







关于Surface请参考下面文章
SurfaceFlinger学习笔记之View Layout Draw过程分析
下面代码基于android T,下面以绘制本地图片为例,介绍绘制流程
整个demo为底部三个tab,在home页绘制一张图片
allocateBuffers流程
- 主线程ViewRootImpl.performTraversals时调用HardwareRenderer.allocateBuffers,进而调用RenderProxy::allocateBuffers,然后在mRenderThread线程执行CanvasContext::allocateBuffers
- CanvasContext::allocateBuffers调用ANativeWindow_tryAllocateBuffers,进而调用BufferQueueProducer::allocateBuffers
- 通过 HIDL::IAllocator::allocate::client接口调用vendor.qti.hardware.display.allocator-service中
准备流程
- 第一步:SkiaOpenGLPipeline::getFrame或者SkiaVulkanPipeline::getFrame

根据是否开启ro.hwui.use_vulkan开区分,T上默认false,U上默认为true
先介绍T上流程:
调用EglManager::beginFrame开始一个新的渲染帧,并返回一个包含渲染帧信息的 Frame 对象
- 调用 makeCurrent 函数,进而调用eglMakeCurrent(mEglDisplay, surface, surface, mEglContext)
将当前线程的 OpenGL 上下文设置为与传入的 EGLSurface 相关联的上下文,以便进行渲染操作- 调用 eglQuerySurface 函数查询 EGLSurface 的宽度和高度,并将它们保存到 frame.mWidth 和 frame.mHeight 成员变量中
- 调用queryBufferAge查询可用buffer,这里主要调用eglQuerySurface,传递EGL_BUFFER_AGE_EXT参数,执行dequeueBuffer流程
- 调用eglBeginFrame开始一个新的渲染帧,并返回 Frame 对象,以便进行后续的渲染操作
* frameworks/base/libs/hwui/renderthread/EglManager.cpp
Frame EglManager::beginFrame(EGLSurface surface) {
LOG_ALWAYS_FATAL_IF(surface == EGL_NO_SURFACE, "Tried to beginFrame on EGL_NO_SURFACE!");
makeCurrent(surface);
Frame frame;
frame.mSurface = surface;
eglQuerySurface(mEglDisplay, surface, EGL_WIDTH, &frame.mWidth);
eglQuerySurface(mEglDisplay, surface, EGL_HEIGHT, &frame.mHeight);
frame.mBufferAge = queryBufferAge(surface);
eglBeginFrame(mEglDisplay, surface);
return frame;
}
EGLint EglManager::queryBufferAge(EGLSurface surface) {
switch (mSwapBehavior) {
case SwapBehavior::Discard:
return 0;
case SwapBehavior::Preserved:
return 1;
case SwapBehavior::BufferAge:
EGLint bufferAge;
eglQuerySurface(mEglDisplay, surface, EGL_BUFFER_AGE_EXT, &bufferAge);
return bufferAge;
}
return 0;
}
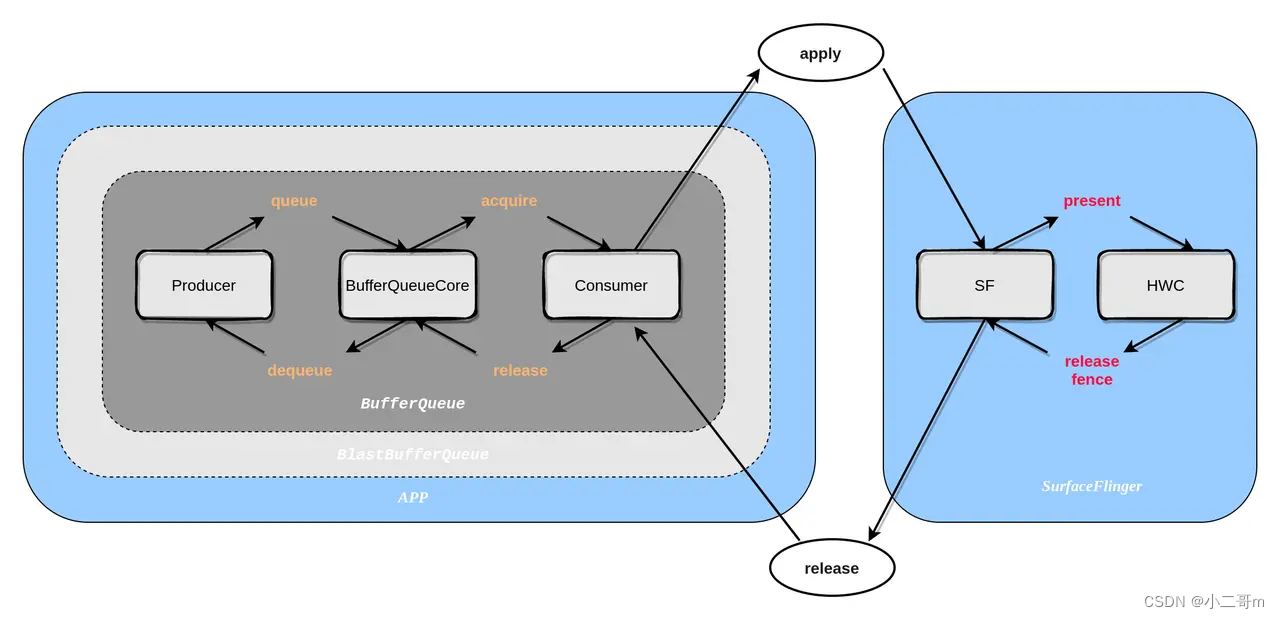
gui里面的Surface继承ANativeWindow,ANativeWindow实现在frameworks/native/libs/nativewindow/include/system/window.h中,定义dequeueBuffer、lockBuffer、query等操作.
EglManager::queryBufferAge调用device/generic/goldfish-opengl/system/egl/egl.cpp中的eglQuerySurface,进而调用到egl_platform_entries::eglQuerySurfaceImpl
而后通过libGLESv2_adreno.so调用到ANativeWindow_dequeueBuffer执行dequeueBuffer流程
调用堆栈如下:
#00 pc 000000000010a5d0 /system/lib64/libgui.so (android::Surface::hook_dequeueBuffer(ANativeWindow*, ANativeWindowBuffer**, int*)+92)
#01 pc 0000000000005c6c /system/lib64/libnativewindow.so (ANativeWindow_dequeueBuffer+16)
#02 pc 0000000000014c18 /vendor/lib64/egl/eglSubDriverAndroid.so
#03 pc 0000000000014290 /vendor/lib64/egl/eglSubDriverAndroid.so
#04 pc 00000000002bf958 /vendor/lib64/egl/libGLESv2_adreno.so (!!!0000!59bef17764eba5e897c3f9ebcb5264!ee4b625!+280)
#05 pc 00000000002ad1e0 /vendor/lib64/egl/libGLESv2_adreno.so (!!!0000!76a447c8b7e9705dc6af2d47a4b56b!ee4b625!+128)
#06 pc 000000000001f68c /system/lib64/libEGL.so (android::eglQuerySurfaceImpl(void*, void*, int, int*)+212)
#07 pc 000000000001c5e4 /system/lib64/libEGL.so (eglQuerySurface+68)
#08 pc 00000000002888bc /system/lib64/libhwui.so (android::uirenderer::renderthread::EglManager::beginFrame(void*)+188)
#09 pc 00000000002839c0 /system/lib64/libhwui.so (android::uirenderer::renderthread::CanvasContext::draw()+268)
#10 pc 0000000000286ba0 /system/lib64/libhwui.so (std::__1::__function::__func<android::uirenderer::renderthread::DrawFrameTask::postAndWait()::$_0, std::__1::allocator<android::uirenderer::renderthread::DrawFrameTask::postAndWait()::$_0>, void ()>::operator()() (.c1671e787f244890c877724752face20)+968)
#11 pc 0000000000276114 /system/lib64/libhwui.so (android::uirenderer::WorkQueue::process()+588)
#12 pc 0000000000297814 /system/lib64/libhwui.so (android::uirenderer::renderthread::RenderThread::threadLoop()+416)
#13 pc 00000000000135d8 /system/lib64/libutils.so (android::Thread::_threadLoop(void*)+424)
注:
如果是软绘制,那么会通过主线程的ViewRootImpl.drawSoftware,调用Surface::lock,进而执行Surface::dequeueBuffer,trace如下
U上使使用vulkan流程

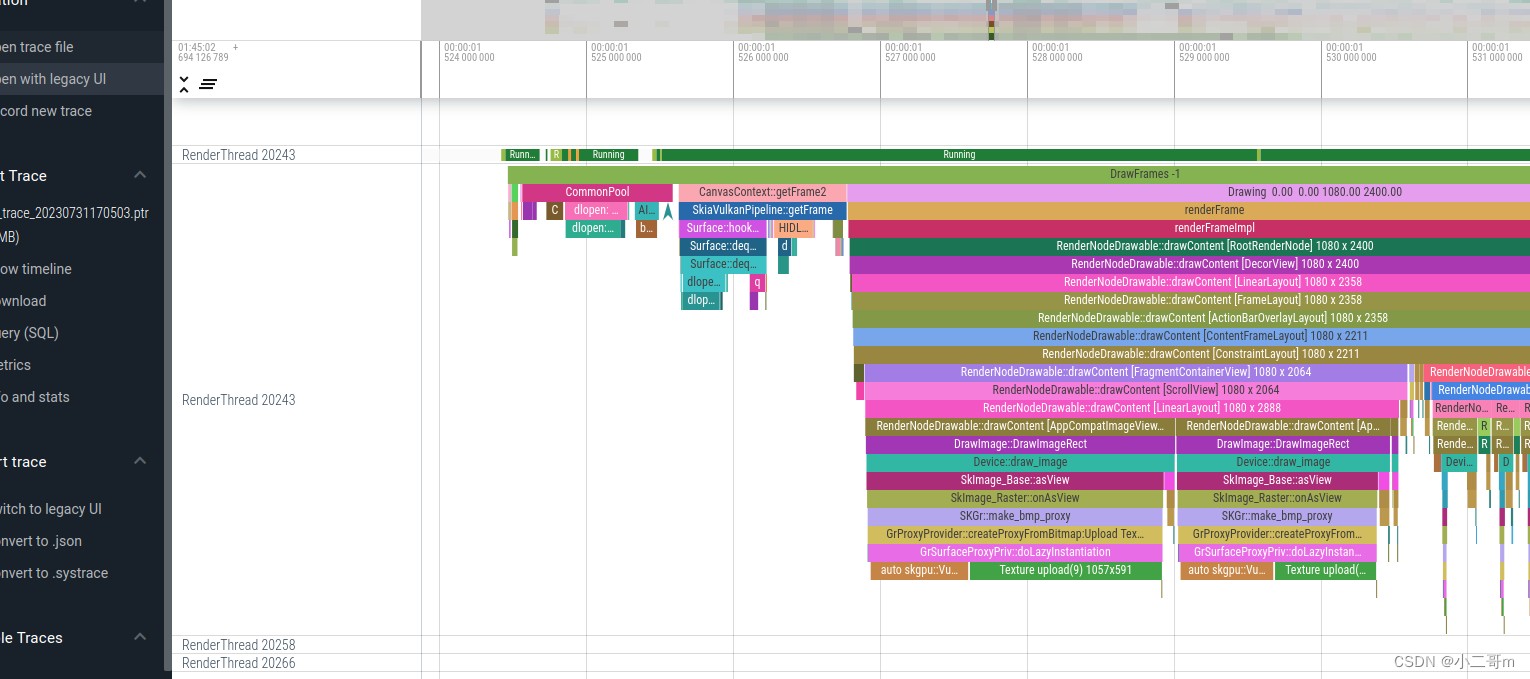
和T上不同的是,U上通过VulkanManager::dequeueNextBuffer->VulkanSurface::dequeueNativeBuffer->ANativeWindow::dequeueBuffer直接调用的,不是通过egl调用
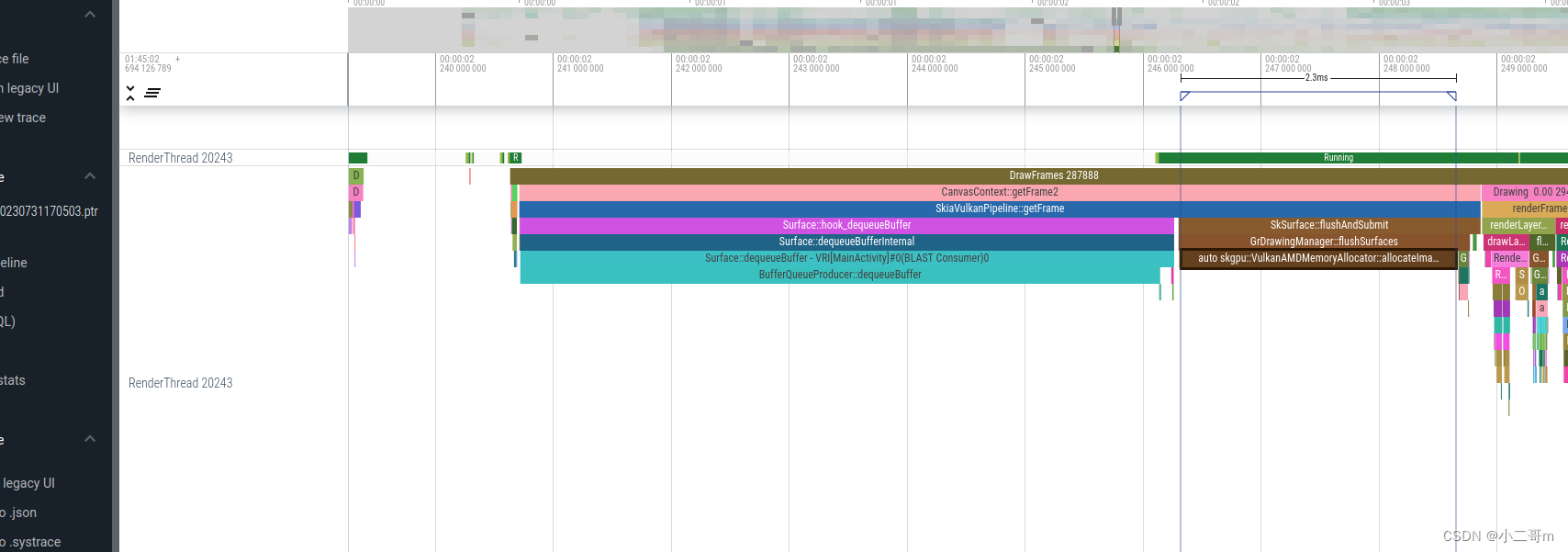
Surface::dequeueBuffer执行如下
- BufferQueueProducer::dequeueBuffer
- FenceMonitor::queueFence
该函数用于跟踪帧缓冲区的状态变化。当 SurfaceFlinger 将帧缓冲区提交到硬件合成器时,它会创建一个 Fence 对象,并将其加入到 FenceMonitor 的监控队列中。当硬件合成器完成帧缓冲区的渲染并将其输出到显示设备上时,该 Fence 对象的状态将变为 signaled 状态,并立即回调其回调函数,通知 SurfaceFlinger 可以继续渲染下一帧了。- BufferQueueProducer::requestBuffer 请求一个缓冲区
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
...
status_t returnFlags = NO_ERROR;
EGLDisplay eglDisplay = EGL_NO_DISPLAY;
EGLSyncKHR eglFence = EGL_NO_SYNC_KHR;
bool attachedByConsumer = false;
{ // Autolock scope
ListenerHolder holder;
std::unique_lock<std::mutex> lock(mCore->mMutex);
// 进行自动加锁,如果没有空闲的缓冲区,但是正在分配缓冲区,则等待分配完成。如果要求使用默认的宽高,则使用默认的宽高
if (mCore->mFreeBuffers.empty() && mCore->mIsAllocating) {
mDequeueWaitingForAllocation = true;
mCore->waitWhileAllocatingLocked(lock);
mDequeueWaitingForAllocation = false;
mDequeueWaitingForAllocationCondition.notify_all();
}
if (format == 0) {
format = mCore->mDefaultBufferFormat;
}
// Enable the usage bits the consumer requested
usage |= mCore->mConsumerUsageBits;
const bool useDefaultSize = !width && !height;
if (useDefaultSize) {
width = mCore->mDefaultWidth;
height = mCore->mDefaultHeight;
if (mCore->mAutoPrerotation &&
(mCore->mTransformHintInUse & NATIVE_WINDOW_TRANSFORM_ROT_90)) {
std::swap(width, height);
}
}
int found = BufferItem::INVALID_BUFFER_SLOT;
while (found == BufferItem::INVALID_BUFFER_SLOT) {
// 检查当前是否有空闲的槽位,如果有则返回一个空闲槽位的编号;如果没有,则等待直到有槽位可用
status_t status = waitForFreeSlotThenRelock(FreeSlotCaller::Dequeue, lock, &found);
if (status != NO_ERROR) {
return status;
}
// This should not happen
if (found == BufferQueueCore::INVALID_BUFFER_SLOT) {
BQ_LOGE("dequeueBuffer: no available buffer slots");
return -EBUSY;
}
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
//如果不允许分配新的缓冲区,waitForFreeSlotThenRelock 必须返回一个包含缓冲区的槽位。如果这个缓冲区需要重新分配才能满足请求的属性,我们会释放它并尝试获取另一个缓冲区。
if (!mCore->mAllowAllocation) {
if (buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage)) {
if (mCore->mSharedBufferSlot == found) {
BQ_LOGE("dequeueBuffer: cannot re-allocate a sharedbuffer");
return BAD_VALUE;
}
mCore->mFreeSlots.insert(found);
mCore->clearBufferSlotLocked(found);
found = BufferItem::INVALID_BUFFER_SLOT;
continue;
}
}
}
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
if (mCore->mSharedBufferSlot == found &&
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage)) {
BQ_LOGE("dequeueBuffer: cannot re-allocate a shared"
"buffer");
return BAD_VALUE;
}
if (mCore->mSharedBufferSlot != found) {
mCore->mActiveBuffers.insert(found);
}
*outSlot = found;
// 输出类似VRI[MainActivity]#0(BLAST Consumer)0: 3的trace
// VRI[MainActivity]为ViewRootImpl的tag
ATRACE_BUFFER_INDEX(found);
attachedByConsumer = mSlots[found].mNeedsReallocation;
mSlots[found].mNeedsReallocation = false;
mSlots[found].mBufferState.dequeue();
if ((buffer == nullptr) ||
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage))
{
mSlots[found].mAcquireCalled = false;
mSlots[found].mGraphicBuffer = nullptr;
mSlots[found].mRequestBufferCalled = false;
mSlots[found].mEglDisplay = EGL_NO_DISPLAY;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
mCore->mBufferAge = 0;
mCore->mIsAllocating = true;
returnFlags |= BUFFER_NEEDS_REALLOCATION;
} else {
// We add 1 because that will be the frame number when this buffer
// is queued
mCore->mBufferAge = mCore->mFrameCounter + 1 - mSlots[found].mFrameNumber;
}
BQ_LOGV("dequeueBuffer: setting buffer age to %" PRIu64,
mCore->mBufferAge);
if (CC_UNLIKELY(mSlots[found].mFence == nullptr)) {
BQ_LOGE("dequeueBuffer: about to return a NULL fence - "
"slot=%d w=%d h=%d format=%u",
found, buffer->width, buffer->height, buffer->format);
}
eglDisplay = mSlots[found].mEglDisplay;
eglFence = mSlots[found].mEglFence;
// Don't return a fence in shared buffer mode, except for the first
// frame.
*outFence = (mCore->mSharedBufferMode &&
mCore->mSharedBufferSlot == found) ?
Fence::NO_FENCE : mSlots[found].mFence;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
// If shared buffer mode has just been enabled, cache the slot of the
// first buffer that is dequeued and mark it as the shared buffer.
if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot ==
BufferQueueCore::INVALID_BUFFER_SLOT) {
mCore->mSharedBufferSlot = found;
mSlots[found].mBufferState.mShared = true;
}
if (!(returnFlags & BUFFER_NEEDS_REALLOCATION)) {
if (mCore->mConsumerListener != nullptr) {
auto slotId = mSlots[*outSlot].mGraphicBuffer->getId();
holder.setListener(mCore->mConsumerListener);
holder.setDequeuePayload(slotId);
}
}
} // Autolock scope
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
// 重新分配buffer,创建GraphicBuffer
BQ_LOGV("dequeueBuffer: allocating a new buffer for slot %d", *outSlot);
sp<GraphicBuffer> graphicBuffer = new GraphicBuffer(
width, height, format, BQ_LAYER_COUNT, usage,
{mConsumerName.string(), mConsumerName.size()});
status_t error = graphicBuffer->initCheck();
{ // Autolock scope
ListenerHolder holder;
std::unique_lock<std::mutex> lock(mCore->mMutex);
if (error == NO_ERROR && !mCore->mIsAbandoned) {
graphicBuffer->setGenerationNumber(mCore->mGenerationNumber);
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;
if (mCore->mConsumerListener != nullptr) {
auto slotId = mSlots[*outSlot].mGraphicBuffer->getId();
holder.setListener(mCore->mConsumerListener);
holder.setDequeuePayload(slotId);
}
}
mCore->mIsAllocating = false;
mCore->mIsAllocatingCondition.notify_all();
...
VALIDATE_CONSISTENCY();
} // Autolock scope
}
if (attachedByConsumer) {
returnFlags |= BUFFER_NEEDS_REALLOCATION;
}
if (eglFence != EGL_NO_SYNC_KHR) {
// 如果缓冲区有 EGL 同步标志,则等待同步完成
EGLint result = eglClientWaitSyncKHR(eglDisplay, eglFence, 0,
1000000000);
...
eglDestroySyncKHR(eglDisplay, eglFence);
}
if (outBufferAge) {
*outBufferAge = mCore->mBufferAge;
}
addAndGetFrameTimestamps(nullptr, outTimestamps);
return returnFlags;
}
绘制流程
- 第二步:SkiaOpenGLPipeline::draw
SkiaOpenGLPipeline::draw
- 调用EglManager.damageFrame主要是部分更新参数的设置,前面我们也damage的区域就是前面Prepare时累加器累加出来的
- 调用renderFrame进行纹理创建,实现在基类SkiaPipeline::renderFrame中
- 调用flushAndSubmit,进行纹理绑定
* frameworks/base/libs/hwui/pipeline/skia/SkiaOpenGLPipeline.cpp
bool SkiaOpenGLPipeline::draw(const Frame& frame, const SkRect& screenDirty, const SkRect& dirty,
const LightGeometry& lightGeometry,
LayerUpdateQueue* layerUpdateQueue, const Rect& contentDrawBounds,
bool opaque, const LightInfo& lightInfo,
const std::vector<sp<RenderNode>>& renderNodes,
FrameInfoVisualizer* profiler) {
1. damageFrame
mEglManager.damageFrame(frame, dirty);
...
// 这里调用SkSurface::MakeFromBackendRenderTarget
sk_sp<SkSurface> surface(SkSurface::MakeFromBackendRenderTarget(
mRenderThread.getGrContext(), backendRT, this->getSurfaceOrigin(), colorType,
mSurfaceColorSpace, &props));
LightingInfo::updateLighting(lightGeometry, lightInfo);
2. renderFrame
renderFrame(*layerUpdateQueue, dirty, renderNodes, opaque, contentDrawBounds, surface,
SkMatrix::I());
...
{
ATRACE_NAME("flush commands");
3. flush commands
surface->flushAndSubmit();
}
layerUpdateQueue->clear();
...
return {true, IRenderPipeline::DrawResult::kUnknownTime};
}
创建纹理流程:
创建纹理调用堆栈
#00 pc 00000000005b4234 /system/lib64/libhwui.so (GrGLGpu::createTexture(SkISize, GrGLFormat, unsigned int, GrRenderable, GrGLTextureParameters::SamplerOverriddenState*, int, GrProtected)+108)
#01 pc 00000000005b3d2c /system/lib64/libhwui.so (GrGLGpu::onCreateTexture(SkISize, GrBackendFormat const&, GrRenderable, int, SkBudgeted, GrProtected, int, unsigned int)+224)
#02 pc 0000000000543994 /system/lib64/libhwui.so (GrGpu::createTextureCommon(SkISize, GrBackendFormat const&, GrTextureType, GrRenderable, int, SkBudgeted, GrProtected, int, unsigned int)+256)
#03 pc 0000000000543cf0 /system/lib64/libhwui.so (GrGpu::createTexture(SkISize, GrBackendFormat const&, GrTextureType, GrRenderable, int, SkBudgeted, GrProtected, GrColorType, GrColorType, GrMipLevel const*, int)+464)
#04 pc 000000000055b220 /system/lib64/libhwui.so (GrResourceProvider::createTexture(SkISize, GrBackendFormat const&, GrTextureType, GrColorType, GrRenderable, int, SkBudgeted, GrMipmapped, GrProtected, GrMipLevel const*)+636)
#05 pc 000000000055c290 /system/lib64/libhwui.so (GrResourceProvider::createTexture(SkISize, GrBackendFormat const&, GrTextureType, GrColorType, GrRenderable, int, SkBudgeted, SkBackingFit, GrProtected, GrMipLevel const&)+148)
#06 pc 000000000054e168 /system/lib64/libhwui.so (std::__1::__function::__func<GrProxyProvider::createNonMippedProxyFromBitmap(SkBitmap const&, SkBackingFit, SkBudgeted)::$_0, std::__1::allocator<GrProxyProvider::createNonMippedProxyFromBitmap(SkBitmap const&, SkBackingFit, SkBudgeted)::$_0>, GrSurfaceProxy::LazyCallbackResult (GrResourceProvider*, GrSurfaceProxy::LazySurfaceDesc const&)>::operator()(GrResourceProvider*&&, GrSurfaceProxy::LazySurfaceDesc const&) (.14006f304cec4648659a8a056b977056)+136)
#07 pc 00000000005613b0 /system/lib64/libhwui.so (GrSurfaceProxyPriv::doLazyInstantiation(GrResourceProvider*)+180)
#08 pc 000000000054c5ec /system/lib64/libhwui.so (GrProxyProvider::createProxyFromBitmap(SkBitmap const&, GrMipmapped, SkBackingFit, SkBudgeted)+1276)
#09 pc 000000000056a6f8 /system/lib64/libhwui.so (make_bmp_proxy(GrProxyProvider*, SkBitmap const&, GrColorType, GrMipmapped, SkBackingFit, SkBudgeted)+160)
#10 pc 000000000056a218 /system/lib64/libhwui.so (GrMakeCachedBitmapProxyView(GrRecordingContext*, SkBitmap const&, GrMipmapped)+424)
#11 pc 00000000003fdeb4 /system/lib64/libhwui.so (SkImage_Raster::onAsView(GrRecordingContext*, GrMipmapped, GrImageTexGenPolicy) const+380)
#12 pc 00000000003fdfb8 /system/lib64/libhwui.so (SkImage_Raster::onAsFragmentProcessor(GrRecordingContext*, SkSamplingOptions, SkTileMode const*, SkMatrix const&, SkRect const*, SkRect const*) const+100)
#13 pc 00000000003f8360 /system/lib64/libhwui.so (SkImage_Base::asFragmentProcessor(GrRecordingContext*, SkSamplingOptions, SkTileMode const*, SkMatrix const&, SkRect const*, SkRect const*) const+148)
#14 pc 000000000064fb60 /system/lib64/libhwui.so ((anonymous namespace)::draw_image(GrRecordingContext*, skgpu::v1::SurfaceDrawContext*, GrClip const*, SkMatrixProvider const&, SkPaint const&, SkImage_Base const&, SkRect const&, SkRect const&, SkPoint const*, SkMatrix const&, GrAA, GrQuadAAFlags, SkCanvas::SrcRectConstraint, SkSamplingOptions, SkTileMode)+1680)
#15 pc 000000000065141c /system/lib64/libhwui.so (skgpu::v1::Device::drawImageQuad(SkImage const*, SkRect const*, SkRect const*, SkPoint const*, GrAA, GrQuadAAFlags, SkMatrix const*, SkSamplingOptions const&, SkPaint const&, SkCanvas::SrcRectConstraint)+3092)
#16 pc 000000000064ced4 /system/lib64/libhwui.so (skgpu::v1::Device::drawImageRect(SkImage const*, SkRect const*, SkRect const&, SkSamplingOptions const&, SkPaint const&, SkCanvas::SrcRectConstraint)+80)
#17 pc 00000000002ea6b8 /system/lib64/libhwui.so (SkCanvas::onDrawImageRect2(SkImage const*, SkRect const&, SkRect const&, SkSamplingOptions const&, SkPaint const*, SkCanvas::SrcRectConstraint)+292)
#18 pc 00000000002657bc /system/lib64/libhwui.so (android::uirenderer::VectorDrawable::Tree::draw(SkCanvas*, SkRect const&, SkPaint const&)+312)
#19 pc 0000000000253668 /system/lib64/libhwui.so (android::uirenderer::DisplayListData::draw(SkCanvas*) const+132)
#20 pc 000000000023bc78 /system/lib64/libhwui.so (android::uirenderer::skiapipeline::RenderNodeDrawable::drawContent(SkCanvas*) const+1756)
#21 pc 000000000023c3b4 /system/lib64/libhwui.so (android::uirenderer::skiapipeline::RenderNodeDrawable::forceDraw(SkCanvas*) const+292)
#22 pc 00000000003095cc /system/lib64/libhwui.so (SkDrawable::draw(SkCanvas*, SkMatrix const*)+120)
#23 pc 0000000000253668 /system/lib64/libhwui.so (android::uirenderer::DisplayListData::draw(SkCanvas*) const+132)
#24 pc 000000000023bc78 /system/lib64/libhwui.so (android::uirenderer::skiapipeline::RenderNodeDrawable::drawContent(SkCanvas*) const+1756)
#25 pc 000000000023c3b4 /system/lib64/libhwui.so (android::uirenderer::skiapipeline::RenderNodeDrawable::forceDraw(SkCanvas*) const+292)
#26 pc 00000000003095cc /system/lib64/libhwui.so (SkDrawable::draw(SkCanvas*, SkMatrix const*)+120)
#27 pc 0000000000253668 /system/lib64/libhwui.so (android::uirenderer::DisplayListData::draw(SkCanvas*) const+132)
#28 pc 000000000023bc78 /system/lib64/libhwui.so (android::uirenderer::skiapipeline::RenderNodeDrawable::drawContent(SkCanvas*) const+1756)
#29 pc 000000000023c3b4 /system/lib64/libhwui.so (android::uirenderer::skiapipeline::RenderNodeDrawable::forceDraw(SkCanvas*) const+292)
#30 pc 00000000003095cc /system/lib64/libhwui.so (SkDrawable::draw(SkCanvas*, SkMatrix const*)+120)
#63 pc 000000000027e9cc /system/lib64/libhwui.so (android::uirenderer::skiapipeline::SkiaPipeline::renderFrameImpl(SkRect const&, std::__1::vector<android::sp<android::uirenderer::RenderNode>, std::__1::allocator<android::sp<android::uirenderer::RenderNode> > > const&, bool, android::uirenderer::Rect const&, SkCanvas*, SkMatrix const&)+512)
#64 pc 000000000027e50c /system/lib64/libhwui.so (android::uirenderer::skiapipeline::SkiaPipeline::renderFrame(android::uirenderer::LayerUpdateQueue const&, SkRect const&, std::__1::vector<android::sp<android::uirenderer::RenderNode>, std::__1::allocator<android::sp<android::uirenderer::RenderNode> > > const&, bool, android::uirenderer::Rect const&, sk_sp<SkSurface>, SkMatrix const&)+656)
#65 pc 000000000027c268 /system/lib64/libhwui.so (android::uirenderer::skiapipeline::SkiaOpenGLPipeline::draw(android::uirenderer::renderthread::Frame const&, SkRect const&, SkRect const&, android::uirenderer::LightGeometry const&, android::uirenderer::LayerUpdateQueue*, android::uirenderer::Rect const&, bool, android::uirenderer::LightInfo const&, std::__1::vector<android::sp<android::uirenderer::RenderNode>, std::__1::allocator<android::sp<android::uirenderer::RenderNode> > > const&, android::uirenderer::FrameInfoVisualizer*)+520)
#66 pc 0000000000283974 /system/lib64/libhwui.so (android::uirenderer::renderthread::CanvasContext::draw()+1104)
#67 pc 00000000002866b4 /system/lib64/libhwui.so (std::__1::__function::__func<android::uirenderer::renderthread::DrawFrameTask::postAndWait()::$_0, std::__1::allocator<android::uirenderer::renderthread::DrawFrameTask::postAndWait()::$_0>, void ()>::operator()() (.c1671e787f244890c877724752face20)+904)
#68 pc 0000000000276090 /system/lib64/libhwui.so (android::uirenderer::WorkQueue::process()+588)
#69 pc 00000000002972c0 /system/lib64/libhwui.so (android::uirenderer::renderthread::RenderThread::threadLoop()+416)
#70 pc 0000000000013598 /system/lib64/libutils.so (android::Thread::_threadLoop(void*)+424)
#71 pc 00000000000f5548 /apex/com.android.runtime/lib64/bionic/libc.so (__pthread_start(void*)+208)
#72 pc 000000000008ef3c /apex/com.android.runtime/lib64/bionic/libc.so (__start_thread+68)
SkiaOpenGLPipeline继承SkiaPipeline
frameworks/base/libs/hwui/pipeline/skia/SkiaPipeline.cpp
void SkiaPipeline::renderFrame(const LayerUpdateQueue& layers, const SkRect& clip,
const std::vector<sp<RenderNode>>& nodes, bool opaque,
const Rect& contentDrawBounds, sk_sp<SkSurface> surface,
const SkMatrix& preTransform) {
...
// Initialize the canvas for the current frame, that might be a recording canvas if SKP
// capture is enabled.
SkCanvas* canvas = tryCapture(surface.get(), nodes[0].get(), layers);
// draw all layers up front
renderLayersImpl(layers, opaque);
renderFrameImpl(clip, nodes, opaque, contentDrawBounds, canvas, preTransform);
endCapture(surface.get());
...
Properties::skpCaptureEnabled = previousSkpEnabled;
}
void SkiaPipeline::renderFrameImpl(const SkRect& clip,
const std::vector<sp<RenderNode>>& nodes, bool opaque,
const Rect& contentDrawBounds, SkCanvas* canvas,
const SkMatrix& preTransform) {
...
//它有多个渲染nodes,其布局如下:
// #0 -背景(内容+标题)
// #1 -内容(本地边界为(0,0),将被翻译和剪辑到背景)
// #2 -附加的覆盖节点
//通常看不到背景,因为它将完全被内容所覆盖。
//在调整大小时,它可能会部分可见。下面的渲染循环将根据内容裁剪背景,并绘制它的其余部分。然后,它将绘制裁剪到背景中的内容(因为这表明窗口正在缩小)。
//额外的节点将被绘制在顶部,没有特定的剪切语义。
//通常内容边界应该是mContentDrawBounds-然而,我们将移动它到固定的边缘,以给它一个更稳定的外观(目前)。
//如果没有内容边界,我们将忽略上面所述的分层,并从2开始。
const Rect backdrop = nodeBounds(*nodes[0]);
// 内容将填充渲染目标空间的边界(注意,内容节点边界可能较大)
Rect content(contentDrawBounds.getWidth(), contentDrawBounds.getHeight());
content.translate(backdrop.left, backdrop.top);
if (!content.contains(backdrop) && !nodes[0]->nothingToDraw()) {
// 内容不完全重叠背景,所以填充内容(右/下)
//注意:在未来,如果内容没有捕捉到背景的左/顶部,这可能还需要填充左/顶部。目前,2向上和自由形式的位置内容都在背景的上/左,所以这是没有必要的。
RenderNodeDrawable backdropNode(nodes[0].get(), canvas);
if (content.right < backdrop.right) {
//如果内容右侧不能覆盖背景,则绘制右侧的背景区域
SkAutoCanvasRestore acr(canvas, true);
canvas->clipRect(SkRect::MakeLTRB(content.right, backdrop.top, backdrop.right,
backdrop.bottom));
backdropNode.draw(canvas);
}
if (content.bottom < backdrop.bottom) {
// 将背景绘制到内容的底部
//注意:底部填充使用左/右的内容,以避免覆盖左/右填充
SkAutoCanvasRestore acr(canvas, true);
canvas->clipRect(SkRect::MakeLTRB(content.left, content.bottom, content.right,
backdrop.bottom));
backdropNode.draw(canvas);
}
}
// 绘制内容nodes及背景的左/上
RenderNodeDrawable contentNode(nodes[1].get(), canvas);
if (!backdrop.isEmpty()) {
// 计算相对背景x、y的偏移,然后做变换
float dx = backdrop.left - contentDrawBounds.left;
float dy = backdrop.top - contentDrawBounds.top;
SkAutoCanvasRestore acr(canvas, true);
canvas->translate(dx, dy);
const SkRect contentLocalClip =
SkRect::MakeXYWH(contentDrawBounds.left, contentDrawBounds.top,
backdrop.getWidth(), backdrop.getHeight());
canvas->clipRect(contentLocalClip);
contentNode.draw(canvas);
} else {
SkAutoCanvasRestore acr(canvas, true);
contentNode.draw(canvas);
}
//最后绘制剩余的-附加的覆盖节点
for (size_t index = 2; index < nodes.size(); index++) {
if (!nodes[index]->nothingToDraw()) {
SkAutoCanvasRestore acr(canvas, true);
RenderNodeDrawable overlayNode(nodes[index].get(), canvas);
overlayNode.draw(canvas);
}
}
...
}
- renderLayersImpl hardware绘制流程
* frameworks/base/libs/hwui/pipeline/skia/SkiaPipeline.cpp
void SkiaPipeline::renderLayersImpl(const LayerUpdateQueue& layers, bool opaque) {
sk_sp<GrDirectContext> cachedContext;
// 按顺序渲染所有需要更新的图层
for (size_t i = 0; i < layers.entries().size(); i++) {
RenderNode* layerNode = layers.entries()[i].renderNode.get();
// 仅在节点仍在图层上时才进行重绘,可能在帧丢失期间已被移除,但仍会保留图层以防止损坏信息丢失
if (CC_UNLIKELY(layerNode->getLayerSurface() == nullptr)) {
continue;
}
SkASSERT(layerNode->getLayerSurface());
SkiaDisplayList* displayList = layerNode->getDisplayList().asSkiaDl();
...
const Rect& layerDamage = layers.entries()[i].damage;
SkCanvas* layerCanvas = layerNode->getLayerSurface()->getCanvas();
int saveCount = layerCanvas->save();
SkASSERT(saveCount == 1);
layerCanvas->androidFramework_setDeviceClipRestriction(layerDamage.toSkIRect());
// 将局部化的光源中心计算和存储放到与可绘制对象相关的代码中。在全局状态中存储局部化的数据似乎不是正确的做法。
// 在这里和recordLayers中进行修复。
const Vector3 savedLightCenter(LightingInfo::getLightCenterRaw());
Vector3 transformedLightCenter(savedLightCenter);
// 将当前光源中心映射到 RenderNode 的坐标空间中
layerNode->getSkiaLayer()->inverseTransformInWindow.mapPoint3d(transformedLightCenter);
LightingInfo::setLightCenterRaw(transformedLightCenter);
const RenderProperties& properties = layerNode->properties();
const SkRect bounds = SkRect::MakeWH(properties.getWidth(), properties.getHeight());
if (properties.getClipToBounds() && layerCanvas->quickReject(bounds)) {
return;
}
ATRACE_FORMAT("drawLayer [%s] %.1f x %.1f", layerNode->getName(), bounds.width(),
bounds.height());
layerNode->getSkiaLayer()->hasRenderedSinceRepaint = false;
// 设置画布为透明色
layerCanvas->clear(SK_ColorTRANSPARENT);
// RenderNodeDrawable上绘制layer
RenderNodeDrawable root(layerNode, layerCanvas, false);
root.forceDraw(layerCanvas);
layerCanvas->restoreToCount(saveCount);
LightingInfo::setLightCenterRaw(savedLightCenter);
// 缓存当前的上下文,以便我们可以推迟刷新,直到所有图层都被渲染完成或上下文发生变化。
GrDirectContext* currentContext =
GrAsDirectContext(layerNode->getLayerSurface()->getCanvas()->recordingContext());
if (cachedContext.get() != currentContext) {
// 如果cache和current不一样,则执行一次flush
if (cachedContext.get()) {
ATRACE_NAME("flush layers (context changed)");
cachedContext->flushAndSubmit();
}
cachedContext.reset(SkSafeRef(currentContext));
}
}
if (cachedContext.get()) {
ATRACE_NAME("flush layers");
cachedContext->flushAndSubmit();
}
}
那么这个layers.entries数据从哪里设置的呢?
* frameworks/base/libs/hwui/LayerUpdateQueue.cpp
void LayerUpdateQueue::enqueueLayerWithDamage(RenderNode* renderNode, Rect damage) {
damage.roundOut();
damage.doIntersect(0, 0, renderNode->getWidth(), renderNode->getHeight());
if (!damage.isEmpty()) {
for (Entry& entry : mEntries) {
if (CC_UNLIKELY(entry.renderNode == renderNode)) {
entry.damage.unionWith(damage);
return;
}
}
// 在这里push进去
mEntries.emplace_back(renderNode, damage);
}
}
enqueueLayerWithDamage在RenderNode::pushLayerUpdate调用,而pushLayerUpdate在DrawFrameTask::syncFrameState->CanvasContext::prepareTree->RootRenderNode::prepareTree->RenderNode::prepareTree->RenderNode::prepareTreeImpl调用
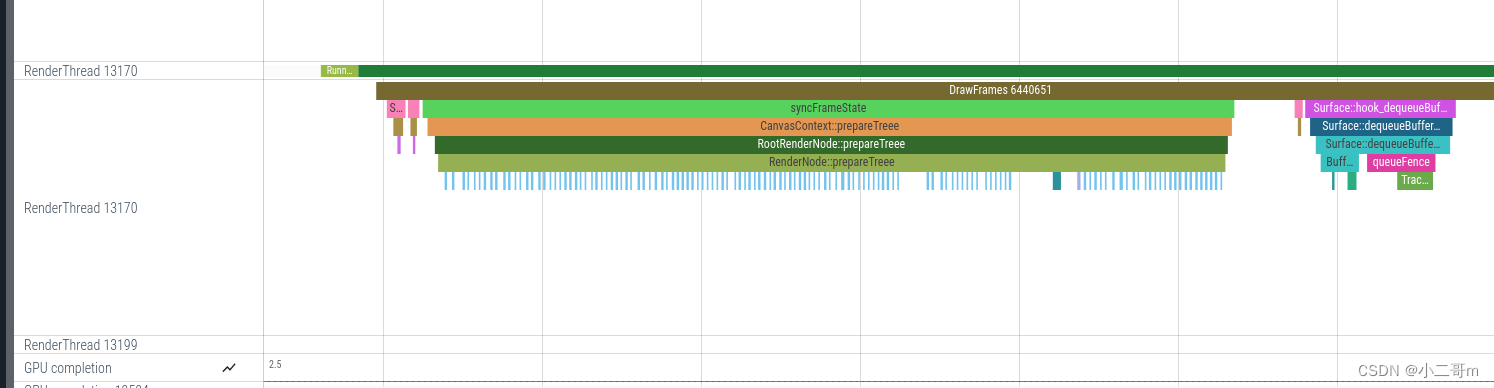
* frameworks/base/libs/hwui/RenderNode.cpp
void RenderNode::pushLayerUpdate(TreeInfo& info) {
#ifdef __ANDROID__ // Layoutlib does not support CanvasContext and Layers
LayerType layerType = properties().effectiveLayerType();
// 如果当前RenderNode不是一个图层,或者无法进行渲染(例如,View 是 detached),那么我们需要销毁之前可能存在的任何图层,调用setLayerSurface为null后,执行正常绘制流程
// 如果layer不是RenderLayer类型、宽为0、高为0、不能够渲染、不适用的layer则走非hardware绘制路程
if (CC_LIKELY(layerType != LayerType::RenderLayer) || CC_UNLIKELY(!isRenderable()) ||
CC_UNLIKELY(properties().getWidth() == 0) || CC_UNLIKELY(properties().getHeight() == 0) ||
CC_UNLIKELY(!properties().fitsOnLayer())) {
if (CC_UNLIKELY(hasLayer())) {
this->setLayerSurface(nullptr);
}
return;
}
...
SkRect dirty;
info.damageAccumulator->peekAtDirty(&dirty);
info.layerUpdateQueue->enqueueLayerWithDamage(this, dirty);
...
#endif
}
layerType怎么被设定为RenderLayer的,看如下代码,promotedToLayer返回true则为RenderLayer
这里的fitsOnLayer基本为true,mLayerProperties.mType也大部分为LayerType::None,
mNeedLayerForFunctors当制定displayList func时候为true,所以基本也为false
mImageFilter当设置ImageFilter时候为true,所以基本也为false
mLayerProperties.getStretchEffect().requiresLayer当设置拉伸效果时候为true,比如ScrollView顶部时候的拉伸特效
要么设置alpha透明度时,即alpha<1,比如淡入淡出动画等
* frameworks/base/libs/hwui/RenderProperties.h
bool promotedToLayer() const {
return mLayerProperties.mType == LayerType::None && fitsOnLayer() &&
(mComputedFields.mNeedLayerForFunctors || mLayerProperties.mImageFilter != nullptr ||
mLayerProperties.getStretchEffect().requiresLayer() ||
(!MathUtils::isZero(mPrimitiveFields.mAlpha) && mPrimitiveFields.mAlpha < 1 &&
mPrimitiveFields.mHasOverlappingRendering));
}
LayerType effectiveLayerType() const {
return CC_UNLIKELY(promotedToLayer()) ? LayerType::RenderLayer : mLayerProperties.mType;
}
// 此函数每一帧会被执行上百次,且固定值,比如我设备为16384 x 16384,所以基本为true
bool fitsOnLayer() const {
// Layoutlib does not support device info
const DeviceInfo* deviceInfo = DeviceInfo::get();
return mPrimitiveFields.mWidth <= deviceInfo->maxTextureSize() &&
mPrimitiveFields.mHeight <= deviceInfo->maxTextureSize();
}
先看比较常用的mLayerProperties.getStretchEffect().requiresLayer,调用mStretchDirection设置的地方有两个地方,RenderNode.stretch或者SurfaceControl.setStretchEffect
RenderNode.stretch在EdgeEffect.draw中调用,最终的调用者为ViewPager或者RecyclerView的draw里面实现滚动边缘效果
SurfaceControl.setStretchEffect在SurfaceView.applyStretch实现应用拉伸效果
* frameworks/base/libs/hwui/effects/StretchEffect.h
bool requiresLayer() const {
return !isEmpty();
}
bool isEmpty() const { return isZero(mStretchDirection.x()) && isZero(mStretchDirection.y()); }
* frameworks/base/core/java/android/view/SurfaceControl.java
public Transaction setStretchEffect(SurfaceControl sc, float width, float height,
float vecX, float vecY, float maxStretchAmountX,
float maxStretchAmountY, float childRelativeLeft, float childRelativeTop, float childRelativeRight,
float childRelativeBottom) {
checkPreconditions(sc);
nativeSetStretchEffect(mNativeObject, sc.mNativeObject, width, height,
vecX, vecY, maxStretchAmountX, maxStretchAmountY, childRelativeLeft, childRelativeTop,
childRelativeRight, childRelativeBottom);
return this;
}
* frameworks/base/graphics/java/android/graphics/RenderNode.java
public boolean stretch(float vecX, float vecY,
float maxStretchAmountX, float maxStretchAmountY) {
}
在看看mHasOverlappingRendering,通过调用setHasOverlappingRendering设置,调用的地方为android_graphics_RenderNode,通过View.setDisplayListProperties调用,这里会调用getHasOverlappingRendering,这里
主要调用hasOverlappingRendering函数,默认返回true
* frameworks/base/libs/hwui/jni/android_graphics_RenderNode.cpp
static jboolean android_view_RenderNode_setHasOverlappingRendering(CRITICAL_JNI_PARAMS_COMMA jlong renderNodePtr,
bool hasOverlappingRendering) {
return SET_AND_DIRTY(setHasOverlappingRendering, hasOverlappingRendering,
RenderNode::GENERIC);
}
* frameworks/base/core/java/android/view/View.java
void setDisplayListProperties(RenderNode renderNode) {
if (renderNode != null) {
renderNode.setHasOverlappingRendering(getHasOverlappingRendering());
...
}
}
public final boolean getHasOverlappingRendering() {
return (mPrivateFlags3 & PFLAG3_HAS_OVERLAPPING_RENDERING_FORCED) != 0 ?
(mPrivateFlags3 & PFLAG3_OVERLAPPING_RENDERING_FORCED_VALUE) != 0 :
hasOverlappingRendering();
}
public boolean hasOverlappingRendering() {
return true;
}
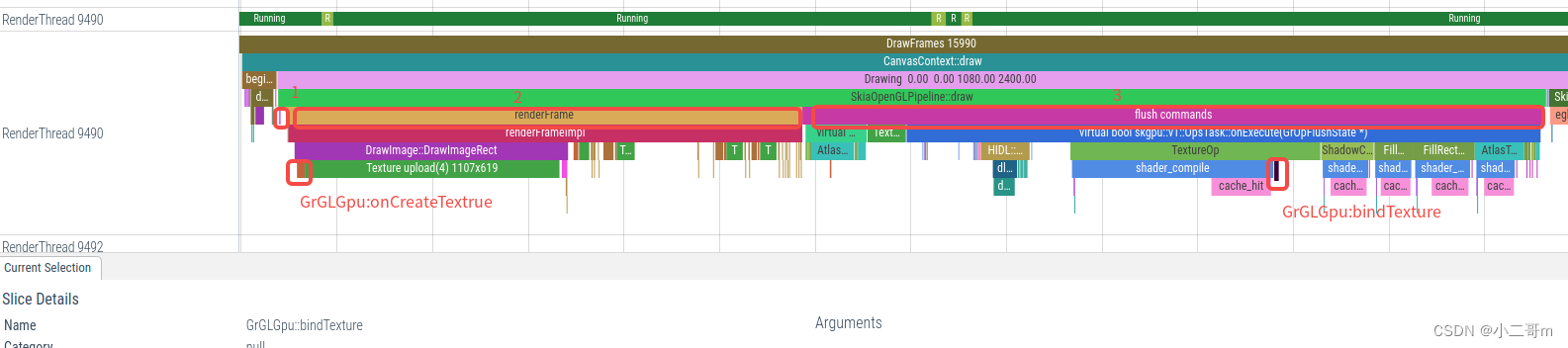
- renderFrameImpl 流程
SkiaPipeline::renderFrameImpl执行Draw流程, 先绘制背景(内容+标题)的右侧和底部区域,然后绘制内容+背景的左上区域,主要是调用RenderNodeDrawable:draw去绘制,RenderNodeDrawable继承SkDrawable,通过SkDrawable::draw调用RenderNodeDrawable::forceDraw->RenderNodeDrawable::drawContent->SkiaDisplayList::draw->DisplayListData::draw->SkCanvas::onDrawImageRect2
进入到设备的GPU绘制中:skgpu::v1::Device::drawImageRect,这里主要执行两个流程
- 调用GrGLGpu::createTexture去创建texture,创建纹理
- 创建纹理成功后,调用SurfaceDrawContext::addDrawOp,进而调用OpsTask::addDrawOp

external/skia/src/gpu/v1/Device.cpp
void Device::drawImageRect(const SkImage* image,
const SkRect* src,
const SkRect& dst,
const SkSamplingOptions& sampling,
const SkPaint& paint,
SkCanvas::SrcRectConstraint constraint) {
...
this->drawImageQuad(image, src, &dst, nullptr, aa, aaFlags, nullptr, sampling, paint,
constraint);
}
external/skia/src/gpu/v1/Device_drawTexture.cpp
void Device::drawImageQuad(const SkImage* image,
const SkRect* srcRect,
const SkRect* dstRect,
const SkPoint dstClip[4],
GrAA aa,
GrQuadAAFlags aaFlags,
const SkMatrix* preViewMatrix,
const SkSamplingOptions& origSampling,
const SkPaint& paint,
SkCanvas::SrcRectConstraint constraint) {
...
draw_image(fContext.get(),
fSurfaceDrawContext.get(),
clip,
matrixProvider,
paint,
*as_IB(image),
src,
dst,
dstClip,
srcToDst,
aa,
aaFlags,
constraint,
sampling);
return;
}
void draw_image(GrRecordingContext* rContext,
skgpu::v1::SurfaceDrawContext* sdc,
const GrClip* clip,
const SkMatrixProvider& matrixProvider,
const SkPaint& paint,
const SkImage_Base& image,
const SkRect& src,
const SkRect& dst,
const SkPoint dstClip[4],
const SkMatrix& srcToDst,
GrAA aa,
GrQuadAAFlags aaFlags,
SkCanvas::SrcRectConstraint constraint,
SkSamplingOptions sampling,
SkTileMode tm = SkTileMode::kClamp) {
...
if (tm == SkTileMode::kClamp &&
!image.isYUVA() &&
can_use_draw_texture(paint, sampling.useCubic, sampling.mipmap)) {
// We've done enough checks above to allow us to pass ClampNearest() and not check for
// scaling adjustments.
1. 调用asView创建纹理
auto [view, ct] = image.asView(rContext, GrMipmapped::kNo);
if (!view) {
return;
}
GrColorInfo info(image.imageInfo().colorInfo());
info = info.makeColorType(ct);
2. add Draw
draw_texture(sdc,
clip,
ctm,
paint,
sampling.filter,
src,
dst,
dstClip,
aa,
aaFlags,
constraint,
std::move(view),
info);
return;
}
// 下面是类似底部导航栏这种的图片绘制
1.. createTexture
std::unique_ptr<GrFragmentProcessor> fp = image.asFragmentProcessor(rContext,
sampling,
tileModes,
textureMatrix,
subset,
domain);
2.. 底部导航栏这种通过path绘制的图标,一般会走这里
if (!mf) {
// Can draw the image directly (any mask filter on the paint was converted to an FP already)
if (dstClip) {
SkPoint srcClipPoints[4];
SkPoint* srcClip = nullptr;
if (canUseTextureCoordsAsLocalCoords) {
// Calculate texture coordinates that match the dst clip
GrMapRectPoints(dst, src, dstClip, srcClipPoints, 4);
srcClip = srcClipPoints;
}
sdc->fillQuadWithEdgeAA(clip, std::move(grPaint), aa, aaFlags, ctm, dstClip, srcClip);
} else {
// Provide explicit texture coords when possible, otherwise rely on texture matrix
sdc->fillRectWithEdgeAA(clip, std::move(grPaint), aa, aaFlags, ctm, dst,
canUseTextureCoordsAsLocalCoords ? &src : nullptr);
}
}
}
void draw_texture(skgpu::v1::SurfaceDrawContext* sdc,
const GrClip* clip,
const SkMatrix& ctm,
const SkPaint& paint,
GrSamplerState::Filter filter,
const SkRect& srcRect,
const SkRect& dstRect,
const SkPoint dstClip[4],
GrAA aa,
GrQuadAAFlags aaFlags,
SkCanvas::SrcRectConstraint constraint,
GrSurfaceProxyView view,
const GrColorInfo& srcColorInfo) {
SkPMColor4f color = texture_color(paint.getColor4f(), 1.f, srcColorInfo.colorType(), dstInfo);
if (dstClip) {
// Get source coords corresponding to dstClip
SkPoint srcQuad[4];
GrMapRectPoints(dstRect, srcRect, dstClip, srcQuad, 4);
sdc->drawTextureQuad(clip,
std::move(view),
srcColorInfo.colorType(),
srcColorInfo.alphaType(),
filter,
GrSamplerState::MipmapMode::kNone,
paint.getBlendMode_or(SkBlendMode::kSrcOver),
color,
srcQuad,
dstClip,
aa,
aaFlags,
constraint == SkCanvas::kStrict_SrcRectConstraint ? &srcRect : nullptr,
ctm,
std::move(textureXform));
} else {
sdc->drawTexture(clip,
std::move(view),
srcColorInfo.alphaType(),
filter,
GrSamplerState::MipmapMode::kNone,
paint.getBlendMode_or(SkBlendMode::kSrcOver),
color,
srcRect,
dstRect,
aa,
aaFlags,
constraint,
ctm,
std::move(textureXform));
}
}
Device_drawTexture.cpp的draw_image中,主要两个操作创建纹理或者addDraw
分两种情况:
- ImageVIew这种资源图片的
- 调用SkImage_Base::asView去创建纹理
SkImage_Gpu和SkImage_Raster继承SkImage_Base,实现了onAsView,在asView->onAsView中去创建纹理,这里会调用SkImage_Raster::onAsView- 调用调用draw_texture去add draw
draw_texture中主要是调用SurfaceDrawContext::drawTexture/drawTextureQuad,进而去调用SurfaceDrawContext::addDrawOp->OpsTask::addDrawOp添加到fOpChains中
那么这里的图片资源怎么加载的呢,怎么知道要使用SkImage_Raster还是SkImage_Gpu呢?
可以看到下面的trace中,总共有两次
针对mimap里面的图片,会执行两次创建,why?
主线程在startActivity执行inflate时,回去加载资源图片,因为调用了ImageView.setImageResource,进而调用ImageView.resolveUri去执行getDrawable去加载资源,调用android.content.Context.getDrawable时,调用到ImageDecoder.decodeDrawable->ImageDecoder_nDecodeBitmap->ImageDecoder::decode,两次前面流程一样,下面分别调用
a. SkImage::MakeFromBitmap->SkImage_Raster.SkMakeImageFromRasterBitmap
b. SkCanvas::drawImage->SkCanvas::onDrawImage2->SkBitmapDevice::drawImageRect->SkDraw::drawBitmap->make_paint_with_image->SkMakeBitmapShaderForPaint->SkImage_Raster.SkMakeImageFromRasterBitmap在第一次draw的时候,调用android.view.ViewGroup.drawChild->BaseRecordingCanvas.drawBitmap->CanvasJNI::drawBitmapRect->SkiaRecordingCanvas::drawBitmap进而调用SkImage_Raster::SkMakeImageFromRasterBitmapPriv去创建SkImage_Raster对象,进而去创建纹理
那么这两次有什么区别呢

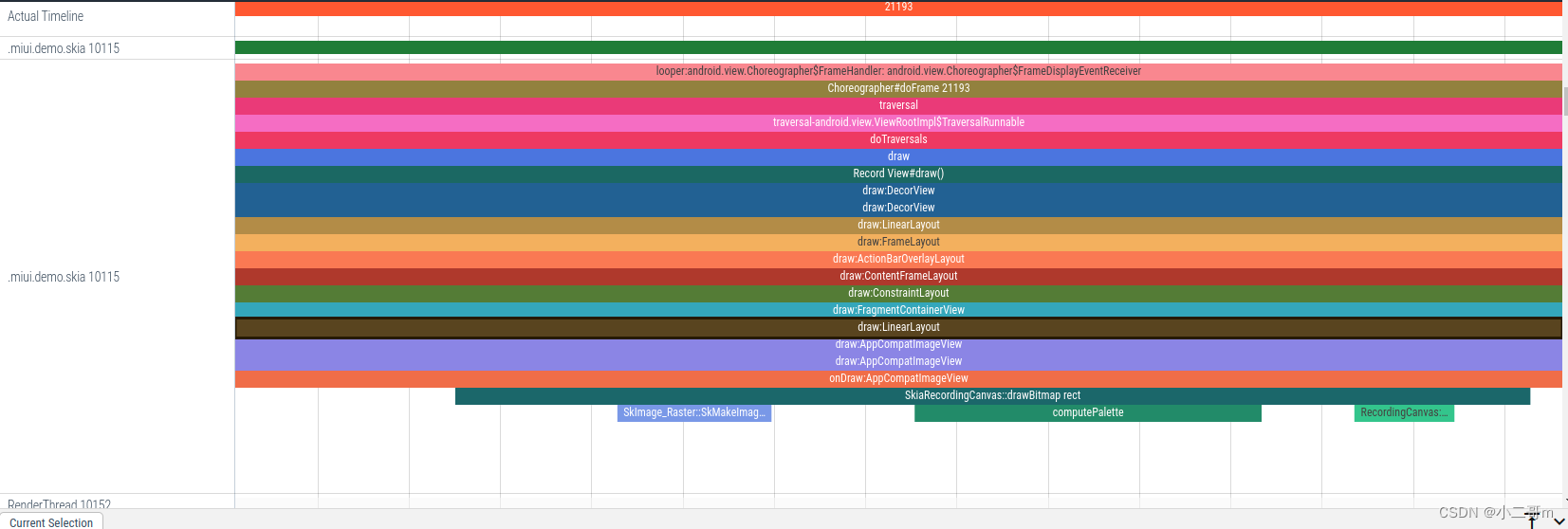
external/skia/src/image/SkImage_Raster.cpp
sk_sp<SkImage> SkMakeImageFromRasterBitmapPriv(const SkBitmap& bm, SkCopyPixelsMode cpm,
uint32_t idForCopy) {
if (kAlways_SkCopyPixelsMode == cpm || (!bm.isImmutable() && kNever_SkCopyPixelsMode != cpm)) {
SkPixmap pmap;
if (bm.peekPixels(&pmap)) {
return MakeRasterCopyPriv(pmap, idForCopy);
} else {
return sk_sp<SkImage>();
}
}
ATRACE_ANDROID_FRAMEWORK_ALWAYS("SkImage_Raster::SkMakeImageFromRasterBitmapPriv");
return sk_make_sp<SkImage_Raster>(bm, kNever_SkCopyPixelsMode == cpm);
}
- 通过path绘制图片的
- .调用SkImage_Base::asFragmentProcessor进而调用到GrGLGpu::createTexture创建纹理
- 调用fillQuadWithEdgeAA去执行draw流程
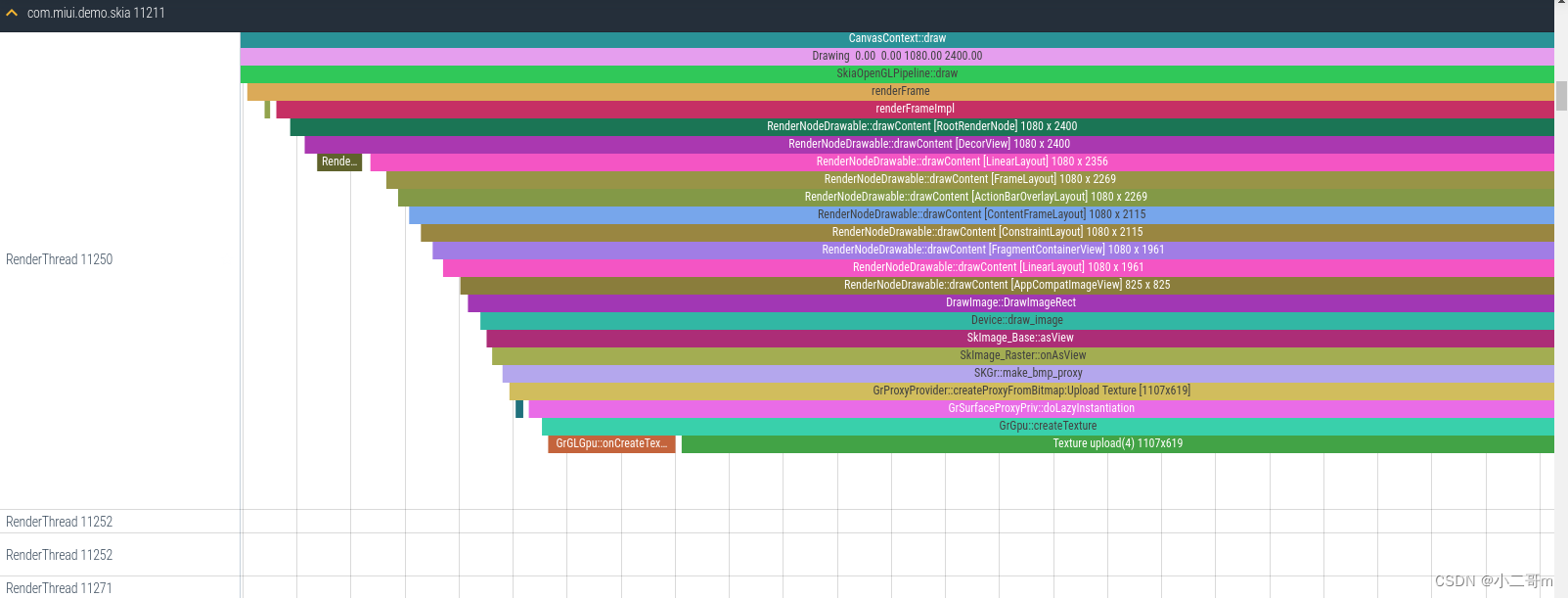
- 真正的纹理创建流程
SkImage_Raster::onAsView调用到SkGr::GrMakeCachedBitmapProxyView,然后调用make_bmp_proxy先创建Bitmap,这里调用GrProxyProvider::createProxyFromBitmap->createNonMippedProxyFromBitmap,这里主要调用GrSurfaceProxyPriv::doLazyInstantiation,调用GrProxyProvider::createNonMippedProxyFromBitmap后,调用GrResourceProvider::createTexture,这里主要执行两个流程
- 调用GrGpu::createTextureCommon->GrGLGpu::onCreateTexture->GrGLGpu::createTexture创建纹理
- 调用GrGpu::createTexture->GrGpu::writePixels执行 Texture upload流程
external/skia/src/image/SkImage_Raster.cpp
#if SK_SUPPORT_GPU
std::tuple<GrSurfaceProxyView, GrColorType> SkImage_Raster::onAsView(
GrRecordingContext* rContext,
GrMipmapped mipmapped,
GrImageTexGenPolicy policy) const {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("SkImage_Raster::onAsView");
...
if (policy == GrImageTexGenPolicy::kDraw) {
return GrMakeCachedBitmapProxyView(rContext, fBitmap, mipmapped);
}
...
}
* external/skia/src/gpu/SkGr.cpp
std::tuple<GrSurfaceProxyView, GrColorType>
GrMakeCachedBitmapProxyView(GrRecordingContext* rContext,
const SkBitmap& bitmap,
GrMipmapped mipmapped) {
...
skgpu::UniqueKey key;
SkIPoint origin = bitmap.pixelRefOrigin();
SkIRect subset = SkIRect::MakePtSize(origin, bitmap.dimensions());
// 根据id和图片的尺寸等信息,生成key
GrMakeKeyFromImageID(&key, bitmap.pixelRef()->getGenerationID(), subset);
mipmapped = adjust_mipmapped(mipmapped, bitmap, caps);
GrColorType ct = choose_bmp_texture_colortype(caps, bitmap);
// 创建bitmap后,会回调installKey,调用assignUniqueKeyToProxy去存储
auto installKey = [&](GrTextureProxy* proxy) {
auto listener = GrMakeUniqueKeyInvalidationListener(&key, proxyProvider->contextID());
bitmap.pixelRef()->addGenIDChangeListener(std::move(listener));
proxyProvider->assignUniqueKeyToProxy(key, proxy);
};
sk_sp<GrTextureProxy> proxy = proxyProvider->findOrCreateProxyByUniqueKey(key);
if (!proxy) {
// 第一次执行make
proxy = make_bmp_proxy(proxyProvider,
bitmap,
ct,
mipmapped,
SkBackingFit::kExact,
SkBudgeted::kYes);
if (!proxy) {
return {};
}
SkASSERT(mipmapped == GrMipmapped::kNo || proxy->mipmapped() == GrMipmapped::kYes);
installKey(proxy.get());
}
// 绘制
skgpu::Swizzle swizzle = caps->getReadSwizzle(proxy->backendFormat(), ct);
if (mipmapped == GrMipmapped::kNo || proxy->mipmapped() == GrMipmapped::kYes) {
return {{std::move(proxy), kTopLeft_GrSurfaceOrigin, swizzle}, ct};
}
}
* external/skia/src/gpu/GrProxyProvider.cpp
sk_sp<GrTextureProxy> GrProxyProvider::createProxyFromBitmap(const SkBitmap& bitmap,
GrMipmapped mipMapped,
SkBackingFit fit,
SkBudgeted budgeted) {
...
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrProxyProvider::createProxyFromBitmap:Upload %sTexture [%ux%u]",
GrMipmapped::kYes == mipMapped ? "MipMap " : "",
bitmap.width(), bitmap.height());
...
sk_sp<GrTextureProxy> proxy;
if (mipMapped == GrMipmapped::kNo ||
0 == SkMipmap::ComputeLevelCount(copyBitmap.width(), copyBitmap.height())) {
// 这里调用createNonMippedProxyFromBitmap,即创建GrTextureProxy
proxy = this->createNonMippedProxyFromBitmap(copyBitmap, fit, budgeted);
} else {
proxy = this->createMippedProxyFromBitmap(copyBitmap, budgeted);
}
if (!proxy) {
return nullptr;
}
auto direct = fImageContext->asDirectContext();
if (direct) {
GrResourceProvider* resourceProvider = direct->priv().resourceProvider();
// priv直接返回GrTextureProxy,去创建对应对象的实例,执行纹理创建
if (!proxy->priv().doLazyInstantiation(resourceProvider)) {
return nullptr;
}
}
return proxy;
}
sk_sp<GrTextureProxy> GrProxyProvider::createNonMippedProxyFromBitmap(const SkBitmap& bitmap,
SkBackingFit fit,
SkBudgeted budgeted) {
auto dims = bitmap.dimensions();
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrProxyProvider::createNonMippedProxyFromBitmap");
...
// 这里在创建时候,回调GrTextureProxy::createTexture
sk_sp<GrTextureProxy> proxy = this->createLazyProxy(
[bitmap](GrResourceProvider* resourceProvider, const LazySurfaceDesc& desc) {
SkASSERT(desc.fMipmapped == GrMipmapped::kNo);
GrMipLevel mipLevel = {bitmap.getPixels(), bitmap.rowBytes(), nullptr};
auto colorType = SkColorTypeToGrColorType(bitmap.colorType());
return LazyCallbackResult(resourceProvider->createTexture(
desc.fDimensions,
desc.fFormat,
desc.fTextureType,
colorType,
desc.fRenderable,
desc.fSampleCnt,
desc.fBudgeted,
desc.fFit,
desc.fProtected,
mipLevel));
},
format, dims, GrMipmapped::kNo, GrMipmapStatus::kNotAllocated,
GrInternalSurfaceFlags::kNone, fit, budgeted, GrProtected::kNo, UseAllocator::kYes);
...
return proxy;
}
* external/skia/src/gpu/GrSurfaceProxyPriv.h
inline GrSurfaceProxyPriv GrSurfaceProxy::priv() { return GrSurfaceProxyPriv(this); }
* external/skia/src/gpu/GrGpu.cpp
sk_sp<GrTexture> GrGpu::createTexture(SkISize dimensions,
const GrBackendFormat& format,
GrTextureType textureType,
GrRenderable renderable,
int renderTargetSampleCnt,
SkBudgeted budgeted,
GrProtected isProtected,
GrColorType textureColorType,
GrColorType srcColorType,
const GrMipLevel texels[],
int texelLevelCount) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGpu::createTexture");
...
auto tex = this->createTextureCommon(dimensions,
format,
textureType,
renderable,
renderTargetSampleCnt,
budgeted,
isProtected,
texelLevelCount,
levelClearMask);
...
if (!this->writePixels(tex.get(),
SkIRect::MakeSize(dimensions),
textureColorType,
srcColorType,
texels,
texelLevelCount)) {
return nullptr;
}
...
return tex;
}
bool GrGpu::writePixels(GrSurface* surface,
SkIRect rect,
GrColorType surfaceColorType,
GrColorType srcColorType,
const GrMipLevel texels[],
int mipLevelCount,
bool prepForTexSampling) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGpu::writePixels Texture upload(%u) %ix%i",
surface->uniqueID().asUInt(), rect.width(), rect.height());
...
if (this->onWritePixels(surface,
rect,
surfaceColorType,
srcColorType,
texels,
mipLevelCount,
prepForTexSampling)) {
this->didWriteToSurface(surface, kTopLeft_GrSurfaceOrigin, &rect, mipLevelCount);
fStats.incTextureUploads();
return true;
}
return false;
}
* external/skia/src/gpu/gl/GrGLGpu.cpp
GrGLuint GrGLGpu::createTexture(SkISize dimensions,
GrGLFormat format,
GrGLenum target,
GrRenderable renderable,
GrGLTextureParameters::SamplerOverriddenState* initialState,
int mipLevelCount,
GrProtected isProtected) {
...
GrGLuint id = 0;
// 产生一个纹理Id
GL_CALL(GenTextures(1, &id));
...
// 调用GLBindTexture,使用这个纹理id,或者叫绑定(关联)
this->bindTextureToScratchUnit(target, id);
...
bool success = false;
if (internalFormat) {
if (this->glCaps().formatSupportsTexStorage(format)) {
...
} else {
GrGLenum externalFormat, externalType;
this->glCaps().getTexImageExternalFormatAndType(format, &externalFormat, &externalType);
GrGLenum error = GR_GL_NO_ERROR;
if (externalFormat && externalType) {
for (int level = 0; level < mipLevelCount && error == GR_GL_NO_ERROR; level++) {
const int twoToTheMipLevel = 1 << level;
const int currentWidth = std::max(1, dimensions.width() / twoToTheMipLevel);
const int currentHeight = std::max(1, dimensions.height() / twoToTheMipLevel);
// 指定二维纹理图像
error = GL_ALLOC_CALL(TexImage2D(target, level, internalFormat, currentWidth,
currentHeight, 0, externalFormat, externalType,
nullptr));
}
success = (error == GR_GL_NO_ERROR);
}
}
}
if (success) {
return id;
}
GL_CALL(DeleteTextures(1, &id));
return 0;
}
bool GrGLGpu::onWritePixels(GrSurface* surface,
SkIRect rect,
GrColorType surfaceColorType,
GrColorType srcColorType,
const GrMipLevel texels[],
int mipLevelCount,
bool prepForTexSampling) {
...
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGLGpu::onWritePixels (%u) %ix%i",
surface->uniqueID().asUInt(), rect.width(), rect.height());
// If we have mips make sure the base/max levels cover the full range so that the uploads go to
// the right levels. We've found some Radeons require this.
if (mipLevelCount && this->glCaps().mipmapLevelControlSupport()) {
auto params = glTex->parameters();
GrGLTextureParameters::NonsamplerState nonsamplerState = params->nonsamplerState();
int maxLevel = glTex->maxMipmapLevel();
if (params->nonsamplerState().fBaseMipMapLevel != 0) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGLGpu::onWritePixels TexParameteri base ");
GL_CALL(TexParameteri(glTex->target(), GR_GL_TEXTURE_BASE_LEVEL, 0));
nonsamplerState.fBaseMipMapLevel = 0;
}
if (params->nonsamplerState().fMaxMipmapLevel != maxLevel) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGLGpu::onWritePixels TexParameteri max ");
GL_CALL(TexParameteri(glTex->target(), GR_GL_TEXTURE_MAX_LEVEL, maxLevel));
nonsamplerState.fBaseMipMapLevel = maxLevel;
}
params->set(nullptr, nonsamplerState, fResetTimestampForTextureParameters);
}
...
return this->uploadColorTypeTexData(glTex->format(),
surfaceColorType,
glTex->dimensions(),
glTex->target(),
rect,
srcColorType,
texels,
mipLevelCount);
}
void GrGLGpu::uploadTexData(SkISize texDims,
GrGLenum target,
SkIRect dstRect,
GrGLenum externalFormat,
GrGLenum externalType,
size_t bpp,
const GrMipLevel texels[],
int mipLevelCount) {
...
const GrGLCaps& caps = this->glCaps();
bool restoreGLRowLength = false;
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGLGpu::uploadTexData");
this->unbindXferBuffer(GrGpuBufferType::kXferCpuToGpu);
// 指定内存中每个像素行开始的对齐要求。 允许的值为 1 (字节对齐) 、2 (行与偶数字节对齐) 、4 (字对齐) ,8 (行从双字边界开始) 。
GL_CALL(PixelStorei(GR_GL_UNPACK_ALIGNMENT, 1));
SkISize dims = dstRect.size();
for (int level = 0; level < mipLevelCount; ++level, dims = {std::max(dims.width() >> 1, 1),
std::max(dims.height() >> 1, 1)}) {
if (!texels[level].fPixels) {
continue;
}
const size_t trimRowBytes = dims.width() * bpp;
const size_t rowBytes = texels[level].fRowBytes;
if (caps.writePixelsRowBytesSupport() && (rowBytes != trimRowBytes || restoreGLRowLength)) {
GrGLint rowLength = static_cast<GrGLint>(rowBytes / bpp);
GL_CALL(PixelStorei(GR_GL_UNPACK_ROW_LENGTH, rowLength));
restoreGLRowLength = true;
} else {
SkASSERT(rowBytes == trimRowBytes);
}
GL_CALL(TexSubImage2D(target, level, dstRect.x(), dstRect.y(), dims.width(), dims.height(),
externalFormat, externalType, texels[level].fPixels));
}
if (restoreGLRowLength) {
SkASSERT(caps.writePixelsRowBytesSupport());
GL_CALL(PixelStorei(GR_GL_UNPACK_ROW_LENGTH, 0));
}
}
创建纹理
- 调用GenTextures,产生一个纹理Id,可以认为是纹理句柄,后面的操作将书用这个纹理id
- 调用glBindTexture,使用这个纹理id,或者叫绑定(关联)
- 调用glTexImage2D,指定二维纹理图像
设置纹理参数
onWritePixels中,首先调用 GL_CALL(TexParameteri(glTex->target(), GR_GL_TEXTURE_MAX_LEVEL, maxLevel))设置mipmaps的层级,然后调用GrGLGpu::uploadColorTypeTexData->GrGLGpu::uploadTexData->TexSubImage2D
这里最终调用glTexSubImage2D去加载纹理

创建纹理demo
virtual unsigned loadTexture(const char* fileName)
{
unsigned textureId = 0;
//1 获取图片格式
FREE_IMAGE_FORMAT fifmt = FreeImage_GetFileType(fileName, 0);
//2 加载图片
FIBITMAP *dib = FreeImage_Load(fifmt, fileName,0);
//3 转化为rgb 24色
dib = FreeImage_ConvertTo24Bits(dib);
//4 获取数据指针
BYTE *pixels = (BYTE*)FreeImage_GetBits(dib);
int width = FreeImage_GetWidth(dib);
int height = FreeImage_GetHeight(dib);
//windows是BGR模式
for (int i =0;i<width*height*3;)
{
float temp = pixels[i+2];
pixels[i + 2] = pixels[i];
pixels[i] = temp;
i += 3;
}
/**
* 产生一个纹理Id,可以认为是纹理句柄,后面的操作将书用这个纹理id
*/
glGenTextures( 1, &textureId );
/**
* 使用这个纹理id,或者叫绑定(关联)
*/
glBindTexture( GL_TEXTURE_2D, textureId );
/**
* 指定纹理的放大,缩小滤波,使用线性方式,即当图片放大的时候插值方式
*/
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_MAG_FILTER,GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D,GL_TEXTURE_MIN_FILTER,GL_LINEAR);
/**
* 将图片的rgb数据上传给opengl.
*/
glTexImage2D(
GL_TEXTURE_2D, //! 指定是二维图片
0, //! 指定为第一级别,纹理可以做mipmap,即lod,离近的就采用级别大的,远则使用较小的纹理
GL_RGB, //! 纹理的使用的存储格式
width, //! 宽度,老一点的显卡,不支持不规则的纹理,即宽度和高度不是2^n。
height, //! 宽度,老一点的显卡,不支持不规则的纹理,即宽度和高度不是2^n。
0, //! 是否的边
GL_RGB, //! 数据的格式,bmp中,windows,操作系统中存储的数据是bgr格式
GL_UNSIGNED_BYTE, //! 数据是8bit数据
pixels
);
char subData[100 * 100 * 3];
memset(subData, 255, sizeof(subData));
for (int i = 0; i<150;)
{
subData[i] = 0;
subData[++i] = 0;
subData[++i] = 255;
}
glTexSubImage2D(GL_TEXTURE_2D, 0, 100, 50, 100, 100, GL_RGB, GL_UNSIGNED_BYTE, subData);
/**
* 释放内存
*/
FreeImage_Unload(dib);
return textureId;
}
相关OpenGL介绍
OPENGL 设置纹理参数glTextureParameter
void glTexParameter*(GLenum target, GLenum pname, GLint param);
OpenGL中设置纹理参数的API接口为glTextureParameter,我们所有的纹理参数都由这个接口设置,下面我们介绍几种常用的纹理参数的配置。
- 采样:Wrapping
纹理坐标的范围与OpenGL的屏幕坐标范围一样,是0-1。超出这一范围的坐标将被OpenGL根据GL_TEXTURE_WRAP参数的值进行处理:
GL_REPEAT: 超出纹理范围的坐标整数部分被忽略,形成重复效果。
GL_MIRRORED_REPEAT: 超出纹理范围的坐标整数部分被忽略,但当整数部分为奇数时进行取反,形成镜像效果。
GL_CLAMP_TO_EDGE:超出纹理范围的坐标被截取成0和1,形成纹理边缘延伸的效果。
GL_CLAMP_TO_BORDER: 超出纹理范围的部分被设置为边缘色。
- 过滤
由于纹理坐标和我们当前的屏幕分辨率是无关的,所以当我们为一个模型贴纹理时,往往会遇到纹理尺寸与模型尺寸不符的情况,这时,纹理会因为缩放而失真。处理这一失真的过程我们称为过滤,在OpenGL中我们有如下几种常用的过滤手段:
GL_NEAREST: 最临近过滤,获得最靠近纹理坐标点的像素。
GL_LINEAR: 线性插值过滤,获取坐标点附近4个像素的加权平均值。
GL_NEAREST_MIPMAP_NEAREST:用于mipmap,下节将详细介绍。
GL_LINEAR_MIPMAP_NEAREST:
GL_NEAREST_MIPMAP_LINEAR:
GL_LINEAR_MIPMAP_LINEAR:
我们可以单独为纹理缩放指定不同的过滤算法,这两种情况下纹理参数设置分别对应为:GL_TEXTURE_MIN_FILTER和GL_TEXTURE_MAG_FILTER.
- 纹理映射 Mipmaps
Mipmaps是一个功能强大的纹理技术,它可以提高渲染的性能以及提升场景的视觉质量。它可以用来解决使用一般的纹理贴图会出现的两个常见的问题:
1.闪烁,当屏幕上被渲染区域与它所应用的纹理图像相比显得非常小时,就会出现闪烁。尤其当视口和物体在移动的时候,这种负面效果更容易被看到。
2.性能问题。如果我们的贴纹理的区域离我们非常远,远到在屏幕中只有一个像素那么大小时,纹理的所有纹素都集中在这一像素中。这时,我们无论做邻近过滤还是做线性过滤时都不得不将纹理的所有纹素计算在内,这种计算效率将大大影响我们的采样效率,而纹理的数据量越大,对效率的影响就会更大。
使用Mipmaps技术就可以解决上面那两个问题。当加载纹理的同时预处理生成一系列从大到小的纹理,使用时只需选择合适大小的纹理加载就行了。这样虽然会增加一些额外的内存(一个正方形纹理将额外占用约30%的内存),但将大大提高了我们的采样效率和采样质量。
生成mipmaps的过程很简单,只需要在加载纹理后执行下面一行代码:
使用mipmaps也很简单,只需设置过滤参数为以下4种中的任意一种:
GL_NEAREST_MIPMAP_NEAREST:选择最邻近的mip层,并使用最邻近过滤。
GL_NEAREST_MIPMAP_LINEAR:对两个mip层使用最邻近过滤后的采样结果进行加权平均。
GL_LINEAR_MIPMAP_NEAREST:选择最邻近的mip层,使用线性插值算法进行过滤。
GL_LINEAR_MIPMAP_LINEAR:对两个mip层使用线性插值过滤后的采样结果进行加权平均,又称三线性mipmap。
在选择这几种过滤方法时,我们需要考虑的是效率和质量,线性过滤往往更加平滑,但随之而来的是更多的采样次数;而临近过滤减少了采样次数,但最终视觉效果会比较差。- mipmaps的层级
mipmap有多少个层级是有glTexImage1D、glTexImage2D载入纹理的第二个参数level决定的。 层级从0开始,0,1,2,3这样递增,如果没有使用mipmap技术,只有第0层的纹理会被加载,OpenGL会根据给定的几何图像的大小选择最合适的纹理。
在默认情况下, 为了使用mipmap,所有层级都会被加载,但是我们可以用纹理参数来控制要加载的层级范围:
使用glTexParameteri, 设定纹理参数。
参数为GL_TEXTURE_BASE_LEVEL来指定最低层级的level
参数为GL_TEXTURE_MAX_LEVEL来指定最高层级的level




OPENGL 对齐像素字节glPixelStorei
从本地内存向GPU的传输(UNPACK),包括各种glTexImage、glDrawPixel;从GPU到本地内存的传输(PACK),包括glGetTexImage、glReadPixel等
官方介绍,参考文档:glPixelStorei 函数
- GL_UNPACK_ALIGNMENT
glPixelStorei(GL_UNPACK_ALIGNMENT,1)控制的是所读取数据的按照字节对齐方式对齐,默认4字节对齐,即一行的图像数据字节数必须是4的整数倍,即读取数据时,读取4个字节用来渲染一行,之后读取4字节数据用来渲染第二行。对RGB 3字节像素而言,若一行10个像素,即30个字节,在4字节对齐模式下,OpenGL会读取32个字节的数据,若不加注意,会导致glTextImage中致函数的读取越界,从而全面崩溃。
- GL_UNPACK_ROW_LENGTH/GL_UNPACK_SKIP_ROWS /GL_UNPACK_SKIP_PIXELS
有的时候,我们把一些小图片拼凑进一张大图片内,这样使用大图片生成的纹理,一来可以使多个原本使用不同的图片作为纹理的同质物件如今能够在同一个Batch内,节省了一些状态切换的开销,二来也容易综合地降低了显存中纹理的总大小。但是,也有些时候,我们需要从原本一张大的图片中,截取图片当中的某一部分作为纹理。要能够做到这样,可以通过预先对图片进行裁剪或者在获得像素数据后,把其中需要的那一部分另外存储到一个Buffer内再交给glTexImage2D之类的函数。而上述这些参数下glPixelStore的使用将帮助我们更好地完成这个目的:
//原图中需要单独提取出来制成纹理的区域
RECT subRect = {{100, 80}, {500, 400}}; //origin.x, origin.y, size.width, size.height
//假设原图的宽度为BaseWidth, 高度为BaseHeight
glPixelStorei(GL_UNPACK_ROW_LENGTH, BaseWidth); //指定像素数据中原图的宽度
glPixelStorei(GL_UNPACK_SKIP_ROWS, subRect. origin.y.); //指定纹理起点偏离原点的高度值
glPixelStorei(GL_UNPACK_SKIP_PIXELS, subRect. origin.x); //指定纹理起点偏离原点的宽度值
生成纹理名称 glGenTextures
void glGenTextures(GLsizei n, GLuint * textures);
texture object也有同样的五大API,分别是glGenTextures、glBindTexture、glTexImage2D、glTexSubImage2D和glDeleteTexture。比如glGenBuffers这个API,就是用于先创建texture object的name,然后在glBindTexture的时候再创建一个texture object
这个函数的第一个输入参数的意思是该API会生成n个texture object name,当n小于0的时候,出现INVALID_VALUE的错误。第二个输入参数用于保存被创建的texture object name。这些texture object name其实也就是一些数字,而且假如一次性生成多个texture object name,那么它们没有必要必须是连续的数字。texture object name是uint类型,而且0已经被预留了,所以肯定是一个大于0的整数。
这个函数没有输出参数。当创建成功的时候,会在第二个参数textures中生成n个之前没有使用过的texture objects的name。然后这些name会被标记为已使用,而这个标记只对glGenTextures这个API有效,也就是再通过这个API生成更多的texture object name的时候,不会使用之前创建的这些texture objects name。这一步其实只是创建了一些texture object name,而没有真正的创建texture object,所以也不知道这些创建的texture的维度类型等信息,比如我可以先说在OpenGL ES2.0中texture可以分为2D和cubemap的,在OpenGL ES3.0还会有3D和2D_ARRAY的texture,这些就是texture的维度类型。而只有在这些texture object name被glBindTexture进行bind之后,才会真正的创建对应的texture object,texture才有了维度类型。
创建绑定纹理 glBindTexture
void glBindTexture(GLenum target, GLuint texture);
glGenTextures我们只创建了一些texture object的name,然后在glBindTexture这个API再创建一个texture object
这个函数的第一个输入参数的意思是指定texture object的类型,就好像buffer object分为VBO和IBO一样。texture object也是分类型的,刚才我们已经说了纹理的维度类型,在OpenGL ES2.0中,分为2D texture和CUBEMAP texture 两种。2D texture比较容易理解,就是一张2D的纹理图片,CUBEMAP的texture顾名思义,是用于组成Cube的texture,我们知道cube是立方体的意思,那么立方体有6个面,所以CUBEMAP texture是由6张2D texture组成的。那么在这里,第一个输入参数必须是GL_TEXTURE_2D或者GL_TEXTURE_CUBE_MAP。其中GL_TEXTURE_2D对应的是2D texture,GL_TEXTURE_CUBE_MAP对应的是cubemap texture。如果传入其他的参数,就会报INVALID_ENUM的错误。第二个输入参数为刚才glGenTextures得到的texture object name。
这个函数没有输出参数,假如传入的texture是刚被创建的texture object name,那么它还没有被创建和关联一个texture object,那么通过这个API,就会生成一个指定类型的texture object,且与这个texture object name关联在一起。之后指定某个texture object name的时候,也就相当于指定这个texture object。texture object是一个容器,它持有该纹理被使用时所需要用到的所有数据,这些数据包括图像像素数据、filter模式、wrapmode等,这些数据我们一会再说。而且新创建的texture object,不管是2D texture还是cubemap texture,它们的状态都是根据维度类型,GL所初始化好的默认值,这个texture object的维度类型将在其生命周期中保持不变,一直到该texture被删除。创建和关联完毕之后,就会把这个texture object当作是当前GPU所使用的2D texture或者cubemap texture
切换纹理 glActiveTexture
void glActiveTexture(GLenum texture);
GPU中同一时间一个thread的一个context中只能有一个纹理单元是处于被使用状态,所以想要将所有纹理单元中都放入texture,就需要不停的切换active texture。那么glActiveTexture这个API,就是用于将某个指定的纹理单元设置为被使用状态。
这个函数的输入参数的意思是指定某个纹理单元被使用。GPU中最多可以有8个纹理单元,但是每个GPU又都不同,所以可以通过glGet这个API,传入GL_MAX_COMBINED_TEXTURE_IMAGE_UNITS这个参数来获取到当前GPU最多可以有多少个纹理,GL_MAX_COMBINED_TEXTURE_IMAGE_UNITS不能超过8。所以第一个输入参数只能是GL_TEXTUREi,其中i从0一直到GL_MAX_COMBINED_TEXTURE_IMAGE_UNITS -1。初始状态下,GL_TEXTURE0是被active的。如果这里传入的值并非GL_TEXTUREi,i从0到GL_MAX_COMBINED_TEXTURE_IMAGE_UNITS -1。那么就会出现GL_INVALID_ENUM的错
OPENGL 指定二维纹理图像 glTexImage2D
void glTexImage2D(GLenum target, GLint level, GLint internalformat, GLsizei width, GLsizei height, GLint border, GLenum format, GLenum type, const GLvoid * data);
创建了texture object之后,就需要给这个texture object赋予数据了,而glTexImage2D这个API就是通过OpenGL ES,把我们刚才准备好的数据,从CPU端保存的数据传递给GPU端,保存在指定的texture object中
第一个输入参数的意思是指定texture object的类型,可以是GL_TEXTURE_2D,又或者是cubemap texture6面中的其中一面,通过GL_TEXTURE_CUBE_MAP_POSITIVE_X, GL_TEXTURE_CUBE_MAP_NEGATIVE_X, GL_TEXTURE_CUBE_MAP_POSITIVE_Y, GL_TEXTURE_CUBE_MAP_NEGATIVE_Y, GL_TEXTURE_CUBE_MAP_POSITIVE_Z, or GL_TEXTURE_CUBE_MAP_NEGATIVE_Z来指定,我们说了cubemap的texture其实也就是由6个2D texture组成的,所以这个函数实际上是用于给一张2D texture赋值
第二个是指给该texture的第几层赋值。详细级别编号。 级别 0 是基础映像级别。 级别 n 是第 n 个 mipmap 缩减图像。没有mipmap的texture,就相当于只有一层mipmap,而有mipmap的texture就好比一层一层塔一样,每一层都需要赋值。所以在这里需要确认我们是给纹理的第几层赋值,绝大多数情况是给第一层赋值,因为即使纹理需要mipmap,我们也经常会使用glGenerateMipmap这个API去生成mipmap信息,而不直接赋值。level 0就是第一层mipmap,也就是图像的基本层。如果level小于0,则会出现GL_INVALID_VALUE的错误。而且level也不能太大,因为texture是由最大尺寸限制的,而第一层mipmap就是纹理的原始尺寸,而第二层mipmap的尺寸为原始宽高各除以2,依次类推,最后一层mipmap的尺寸为宽高均为1。
第三个参数internalformat,第七个参数format和第八个参数type我们放在一起来说,就是指定原始数据在从CPU传入GPU之前,在CPU中的格式信息,以及传入GPU之后,在GPU中的格式。internalformat,是用于指定纹理在GPU端的格式,只能是GL_ALPHA, GL_LUMINANCE, GL_LUMINANCE_ALPHA, GL_RGB, GL_RGBA。GL_ALPHA指的是每个像素点只有alpha通道,相当于RGB通道全为0。GL_LUMINANCE指的是每个像素点只有一个luminance值,相当于RGB的值全为luminance的值,alpha为1。GL_LUMINANCE_ALPHA指的是每个像素点有一个luminance值和一个alpha值,相当于RGB的值全为luminance的值,alpha值保持不变。GL_RGB指的是每个像素点有一个red、一个green值和一个blue值,相当于RGB的值保持不变,alpha为1。GL_RGBA指的是每个像素点有一个red、一个green值、一个blue值和一个alpha值,相当于RGBA的值都保持不变。如果internalformat是其他值,则会出现GL_INVALID_VALUE的错误。第七个参数format和第八个参数type,用于指定将会生成的纹理在所需要的信息在CPU中的存储格式,其中format指定通道信息,只能是GL_ALPHA, GL_RGB, GL_RGBA, GL_LUMINANCE, and GL_LUMINANCE_ALPHA。type指的每个通道的位数以及按照什么方式保存,到时候读取数据的时候是以byte还是以short来进行读取。只能是GL_UNSIGNED_BYTE, GL_UNSIGNED_SHORT_5_6_5, GL_UNSIGNED_SHORT_4_4_4_4, and GL_UNSIGNED_SHORT_5_5_5_1。当type为GL_UNSIGNED_BYTE的时候,每一个byte都保存的是一个颜色通道中的值,当type为GL_UNSIGNED_SHORT_5_6_5, GL_UNSIGNED_SHORT_4_4_4_4, and GL_UNSIGNED_SHORT_5_5_5_1的时候,每个short值中将包含了一个像素点的所有颜色信息,也就是包含了所有的颜色通道的值。从CPU往GPU传输数据生成纹理的时候,会将这些格式的信息转成float值,方法是比如byte,那么就把值除以255,比如GL_UNSIGNED_SHORT_5_6_5,就把red和blue值除以31,green值除以63,然后再全部clamp到闭区间[0,1],设计这种type使得绿色更加精确,是因为人类的视觉系统对绿色更敏感。而type为GL_UNSIGNED_SHORT_5_5_5_1使得只有1位存储透明信息,使得每个像素要么透明要么不透明,这种格式比较适合字体,这样可以使得颜色通道有更高的精度。如果format和type不是这些值,那么就会出现GL_INVALID_ENUM的错误。
第四个参数width和第五个参数height就是原始图片的宽和高,也是新生成纹理的宽和高
第6个参数border,代表着纹理是否有边线,在这里必须写成0,也就是没有边线,如果写成其他值,则会出现GL_INVALID_VALUE的错误
最后一个参数data是CPU中一块指向保存实际数据的内存。如果data不为null,那么将会有width*height个像素的data从CPU端的data location开始读取,然后会被从CPU端传输并且更新格式保存到GPU端的texture object中。当然,从CPU读取数据的时候要遵守刚才glPixelStorei设置的对齐规则。其中第一个数据对应的是纹理中左下角那个顶点。然后第二个数据对应的是纹理最下面一行左边第二个点,依次类推,按照从左到右的顺序,然后一行完毕,从下往上再赋值下一行的顺序,一直到最后一个数据对应纹理中右上角那个顶点。如果data为null,那么执行完这个API之后,依然会给texture object分配可以保存width*height那么多像素信息的内存,但是没有对这块内存进行初始化,如果使用这个texture去绘制到图片上,那么绘制出来的颜色值为undefine。可以通过glTexSubImage2D给这块没有初始化的内存赋值。
总结一下,这个命令的输入为CPU内存中以某种方式保存的像素数据,转变成闭区间[0,1]的浮点型RGBA像素值,保存在GPU中的texture object内
一旦该命令被执行,会立即将图像像素数据从CPU传输到GPU的内存中,后续对客户端数据的修改不会影响服务器中的texture object相关信息。所以在这个API执行之后,客户端中的图像数据就可以被删掉了。
如果一个texture object中已经包含有内容了,那么依然可以使用glTexImage2D对这个texture object中的内容进行替换。
OPENGL 指定现有一维纹理图像的一部分 glTexSubImage2D
void glTexSubImage2D(GLenum target, GLint level, GLint xoffset, GLint yoffset, GLsizei width, GLsizei height, GLenum format, GLenum type, const GLvoid * data);
glTexSubImage2D 函数指定现有一维纹理图像的一部分。 不能使用 glTexSubImage2D 定义新纹理。顾名思义,glTexImage2D是给texture object传入数据,这个glTexSubImage2D是给texture object的一部分传入数据。这个命令不会改变texture object的internalformat、width、height、参数以及指定部分之外的内容
这个函数的第一个和第二个输入参数和glTexImage2D的一样,用于指定texture object的类型,以及该给texture的第几层mipmap赋值
第三个、第四个、第五个和第六个输入参数的意思是:以texture object的开始为起点,宽度进行xoffset个位置的偏移,高度进行yoffset个位置的偏移,从这个位置开始,宽度为width个单位高度为height的这么一块空间,使用data指向的一块CPU中的内存数据,这块内存数据的format和type为第七和第八个参数,将这块内存数据根据这块texture的internalformat进行转换,转换好了之后,对这块空间进行覆盖
生成mipmap glGenerateMipmap
void glGenerateMipmap(GLenum target);
Mipmap又称多级纹理,每个纹理都可以有mipmap,也都可以没有mipmap。这个概念我们在上面有接触过,当时我们说了有mipmap的texture就好比一层一层塔一样,每一层都需要赋值。纹理texture object就是GPU中一块内存,这块内存中保存着一定宽高的颜色信息以及其他属性信息。而一个texture object中可以包含不止一块内存,mipmap的texture object就包含着多级内存的。比如,我们创建的texture object的宽和高为3232,那么我们知道,当纹理被准备好的时候,会拥有一块可以存放3232个像素点颜色信息的内存。如果我们通过命令使得texture object包含多级内存,第一级内存就是刚才那块保存了3232个像素点颜色信息的内存,而第二级内存就是保存了1616个像素点颜色信息的内存,依次类推,每降低以及,宽和高都将缩小一倍,一直到第六级内存就是保存了11个像素点颜色信息的内存。也就是说,宽高为3232的纹理,如果生成多级纹理,就会多出5块内存,大小分别是1616,88,44,22,11。当生成多级纹理之后,我们使用texture object name指定的texture object,就是这个包含了多级纹理的纹理。多级纹理的用处一会我们再说,我们先说多级纹理是如何生成的。我们在说glTexImage2D这个API的时候,说过纹理的内存是通过这个API生成的,当使用这个API的时候,第二个输入参数就是制定给纹理的第几层赋值,当时我们都是给第0层赋值,那么现在我们就知道了,第0层为纹理的base level,那么默认都是给第0层赋值,但是我们也可以通过这个API给纹理的第1层mipmap,第2层mipmap赋值,一直到第N层mipmap。而这个在给第i层mipmap赋值的时候顺便也就把需要的内存生成出来。我们也说过每个纹理的mipmap是有限制的,比如3232的texture只能有6层mipmap,而64*64的texture有7层mipmap,依次类推。但是通过这个方式,一次只能给一层mipmap赋值,将多级纹理的所有层都赋上值,需要调用好多次命令。所以就有了glGenerateMipmap这个函数,这个函数就是将一个base level已经准备好的纹理,生成它的各级mipmap。这两种方式唯一的区别在于,通过glTexImage2D赋值的时候,对应texture object对应的内存存放的值是由开发者指定的,开发者可以往里面随意存入数值,而通过glGenerateMipmap这个函数生成的多级纹理中存储的值,第i层的值都是直接或者间接根据第0层的值计算出来的。生成算法一会再说。
这个函数的输入参数用于指定texture object的类型,必须是GL_TEXTURE_2D或者GL_TEXTURE_CUBE_MAP,来指定当前active的纹理单元中的一张texture,也就是用这个target来确定生成哪张纹理的mipmap。所以想要对一张纹理生成mipmap,先要通过glActiveTexture,enable一个纹理单元,然后通过glBindTexture,把这个texture绑定到这个纹理单元上。然后保持这个纹理单元处于active的状态,再调用这个API,来生成指定纹理的mipmap。如果输入了错误的target,就会出现GL_INVALID_ENUM的错误。
经过这个API,会根据第0层的数据产生一组mipmap数据,这组mipmap数据会替换掉texture之前的除了第0层之外的所有层的数据,第0层保持不变。所有层数据的internalformat都与第0层保持一致,每层的宽高都是上一层宽高除以2,一直到宽高均为1的一层。然后除了第0层之外,每一层的数据都是通过上一层计算出来的,算法也比较简单,一般都是根据四个像素点的值算出一个像素点的值即可
删除纹理glDeleteTextures
void glDeleteTextures(GLsizei n, const GLuint * textures);
纹理一旦被传输至GPU,就会一直留在GPU管理的内存中。因此我们应该留意那些不再被使用的纹理,及时的从GL内存中删除它们,以减少应用程序内存的占用。所以当texture不再被需要的时候,则可以通过glDeleteTextures这个API把texture object name删除。
创建Program glCreateProgram
GLuint glCreateProgram(void);
在一个完整的 OpenGL ES 的 pipeline 中,需要使用两个不同类型的 shader, 一个是 vertex shader,用于处理顶点坐标,一个是 fragment shader,用于处理顶点颜色。可以在代码中创建无数个 shader,但是最终交给 GPU 真正使用的,一次只能是一组两个不同类型的 shader。这两个 shader 将被放在一个叫做 program 的 object 中,然后把 program object 交给 GPU。而 glCreateProgram 就是用于创 建一个 program object 的。
指定program glUseProgram
void glUseProgram(GLuint program);
当一个 program 被成功链接之后,也就说明了该 program 已经准备就绪,可以被使用了,一个程序中可以有很多链接好的 program,但是同一时间只能有一个 program 被使用,那么 glUseProgram 这个 API 就是指定了哪个 program 会被使用,也就是把该 program 的可执行文件当作当前 rendering state 的一部分。
Blend融合
把当前帧绘制的颜色根据设定的方式与framebuffer上原有颜色进行混合。而Blend中的Alpha Blend就是传说中的半透明,也就是特效堆积游戏中最大的性能陷阱,因为它将百分之百带来overdraw
Blend其实就是将当前DC得到的颜色与存储在framebuffer上的目标颜色进行混合。混合方式取决于glBlendEquation,混合因子取决于glBlendFunc和glBlendColor。混合得到的结果会被clamp到[0, 1]。Blend中最常见的就是根据src或者dest的alpha值作为因子进行的alpha blend。Blend通过 glEnable和glDisable传入参数GL_BLEND来打开和关闭。初始状态下Blend是关闭的,如果关闭的话,则会直接跳到下一个环节。
- void glBlendColor(GLclampf red, GLclampf green, GLclampf blue, GLclampf alpha);
定义一个Blend Color,这个Blend Color将有可能作为Blend因子,详细作用见glBlendFunc。- void glBlendEquation(GLenum mode);
void glBlendEquationSeparate(GLenum modeRGB, GLenum modeAlpha);
混合的操作是由这两个API设定的。
glBlendEquationSeparate有2个输入参数,第一个参数modeRGB用于确定RGB三通道的混合模式,第二个参数modeAlpha用于确定alpha通道的混合模式。glBlendEquation只有一个输入参数,代表着RGBA四个通道的混合模式。以上涉及到的三个参数都必须是GL_FUNC_ADD, GL_FUNC_SUBTRACT, or GL_FUNC_REVERSE_SUBTRACT。否则就会出现GL_INVALID_ENUM 的错误。初始状态下,这三个参数的默认值均为GL_FUNC_ADD,GL_FUNC_ADD 也是最常用的混合算法,常用于比如AA或者半透明计算等- void glBlendFunc(GLenum sfactor, GLenum dfactor);
void glBlendFuncSeparate(GLenum srcRGB, GLenum dstRGB, GLenum srcAlpha, GLenum dstAlpha);
混合的因子是由这两个API设定的。
glBlendFuncSeparate 有4个输入参数,第一个参数 srcRGB 和第二个参数 dstRGB 用于确定RGB三通道src和dest的混合因子,第三个参数 srcAlpha 和第四个参数 dstAlpha 用于确定alpha通道src和dest的混合因子。 glBlendFunc 只有2个输入参数,第一个参数sfactor代表着src中RGBA四个通道的混合因子,第二个参数dfactor代表着dest中RGBA四个通道的混合因子。以上涉及到的六个参数中,三个参数是针对src的,三个参数是针对dest的。针对dest的参数必须是GL_ZERO, GL_ONE, GL_SRC_COLOR, GL_ONE_MINUS_SRC_COLOR, GL_DST_COLOR, GL_ONE_MINUS_DST_COLOR, GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA, GL_DST_ALPHA, GL_ONE_MINUS_DST_ALPHA. GL_CONSTANT_COLOR, GL_ONE_MINUS_CONSTANT_COLOR, GL_CONSTANT_ALPHA, and GL_ONE_MINUS_CONSTANT_ALPHA。初始状态下默认值为 GL_ZERO 。针对src的参数比针对dest的参数可选择性多一个 GL_SRC_ALPHA_SATURATE 。初始状态下默认值为GL_ONE。否则就会出现GL_INVALID_ENUM 的错误
混合将在所有的draw buffer中发生,使用这些buffer的颜色作为dest。如果color buffer中没有alpha值,则alpha为1。- void glEnable(GLenum cap);
void glDisable(GLenum cap);
开启或者关闭GPU的特性。
glEnable 和 glDisable函数都是只有1个输入参数,用于指定一个GL的特性。可以传入GL_BLEND(将PS算出的颜色与color buffer上的颜色进行混合)、GL_CULL_FACE(根据三角形在window坐标系的顶点顺序进行剔除)、GL_DEPTH_TEST(进行depth test并根据test结果更新depth buffer,需要注意即使存在depth buffer且depth mask为非0,如果depth test被disable了,那么也不会进行depth test)、GL_DITHER(在写入color buffer之前对color进行dither,默认开启)、GL_POLYGON_OFFSET_FILL(将光栅化产生的polygon fragment的depth进行offset的偏移)
Stencil Buffer(模板缓冲区)
Stencil Buffer(模板缓冲区)是OpenGL中的一种缓冲区,它通常与深度缓冲区一起使用,用于实现各种图形渲染效果。Stencil Buffer可以看作是一个二维的像素数组,每个像素都有一个与之对应的Stencil值。可以用于实现各种高级的图形效果。
Stencil Buffer的主要作用是在绘制过程中对像素进行遮罩和裁剪。Stencil Buffer可以被用来跟踪像素是否被渲染过,通过设置Stencil值可以控制哪些像素可以被渲染,哪些像素不能被渲染。Stencil Buffer可以用于实现一些高级的图形效果,如镜像、投影、轮廓线等。
设置模板测试函数
void glStencilFunc(GLenum func, GLint ref, GLuint mask);
void glStencilFuncSeparate(GLenum face, GLenum func, GLint ref, GLuint mask);
- glStencilFunc函数用于设置模板测试函数,该函数将当前的像素值与参考值进行比较,如果比较结果符合测试条件,则将该像素通过模板测试,否则该像素将被丢弃。该函数的参数包括比较函数、参考值和掩码,可以通过掩码来控制只对指定位进行比较。
- glStencilFuncSeparate函数与glStencilFunc函数类似,但它可以分别设置前、后模板测试函数,用于分别对正面和背面进行模板测试。这个函数的参数也包括比较函数、参考值和掩码,分别用于设置前、后模板测试。该函数通常用于绘制具有不同正反面属性的物体时,可以使用不同的模板测试函数来控制它们的渲染效果。
设置模板缓冲区的操作
void glStencilOp(GLenum sfail, GLenum dpfail, GLenum dppass);
void glStencilOpSeparate(GLenum face, GLenum sfail, GLenum dpfail, GLenum dppass);
- glStencilOp函数用于设置模板缓冲区的操作,主要包括三个参数:stencil fail、depth fail和depth pass。这些参数控制模板缓冲区的操作,当模板测试失败时,执行stencil fail操作,当深度测试失败时,执行depth fail操作,当深度和模板测试都通过时,执行depth pass操作。可以通过这些操作来控制在模板测试和深度测试中,模板缓冲区的内容如何被修改。
- glStencilOpSeparate函数与glStencilOp函数类似,但可以分别设置前、后模板缓冲区的操作,用于分别对正面和背面进行操作。这个函数的参数也包括stencil fail、depth fail和depth pass,分别用于设置前、后模板缓冲区操作。这个函数通常用于绘制具有不同正反面属性的物体时,可以使用不同的模板操作来控制它们的渲染效果。
设置模板缓冲区的写入掩码
void glStencilMask(GLuint mask);
void glStencilMaskSeparate(GLenum face, GLuint mask);
- glStencilMask函数用于设置模板缓冲区的写入掩码,掩码的作用是限制模板缓冲区中哪些位可以被写入。这个函数的参数是一个无符号整数,用于指定写入掩码。掩码中每个位的值为1,则对应的模板缓冲区位可以被写入,如果为0,则对应的位不能被写入。
- glStencilMaskSeparate函数与glStencilMask函数类似,但可以分别设置前、后模板缓冲区的写入掩码,用于分别对正面和背面进行设置。这个函数的参数也是一个无符号整数,分别用于设置前、后模板缓冲区的写入掩码。
这些函数通常与glStencilFunc、glStencilOp等函数一起使用,可以通过设置不同的掩码来控制哪些位可以被写入,以及如何修改模板缓冲区的内容。例如,可以使用glStencilMask函数将模板缓冲区的所有位设置为0,然后使用glStencilFunc和glStencilOp等函数来绘制一个具有特定模板值的形状,以此来实现模板缓冲区的裁剪效果。
glScissor裁剪测试
void glScissor(GLint x, GLint y, GLsizei width, GLsizei height);
glScissor函数用于定义一个矩形区域,该区域内的像素将会被保留,而其它区域的像素将会被丢弃。也就是说,该函数可以用来裁剪屏幕上的渲染结果,只保留指定区域内的内容。
该函数的参数包括矩形左下角的x、y坐标,以及矩形的宽度和高度。在调用该函数之后,只有在该矩形内的像素才会被保留,其它像素将会被丢弃。
glScissor函数通常与glEnable(GL_SCISSOR_TEST)函数一起使用,以启用裁剪测试。裁剪测试的作用是在渲染时,只绘制指定区域内的像素,其它像素将被忽略。这个函数通常用于实现视口变换、窗口裁剪、镜面反射等效果。
submit函数glFlush 和glFinish
glFlush 和 glFinish 都是 OpenGL 中用于控制命令提交和执行的函数,它们的作用如下:
void glFlush(void);
void glFinish(void);
- glFlush 函数:将所有已提交但未执行的命令立即发送到 GPU 执行,而不会等待 GPU 执行完成。该函数会立即返回,而不会阻塞调用线程。
- glFinish 函数:等待 GPU 执行所有已提交的命令并完成执行,然后该函数才会返回。它会阻塞调用线程,直到 GPU 执行完成为止。
总的来说,glFlush 函数通常用于优化性能,因为它能够减少命令提交的延迟,但它并不能保证所有命令都已执行完成。而 glFinish 函数则更适用于需要确保所有命令都已执行完成后才能进行后续操作的场景,例如读取渲染结果、截屏等。但由于它会阻塞线程,因此使用不当可能会影响应用程序的响应性能。
OpenGL API使用流程
先通过glGenTextures给生成一个新的texture object name。然后选择一个纹理单元,把这个texture object name生成纹理并绑定到这个纹理单元上。所以通过glActiveTexture把纹理单元enable,然后再通过glBindTexture把这个texture与GL_TEXTURE_2D绑定,我们知道这个texture object name是刚创建的,所以在执行这个命令的时候,我们知道,会先生成一个2D的texture object,然后把这个texture object放入刚才enable的那个纹理单元中。下面再通过glTexParameter对纹理设置参数。之后会使用对应的API去生成纹理内容,比如通过glTexImage2D,传入了target GL_TEXTURE_2D,传入了第几层mipmap,传入了准备好的internalformat、宽、高、format、type和data信息。纹理图片经历了解包、归一划、转换为RGB格式、归一划的过程,存储到了GPU中,在内存中,需要按照UNPACK_ALIGNMENT对齐。当CPU的纹理图片unpack到了GPU,开发者可以把CPU端的纹理图片删除。如果数据来源自CPU的JPG、PNG图片,这些格式图片不包含mipmap信息,而如果来自于pvr、etc之类的用于生成压缩纹理的原始图片,才可能会有mipmap信息。如果需要的话,再通过glHint设置生成mipmap的算法,然后通过glGenerateMipmap生成mipmap信息。这样的话一张纹理就生成了。当纹理使用完毕后,就要通过glDeleteTextures这个API把原来对应的纹理删除,并且把texture object name reset为0。
详细介绍参考:API介绍
绘制纹理流程
下面是绘制第一帧的流程,主要在upload texture上,且比较耗时
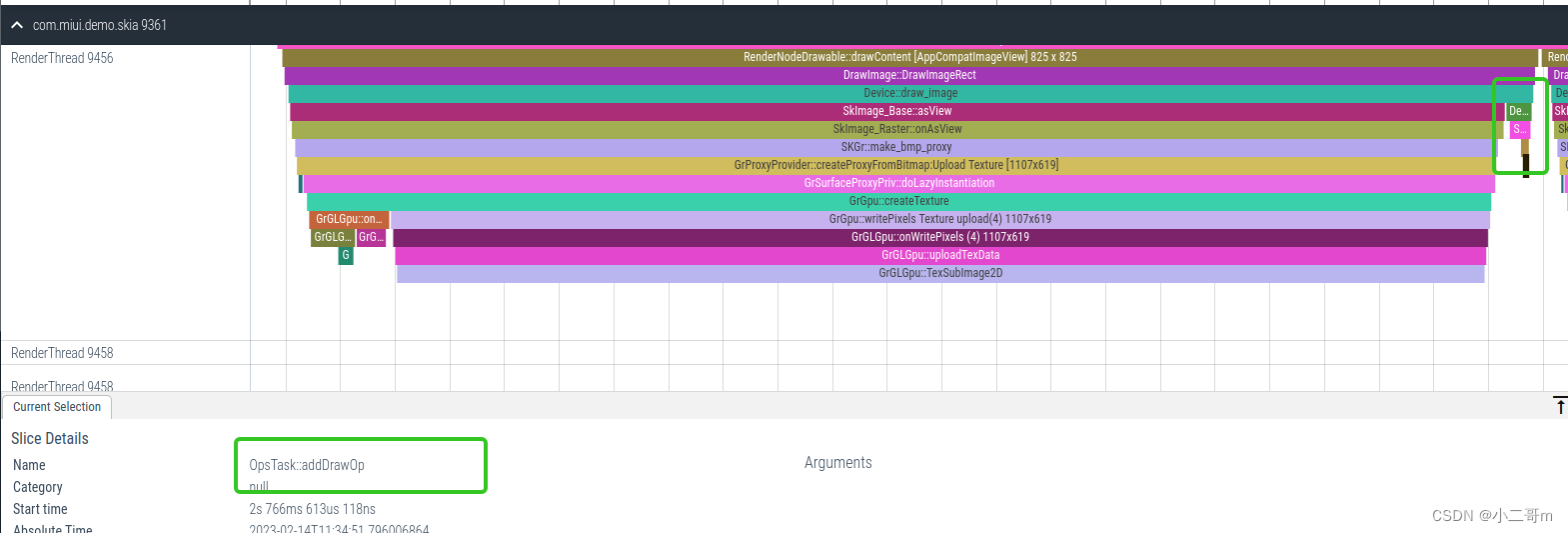
下面为绘制第一帧之后的draw流程

下面看下SkImage_Raster::onAsView的流程,先GrProxyProvider->findOrCreateProxyByUniqueKey,如果获取不到bitmap,则调用make_bmp_proxy创建bitmap,否则,直接返回GrSurfaceProxyView
下来在回顾下 Device::draw_texture流程
Device_drawTexture.cpp的draw_image中,主要两个操作创建纹理或者addDraw
ImageVIew这种资源图片的情况
- 调用SkImage_Base::asView去创建纹理
SkImage_Gpu和SkImage_Raster继承SkImage_Base,实现了onAsView,在asView->onAsView中去创建纹理,这里会调用SkImage_Raster::onAsView- 调用调用draw_texture去add draw
draw_texture中主要是调用SurfaceDrawContext::drawTexture/drawTextureQuad,进而去调用SurfaceDrawContext::addDrawOp->OpsTask::addDrawOp添加到fOpChains中
external/skia/src/gpu/ops/OpsTask.cpp
void OpsTask::addDrawOp(GrDrawingManager* drawingMgr, GrOp::Owner op, bool usesMSAA,
const GrProcessorSet::Analysis& processorAnalysis, GrAppliedClip&& clip,
const GrDstProxyView& dstProxyView,
GrTextureResolveManager textureResolveManager, const GrCaps& caps) {
...
this->recordOp(std::move(op), usesMSAA, processorAnalysis, clip.doesClip() ? &clip : nullptr,
&dstProxyView, caps);
}
void OpsTask::recordOp(
GrOp::Owner op, bool usesMSAA, GrProcessorSet::Analysis processorAnalysis,
GrAppliedClip* clip, const GrDstProxyView* dstProxyView, const GrCaps& caps) {
...
// Check if there is an op we can combine with by linearly searching back until we either
// 1) check every op
// 2) intersect with something
// 3) find a 'blocker'
...
if (clip) {
clip = fArenas->arenaAlloc()->make<GrAppliedClip>(std::move(*clip));
SkDEBUGCODE(fNumClips++;)
}
fOpChains.emplace_back(std::move(op), processorAnalysis, clip, dstProxyView);
}
在recordOp中将被添加到fOpChains中
external/skia/src/gpu/ops/OpsTask.h
// For ops/opsTask we have mean: 5 stdDev: 28
SkSTArray<25, OpChain> fOpChains;
纹理bind流程
纹理创建完成后,执行surface->flushAndSubmit去完成真正的绘制流程
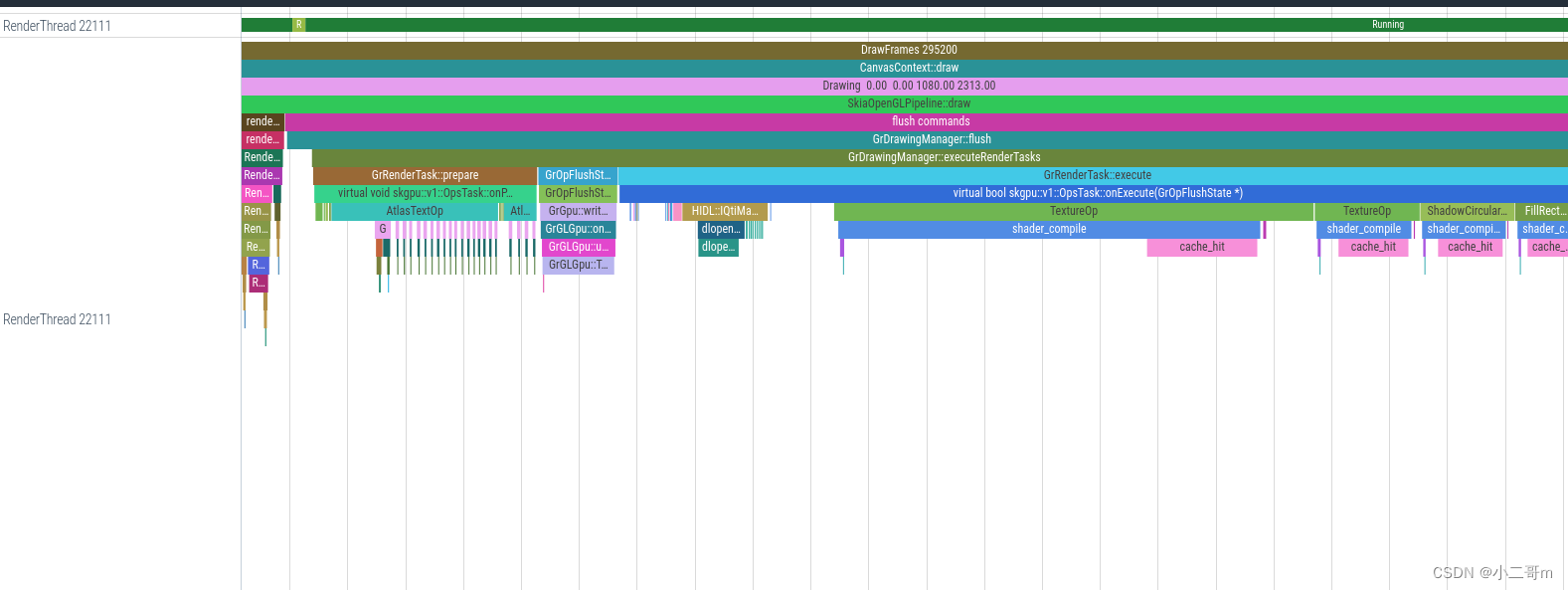
这里会执行bindTexture去绑定纹理,调用堆栈如下
#00 pc 00000000005b7eec /system/lib64/libhwui.so (GrGLGpu::bindTexture(int, GrSamplerState, skgpu::Swizzle const&, GrGLTexture*)+96)
#01 pc 00000000005c4290 /system/lib64/libhwui.so (GrGLProgram::bindTextures(GrGeometryProcessor const&, GrSurfaceProxy const* const*, GrPipeline const&)+172)
#02 pc 00000000005c2704 /system/lib64/libhwui.so (GrGLOpsRenderPass::onBindTextures(GrGeometryProcessor const&, GrSurfaceProxy const* const*, GrPipeline const&)+84)
#03 pc 0000000000548934 /system/lib64/libhwui.so (GrOpsRenderPass::bindTextures(GrGeometryProcessor const&, GrSurfaceProxy const* const*, GrPipeline const&)+36)
#04 pc 000000000060f084 /system/lib64/libhwui.so ((anonymous namespace)::ShadowCircularRRectOp::onExecute(GrOpFlushState*, SkRect const&)+172)
#05 pc 0000000000605988 /system/lib64/libhwui.so (skgpu::v1::OpsTask::onExecute(GrOpFlushState*)+772)
#06 pc 00000000005367b8 /system/lib64/libhwui.so (GrDrawingManager::flush(SkSpan<GrSurfaceProxy*>, SkSurface::BackendSurfaceAccess, GrFlushInfo const&, GrBackendSurfaceMutableState const*)+2780)
#07 pc 0000000000536d44 /system/lib64/libhwui.so (GrDrawingManager::flushSurfaces(SkSpan<GrSurfaceProxy*>, SkSurface::BackendSurfaceAccess, GrFlushInfo const&, GrBackendSurfaceMutableState const*)+164)
#08 pc 000000000052f5f0 /system/lib64/libhwui.so (GrDirectContextPriv::flushSurfaces(SkSpan<GrSurfaceProxy*>, SkSurface::BackendSurfaceAccess, GrFlushInfo const&, GrBackendSurfaceMutableState const*)+284)
#09 pc 000000000068c6bc /system/lib64/libhwui.so (SkSurface_Gpu::onFlush(SkSurface::BackendSurfaceAccess, GrFlushInfo const&, GrBackendSurfaceMutableState const*)+152)
#10 pc 000000000068e688 /system/lib64/libhwui.so (SkSurface::flushAndSubmit(bool)+64)
#11 pc 000000000027c2bc /system/lib64/libhwui.so (android::uirenderer::skiapipeline::SkiaOpenGLPipeline::draw(android::uirenderer::renderthread::Frame const&, SkRect const&, SkRect const&, android::uirenderer::LightGeometry const&, android::uirenderer::LayerUpdateQueue*, android::uirenderer::Rect const&, bool, android::uirenderer::LightInfo const&, std::__1::vector<android::sp<android::uirenderer::RenderNode>, std::__1::allocator<android::sp<android::uirenderer::RenderNode> > > const&, android::uirenderer::FrameInfoVisualizer*)+604)
#12 pc 0000000000283974 /system/lib64/libhwui.so (android::uirenderer::renderthread::CanvasContext::draw()+1104)
#13 pc 00000000002866b4 /system/lib64/libhwui.so (std::__1::__function::__func<android::uirenderer::renderthread::DrawFrameTask::postAndWait()::$_0, std::__1::allocator<android::uirenderer::renderthread::DrawFrameTask::postAndWait()::$_0>, void ()>::operator()() (.c1671e787f244890c877724752face20)+904)
#14 pc 0000000000276090 /system/lib64/libhwui.so (android::uirenderer::WorkQueue::process()+588)
#15 pc 00000000002972c0 /system/lib64/libhwui.so (android::uirenderer::renderthread::RenderThread::threadLoop()+416)
#16 pc 0000000000013598 /system/lib64/libutils.so (android::Thread::_threadLoop(void*)+424)
#17 pc 00000000000f5548 /apex/com.android.runtime/lib64/bionic/libc.so (__pthread_start(void*)+208)
#18 pc 000000000008ef3c /apex/com.android.runtime/lib64/bionic/libc.so (__start_thread+68)
* frameworks/base/libs/hwui/pipeline/skia/SkiaOpenGLPipeline.cpp
bool SkiaOpenGLPipeline::draw(const Frame& frame, const SkRect& screenDirty, const SkRect& dirty,
const LightGeometry& lightGeometry,
LayerUpdateQueue* layerUpdateQueue, const Rect& contentDrawBounds,
bool opaque, const LightInfo& lightInfo,
const std::vector<sp<RenderNode>>& renderNodes,
FrameInfoVisualizer* profiler) {
1. damageFrame
mEglManager.damageFrame(frame, dirty);
...
// 这里调用SkSurface::MakeFromBackendRenderTarget
sk_sp<SkSurface> surface(SkSurface::MakeFromBackendRenderTarget(
mRenderThread.getGrContext(), backendRT, this->getSurfaceOrigin(), colorType,
mSurfaceColorSpace, &props));
LightingInfo::updateLighting(lightGeometry, lightInfo);
2. renderFrame
renderFrame(*layerUpdateQueue, dirty, renderNodes, opaque, contentDrawBounds, surface,
SkMatrix::I());
...
{
ATRACE_NAME("flush commands");
3. flush commands
surface->flushAndSubmit();
}
layerUpdateQueue->clear();
...
return {true, IRenderPipeline::DrawResult::kUnknownTime};
}
* external/skia/src/image/SkSurface_Gpu.cpp
void SkSurface::flushAndSubmit(bool syncCpu) {
this->flush(BackendSurfaceAccess::kNoAccess, GrFlushInfo());
auto direct = GrAsDirectContext(this->recordingContext());
if (direct) {
direct->submit(syncCpu);
}
}
回顾下绘制流程,第三步调用flushAndSubmit执行纹理bind
这里调用SkSurface_Gpu::flushAndSubmit
第一步调用SkSurface::flush->SkSurface_Gpu::onFlush->GrDirectContextPriv::flushSurfaces->GrDrawingManager::flushSurfaces->GrDrawingManager::flush->GrDrawingManager::executeRenderTasks
第二步调用direct->submit执行submit到GPU
bool GrDrawingManager::flush(
SkSpan<GrSurfaceProxy*> proxies,
SkSurface::BackendSurfaceAccess access,
const GrFlushInfo& info,
const GrBackendSurfaceMutableState* newState) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrDrawingManager::flush");
...
GrGpu* gpu = dContext->priv().getGpu();
...
GrOpFlushState flushState(gpu, resourceProvider, &fTokenTracker, fCpuBufferCache);
GrOnFlushResourceProvider onFlushProvider(this);
...
bool flushed = !resourceAllocator.failedInstantiation() &&
this->executeRenderTasks(&flushState);
this->removeRenderTasks();
gpu->executeFlushInfo(proxies, access, info, newState);
...
return true;
}
bool GrDrawingManager::executeRenderTasks(GrOpFlushState* flushState) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrDrawingManager::executeRenderTasks");
bool anyRenderTasksExecuted = false;
for (const auto& renderTask : fDAG) {
...
renderTask->prepare(flushState);
}
// Upload all data to the GPU
flushState->preExecuteDraws();
...
fOnFlushRenderTasks.reset();
// Execute the normal op lists.
for (const auto& renderTask : fDAG) {
...
if (renderTask->execute(flushState)) {
anyRenderTasksExecuted = true;
}
...
}
...
// We reset the flush state before the RenderTasks so that the last resources to be freed are
// those that are written to in the RenderTasks. This helps to make sure the most recently used
// resources are the last to be purged by the resource cache.
flushState->reset();
return anyRenderTasksExecuted;
}
executeRenderTasks主要执行如下操作
- GrRenderTask->prepare,所以调用OpsTask::onPrepare
- GrOpFlushState::preExecuteDraws,调用GrOpFlushState::doUpload->GrGpu::writePixels,只在第一次加载调用doUpload,
- GrRenderTask->execute,OpsTask继承GrRenderTask,所以调用OpsTask::onExecute,执行纹理bind
- 调用flushState->gpu()->submitToGpu(false)
因为OpsTask继承GrRenderTask
prepare流程
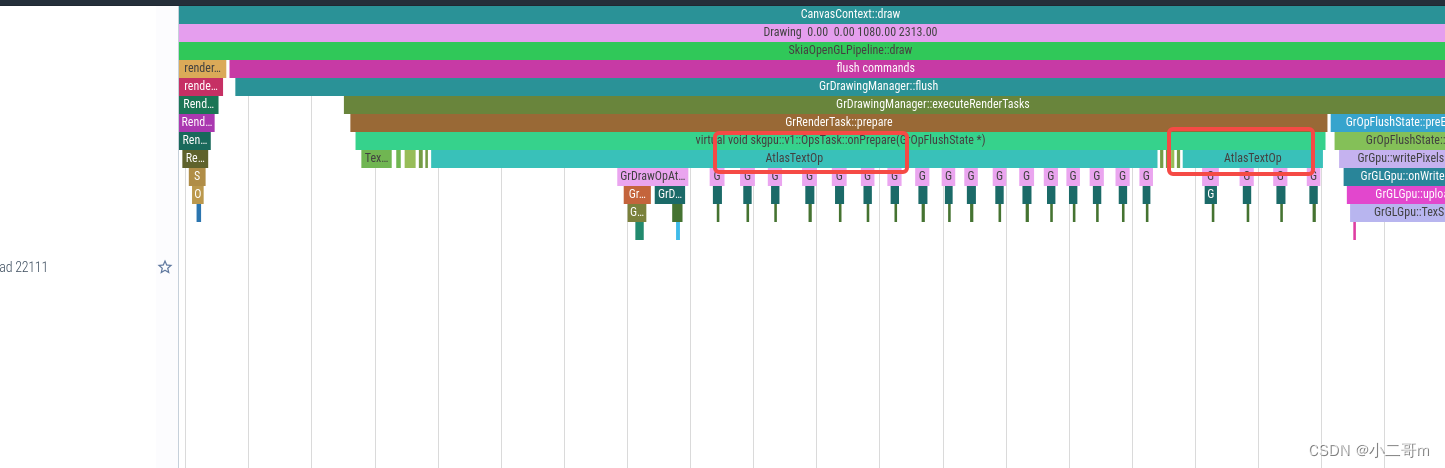
这里第一个AtlasTextOp是底部导航拦,第二个是AtlasTextOp为actionBar
void OpsTask::onPrepare(GrOpFlushState* flushState) {
...
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_FUNC);
flushState->setSampledProxyArray(&fSampledProxies);
GrSurfaceProxyView dstView(sk_ref_sp(this->target(0)), fTargetOrigin, fTargetSwizzle);
// Loop over the ops that haven't yet been prepared.
for (const auto& chain : fOpChains) {
if (chain.shouldExecute()) {
GrOpFlushState::OpArgs opArgs(chain.head(),
dstView,
fUsesMSAASurface,
chain.appliedClip(),
chain.dstProxyView(),
fRenderPassXferBarriers,
fColorLoadOp);
flushState->setOpArgs(&opArgs);
// GrOp::prePrepare may or may not have been called at this point
chain.head()->prepare(flushState);
flushState->setOpArgs(nullptr);
}
}
flushState->setSampledProxyArray(nullptr);
}
GrOp.prepare会回调子类的onPrepare
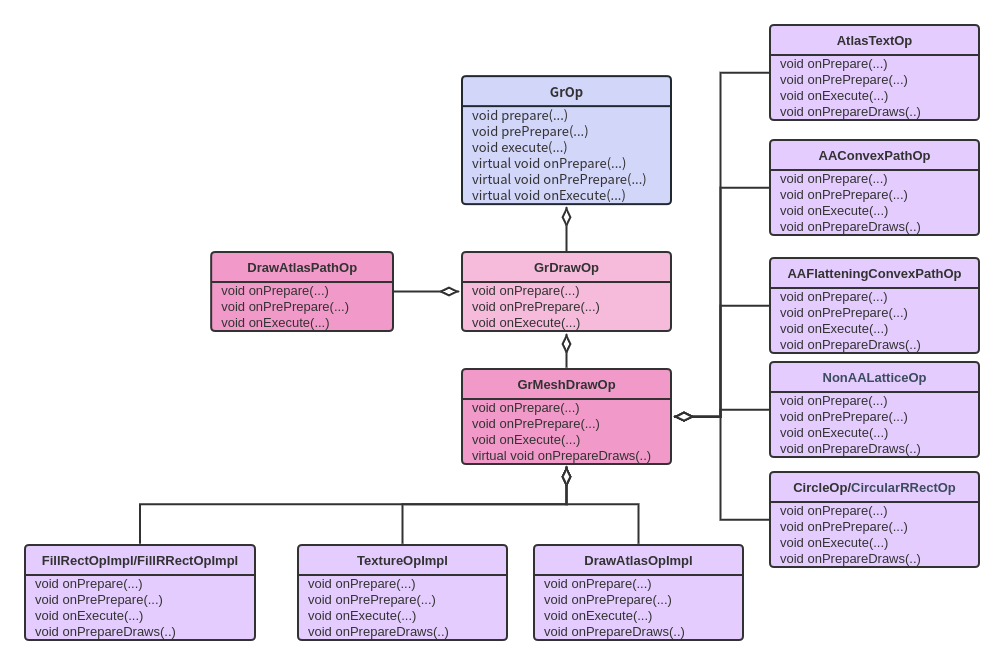
基本上,所有的Op都继承GrMeshDrawOp,在GrMeshDrawOp::onPrepare,会调用子类的onPrepareDraws,比较常用的有AtlasTextOp和TextureOp

* external/skia/src/gpu/ops/TextureOp.cpp
void onPrepareDraws(GrMeshDrawTarget* target) override {
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_FUNC);
...
size_t vertexSize = fDesc->fVertexSpec.vertexSize();
// 1. 实现在GrOpFlushState::makeVertexSpace
void* vdata = target->makeVertexSpace(vertexSize, fDesc->totalNumVertices(),
&fDesc->fVertexBuffer, &fDesc->fBaseVertex);
...
// cpu缓冲区填充数据
if (fDesc->fPrePreparedVertices) {
memcpy(vdata, fDesc->fPrePreparedVertices, fDesc->totalSizeInBytes());
} else {
FillInVertices(target->caps(), this, fDesc, (char*) vdata);
}
}
- 先调用makeVertexSpace
target是GrOpFlushState,GrOpFlushState继承GrMeshDrawTarget,创建在GrDrawingManager::flush时
所以这里调用fVertexPool.makeSpace,然后执行GrVertexBufferAllocPool::makeSpace,因为INHERITED 为GrBufferAllocPool,所以进而调用到GrBufferAllocPool::makeSpace
这里fBlocks为SkTArray的数组,BufferBlock为一个buffer块,包含了块的大小,每个块为GrCpuBuffer
总的来说,makeSpace会通过一个可变的缓冲区池获取一部分空间
- FillInVertices
调用FillInVertices去填充缓冲区数据
* external/skia/src/gpu/GrDrawingManager.cpp
bool GrDrawingManager::flush(SkSpan<GrSurfaceProxy*> proxies, SkSurface::BackendSurfaceAccess access, const GrFlushInfo& info,
const GrBackendSurfaceMutableState* newState) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrDrawingManager::flush");
...
if (!fCpuBufferCache) {
// 当后端使用客户端数组时,我们会缓存更多的缓冲区。
// 否则,我们期望每个池在上传到GPU缓冲区对象之前都会使用一个CPU缓冲区作为分段缓冲区。每个池一次只需要一个工作台缓冲区。
// 这里一般会返回2
int maxCachedBuffers = fContext->priv().caps()->preferClientSideDynamicBuffers() ? 2 : 6;
fCpuBufferCache = GrBufferAllocPool::CpuBufferCache::Make(maxCachedBuffers);
}
...
}
* external/skia/src/gpu/GrOpFlushState.cpp
GrVertexBufferAllocPool fVertexPool;
void* GrOpFlushState::makeVertexSpace(size_t vertexSize, int vertexCount, sk_sp<const GrBuffer>* buffer, int* startVertex) {
return fVertexPool.makeSpace(vertexSize, vertexCount, buffer, startVertex);
}
* external/skia/src/gpu/GrBufferAllocPool.cpp
void* GrBufferAllocPool::makeSpace(size_t size, size_t alignment, sk_sp<const GrBuffer>* buffer, size_t* offset) {
...
if (fBufferPtr) {
// 这里fBlocks为SkTArray<BufferBlock>的数组,BufferBlock为一个buffer块,包含了块的大小,每个块为GrCpuBuffer
BufferBlock& back = fBlocks.back();
size_t usedBytes = back.fBuffer->size() - back.fBytesFree;
size_t pad = align_up_pad(usedBytes, alignment);
SkSafeMath safeMath;
size_t alignedSize = safeMath.add(pad, size);
if (!safeMath.ok()) {
return nullptr;
}
if (alignedSize <= back.fBytesFree) {
memset((void*)(reinterpret_cast<intptr_t>(fBufferPtr) + usedBytes), 0, pad);
usedBytes += pad;
*offset = usedBytes;
*buffer = back.fBuffer;
back.fBytesFree -= alignedSize;
fBytesInUse += alignedSize;
VALIDATE();
return (void*)(reinterpret_cast<intptr_t>(fBufferPtr) + usedBytes);
}
}
// 我们可以通过部分更新当前 VB(如果有空间)来满足空间请求。
// 但是我们目前不使用对 GL 的绘制调用,让驱动程序知道之前发出的绘制不会从我们更新的缓冲区部分读取。
// 此外,如果传递的数据量小于完整缓冲区大小,则 GL 缓冲区实现可能会通过缩小 updateData() 上的缓冲区来欺骗实际缓冲区大小。
if (!this->createBlock(size)) {
return nullptr;
}
SkASSERT(fBufferPtr);
*offset = 0;
BufferBlock& back = fBlocks.back();
*buffer = back.fBuffer;
back.fBytesFree -= size;
fBytesInUse += size;
VALIDATE();
return fBufferPtr;
}
execute
GrDrawingManager::executeRenderTasks先调用GrOpFlushState::preExecuteDraws
GrDrawingManager::executeRenderTasks然后循环调用 GrRenderTask::onExecute
- preExecuteDraws
* external/skia/src/gpu/GrOpFlushState.cpp
void GrOpFlushState::preExecuteDraws() {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrOpFlushState::preExecuteDraws");
fVertexPool.unmap();
fIndexPool.unmap();
fDrawIndirectPool.unmap();
for (auto& upload : fASAPUploads) {
this->doUpload(upload);
}
// Setup execution iterators.
fCurrDraw = fDraws.begin();
fCurrUpload = fInlineUploads.begin();
}
void GrOpFlushState::doUpload(GrDeferredTextureUploadFn& upload,
bool shouldPrepareSurfaceForSampling) {
GrDeferredTextureUploadWritePixelsFn wp = [this, shouldPrepareSurfaceForSampling](
GrTextureProxy* dstProxy,
SkIRect rect,
GrColorType colorType,
const void* buffer,
size_t rowBytes) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrOpFlushState::doUpload");
GrSurface* dstSurface = dstProxy->peekSurface();
...
return this->fGpu->writePixels(dstSurface,
rect,
colorType,
supportedWrite.fColorType,
buffer,
rowBytes,
shouldPrepareSurfaceForSampling);
};
// 执行wp回调
upload(wp);
}
这里主要通过通过匿名函数,调用GrGpu::writePixels进而调用GrGLGpu::onWritePixels来执行纹理上传
onWritePixels中,首先调用 GL_CALL(TexParameteri(glTex->target(), GR_GL_TEXTURE_MAX_LEVEL, maxLevel))设置mipmaps的层级,然后调用GrGLGpu::uploadColorTypeTexData->GrGLGpu::uploadTexData->TexSubImage2D
这里最终调用glTexSubImage2D去加载纹理
- execute
GrDrawingManager::executeRenderTask->GrRenderTask::execute->GrRenderTask::onExecute
因为OpsTask继承GrRenderTask,所以这里调用OpsTask::onExecute
这里主要执行三部操作:
- create_render_pass->GrGpu::getOpsRenderPass->GrGLGpu::onGetOpsRenderPass,然后创建GrGLOpsRenderPass
- 调用GrGLOpsRenderPass::onBegin->GrGLGpu::beginCommandBuffer
- OpChains::execute,主要调用AtlasTextOp和TextureOp的onExecute
- GrGpu::submit
GrGLGpu::beginCommandBuffer首先调用GrGLGpu::flushClearColor,主要执行GLClearColor,这里会根据windowBackground的颜色,设置窗口颜色
glClearColor函数设置好清除颜色,glClear利用glClearColor函数设置好的当前清除颜色设置窗口颜色
那么这个颜色怎么设置的呢?
设置OpsTask::fLoadClearColor颜色的地方,只有在setColorLoadOp中调用,而调用setColorLoadOp的地方在SurfaceFillContext_v1::SurfaceFillContext::internalClear,SurfaceDrawContext继承SurfaceFillContext
#00 pc 00000000006076b8 /system/lib64/libhwui.so (skgpu::v1::OpsTask::setColorLoadOp(GrLoadOp, std::__1::array<float, 4ul>)+84)
#01 pc 000000000065ed5c /system/lib64/libhwui.so (skgpu::v1::SurfaceFillContext::internalClear(SkIRect const*, std::__1::array<float, 4ul>, bool)+700)
#02 pc 0000000000657ca0 /system/lib64/libhwui.so (skgpu::v1::SurfaceDrawContext::attemptQuadOptimization(GrClip const*, GrUserStencilSettings const*, GrAA*, DrawQuad*, GrPaint*)+1652)
#03 pc 00000000006584f4 /system/lib64/libhwui.so (skgpu::v1::SurfaceDrawContext::drawFilledQuad(GrClip const*, GrPaint&&, GrAA, DrawQuad*, GrUserStencilSettings const*)+236)
#04 pc 00000000006575b0 /system/lib64/libhwui.so (skgpu::v1::SurfaceDrawContext::fillRectToRect(GrClip const*, GrPaint&&, GrAA, SkMatrix const&, SkRect const&, SkRect const&)+748)
#05 pc 0000000000659cf8 /system/lib64/libhwui.so (skgpu::v1::SurfaceDrawContext::drawRect(GrClip const*, GrPaint&&, GrAA, SkMatrix const&, SkRect const&, GrStyle const*)+288)
#06 pc 000000000064c6f8 /system/lib64/libhwui.so (skgpu::v1::Device::drawRect(SkRect const&, SkPaint const&)+324)
#07 pc 00000000002e955c /system/lib64/libhwui.so (SkCanvas::onDrawRect(SkRect const&, SkPaint const&)+196)
#08 pc 00000000002e816c /system/lib64/libhwui.so (SkCanvas::drawRect(SkRect const&, SkPaint const&)+136)
#09 pc 00000000002536fc /system/lib64/libhwui.so (android::uirenderer::DisplayListData::draw(SkCanvas*) const+132)
#10 pc 000000000023bc94 /system/lib64/libhwui.so (android::uirenderer::skiapipeline::RenderNodeDrawable::drawContent(SkCanvas*) const+1784)
bool GrDrawingManager::executeRenderTasks(GrOpFlushState* flushState) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrDrawingManager::executeRenderTasks");
bool anyRenderTasksExecuted = false;
for (const auto& renderTask : fDAG) {
...
renderTask->prepare(flushState);
}
// Upload all data to the GPU
flushState->preExecuteDraws();
...
fOnFlushRenderTasks.reset();
// Execute the normal op lists.
for (const auto& renderTask : fDAG) {
...
if (renderTask->execute(flushState)) {
anyRenderTasksExecuted = true;
}
...
}
bool OpsTask::onExecute(GrOpFlushState* flushState) {
...
GrOpsRenderPass* renderPass = create_render_pass(flushState->gpu(),
proxy->peekRenderTarget(),
fUsesMSAASurface,
stencil,
fTargetOrigin,
fClippedContentBounds,
fColorLoadOp,
fLoadClearColor,
stencilLoadOp,
stencilStoreOp,
fSampledProxies,
fRenderPassXferBarriers);
...
renderPass->begin();
GrSurfaceProxyView dstView(sk_ref_sp(this->target(0)), fTargetOrigin, fTargetSwizzle);
// Draw all the generated geometry.
for (const auto& chain : fOpChains) {
...
GrOpFlushState::OpArgs opArgs(chain.head(),
dstView,
fUsesMSAASurface,
chain.appliedClip(),
chain.dstProxyView(),
fRenderPassXferBarriers,
fColorLoadOp);
flushState->setOpArgs(&opArgs);
chain.head()->execute(flushState, chain.bounds());
flushState->setOpArgs(nullptr);
}
renderPass->end();
flushState->gpu()->submit(renderPass);
flushState->setOpsRenderPass(nullptr);
return true;
}
* external/skia/src/gpu/gl/GrGLGpu.cpp
void GrGLGpu::beginCommandBuffer(GrGLRenderTarget* rt, bool useMultisampleFBO,
const SkIRect& bounds, GrSurfaceOrigin origin,
const GrOpsRenderPass::LoadAndStoreInfo& colorLoadStore,
const GrOpsRenderPass::StencilLoadAndStoreInfo& stencilLoadStore) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGLGpu::beginCommandBuffer");
...
GrGLbitfield clearMask = 0;
if (GrLoadOp::kClear == colorLoadStore.fLoadOp) {
SkASSERT(!this->caps()->performColorClearsAsDraws());
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGLGpu::flushClearColor");
this->flushClearColor(colorLoadStore.fClearColor);
this->flushColorWrite(true);
clearMask |= GR_GL_COLOR_BUFFER_BIT;
}
...
if (clearMask) {
this->flushScissorTest(GrScissorTest::kDisabled);
this->disableWindowRectangles();
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrGLGpu::Clear");
GL_CALL(Clear(clearMask));
}
}
attemptQuadOptimization主要是做一些优化剪裁,尝试将一个四边形绘制操作优化为两个三角形绘制操作,以提高渲染性能。这个函数会检查四边形的顶点是否在同一直线上,如果是,则直接使用矩形绘制函数;否则,将四边形分割为两个三角形,并使用三角形绘制函数进行绘制。这里调用SurfaceFillContext::clear,然后调用internalClear去初始化屏幕颜色
SurfaceDrawContext::QuadOptimization SurfaceDrawContext::attemptQuadOptimization(
const GrClip* clip, const GrUserStencilSettings* stencilSettings, GrAA* aa, DrawQuad* quad,
GrPaint* paint) {
ATRACE_ANDROID_FRAMEWORK_ALWAYS("SurfaceDrawContext::attemptQuadOptimization");
// 优化要求:
// 1. kDiscard:当剪辑边界和四边形边界不相交时
// 2a. kSubmitted:当 constColor 和最终几何形状为像素对齐矩形时 或者 像素对齐矩形需要矩形剪辑和(矩形四边形或四边形覆盖剪辑)
// 2b.kSubmitted:当 constColor 和 rrect 剪辑时且四边形覆盖剪辑
// 4. kClipApplied:当矩形剪辑和(矩形四边形或四边形覆盖剪辑)时
// 5. kCropped 在所有其他场景中(尽管裁剪可能是no-op)
const SkPMColor4f* constColor = nullptr;
SkPMColor4f paintColor;
if (!stencilSettings && paint && !paint->hasCoverageFragmentProcessor() &&
paint->isConstantBlendedColor(&paintColor)) {
// 仅在很容易保证 100% 填充单一颜色时才考虑清除/rrects
constColor = &paintColor;
}
// 保存旧的 AA 标志,因为 CropToRect 将修改 'quad',如果返回 kCropped,最好只保留旧标志而不是引入混合边缘标志。
GrQuadAAFlags oldFlags = quad->fEdgeFlags;
//使用渲染目标的逻辑大小,这允许“全屏”清除,即使渲染目标具有近似的背景适合度
SkRect rtRect = this->asSurfaceProxy()->getBoundsRect();
SkRect drawBounds = quad->fDevice.bounds();
..
auto conservativeCrop = [&]() {
static constexpr int kLargeDrawLimit = 15000;
// 将四边形裁剪到渲染目标。 这不会改变绘图的视觉结果,但旨在帮助处理过大的绘图时的数值稳定性。
if (drawBounds.width() > kLargeDrawLimit || drawBounds.height() > kLargeDrawLimit) {
// 该函数可以将一个 DrawQuad 对象裁剪到指定的矩形范围内,并更新其对应的边界标志
GrQuadUtils::CropToRect(rtRect, *aa, quad, /* compute local */ !constColor);
}
};
bool simpleColor = !stencilSettings && constColor;
GrClip::PreClipResult result = clip ? clip->preApply(drawBounds, *aa)
: GrClip::PreClipResult(GrClip::Effect::kUnclipped);
switch(result.fEffect) {
case GrClip::Effect::kClippedOut:
// 如果裁剪结果为完全裁剪,则丢弃这个绘制指令
return QuadOptimization::kDiscarded;
case GrClip::Effect::kUnclipped:
if (!simpleColor) {
// 非单一色,则返回kClipApplied,不做优化,除非是图形非常大,超过15000
conservativeCrop();
return QuadOptimization::kClipApplied;
} else {
// 更新结果,将渲染目标边界按顺序存储,然后继续尝试 draw->native清除优化
result = GrClip::PreClipResult(SkRRect::MakeRect(rtRect), *aa);
}
break;
case GrClip::Effect::kClipped:
if (!result.fIsRRect || (stencilSettings && result.fAA != *aa) ||
(!result.fRRect.isRect() && !simpleColor)) {
//裁剪和绘制状态过于复杂,无法尝试简化处理
conservativeCrop();
return QuadOptimization::kCropped;
} // 否则,继续尝试将绘制和裁剪的几何图形结合在一起。
break;
default:
SkUNREACHABLE;
}
// 如果代码执行到这里,说明我们得到的是一个轴对齐的矩形或圆角矩形裁剪区域,
// 因此我们有可能将其与绘制几何图形结合起来,从而不需要进行裁剪。
SkASSERT(result.fEffect == GrClip::Effect::kClipped && result.fIsRRect);
// 计算绘制操作的有效区域,即绘制区域与裁剪区域的交集。
// 首先,从PreClipResult结果中获取裁剪区域的矩形边界,并将其与渲染目标的矩形边界取交集,得到裁剪后的矩形边界。
// 然后,将绘制区域与裁剪后的矩形边界取交集,得到绘制操作的有效区域。
// 如果有效区域为空,则说明绘制操作完全被裁剪,直接返回QuadOptimization::kDiscarded,表示绘制被丢弃
SkRect clippedBounds = result.fRRect.getBounds();
clippedBounds.intersect(rtRect);
if (!drawBounds.intersect(clippedBounds)) {
//没有交集的情况下,小数边界可能实际上并不在剪辑区域内。GrClip::preApply()有时会按照四舍五入的边界思考。放弃绘制。
return QuadOptimization::kDiscarded;
}
// 防止剪辑绘制在交叉后变成一条细线绘制
if (drawBounds.width() < 1.f || drawBounds.height() < 1.f) {
return QuadOptimization::kCropped;
}
if (result.fRRect.isRect()) {
// 没有圆角,因此我们可能可以成为本地清除或者我们可能能够修改几何图形和边缘标志来表示剪辑和绘制的相交形状
if (GrQuadUtils::CropToRect(clippedBounds, result.fAA, quad,
/*compute local*/ !constColor)) {
if (simpleColor && quad->fDevice.quadType() == GrQuad::Type::kAxisAligned) {
// 单一色且是轴对称,可能进行清除优化
drawBounds = quad->fDevice.bounds();
if (drawBounds.contains(rtRect)) {
// Fullscreen clear
this->clear(*constColor);
return QuadOptimization::kSubmitted;
} else if (GrClip::IsPixelAligned(drawBounds) &&
drawBounds.width() > 256 && drawBounds.height() > 256) {
// 如果是像素对齐(矩形的左上角和右下角坐标的x和y坐标都是整数,则可以认为该矩形是像素对齐的),且宽高大于256
// 像素对齐的,圆角不会有影响
SkIRect scissorRect;
drawBounds.round(&scissorRect);
this->clear(scissorRect, *constColor);
return QuadOptimization::kSubmitted;
}
}
// else the draw and clip were combined so just update the AA to reflect combination
if (*aa == GrAA::kNo && result.fAA == GrAA::kYes &&
quad->fEdgeFlags != GrQuadAAFlags::kNone) {
*aa = GrAA::kYes;
}
return QuadOptimization::kClipApplied;
}
} else {
// 有圆角和常量填充颜色(限制我们只能使用纯色,因为使用drawRRect无法使用自定义的本地坐标)。
SkASSERT(simpleColor);
if (GrQuadUtils::CropToRect(clippedBounds, result.fAA, quad,
/* compute local */ false) &&
quad->fDevice.quadType() == GrQuad::Type::kAxisAligned &&
quad->fDevice.bounds().contains(clippedBounds)) {
// 由于裁剪后的四边形变成了一个覆盖圆角矩形边界的矩形,因此我们可以直接绘制圆角矩形,忽略边缘标志。
this->drawRRect(nullptr, std::move(*paint), result.fAA, SkMatrix::I(), result.fRRect,
GrStyle::SimpleFill());
return QuadOptimization::kSubmitted;
}
}
// The quads have been updated to better fit the clip bounds, but can't get rid of
// the clip entirely
quad->fEdgeFlags = oldFlags;
return QuadOptimization::kCropped;
}
GrQuadUtils::CropToRect函数的作用是将一个四边形裁剪为一个矩形。它会将四边形的四个点与指定的矩形进行相交计算,从而得到四边形与矩形的交集,然后返回一个表示交集的四边形。如果四边形与矩形没有交集,则返回false。
OpChains::execute,主要调用AtlasTextOp、FillRectOp、TextureOp等的onExecute
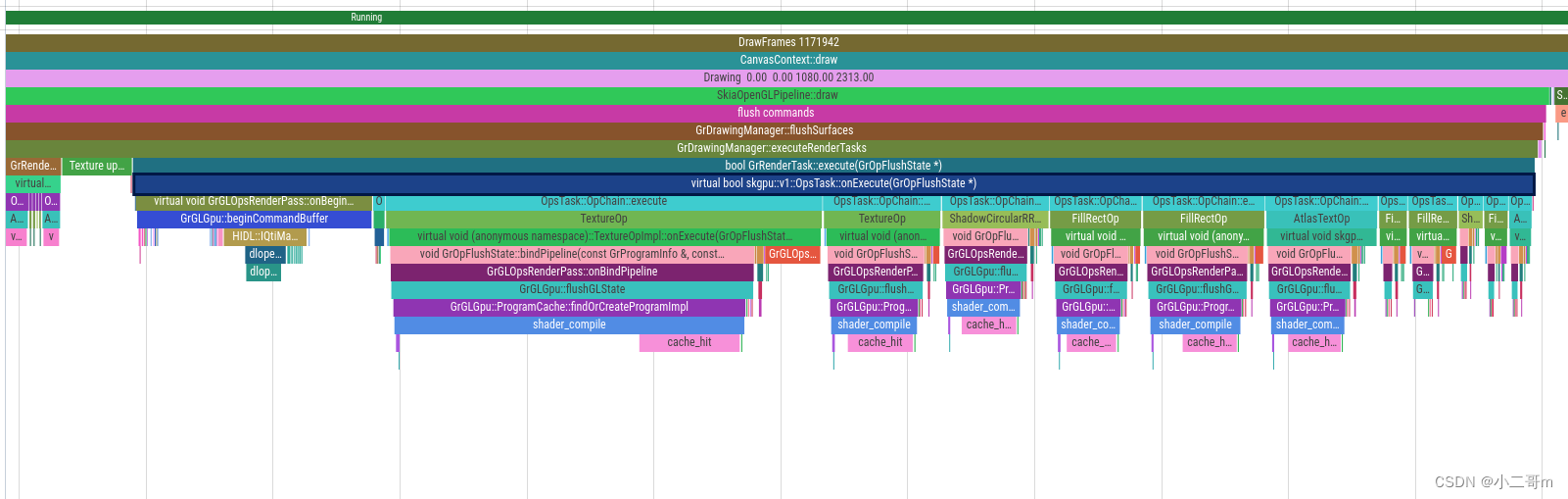

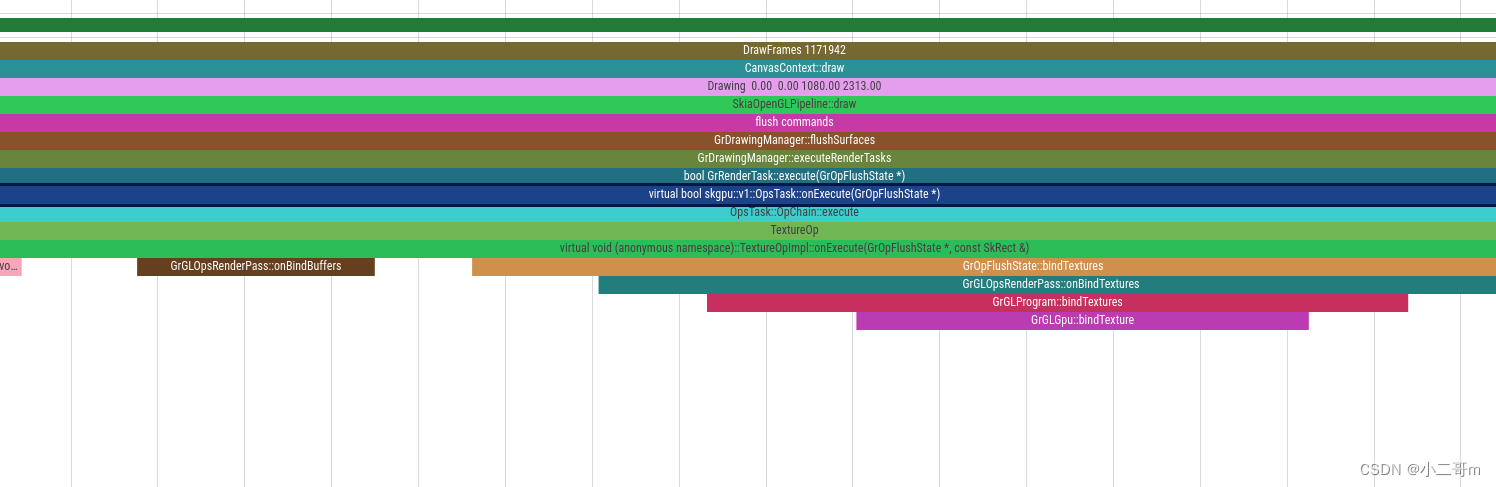
基本流程为:
- 创建GrProgramInfo
- 调用GrOpFlushState::bindPipelineAndScissorClip
调用堆栈为:GrOpFlushState::bindPipeline->GrGLOpsRenderPass::onBindPipeline->GrGLGpu::flushGLState
flushGLState首先调用 GrGLGpu::ProgramCache::findOrCreateProgram进而调用GrGLGpu::ProgramCache::findOrCreateProgramImpl,在第一次执行时,会调用GrGLProgramBuilder::CreateProgram去创建OpenGL着色器程序
然后调用flushProgram,这里主要调用GLUseProgram,去指定program
然后调用flushBlendAndColorWrite设置blend参数,比如调用GLEnable GR_GL_BLEND启用混合,混合方式取决于glBlendEquation,混合因子取决于glBlendFunc和glBlendColor
调用flushStencil,进而调用set_gl_stencil,这里主要调用glStencilFunc、glStencilMask、glStencilOp等来操作模板缓冲区
调用flushScissorTest开启scissor test
调用flushWindowRectangles制定渲染区域,用于实现多重采样、多视口、多显示器等效果,默认不开启
调用flushRenderTarget,然调用flushRenderTargetNoColorWrites开启SCISSOR_TEST,然后调用didWriteToSurface
didWriteToSurface主要是针对纹理标记是否需要更新- bindBuffers,主要调用GrGLOpsRenderPass::onBindBuffers绑定渲染所需的缓冲区对象,包括顶点缓冲区、索引缓冲区、间接绘制缓冲区等,这些缓冲区是GPU中的内存区域,用于存储顶点数据、索引数据和绘制参数等。在渲染时,需要将这些缓冲区绑定到GPU的对应缓冲区对象上,以便GPU能够访问缓冲区中的数据。
- bindTextures,主要调用GrGLOpsRenderPass::onBindTextures->GrGLProgram::bindTextures->GrGLGpu::bindTexture执行bind纹理
- skgpu::v1::QuadPerEdgeAA::IssueDraw将四边形抗锯齿绘制到画布上,使用GPU进行绘制操作,以提高绘制的质量和效果,首先判断是否是三角形,如果是,则直接调用GrGLOpsRenderPass::onDraw,比如TextureOp

* external/skia/src/gpu/gl/GrGLGpuProgramCache.cpp
sk_sp<GrGLProgram> GrGLGpu::ProgramCache::findOrCreateProgram(GrDirectContext* dContext,
const GrProgramInfo& programInfo) {
const GrCaps* caps = dContext->priv().caps();
GrProgramDesc desc = caps->makeDesc(/*renderTarget*/nullptr, programInfo);
if (!desc.isValid()) {
GrCapsDebugf(caps, "Failed to gl program descriptor!\n");
return nullptr;
}
Stats::ProgramCacheResult stat;
sk_sp<GrGLProgram> tmp = this->findOrCreateProgramImpl(dContext, desc, programInfo, &stat);
if (!tmp) {
fStats.incNumInlineCompilationFailures();
} else {
fStats.incNumInlineProgramCacheResult(stat);
}
return tmp;
}
GrGLProgramBuilder类的CreateProgram方法是用于创建OpenGL着色器程序的方法。它接收一个GrGLProgramDesc对象作为参数,该对象包含了着色器程序的描述信息,例如着色器代码、Uniform变量列表、Attribute变量列表等。CreateProgram方法会根据GrGLProgramDesc对象中的信息,创建一个OpenGL着色器程序,并返回一个指向该程序的指针
- submit
SkSurface_Gpu::flushAndSubmit->GrDirectContext::submit->GrGpu::submitToGpu
- 调用incNumSubmitToGpus,增加一个计数器,以跟踪提交次数
- 调用GrRingBuffer::startSubmit,创建SubmitData,调用GrGLGpu::addFinishedProc提交数据fFinishCallbacks中, 在onSubmitToGpu中使用
- 调用GrGLGpu::onSubmitToGpu,主要是调用GrGLGpu::flush,执行glFlush,将所有已提交但未执行的命令立即发送到 GPU 执行,而不会等待 GPU 执行完成。该函数会立即返回,而不会阻塞调用线程
external/skia/src/gpu/GrGpu.cpp
bool GrGpu::submitToGpu(bool syncCpu) {
// 增加一个计数器,以跟踪提交次数
this->stats()->incNumSubmitToGpus();
// 清除缓冲区
if (auto manager = this->stagingBufferManager()) {
manager->detachBuffers();
}
// 调用GrRingBuffer::startSubmit,创建SubmitData,调用GrGLGpu::addFinishedProc提交数据fFinishCallbacks中,
// 在onSubmitToGpu中使用
if (auto uniformsBuffer = this->uniformsRingBuffer()) {
uniformsBuffer->startSubmit(this);
}
bool submitted = this->onSubmitToGpu(syncCpu);
this->callSubmittedProcs(submitted);
this->reportSubmitHistograms();
return submitted;
}
送显流程
SkiaOpenGLPipeline::swapBuffers调用EglManager::swapBuffers,然后调用eglSwapBuffersWithDamageKHR进而通过libGLESv2_adreno.so->eglSubDriverAndroid.so->libnativewindow.so的ANativeWindow_queueBuffer方法,进而去调入android::Surface::hook_queueBuffer
其中ibGLESv2_adreno.so、eglSubDriverAndroid.so为厂商驱动,无代码
BufferQueueProducer::queueBuffer流程
- 从QueueBufferInput中获取有关缓冲区的各种信息(如宽度、高度、数据空间、裁剪区域、缩放模式、变换等),并检查这些信息是否合法,并检查裁剪区域是否在缓冲区内
- 然后,它在BufferQueue中查找空闲的槽位,将缓冲区插入到该槽位中,并将缓冲区的相关信息存储到一个BufferItem对象中。如果队列为空,则直接将该BufferItem对象插入到队列中;否则,它需要检查队列中最后一个缓冲区是否可丢弃,如果是,则用新的缓冲区替换掉它;否则,将新的缓冲区直接插入到队列尾部
- 调用BLASTBufferItemConsumer::addAndGetFrameTimestamps添加历史记录
- BLASTBufferQueue::onFrameAvailable
- lastQueuedFence->waitForever
lastQueuedFence存了最后一个queueBuffer的fence,这样下一个queueBuffer调用就可以限制缓冲区的生产
skia中打印trace方式
ATRACE_ANDROID_FRAMEWORK_ALWAYS("SurfaceDrawContext::drawTexturedQuad");
打印堆栈方式
#include <utils/CallStack.h>
static void debug_stack() {
android::CallStack stack("zzh");
}
耗时分析
- Vulkan执行QueueSubmit耗时,可以看到QueueSubmit循环遍历了三次
* external/vulkan-validation-layers/layers/generated/chassis.cpp
VKAPI_ATTR VkResult VKAPI_CALL QueueSubmit(
VkQueue queue,
uint32_t submitCount,
const VkSubmitInfo* pSubmits,
VkFence fence) {
auto layer_data = GetLayerDataPtr(get_dispatch_key(queue), layer_data_map);
bool skip = false;
for (auto intercept : layer_data->object_dispatch) {
auto lock = intercept->write_lock();
skip |= intercept->PreCallValidateQueueSubmit(queue, submitCount, pSubmits, fence);
if (skip) return VK_ERROR_VALIDATION_FAILED_EXT;
}
for (auto intercept : layer_data->object_dispatch) {
auto lock = intercept->write_lock();
intercept->PreCallRecordQueueSubmit(queue, submitCount, pSubmits, fence);
}
VkResult result = DispatchQueueSubmit(queue, submitCount, pSubmits, fence);
for (auto intercept : layer_data->object_dispatch) {
auto lock = intercept->write_lock();
intercept->PostCallRecordQueueSubmit(queue, submitCount, pSubmits, fence, result);
}
return result;
}
最初的调用者为GrVkPrimaryCommandBuffer::submitToQueue
* external/skia/src/gpu/ganesh/vk/GrVkCommandBuffer.cpp
bool GrVkPrimaryCommandBuffer::submitToQueue(
GrVkGpu* gpu,
VkQueue queue,
SkTArray<GrVkSemaphore::Resource*>& signalSemaphores,
SkTArray<GrVkSemaphore::Resource*>& waitSemaphores) {
SkASSERT(!fIsActive);
ATRACE_ANDROID_FRAMEWORK_ALWAYS("GrVkPrimaryCommandBuffer::submitToQueue");
VkResult err;
if (VK_NULL_HANDLE == fSubmitFence) {
VkFenceCreateInfo fenceInfo;
memset(&fenceInfo, 0, sizeof(VkFenceCreateInfo));
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
GR_VK_CALL_RESULT(gpu, err, CreateFence(gpu->device(), &fenceInfo, nullptr,
&fSubmitFence));
if (err) {
fSubmitFence = VK_NULL_HANDLE;
return false;
}
} else {
// This cannot return DEVICE_LOST so we assert we succeeded.
GR_VK_CALL_RESULT(gpu, err, ResetFences(gpu->device(), 1, &fSubmitFence));
SkASSERT(err == VK_SUCCESS);
}
int signalCount = signalSemaphores.size();
int waitCount = waitSemaphores.size();
bool submitted = false;
if (0 == signalCount && 0 == waitCount) {
// This command buffer has no dependent semaphores so we can simply just submit it to the
// queue with no worries.
submitted = submit_to_queue(
gpu, queue, fSubmitFence, 0, nullptr, nullptr, 1, &fCmdBuffer, 0, nullptr,
gpu->protectedContext() ? GrProtected::kYes : GrProtected::kNo);
} else {
SkTArray<VkSemaphore> vkSignalSems(signalCount);
for (int i = 0; i < signalCount; ++i) {
if (signalSemaphores[i]->shouldSignal()) {
this->addResource(signalSemaphores[i]);
vkSignalSems.push_back(signalSemaphores[i]->semaphore());
}
}
SkTArray<VkSemaphore> vkWaitSems(waitCount);
SkTArray<VkPipelineStageFlags> vkWaitStages(waitCount);
for (int i = 0; i < waitCount; ++i) {
if (waitSemaphores[i]->shouldWait()) {
this->addResource(waitSemaphores[i]);
vkWaitSems.push_back(waitSemaphores[i]->semaphore());
vkWaitStages.push_back(VK_PIPELINE_STAGE_ALL_COMMANDS_BIT);
}
}
submitted = submit_to_queue(gpu, queue, fSubmitFence, vkWaitSems.size(),
vkWaitSems.begin(), vkWaitStages.begin(), 1, &fCmdBuffer,
vkSignalSems.size(), vkSignalSems.begin(),
gpu->protectedContext() ? GrProtected::kYes : GrProtected::kNo);
if (submitted) {
for (int i = 0; i < signalCount; ++i) {
signalSemaphores[i]->markAsSignaled();
}
for (int i = 0; i < waitCount; ++i) {
waitSemaphores[i]->markAsWaited();
}
}
}
if (!submitted) {
// Destroy the fence or else we will try to wait forever for it to finish.
GR_VK_CALL(gpu->vkInterface(), DestroyFence(gpu->device(), fSubmitFence, nullptr));
fSubmitFence = VK_NULL_HANDLE;
return false;
}
return true;
}
- Vulkan执行allocateImageMemory耗时
这里没有采用info.pool,而是采用while循环等待分配vma内存,pool的使用参考external/angle/third_party/vulkan_memory_allocator/src/Tests.cpp,调用vmaCreatePool,在VulkanAMDMemoryAllocator.freeMemory或者析构时,调用 vmaDestroyPool
* external/skia/src/gpu/vk/VulkanAMDMemoryAllocator.cpp
VkResult VulkanAMDMemoryAllocator::allocateImageMemory(VkImage image,
uint32_t allocationPropertyFlags,
skgpu::VulkanBackendMemory* backendMemory) {
TRACE_EVENT0_ALWAYS("skia.gpu", TRACE_FUNC);
VmaAllocationCreateInfo info;
info.flags = 0;
info.usage = VMA_MEMORY_USAGE_UNKNOWN;
info.requiredFlags = VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT;
info.preferredFlags = 0;
info.memoryTypeBits = 0;
info.pool = VK_NULL_HANDLE;
info.pUserData = nullptr;
if (kDedicatedAllocation_AllocationPropertyFlag & allocationPropertyFlags) {
info.flags |= VMA_ALLOCATION_CREATE_DEDICATED_MEMORY_BIT;
}
if (kLazyAllocation_AllocationPropertyFlag & allocationPropertyFlags) {
info.requiredFlags |= VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT;
}
if (kProtected_AllocationPropertyFlag & allocationPropertyFlags) {
info.requiredFlags |= VK_MEMORY_PROPERTY_PROTECTED_BIT;
}
VmaAllocation allocation;
VkResult result = vmaAllocateMemoryForImage(fAllocator, image, &info, &allocation, nullptr);
if (VK_SUCCESS == result) {
*backendMemory = (VulkanBackendMemory)allocation;
}
return result;
}
* external/skia/vma_android/include/vk_mem_alloc.h
VMA_CALL_PRE VkResult VMA_CALL_POST vmaAllocateMemoryForImage(
VmaAllocator allocator,
VkImage image,
const VmaAllocationCreateInfo* pCreateInfo,
VmaAllocation* pAllocation,
VmaAllocationInfo* pAllocationInfo)
{
VMA_ASSERT(allocator && image != VK_NULL_HANDLE && pCreateInfo && pAllocation);
VMA_DEBUG_LOG("vmaAllocateMemoryForImage");
VMA_DEBUG_GLOBAL_MUTEX_LOCK
VkMemoryRequirements vkMemReq = {};
bool requiresDedicatedAllocation = false;
bool prefersDedicatedAllocation = false;
allocator->GetImageMemoryRequirements(image, vkMemReq,
requiresDedicatedAllocation, prefersDedicatedAllocation);
VkResult result = allocator->AllocateMemory(
vkMemReq,
requiresDedicatedAllocation,
prefersDedicatedAllocation,
VK_NULL_HANDLE, // dedicatedBuffer
image, // dedicatedImage
UINT32_MAX, // dedicatedBufferImageUsage
*pCreateInfo,
VMA_SUBALLOCATION_TYPE_IMAGE_UNKNOWN,
1, // allocationCount
pAllocation);
if(pAllocationInfo && result == VK_SUCCESS)
{
allocator->GetAllocationInfo(*pAllocation, pAllocationInfo);
}
return result;
}
VkResult VmaAllocator_T::AllocateMemory(
const VkMemoryRequirements& vkMemReq,
bool requiresDedicatedAllocation,
bool prefersDedicatedAllocation,
VkBuffer dedicatedBuffer,
VkImage dedicatedImage,
VkFlags dedicatedBufferImageUsage,
const VmaAllocationCreateInfo& createInfo,
VmaSuballocationType suballocType,
size_t allocationCount,
VmaAllocation* pAllocations)
{
memset(pAllocations, 0, sizeof(VmaAllocation) * allocationCount);
VMA_ASSERT(VmaIsPow2(vkMemReq.alignment));
if(vkMemReq.size == 0)
{
return VK_ERROR_INITIALIZATION_FAILED;
}
VmaAllocationCreateInfo createInfoFinal = createInfo;
VkResult res = CalcAllocationParams(createInfoFinal, requiresDedicatedAllocation, prefersDedicatedAllocation);
if(res != VK_SUCCESS)
return res;
// 这里传递的是VK_NULL_HANDLE,所以执行else逻辑,会执行while循环,直到分配成功
if(createInfoFinal.pool != VK_NULL_HANDLE)
{
VmaBlockVector& blockVector = createInfoFinal.pool->m_BlockVector;
return AllocateMemoryOfType(
createInfoFinal.pool,
vkMemReq.size,
vkMemReq.alignment,
prefersDedicatedAllocation,
dedicatedBuffer,
dedicatedImage,
dedicatedBufferImageUsage,
createInfoFinal,
blockVector.GetMemoryTypeIndex(),
suballocType,
createInfoFinal.pool->m_DedicatedAllocations,
blockVector,
allocationCount,
pAllocations);
}
else
{
// Bit mask of memory Vulkan types acceptable for this allocation.
uint32_t memoryTypeBits = vkMemReq.memoryTypeBits;
uint32_t memTypeIndex = UINT32_MAX;
res = FindMemoryTypeIndex(memoryTypeBits, &createInfoFinal, dedicatedBufferImageUsage, &memTypeIndex);
// Can't find any single memory type matching requirements. res is VK_ERROR_FEATURE_NOT_PRESENT.
if(res != VK_SUCCESS)
return res;
do
{
VmaBlockVector* blockVector = m_pBlockVectors[memTypeIndex];
VMA_ASSERT(blockVector && "Trying to use unsupported memory type!");
res = AllocateMemoryOfType(
VK_NULL_HANDLE,
vkMemReq.size,
vkMemReq.alignment,
requiresDedicatedAllocation || prefersDedicatedAllocation,
dedicatedBuffer,
dedicatedImage,
dedicatedBufferImageUsage,
createInfoFinal,
memTypeIndex,
suballocType,
m_DedicatedAllocations[memTypeIndex],
*blockVector,
allocationCount,
pAllocations);
// Allocation succeeded
if(res == VK_SUCCESS)
return VK_SUCCESS;
// Remove old memTypeIndex from list of possibilities.
memoryTypeBits &= ~(1u << memTypeIndex);
// Find alternative memTypeIndex.
res = FindMemoryTypeIndex(memoryTypeBits, &createInfoFinal, dedicatedBufferImageUsage, &memTypeIndex);
} while(res == VK_SUCCESS);
// No other matching memory type index could be found.
// Not returning res, which is VK_ERROR_FEATURE_NOT_PRESENT, because we already failed to allocate once.
return VK_ERROR_OUT_OF_DEVICE_MEMORY;
}
}
- Vulkan执行CreateGraphicsPipelines耗时
GrOpFlushState::bindPipeline
sk_sp<GrVkPipeline> GrVkPipeline::Make(GrVkGpu* gpu,
const GrGeometryProcessor::AttributeSet& vertexAttribs,
const GrGeometryProcessor::AttributeSet& instanceAttribs,
GrPrimitiveType primitiveType,
GrSurfaceOrigin origin,
const GrStencilSettings& stencilSettings,
int numSamples,
bool isHWAntialiasState,
const skgpu::BlendInfo& blendInfo,
bool isWireframe,
bool useConservativeRaster,
uint32_t subpass,
VkPipelineShaderStageCreateInfo* shaderStageInfo,
int shaderStageCount,
VkRenderPass compatibleRenderPass,
VkPipelineLayout layout,
bool ownsLayout,
VkPipelineCache cache) {
VkPipelineVertexInputStateCreateInfo vertexInputInfo;
...
VkPipeline vkPipeline;
VkResult err;
{
TRACE_EVENT0_ALWAYS("skia.shaders", "GrVkPipeline::CreateGraphicsPipelines");
#if defined(SK_ENABLE_SCOPED_LSAN_SUPPRESSIONS)
// skia:8712
__lsan::ScopedDisabler lsanDisabler;
#endif
GR_VK_CALL_RESULT(gpu, err, CreateGraphicsPipelines(gpu->device(), cache, 1,
&pipelineCreateInfo, nullptr,
&vkPipeline));
}
if (err) {
SkDebugf("Failed to create pipeline. Error: %d\n", err);
return nullptr;
}
if (!ownsLayout) {
layout = VK_NULL_HANDLE;
}
return sk_sp<GrVkPipeline>(new GrVkPipeline(gpu, vkPipeline, layout));
}
* external/vulkan-validation-layers/layers/generated/chassis.cpp
VKAPI_ATTR VkResult VKAPI_CALL CreateGraphicsPipelines(
VkDevice device,
VkPipelineCache pipelineCache,
uint32_t createInfoCount,
const VkGraphicsPipelineCreateInfo* pCreateInfos,
const VkAllocationCallbacks* pAllocator,
VkPipeline* pPipelines) {
auto layer_data = GetLayerDataPtr(get_dispatch_key(device), layer_data_map);
bool skip = false;
#ifdef BUILD_CORE_VALIDATION
create_graphics_pipeline_api_state cgpl_state{};
#else
struct create_graphics_pipeline_api_state {
const VkGraphicsPipelineCreateInfo* pCreateInfos;
} cgpl_state;
#endif
cgpl_state.pCreateInfos = pCreateInfos;
for (auto intercept : layer_data->object_dispatch) {
auto lock = intercept->write_lock();
skip |= intercept->PreCallValidateCreateGraphicsPipelines(device, pipelineCache, createInfoCount, pCreateInfos, pAllocator, pPipelines, &cgpl_state);
if (skip) return VK_ERROR_VALIDATION_FAILED_EXT;
}
for (auto intercept : layer_data->object_dispatch) {
auto lock = intercept->write_lock();
intercept->PreCallRecordCreateGraphicsPipelines(device, pipelineCache, createInfoCount, pCreateInfos, pAllocator, pPipelines, &cgpl_state);
}
VkResult result = DispatchCreateGraphicsPipelines(device, pipelineCache, createInfoCount, cgpl_state.pCreateInfos, pAllocator, pPipelines);
for (auto intercept : layer_data->object_dispatch) {
auto lock = intercept->write_lock();
intercept->PostCallRecordCreateGraphicsPipelines(device, pipelineCache, createInfoCount, pCreateInfos, pAllocator, pPipelines, result, &cgpl_state);
}
return result;
}


















 1944
1944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









