






内存中的堆和栈
一直使用堆和栈的相关概念,对内存中(操作系统)中的堆与栈和数据结构中的堆与栈一直不求甚解,这次,突然想起这个问题,在此进行一个简单梳理归纳,如有错误,恳请读者指出。
栈(stack)
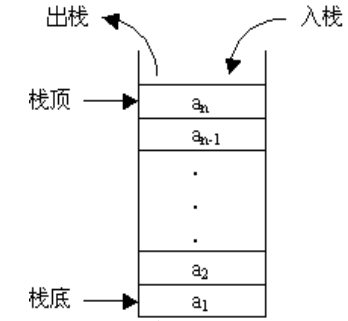
栈是由系统自动分配和回收的内存。例如,编写一个简单的C++程序,main函数内依次调用两个全局函数1、2,压栈顺序大体按照 main函数入栈-> 调用的函数1入栈-> 调用的函数2入栈出栈顺序与入栈相反 可参考函数压栈的过程
栈区位于内存较高的地址,由最高内存地址向低地址扩展(即Push压栈时栈顶指针从最高内存地址向下移动)
栈是一个先进后出(FILO)结构。把数据压入栈时用push进入;当从栈取出数据时用pop取出。栈随着数据被压入或者弹出而增长或者减小。最新压入栈的项被认为是在“栈的顶部”。当从栈中弹出一个项时,我们得到的是位于栈最顶部的那一个(即最新压入的那一个)
在x86体系中,栈顶由堆栈指针寄存器ESP来标记,它是一个32位寄存器,里面存放着最后一个压入栈顶的项的内存地址。正因为有它,我们才能够随时操作到需要的项。需要注意的是,栈顶是朝着地内存方向增长的。
ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈
EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈顶的底部。
在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆(heap)
堆区是向上增长的用于分配程序员申请的内存空间。
操作系统有一个记录空闲内存地址的链表(当然也有可能用位图等其他方法,这里假设使用链表),当系统受到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆(假设使用首次适应(FirstFit)算法)。然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序, 另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。 由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。 也就是说堆会在申请后还要做一些后续的工作这就会引出申请效率的问题。
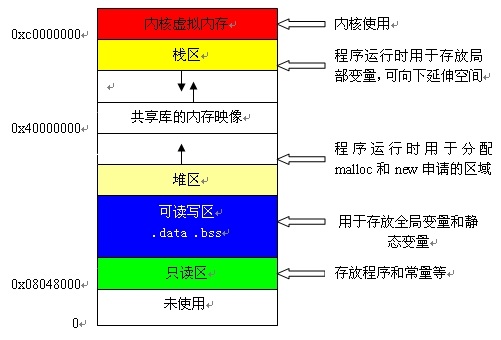
二者分别存储什么以及原因
栈
栈:就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
可以看到栈有一个ESP寄存器管理,从底层就实现了一种“自动化”,而堆似乎并没有额外的东西来帮助管理。
此外,栈的大小需要有一定的限制,栈的增长是向低地址扩展,如照片中看到的,如果栈不断地增加,很可能会与**.bss段**发生碰撞,这是不堪设想的,系统会发出错误并终止程序。
栈应该被看成一个短期存储数据的地方,存在在栈中的数据项没有名字,只是按照后进先出来操作罢了。
栈经常可以用来在寄存器紧张的情况下,临时存储一些数据,并且十分安全。
当寄存器空闲后,我们可以从栈中弹出该数据,供寄存器使用。这种临时存放数据的特性,使得它经常用来存储局部变量,函数参数,上下文环境等。
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。
堆
相反,堆相对于栈,更加强调需要进行控制。常见的就是我们手动申请,手动释放。因此可以分配更大的空间,但开销也会更多。 因此
堆是在程序执行的过程中动态分配的,它最大的特性就是动态性。堆就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
其他存储区
(3)静态存储区:所有的静态对象,全局对象都于静态存储区分配。
(4)常量存储区:这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改。常量字符串都存放在静态存储区,返回的是常量字符串的首地址。
示例代码
int a = 0; 全局初始化区
char *p1; 全局未初始化区
int main ()
{
int b; 栈
char s[] = “abc”;栈
char *p2; 栈
char *p3 = “123456”; 123456\0 在常量区,p3 在栈区
static int c = 0; 全局(静态)初始化区
p1 = (char *)malloc(10);堆
p2 = (char *)malloc (20);堆
}
栈和堆的比较
| 项目 | 栈 | 堆 |
|---|---|---|
| 申请效率 | 效率高,由系统分配,程序员无法控制 | 效率低,程序员通过new分配,速度较慢,容易产生内部碎片 |
| 申请大小 | 最大容量一般由系统预先设定,例如2M | 堆获得的空间较大,较灵活。向高地址扩展,不连续的内存区域(例如用链表存储空闲内存地址) |
| 存储内容 | 在函数调用时,第一个进栈的是主函数中函数调用后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。 当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。 | 一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。 |
| 存取效率 | char s1[] = "运行时赋值";放入栈中,是运行时赋值 | char *s2 = "编译时确定";放入堆中,编译时就确定。(堆中是存储对象的,而在栈中是存放引用) |
深入阅读
参考资料:内存中的堆和栈到底是什么
数据结构中的堆和栈
栈
一种先进后出的数据结构,栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
堆
通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
完全二叉树:若设二叉树的深度为k,除第 k 层外,其它各层 (1~k-1) 的结点数都达到最大个数,第k 层所有的结点都连续集中在最左边,这就是完全二叉树。 (即未满的层只能是最后一层,且节点均连续集中在最左边)














 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









