







 这篇文章主要介绍了python+selenium爬取微博热搜存入Mysql的实现方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下最终的效果废话不多少,直接上图这里可以清楚的看到,数据库里包含了日期,内容,和网站link下面我们来分析怎么实现使用的库`import` `requests``from` `selenium.webdriver` `import` `Chrome, ChromeOptions``import` `t.
这篇文章主要介绍了python+selenium爬取微博热搜存入Mysql的实现方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下最终的效果废话不多少,直接上图这里可以清楚的看到,数据库里包含了日期,内容,和网站link下面我们来分析怎么实现使用的库`import` `requests``from` `selenium.webdriver` `import` `Chrome, ChromeOptions``import` `t.
这篇文章主要介绍了python+selenium爬取微博热搜存入Mysql的实现方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
最终的效果
废话不多少,直接上图
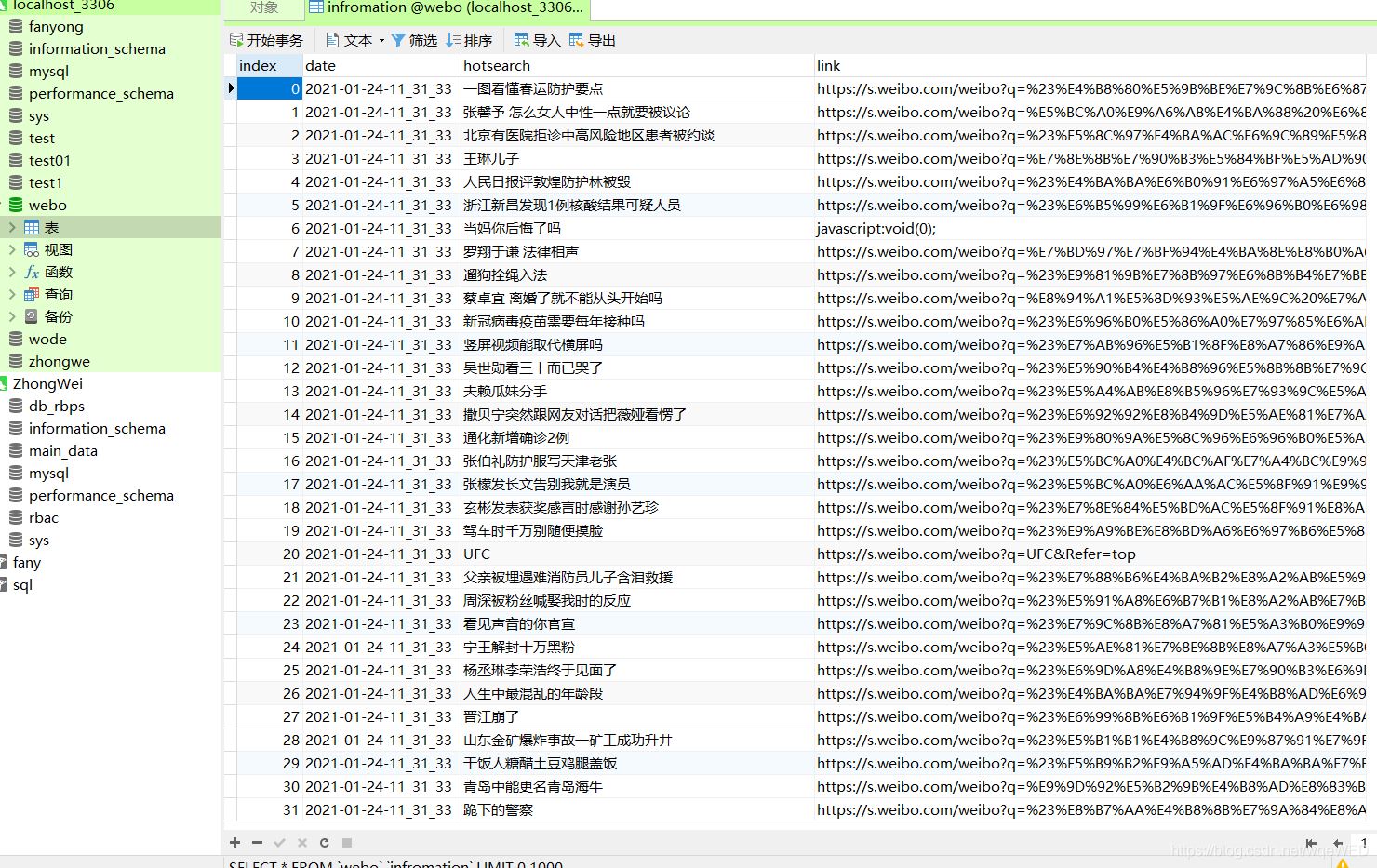
这里可以清楚的看到,数据库里包含了日期,内容,和网站link
下面我们来分析怎么实现
使用的库
`import` `requests`
`from` `selenium.webdriver` `import` `Chrome, ChromeOptions`
`import` `time`
`from` `sqlalchemy` `import` `create_engine`
`import` `pandas as pd`
|
目标分析
这是微博热搜的link:点我可以到目标网页
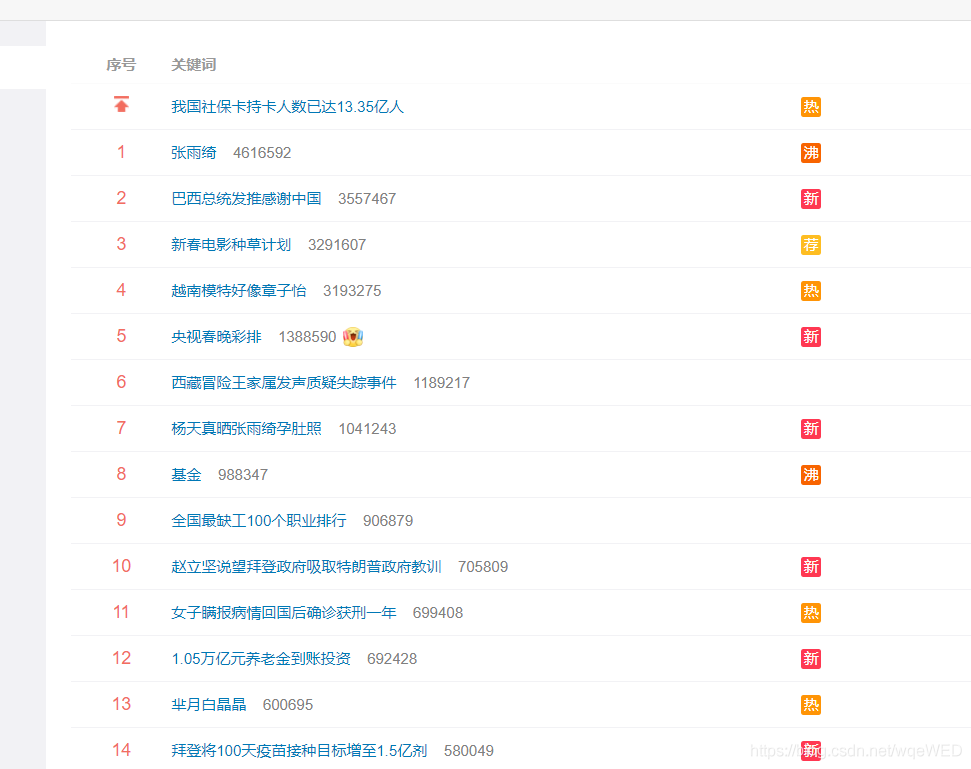
首先我们使用selenium对目标网页进行请求
然后我们使用xpath对网页元素进行定位,遍历获得所有数据
然后使用pandas生成一个Dataframe对像,直接存入数据库
一:得到数据
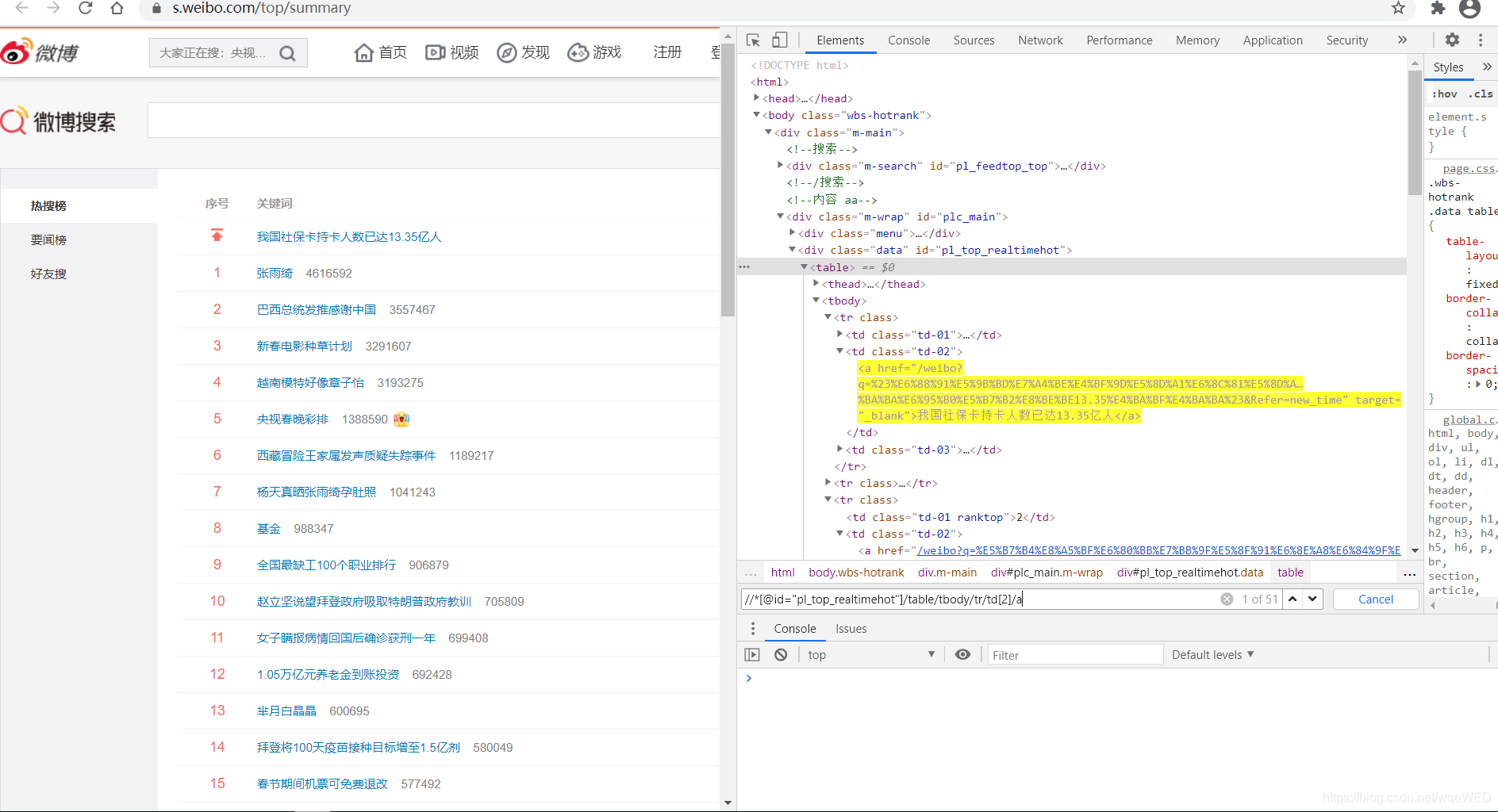
我们看到,使用xpath可以得到51条数据,这就是各热搜,从中我们可以拿到链接和标题内容。最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以价位@762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a')
#得到所有数据
context = [i.text  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









