






 文章详细介绍了维吉尼亚密码的加密原理,包括其多表代换的机制和Kasiski测试法、重合指数分析法在解密中的应用。实验过程展示了如何使用维吉尼亚密码加密文本,以及如何通过Kasiski测试法确定密钥长度和利用重合指数分析法确定密钥具体内容,最终成功解密密文。
文章详细介绍了维吉尼亚密码的加密原理,包括其多表代换的机制和Kasiski测试法、重合指数分析法在解密中的应用。实验过程展示了如何使用维吉尼亚密码加密文本,以及如何通过Kasiski测试法确定密钥长度和利用重合指数分析法确定密钥具体内容,最终成功解密密文。
1.实验原理
1.1维吉尼亚密码
维吉尼亚密码是一种多表代换密码,其密码体制如下:
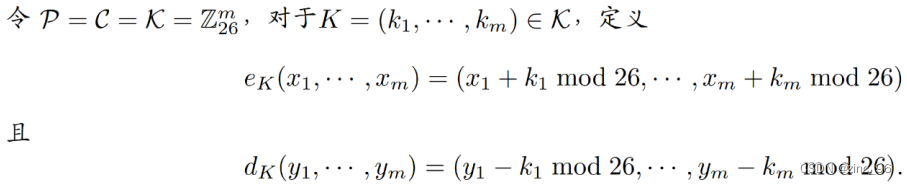
每个密钥相当于一个长度为m的字母串,称为密钥字。维吉尼亚密码一次加密m个明文字母。
1.2Kasiski测试法
在用维吉尼亚密码加密时,明文中的相同字母在密文中通常不会对应相同的字母。但是如果两个相同字母序列 间距恰好是密钥长度的倍数时,就可能产生相同的密文序列。寻找重复出现的字母序列,并求其间距的过程被称为 Kasiski 测试法。
Kasiski 测试法利用多表代换密码的弱点进行解密,相同的明文字母序列,在明文序列中间隔距离为密钥长度 的倍数时,则明文字母序列对应的密文字母序列也必相同;反之相同的概率很大。因此如果将密文中相同字母序列 找出来,并对它们的间隔距离进行分析,找出它们的最大公因子,那么这个数很可能就是密钥长度。
1.3重合指数分析法
在一串无规律英文中随意抽取两个字母,由于每个字母被抽到的概率相同,因此抽取的两个字母相同的概率为 26*(1/26)^2=0.0385。但如果是从一篇文章中抽取,此时概率会变成 P(A)^2+P(B)^2+…+P(Z)^2=0.065,这种特性是破译维吉尼亚密码的关键之一。
单表代换密码加密过的密文,其重合指数接近于0.065,而多表代换密码加密过的密文,其重合指数更接近于0.038。但如果我们把维吉尼亚密码以密钥长度m为步长,分割为m组以同密钥加密的密文串,那么维吉尼亚密码加密的密文就会被简化为 m 组单表代换密码加密的密文,并且每一组重合指数都应该接近于0.065。
2.实验过程
2.1使用维吉尼亚密码加密
根据维吉尼亚密码的密码体制编写加密程序,输入一段适当长度的纯英文字符串 key 作为密钥,输入一个存放 待加密明文的文件 plaintext.txt,将明文去除英文以外符号并且转换为全大写,将密文存放在文件 cipher.txt 中 输出。得到密文为: KNVZIAKNZYNKJKVOERZLVCYGKCVCRTKZFYVKZLPULYVGIIYLFXLMCOEKJYPULRWOEJGRVTKEFLZZZLPULCRTKZFLZTULRACZNOKNFZYKIVVUGRVEFAIIRXVKIUIZYKNUIRUOEMVTVXRRPULRCIVXKGZTCESKRHCKKUUUJUSAKZYKFVGUJOKKZYRRJUKXLKZLPULRFUBLFXKNVKOZIGFXUOEGIEZTKNVUIJZTRXPEFAIIRTKXROEEFAIYVRWZFYVKZZKNZYSXZIBRREVXJKVYTGKNVJIGCYNOKNZTGOVIVYFLSXZIBZYKHAVYKOFTZYTGEEFATGEEFAJKVZYKVDKXRUIJZTRXPYPTTNIUEOTOKEKNRZVDZYKYZTFAICFXCJKNVVVXWKTZZUEUWZYKLTZBVXJKZTRIKOFTKNVKOZIGFXUOEGIESKRAKEFLEGKAIKKNVOEIIKUOSRVSZXRICKFLYADGERZLVZFSVOKYRRCGDGKZVXFLZTKKEZZUEZYKIKZYJUDATNKUSKXXRZVLLRWUIYFSLIYZFHVOEGNKRHFAKRZLVOJVIKTOFAJGEJVDKXRUIJZTRXPVLZPULXRZKKEZZUEUEZYOJLRIKGEJCOKZCKFXUOEGIEKNZTXYNOCRKGBKFTRCYUCKEKNSVGEOEM
2.2使用 Kakiski 测试法确定密钥长度
编写程序循环遍历密文串寻找长度为 3 并且重复出现 3 次及以上的相同字母序列,输出它们在密文串中的位置。实验结果如下:
由实验结果可以看出,共有 9 种 3 位字母序列重复出现 3 次及以上,分别分析它们的间距,如“VXU”的 3 次出现位置的间距为 330、78;“LYO”的 5 次出现位置的间距为 120、12、78、6……等等,分析可知所有间距的最大 公因数为 6,因此猜测密钥长度为 6 的可能性极大。
2.3使用重合指数分析法法确定密钥具体内容
以 2.2 中猜测的密钥长度 6 为步长将密文分割为 6 组子密文,分别求出它们的重合指数为:0.0652, 0.0550, 0.0727, 0.0582, 0.0727, 0.0700,它们的平均值为 0. 06565,说明密钥长度确实为 6。
6 组子密文串由 6 个字母分别加密而成,因此遍历 26 个字母分别进行反代换,比较哪个字母作为密钥时子密 文串的重合指数最接近 0.065。实验结果如下: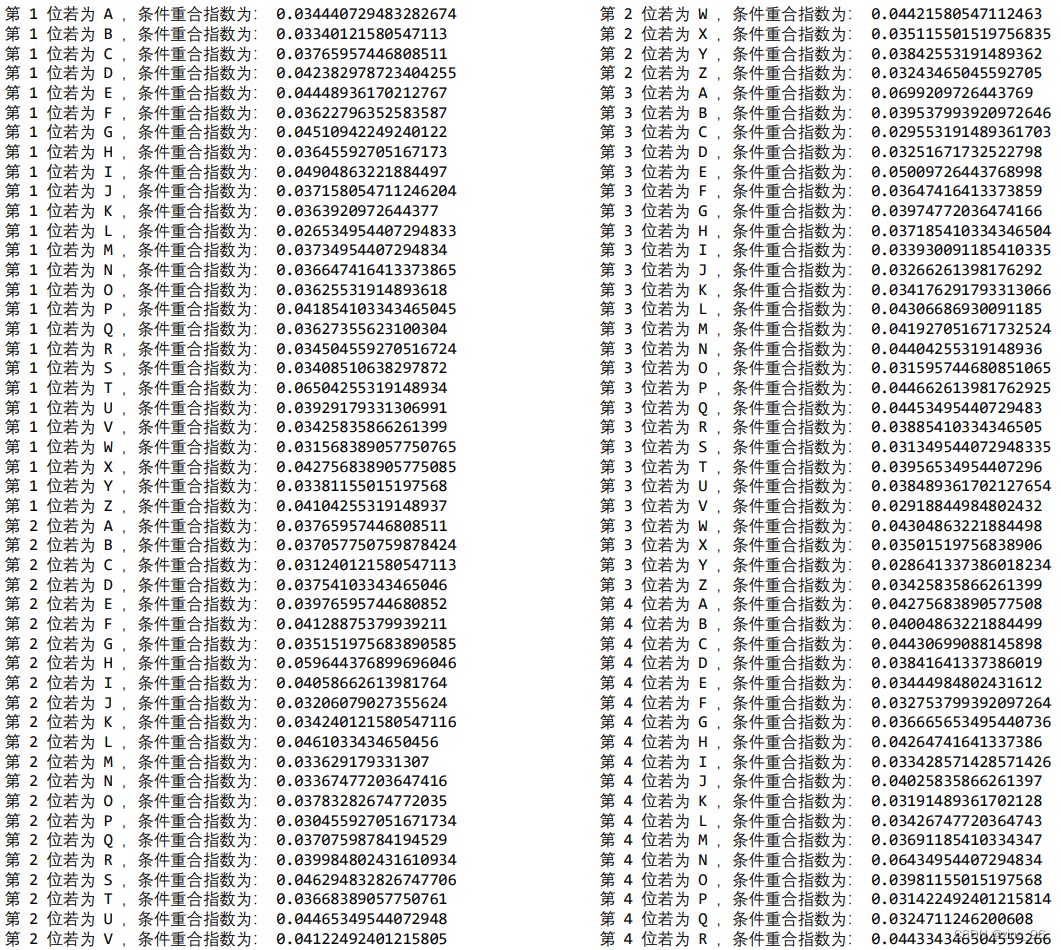
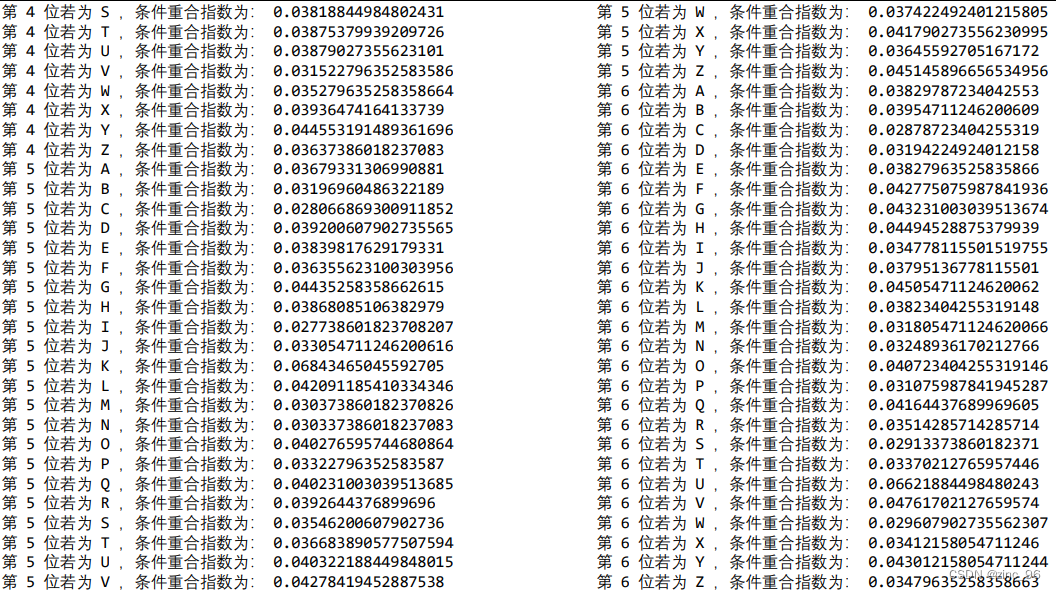 由实验结果可知,当 6 位密钥分别为 t、h、a、n、k、u 时6个子密文串的重合指数最接近于 0.065,假设密钥为 thanku,翻译密文,得到明文为:
由实验结果可知,当 6 位密钥分别为 t、h、a、n、k、u 时6个子密文串的重合指数最接近于 0.065,假设密钥为 thanku,翻译密文,得到明文为:
至此,维吉尼亚密码破解完成。
3.实验总结
本次实验完成了维吉尼亚密码的实现与分析。
不难发现,在使用维吉尼亚密码加密时,密钥长度越长,破译难度越大,并且破译难度和密钥是否有实际意义 无关。维吉尼亚密码的密钥空间大小为26^m,所以即使 m 的值很小,使用穷尽密钥搜索方法也需要很长的时间,但使用计算机能大幅降低计算时间。
维吉尼亚密码作为多表代换密码固然比单表代换密码更为安全,但安全程度有限,其最大的弱点就是可以通过 Kasiski 测试法化为多个单表代换密码,从而将破译难度降为近似于单表代换密码。此外,如果密文越长,就会导致重复出现的字母序列越多,进而更容易确定密钥长度从而完成破译。因此,增加密钥长度和缩短密文长度都是能提高维吉尼亚密码安全程度的方法。
4.代码清单
2.1:
import re
print('本程序的功能为使用维吉尼亚密码加密英文')
print('请确定该程序的文件目录下有名为 plaintext.txt 的文件用来存放待加密的英文')
key = input('请输入一个适当长度的纯英文字符串作为密钥:')
key = key.upper()
# 从 plaintext.txt 文件中读取待加密英文
PlainTextFile = open('plaintext.txt', 'r')
PlainText_temp = PlainTextFile.read()
# 格式化明文串,英文字符转化为大写,去除英文字符以外的所有字符
PlainText_temp = PlainText_temp.upper()
PlainText = ""
for i in range(0, len(PlainText_temp)):
if re.search('[A-Z]', PlainText_temp[i]):
PlainText += PlainText_temp[i]
# 进行加密,得到密文串 Cipher
Cipher = ""
for i in range(0, len(PlainText)):
Cipher += chr((ord(PlainText[i]) + ord(key[i % len(key)]) - 130) % 26 + 65)
# 将密文串写入 cipher.txt 文件
CipherFile = open('cipher.txt', 'w+')
CipherFile.write(Cipher)2.2&2.3:
print('本程序的功能为破解维吉尼亚密码')
print('请确定该程序的文件目录下有名为 cipher.txt 的文件用来存放使用维吉尼亚密码加密过的英文')
# 从文件中读取密文串 Cipher
CipherFile = open('Cipher.txt', 'r')
Cipher = CipherFile.read()
print('利用 Kasiski 测试法确定密钥长度')
# 寻找重复三字密文段
rst = []
for i in range(len(Cipher) - 2):
a = Cipher.count(Cipher[i] + Cipher[i + 1] + Cipher[i + 2])
if a >= 3:
rst.append(Cipher[i] + Cipher[i + 1] + Cipher[i + 2])
# 格式化找到的重复三字密文段
rst = list(set(rst))
for letter in rst:
for i in range(len(Cipher) - 2):
if Cipher[i] + Cipher[i + 1] + Cipher[i + 2] == letter:
print(i, letter)
print('利用重合指数法确定密钥具体内容')
CipherLen = int(input('请输入您根据 Kasiski 测试法确定的密钥长度:'))
# 建立使用相同密钥加密的字符串 Y
Y = [[] for i in range(CipherLen)]
for i in range(CipherLen):
m = 0
while m * CipherLen + i < len(Cipher):
Y[i].append(Cipher[m * CipherLen + i])
m = m + 1
# 建立字母表 alphabet
alphabet = list('ABCDEFGHIJKLMNOPQRSTUVWXYZ')
# 计算重合指数 I_c
I_c = []
for i in range(CipherLen):
p = 0
for letter in alphabet:
p += ((Y[i].count(letter) * (Y[i].count(letter) - 1)) / ((len(Y[i])) * (len(Y[i]) - 1)))
I_c.append(p)
print('六个子密文串的重合指数分别为:\n', I_c)
print('六个子密文串的重合指数的平均值为:\n', sum(I_c) / CipherLen)
# 建立自然语言下 26 个英文字母出现频率表 p
p = [0.082, 0.015, 0.028, 0.043, 0.127, 0.022, 0.020, 0.061, 0.07, 0.002, 0.008, 0.04, 0.024, 0.067, 0.075, 0.019, 0.001, 0.06, 0.063, 0.091, 0.028, 0.01, 0.023, 0.001, 0.02, 0.001]
# 遍历 26 个英文字母,求对应的条件重合指数,找出具体密钥
for i in range(CipherLen):
for g in range(26):
M_g = 0
for letter in alphabet:
M_g += p[ord(letter) - 65] * Y[i].count(chr((ord(letter) - 65 + g) % 26 + 65)) * CipherLen / len(Cipher)
print('第', i + 1, '位若为', chr(g + 65), ',条件重合指数为:', M_g)
















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









