonPages中- HugePages_Total、HugePages_Free、HugePages_Rsvd、HugePages_Surp
Hugepages在/proc/meminfo中是独立统计的,既不会进入rss/pss中,也不计入lru active/inactive, 也不会被计入cache/buffer。如果进程使用hugepages,它的rss/pss也不增加。
THP和hugepages是不同的,THP的统计值是在/proc/meminfo中的AnonHugePages,在/proc/pid/smaps中也有单个进程的统计,这个统计值和进程的rss/pss是有重叠的,如果用户进程使用了THP,那么进程的RSS/PSS也会增加,这和Hugepages是不同的。
HugePages_Total对应内核参数vm.nr_hugepages,也可以在运行的系统之上直接修改,修改的结果会立即影响到空闲内存的大小,因为HugePages在内核上是独立管理的,只要被定义,无论是否被使用,都不再属于free memory。当用户程序申请Hugepages的时候,其实是reserve了一块内存,并没有被真正使用,此时/proc/meminfo中的HugePages_Rsvd会增加,并且HugePages_Free不会减少。只有当用户程序真正写入Hugepages的时候,才会被消耗掉,此时HugePages_Free会减少,HugePages_Rsvd也会减少。
- 内核使用内存
slab + VmallocUsed + PageTables + KernelStack + HardwareCorrupted + Bounce + X
X表示直接通过alloc_pages/__get_free_pages分配的内存,这部分内存没有在/proc/meminfo中统计。
- 用户使用内存
用户使用内存可以有几种不同的统计方式:
- 根据lru进行统计
Active + Inactive + Unevictable + HugePages_Total * Hugepagesize- 根据cache统计
当SwapCached为0的时候,用户进程使用的内存主要包括普通文件缓存Cached、块设备缓存Buffers、匿名页AnonPages和大页
Cached + AnonPages + Buffers + HugePages_Total * Hugepagesize
当SwapCached不是0 的时候,SwapCached中可能包含Shmem和AnonPages,这时候SwapCached有一部分可能与AnonPages重叠。- 根据RSS/PSS统计
所有进程使用PSS加和加上unmapped的部分、再加上buffer和hugepages
∑Pss + (Cached - mapped) + Buffers + (HugePages_Total * Hugepagesize)
所有进程使用的Pss可以通过将/proc/pid/smaps中的Pss加和得到。
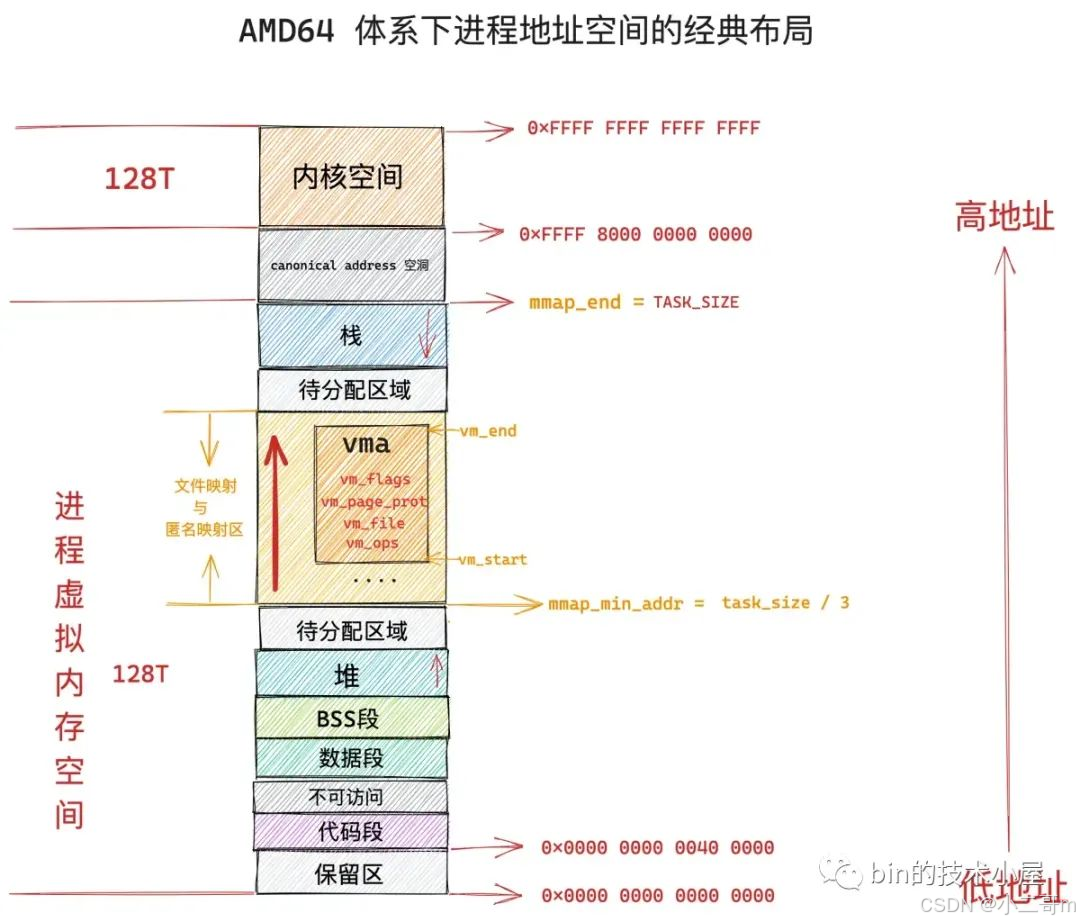
- 内存分配
内核只是在进程的虚拟地址空间中寻找出一段空闲的虚拟内存区域 vma 然后分配给本次映射而已。
vma = vm_area_alloc(mm);
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
如果是文件映射的话,内核还会额外做一项工作,就是将分配出来的这段虚拟内存区域 vma 与映射文件关联映射起来
vma->vm_file = get_file(file);
error = call_mmap(file, vma);
当有新的内存请求时:
- 快速路径(Fast Path):
尝试直接分配内存,如果空闲页足够,立即分配。
若空闲页不足但介于 low 和 high 之间,可能触发 轻量级回收(如通过 get_page_from_freelist() 尝试其他Zone或Node)。- 慢速路径(Slow Path):
若快速路径失败,调用 __alloc_pages_slowpath()。
可能触发 直接内存回收(即使 free_pages > low),但概率较低,或者唤醒kswapd
缺页中断
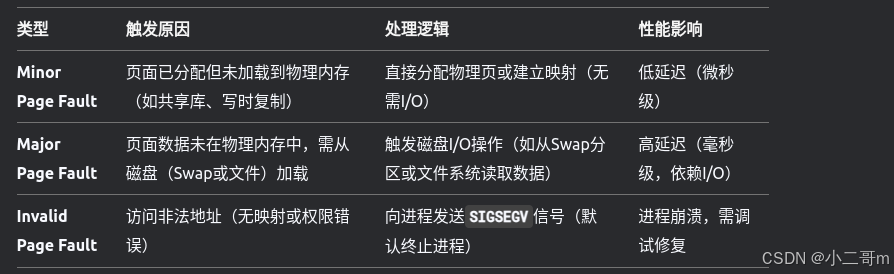
缺页中断是CPU在访问虚拟内存时,因目标页面未正确映射到物理内存(或权限不足)而触发的一种异常。操作系统通过处理此中断,完成物理内存的分配、数据加载或权限修正,确保程序可继续执行。
处理流程(以Major Fault为例)
- 中断触发:CPU检测到虚拟地址无有效物理映射。
- 进入内核态:保存上下文,跳转到缺页处理程序(如handle_mm_fault())。
- 查找原因:
检查虚拟地址是否合法(VMA区域)。
确定页面类型(匿名页、文件页、共享内存等)。- 数据加载:
若为文件页(如代码段),从磁盘读取文件内容到物理页(do_read_fault())。
若为匿名页(如堆内存),分配新页并清零(do_anonymous_page()),或从Swap分区加载。- 更新页表:建立虚拟地址到物理页的映射。
- 恢复执行:返回到用户态,重新执行触发缺页的指令。
/proc/zoneinfo
水位控制zoneinfo
- Linux中物理内存的每个zone都有自己独立的min, low和high三个档位的watermark值,在代码中以struct zone中的_watermark[NR_WMARK]来表示。
WMARK_MIN: 最低水位,代表内存显然已经不够用了。这里要分两种情况来讨论,一种是默认的操作,此时分配器将同步等待内存回收完成,再进行内存分配,也就是direct reclaim。还有一种特殊情况,如果内存分配的请求是带了PF_MEMALLOC(kswapd)标志位的,并且现在空余内存的大小可以满足本次内存分配的需求,那么也将是先分配,再回收
WMARK_LOW:低水位,代表内存已经开始吃紧,需要启动回收页内核线性kswapped去回收内存
WMARK_HIGH:高水位,代表内存还是足够的。
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
}; - spanned_pages: 代表的是这个zone中所有的页,包含空洞,计算公式是: zone_end_pfn - zone_start_pfn
present_pages: 代表的是这个zone中可用的所有物理页,计算公式是:spanned_pages-hole_pages
managed_pages: 代表的是通过buddy管理的所有可用的页,计算公式是:present_pages - reserved_pages
三者的关系是: spanned_pages > present_pages > managed_pages
超过高水位的页数计算方法是:managed_pages减去watermark[HIGH] - lowmem_reserve: 这个zone区域保留的内存,当系统内存出现不足的时候,系统就会使用这些保留的内存来做一些操作,比如使用保留的内存进程用来可以释放更多的内存
free_area:用于维护空闲的页,其中数组的下标对应页的order数。最大order目前是11。free_are的结构体
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
}; - free_list:用于将各个order的free page链接在一起
nr_free: 代表这个order中还有多个空闲page
在进行内存分配的时候,如果分配器(比如buddy allocator)发现当前空余内存的值低于"low"但高于"min",说明现在内存面临一定的压力,那么在此次内存分配完成后,kswapd将被唤醒,以执行内存回收操作。在这种情况下,内存分配虽然会触发内存回收,但不存在被内存回收所阻塞的问题,两者的执行关系是异步的
这里所说的"空余内存"其实是一个zone总的空余内存减去其lowmem_reserve的值。对于kswapd来说,要回收多少内存才算完成任务呢?只要把空余内存的大小恢复到"high"对应的watermark值就可以了,当然,这取决于当前空余内存和"high"值之间的差距,差距越大,需要回收的内存也就越多。"low"可以被认为是一个警戒水位线,而"high"则是一个安全的水位线。

只有"low"与"min"之间之间的这段区域才是kswapd的活动空间,低于了"min"会触发direct reclaim,高于了"low"又不会唤醒kswapd

按照可移动性将内存页分为以下三个类型:
UNMOVABLE:在内存中位置固定,不能随意移动。kernel分配的内存基本属于这个类型;
RECLAIMABLE:不能移动,但可以删除回收。例如文件映射内存;
MOVABLE:可以随意移动,用户空间的内存基本属于这个类型
swappines
/proc/sys/vm/swappiness这个文件,这个文件的值用来定义内核使用swap的积极程度,是个可以用来调整跟swap相关的参数。值越高,内核就会越积极的使用swap,值越低就会降低对swap的使用积极性。这个文件的默认值是android为100, linux为60,可以的取值范围是0-100。
- swappiness这个参数实际上是指导内核在清空内存的时候,是更倾向于清空file-backed内存还是更倾向于进行匿名页的交换的。当然,这只是个倾向性,是指在两个都够用的情况下,更愿意用哪个,如果不够用了,那么该交换还是要交换。
- 如果swappiness设置为100,那么匿名页和文件将用同样的优先级进行回收。很明显,使用清空文件的方式将有利于减轻内存回收时可能造成的IO压力。因为如果file-backed中的数据不是脏数据的话,那么可以不用写回,这样就没有IO发生,而一旦进行交换,就一定会造成IO。
- 如果swappiness设置为60,这样回收内存时,对file-backed的文件cache内存的清空比例会更大,内核将会更倾向于进行缓存清空而不是交换。
- 如果这个值为0,那么内存在free和file-backed(文件映射页的大小)使用的页面总量小于高水位标记(high water mark)之前,不会发生交换。有剩余内存的情况下可能发生交换。
Watermark
Watermark(水位线) 是用于管理内存回收的关键机制。水位线定义了系统内存的不同阈值,当空闲内存低于某个水位线时,内核会触发相应的内存回收操作
- 定义
inux 内核为每个内存区域(Zone)定义了三个水位线:
min 水位线:
表示系统内存的最低阈值。
当空闲内存低于 min 水位线时,系统会触发紧急内存回收(如直接内存回收)。
low 水位线:
表示系统内存的较低阈值。
当空闲内存低于 low 水位线时,系统会唤醒 kswapd 线程进行异步内存回收。
high 水位线:
表示系统内存的较高阈值。
当空闲内存高于 high 水位线时,系统认为内存充足,停止内存回收。- 计算方式
水位线的计算通常基于以下公式:
min = (total_memory * min_free_kbytes) / 100
low = min * 1.5
high = min * 2
其中:
total_memory 是系统的总内存大小。
min_free_kbytes 是一个内核参数,表示系统保留的最小空闲内存(以 KB 为单位)。
PSI

对上,PSI 模块通过文件系统节点向用户空间开放两种形态的接口。一种是系统级别的接口,即输出整个系统级别的资源压力信息。另外一种是结合 control group,进行更精细化的分组。
对下,PSI 模块通过在内存管理模块以及调度器模块中插桩,我们可以跟踪每一个任务由于 memory、io 以及 CPU 资源而进入等待状态的信息。例如系统中处于 iowait 状态的 task 数目、由于等待 memory 资源而处于阻塞状态的任务数目。
基于 task 维度的信息,PSI 模块会将其汇聚成 PSI group 上的 per cpu 维度的时间信息。例如该cpu上部分任务由于等待 IO 操作而阻塞的时间长度(CPU 并没有浪费,还有其他任务在执行)。PSI group 还会设定一个固定的周期去计算该采样周期内核的当前 psi 值(基于该 group 的 per cpu 时间统计信息)。
为了避免 PSI 值的抖动,实际上上层应用通过系统调用获取某个 PSI group 的压力值的时候会上报近期一段时间值的滑动平均值。
每类资源的压力信息都通过 proc 文件系统的独立文件来提供,路径为 /proc/pressure/ – cpu, memory, and io.
- 其中 CPU 压力信息格式如下:
some avg10=2.98 avg60=2.81 avg300=1.41 total=268109926- memory 和 io 格式如下:
some avg10=0.30 avg60=0.12 avg300=0.02 total=4170757
full avg10=0.12 avg60=0.05 avg300=0.01 total=1856503
avg10、avg60、avg300 分别代表 10s、60s、300s 的时间周期内的阻塞时间百分比。total 是总累计时间,以毫秒为单位。
some 这一行,代表至少有一个任务在某个资源上阻塞的时间占比,full 这一行,代表所有的非idle任务同时被阻塞的时间占比,这期间 cpu 被完全浪费,会带来严重的性能问题。我们以 IO 的 some 和 full 来举例说明,假设在 60 秒的时间段内,系统有两个 task,在 60 秒的周期内的运行情况如下图所示:

红色阴影部分表示任务由于等待 IO 资源而进入阻塞状态。Task A 和 Task B 同时阻塞的部分为 full,占比 16.66%;至少有一个任务阻塞(仅 Task B 阻塞的部分也计算入内)的部分为 some,占比 50%。
some 和 full 都是在某一时间段内阻塞时间占比的总和,阻塞时间不一定连续,如下图所示:

IO 和 memory 都有 some 和 full 两个维度,那是因为的确有可能系统中的所有任务都阻塞在 IO 或者 memory 资源,同时 CPU 进入 idle 状态。
但是 CPU 资源不可能出现这个情况:不可能全部的 runnable 的任务都等待 CPU 资源,至少有一个 runnable 任务会被调度器选中占有 CPU 资源,因此 CPU 资源没有 full 维度的 PSI 信息呈现。
通过这些阻塞占比数据,我们可以看到短期以及中长期一段时间内各种资源的压力情况,可以较精确的确定时延抖动原因,并制定对应的负载管理策略。
PSI 相关源代码比较简单,核心功能都在 kernel/sched/psi.c 文件中实现。
- 初始化
在 psi_proc_init 函数中完成 PSI 接口文件节点的创建。首先建立proc/pressure目录,然后 3 个 proc_create 函数创建了 io、memory 和 cpu 三个 proc 属性文件:
proc_mkdir(“pressure”, NULL);
proc_create(“pressure/io”, 0, NULL, &psi_io_fops);
proc_create(“pressure/memory”, 0, NULL, &psi_memory_fops);
proc_create(“pressure/cpu”, 0, NULL, &psi_cpu_fops);
在 psi_init 函数中初始化统计管理结构和更新任务的周期:
// 将jiffies转换为对应的ns值, 2s
psi_period = jiffies_to_nsecs(PSI_FREQ);
group_init(&psi_system);

日志分析
lmkd相关日志从标签是lowmemorykiller,可以搜索这个关键字查看低内存情况下查杀进程信息,如:
02-23 00:39:03.885 lmkd 978 978 E lowmemorykiller: Kill ‘com.xiaomi.account:accountservice’ (10282), uid 10098, oom_adj 945 to free 79680kB
02-23 00:39:03.886 lmkd 978 978 I lowmemorykiller: Reclaimed 79680kB, cache(717872kB) and free(375732kB)-reserved(109768kB) below min(765000kB) for oom_adj 900
这两行日志对应的代码如下所示:
ULMK_LOG(E, “Kill ‘%s’ (%d), uid %d, oom_adj %d to free %ldkB”, taskname, pid, uid, procp->oomadj, tasksize * page_k);
说明:taskname是通过/proc/pid/cmdline读取的信息
tasksize 是一般情况是通过/proc/pid/statm中的第二个参数rss页大小,也可能从/proc/pid/status中的VmSwap页大小
page_k是一个内存页的大小,默认是4KB
ALOGI("Reclaimed %ldkB, cache(%ldkB) and "
"free(%" PRId64 "kB)-reserved(%" PRId64 "kB) below min(%ldkB) for oom_adj %d",
pages_freed * page_k,
other_file * page_k, mi.field.nr_free_pages * page_k,
zi.field.totalreserve_pages * page_k,
minfree * page_k, min_score_adj);
说明:
pages_freed就是上面所说的tasksize,通常是通过/proc/pid/statm中的第二个参数rss页大小
other_file的定义如下:通过解析/proc/meminfo相关字段信息进行计算的
if (mi.field.nr_file_pages > (mi.field.shmem(tmpfs 使用的内存数) + mi.field.unevictable(不能 swap out 的内存) + mi.field.swap_cached(swap出去又读进内存中的数据))) {
other_file = (mi.field.nr_file_pages - mi.field.shmem - mi.field.unevictable - mi.field.swap_cached);
} else {
other_file = 0;
}
nr_free_pages对应的是/proc/meminfo中的字段MemFree
otalreserve_pages 解析/proc/zoneinfo并匹配相应字段信息,获取保留页的大小,前面已经介绍了。
minfree和oom_adj 是一一对应的,这里是oom_adj是900时,对应的可用内存是191250*4K
kill reason 大致分为:
- PRESSURE_AFTER_KILL
- NOT_RESPONDING
- LOW_SWAP_AND_THRASHING
- LOW_MEM_AND_SWAP
- LOW_MEM_AND_SWAP_UTIL
- LOW_MEM_AND_THRASHING
- DIRECT_RECL_AND_THRASHING
- LOW_FILECACHE_AFTER_THRASHING
- 状态 PRESSURE_AFTER_KILL
此状态条件是:cycle_after_kill && wmark < WMARK_LOW
cycle_after_kill 为true 表明此时还处于killing 状态,并且水位已经低于low 水位。此状态通常发生在memory 压力测试中。
wmark的值即为proc/zoneinfo节点中的nr_free_pages.- 状态 NOT_RESPONDING
此状态条件是:level == VMPRESS_LEVEL_CRITICAL && events !=0
此时内存pressure 已经超出了PSI complete stall,即full 状态设定的阈值。此时设备处于拼命reclaim memory ,这有可能导致ANR 产生。- 状态LOW_SWAP_AND_THRASHING
此状态条件是:swap_is_low && thrashing > thrashing_limit_pct
swap_is_low 是swap 空间已经超过底线了,这个底线是详细看step 2。
thrashing 是workset refault值基于file-backed 页面缓存的抖动百分比,详细看step 4。
thrashing_limit_pct 来自prop ro.lmk.thrashing_limit,对于low ram 该值为30,否则为100;
但如果水位还没有低于MIN,并且thrashing 没有高于thrashing_critical_pct(由prop ro.lmk.thrashing_limit_critical指定,如果未定义该属性,默认取thrashing_limit_pct的2倍) 时,不去kill perceptible 之下的应用。- 状态 LOW_MEM_AND_SWAP
此状态条件是: swap_is_low && wmark < WMARK_HIGH
此时swap 低于设限的阈值,free pages 处于水位 HIGH 之下(有可能已经处于MIN 之下)。
但如果水位还没有低于MIN,并且thrashing 没有高于thrashing_critical_pct(由prop ro.lmk.thrashing_limit_critical指定,如果未定义该属性,默认取thrashing_limit_pct的2倍) 时,不去kill perceptible 之下的应用。- LOW_MEM_AND_SWAP_UTIL
此状态条件为: wmark < WMARK_HIGH && swap_util_max < 100 && (swap_util = calc_swap_utilization(&mi)) > swap_util_max
此时的内存水位已经很低了,swap_util_max由属性ro.lmk.swap_util_max指定,默认为100%,表示最大可使用的交换内存量。
且通过meminfo计算出的交换内存使用大于设置的可用swap内存。
说明即使大量anon的内存被交换后,swap的使用量依旧很高。说明此时使用的不可交换的内存造成了内存压力。- LOW_MEM_AND_THRASHING
此状态条件是: wmark < WMARK_HIGH && thrashing > thrashing_limit
水位在HIGH 之下(有可能处于MIN),并且抖动值已经超过 thrashing_limit。标记此时处于低水位并抖动状态。
如果抖动的值没有超过了ro.lmk.thrashing_limit_critical 设定的(默认为ro.lmk.thrashing_limit 2倍),则不去kill perceptible 之下的进程。- DIRECT_RECL_AND_THRASHING
此状态条件是:reclaim == DIRECT_RECLAIM && thrashing > thrashing_limit
当抖动大于limit 值,kswap 进入reclaim状态时,就会kill apps。
默认kill apps 的min_score_adj 是从0 开始,有些条件不是很过分时min_score_adj 会选择从PERCEPTIBLE_APP_ADJ + 1 开始。最终根据该min_score_adj 传入find_and_kill_process 找到合适的进程进行kill。- LOW_FILECACHE_AFTER_THRASHING
此状态条件为file_lru_kb < filecache_min_kb

















 6955
6955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









