







python网络爬虫
写在前面
本节的主旨在于: 通过介绍python2.7 BeautifulSoup+urllib2爬虫技术,帮助快速掌握基本爬虫技术,形成一条主线,能为自己的实验构造基础数据。在需要相关基础知识的地方,文中给出的链接地址,都是很好的教程,可以参考。这里学习的爬虫技术适用于数据挖掘、自然语言处理等需要从外部挖掘数据的学科。
1.什么是网络爬虫?
网络爬虫(Web crawler)也叫蚂蚁(ant),自动检索工具(automatic indexer)。简单来说,就是通过不断请求各个网络资源,然后整理它们,形成自己的数据目录。具体的展开叙述可以参考wiki 网络蜘蛛。
这里用自己的话表达就是: 网络爬虫 = {一组初始url,一组筛选数据规则,一组具体实施的技术}
简单网络爬虫的算法伪代码如下(参考资stackoverflow):
一个未访问列表
一个已经访问列表
以及一组判定你对该资源感兴趣的规则
while 未访问url列表不为空:
从未访问url列表取出一个URL
记录下URL页面上你感兴趣的东西
如果它是HTML:
解析出页面的链接links
对于每一个链接link:
如果它符合你的规则,并且不在你的已访问列表中或者未访问列表中:
将链接添加到未访问列表网络爬虫技术必须要注意几点(参考自:A few scraping rules):
- 重视网站的版权声明。网站拥有并管理他们的数据,你应该在爬取一个网站之前查看网站的版权条款。
- 不要太暴力。机器访问速度远远高于人,不要以粗暴地方式攻击别人的服务器。
- 爬虫结果受限于网站结构。随着网页改动,网站数据更改和维护,原本工作的代码可能要随之变动。
2.Python爬虫技术主要有哪些?
Python语言中主要的爬虫库包括:
更多内容可以参考: stackoverflow获取更多库支持。
我们主要还是关注如何方便我们达到目的即可,本节主要使用BeautifulSoup来展开后面的示例。
使用BeautifulSoup时,通过利用urllib2读取网页内容,然后由BeautifulSoup解析内容。BeautifulSoup的中文文档地址: BeautifulSoup中文.
3. 爬虫技术关键点
3.1 寻找到我们想要的内容
如何在找到的html或者xml中查找我们感兴趣的内容,主要有两个方面。
第一如何获取网页中对应的节点。根据不同库的实现不同,稍微有些不同。但是基本上都包括:
遍历DOM对象,利用标签过滤,例如a,选择所有的链接. DOM以树的形式组织整个HTML文档,例如简单DOM树如下:
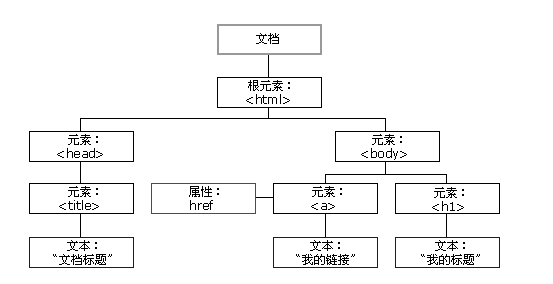
如何学会使用DOM对象,可以参考: HTML DOM.
利用CSS选择器过滤对象,例如p > span ,选择段落的直接子标签span.可以参考 W3school CSS 选择器.
利用正则表达式过滤标签内容,从而获得我们感兴趣的文本,关于如何使用正则表达式,可以参考:Python正则表达式指南.
3.2 爬虫的一些技巧
身份伪装
个别网站不允许我们爬取,需要伪装成浏览器才可以,通过在请求头中添加浏览器和操作系统信息达到伪装目的。例如csdn网站,如果直接爬取,则容易出现403错误。
数据解压缩
注意使用伪装手段时,需要查看返回的相应头的编码方式,如果没有对gzip类型进行解压缩,那么通常会发生数据无法读取的错误,或者产生:UnicodeDecodeError: 'utf8' codec can't decode byte 0x8b in position 1: invalid start byte错误。
数据编码
python2.7内部默认编码采用ASCII方式,str类型即采用改编码方式,当我们读入网页后,需要解析网页头部,识别编码(当然好的库会自动帮我们完成),这里注意str与unicode之间的转换:
u = u'中文' #显示指定unicode类型对象u
str = u.encode('gb2312') #以gb2312编码对unicode对像进行编码
str1 = u.encode('gbk') #以gbk编码对unicode对像进行编码
str2 = u.encode('utf-8') #以utf-8编码对unicode对像进行编码
u1 = str.decode('gb2312')#以gb2312编码对字符串str进行解码,以获取unicode更多内容,可以参考: cnblog python encode和decode函数说明.
另外,如果使用BeautifulSoup,那么构造BeautifulSoup对象时,可以传入文件句柄或者字符串,文档会被转换为unicode,html标记都会被转换为unicode,BeatifulSoup默认将内容编码视为UTF-8.你可以通过传入unicode来避免这一默认特性.
尤其注意,当解析非utf-8编码的文档,例如gbk时,要注意将文档内容转换为unicode传入,否则出现一些错误,例如:encoding error : input conversion failed due to input error, bytes 0x84 0x31 0x95 0x33.
例如解析gb2312编码文档,可以使用:
response = urllib2.urlopen(url).read().decode('gb2312','ignore')
bs = BeautifulSoup(response)关于这一点,还可以参考:字符的编码和解码 .
发送数据
向网站发送数据方式,通常就是Get和Post两种方式,关于这两种方式,可以参考: HTTP 方法:GET 对比 POST介绍。
使用urllib2时,默认发送数据方式是Post,post发送数据也就是发送字典对象中的键值对,例如示例代码(例子来自:stackoverflow):
import urllib
import urllib2
url = 'http://example.com/...'
values = { 'productslug': 'bar','qty': 'bar' }
data = urllib.urlencode(values)
req = urllib2.Request(url, data)
response = urllib2.urlopen(req)
result = response.read()
print result
当然还有重定向,代理等其他技术,更多内容可以参考:urllib2的使用细节与抓站技巧.
这里给出一个应用了上述部分关键点的,一个利用系统自带的urllib2爬取CSDN官方博客类别列表的示例:
# coding: utf-8
# """获取csdn博客类别列表"""
import urllib2
import gzip
import StringIO
import re
from urllib2 import URLError, HTTPError
def read_data(resp):
# 读取响应内容 如果是gzip类型则解压缩
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO.StringIO(resp.read())
gzip_f = gzip.GzipFile(fileobj=buf)
return gzip_f.read()
else:
return resp.read()
URL = 'http://blog.csdn.net/blogdevteam/'
HEADERS = {
'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:34.0) "
"Gecko/20100101 Firefox/34.0"
, 'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
, 'Accept-Language': "zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3"
, 'Accept-Encoding': "gzip, deflate"
}
req = urllib2.Request(URL, None, HEADERS) # 通过添加头来达到伪装目的
try:
response = urllib2.urlopen(req)
page_content = read_data(response)
encoding = response.headers['content-type'].split('charset=')[-1]
p = re.compile(ur'(<a.*?href=)(.*?category.*?>)(.*)(</a>)') # 解析类别的正则表达式
m = p.findall(page_content.decode(encoding))
if m:
for x in m:
print x[2].encode(encoding)
except URLError, e:
if hasattr(e, 'code'):
print '错误码: ', e.code, ',无法完成请求.'
elif hasattr(e, 'reason'):
print '请求失败: ', e.reason, '无法连接服务器'
else:
print '请求已完成.'
输出结果为:
首页公告栏
专家访谈
使用小技巧
投诉建议
常见问题
网友心声
博客活动
精品下载资源推荐
2011中国移动开发者大会
CSDN官方活动
2011年SD2.0大会
2012 SDCC中国软件开发者大会
2012移动开发者大会
SDCC大会
2013年云计算大会
微软MVP
社区周刊
博客推荐汇总
博文推荐汇总
4.两个示例
下面示例部分我们给出通过使用BeautifulSoup+urllib2库抓取数据的实验。
BeautifulSoup筛选网页标签的关键技术,包括两项。一是使用find,find_all选择标签获取,这个函数的原型为:
find( name , attrs , recursive , text , **kwargs )
可以使用标签名称,属性,以及是否递归搜索,和一些关键字指定的属性。
另一个是通过CSS选择器,select获取标签列表,例如soup.select('p')获取所有段落。
BeautifulSoup中文文档.,给出了很详细的API说明,可以参考。
获取网页数据的关键点:
- 分析网页结构,找到我们所需部分的最简单标志,标志越简单越好,例如CSS选择器标志或者标签标志
- 利用正则表达式或者标签属性对内容进行过滤
- 抓取的效率问题,可以采用多线程等技术
- 正确的序列化抓取的资源,例如写入文件,数据库
4.1 抓取酷狗音乐网站首页音乐排行榜数据
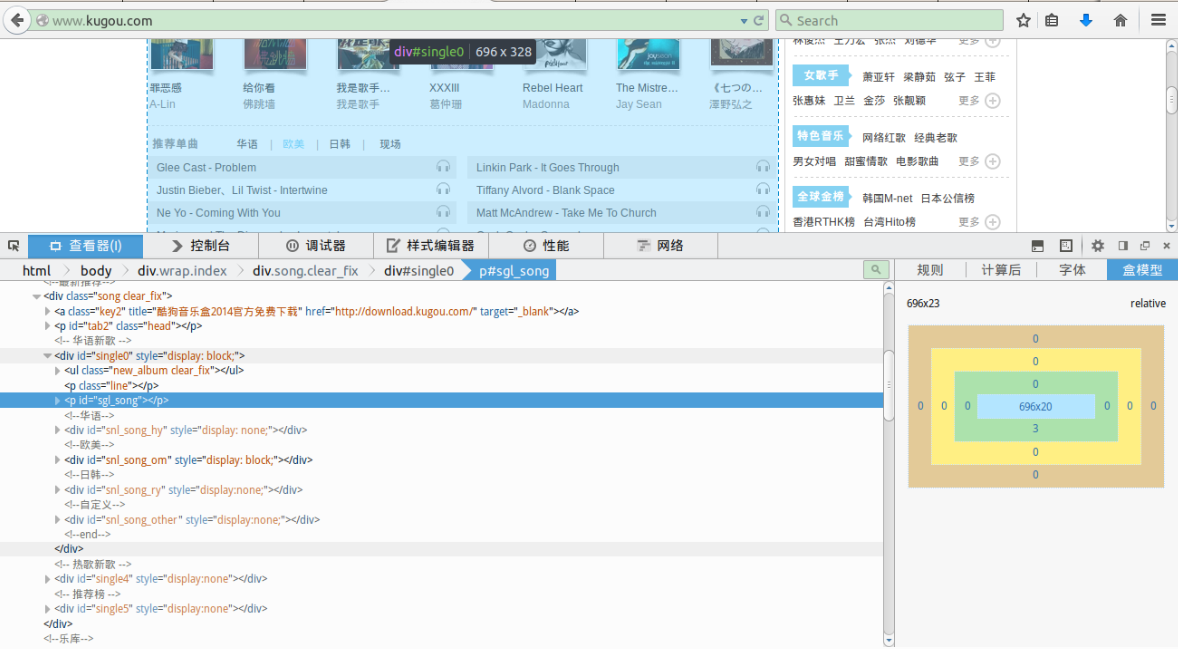
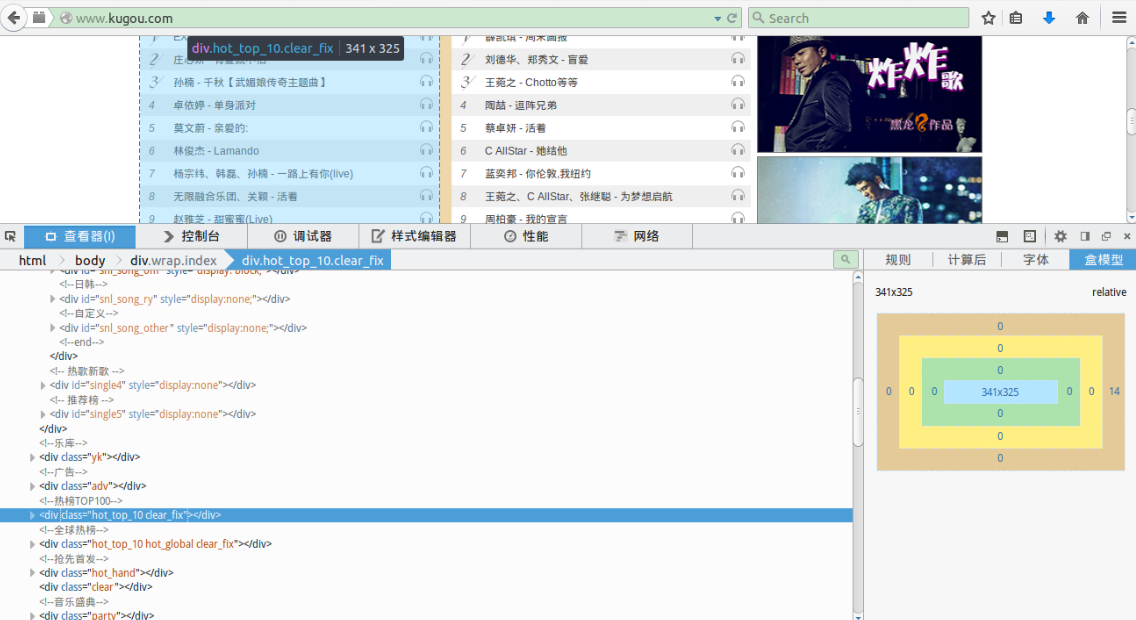
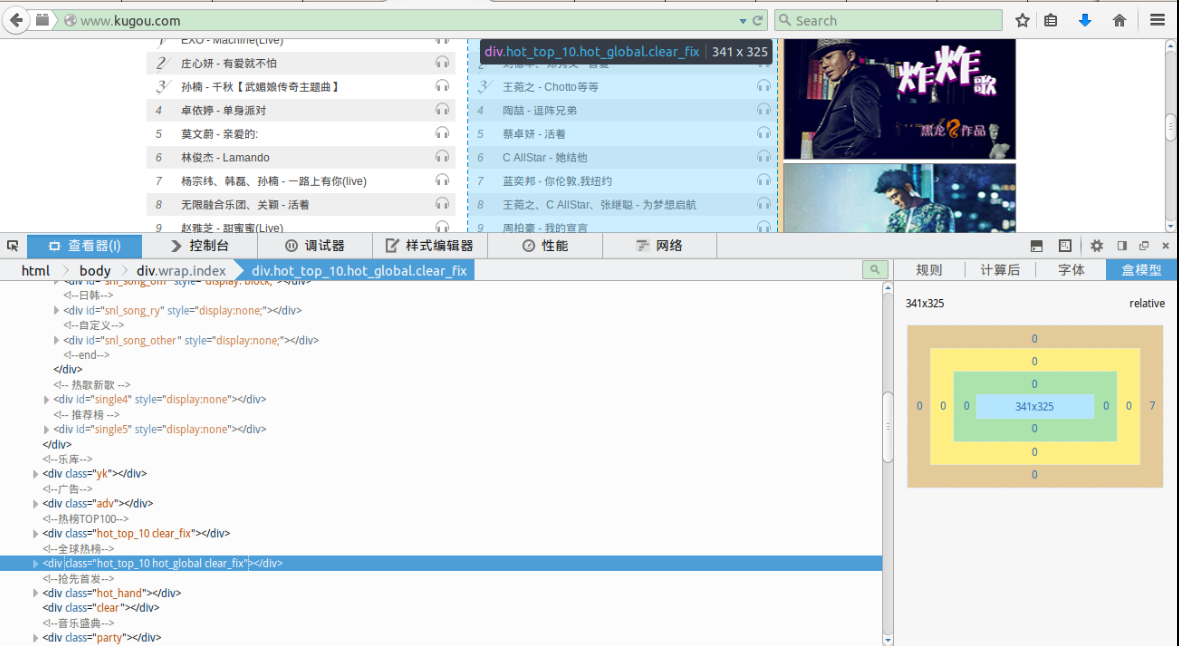
抓取网页数据的第一步便是分析网页结构,分析网页结构可以借助浏览器(Firefox,Google chrome等)的分析工具,在所需要的趋于右键鼠标[查看元素]即可获取该页面元素的对应的选择器和相应代码。
我们查看下酷狗音乐首页的排行榜div,我们要抓取的三个部分的排行榜div如下图所示:
推荐歌曲排行榜:
Top10排行榜:
全球热榜:
这三个区域的共同点在于:
首先一个大div,div下面有一个p,p中包含了这个排行榜里面的小分类,然后下面的div里面有ul具体填写了歌曲信息,你可以通过分析该网页来了解具体细节。
下面是我们的实现代码:
#!/usr/bin/env python
#-*- coding:utf-8 -*-
"""
*********************************************************
获取酷狗音乐首页排行榜列表
依赖于html页面div选择器 如果改动程序可能失效
by wangdq 2015-01-05(http://blog.csdn.net/wangdingqiaoit)
*********************************************************
"""
from bs4 import BeautifulSoup
from urllib2 import urlopen, Request, URLError, HTTPError
import time
def make_soup(url):
# """打开指定url 获取BeautifulSoup对象"""
try:
req = Request(url)
response = urlopen(req)
html = response.read()
except URLError, e:
if hasattr(e, 'code'):
print '错误码: ', e.code, ',无法完成请求.'
elif hasattr(e, 'reason'):
print '请求失败: ', e.reason, '无法连接服务器'
else:
return BeautifulSoup(html)
def get_music(b_soup, sel):
#""" 获取歌曲榜单"""
main_div = b_soup.select(sel)[0]
# 获取类别列表
sum_category = main_div.select('p > strong > a[title]')[0].string
titles = [sum_category+' '+a.string for a in main_div.select('p > span > a[title]')]
index = 0
song_dict = {}
# 逐个解析下层的歌单并加入类别:歌单 字典对象
for div in main_div.find_all('div', recursive=False): # 这里我们不能递归查找
part = div.find_all('span', class_='text')
if part:
song_dict[titles[index]] = part
index += 1
return song_dict
BASE_URL = 'http://www.kugou.com/'
#这是酷狗首页榜单的div选择器
#如果页面变动 需要更改此处
DIV_LIST = [
'div#single0', # 推荐歌曲部分div
'div.clear_fix.hot_top_10', # 热榜top10部分div
'div.clear_fix.hot_global.hot_top_10' # 全球热榜部分div
]
def main():
soup = make_soup(BASE_URL)
if soup is None:
print '抱歉,无法完成抽取任务,即将退出...'
exit()
print '获取时间: '+time.strftime("%Y-%m-%d %H:%M:%S")
for k in DIV_LIST: # 从歌单div逐个解析
for category, items in get_music(soup, k).iteritems(): # 打印类别:歌单字典对象内容
print '*'*20+category+'*'*30
count = 1
for song in items:
print count, song.string
count += 1
print '*'*60
print '获取歌单结束'
if __name__ == "__main__":
main()获取的酷狗首页排行榜结果如下(有删节):
获取时间: 2015-01-06 22:29:11
********************推荐单曲 现场******************************
1 韩红 - 天亮了(Live)
2 A-Lin - 给我一个理由忘记(Live)
...省略
********************推荐单曲 华语******************************
1 王力宏 - 就是现在
2 梁静茹 - 在爱里等你【只因单身在一起主题曲】
...省略
********************推荐单曲 日韩******************************
1 孝琳、San E - Coach Me
2 Hello Venus - Wiggle Wiggle
...省略
********************推荐单曲 欧美******************************
1 Glee Cast - Problem
2 Justin Bieber、Lil Twist - Intertwine
...省略
********************热榜TOP10 最新******************************
1 EXO - Machine(Live)
2 庄心妍 - 有爱就不怕
...省略
********************热榜TOP10 最热******************************
1 筷子兄弟 - 小苹果
2 邓紫棋 - 喜欢你
...
获取歌单结束4.2 抓取免费图库图片资源
下面学习抓取网络上的图片资源,其他资源同理。这里使用免费网站素材CNN的站点进行抓取。
我们在必要的时候需要使用多线程技术,关于多线程的简单使用,不是很复杂,可以参考: Python 多线程教程。
多线程的难点在于如何相应用户键盘Ctrl+C或者系统kill命令的中断,结束线程任务,
关于这一点请参考: Python中用Ctrl+C终止多线程程序的问题解决.
我们首先分析这个网站的结构,如下:
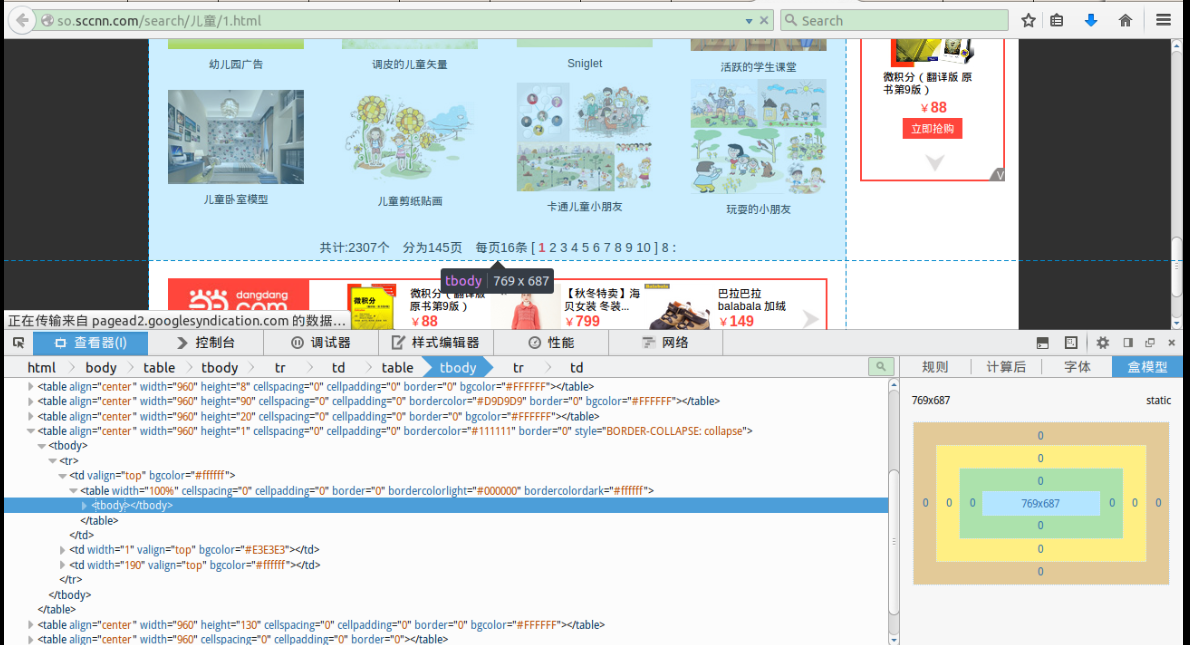
这个网站的搜索关键词就是网页URL中出现的部分,也就是URL = http://so.sccnn.com+儿童+1.html,其中1是当前页号码,图中显示一共有145页,我们需要三个步骤来完成抓取:
第一,获取一个搜索关键词的结果个数包括总数目、页数目;
第二,通过关键词和页数目,拼接URL,解析每个页面包含的图片列表,这个页面很简单,图片主要使用img标签来标注;
第三,当所有图片URL都解析完毕后,开启多个线程下在,并通知用户下载情况。
我们抓取的分页的图片url实际上是小图的url,该网站大图和小图的url格式区别很小,例如:
大图: <img src="http://img.sccnn.com/bimg/337/34697.jpg" alt="婚庆背景板" border="0">
小图: <img src="http://img.sccnn.com//simg/337/34697.jpg" alt="婚庆背景板" border="0">
解析结果数目主要代码如下:
result_string = unicode(result.get_text()).encode('utf-8') # 例如 共计:2307个 分为145页 每页16条
p = re.compile(r'\d+')
count_list = [int(x) for x in p.findall(result_string)] # 计数例如 ['2307', '145', '16']线程使用python的threading库,通知客户端下载情况使用 progress 1.2 ,这个库很简单。
具体实现代码如下:
#!/usr/bin/env python
#-*- coding:utf-8 -*-
"""
*********************************************************
多线程下载素材CNN免费图片 该网站网址: http://so.sccnn.com
by wangdq 2015-01-05(http://blog.csdn.net/wangdingqiaoit)
使用方法:
按照提示输入图片保存路径 例如: /home
提示是否下载大图片时,选择Y可以下载大图片,默认下载小格式图片
要查找图片的关键字即可 例如: 宠物
*********************************************************
"""
from bs4 import BeautifulSoup
from progress.bar import Bar
import urllib2
import os
import re
import threading
import signal
BASE_URL = "http://so.sccnn.com"
is_exit = False # 全局线程结束变量
def make_soup(url):
# """打开指定url 获取BeautifulSoup对象"""
try:
req = urllib2.Request(url)
response = urllib2.urlopen(req)
html = response.read()
except urllib2.URLError, e:
if hasattr(e, 'code'):
print '错误码%d,无法完成请求' % e.code
elif hasattr(e, 'reason'):
print '错误码%d,无法连接服务器' % e.reason
else:
return BeautifulSoup(html)
def join_url(keyword, count):
#"""链接url路径"""
unicode_url = unicode(BASE_URL+'/search/'+keyword+'/'+str(count)+'.html', 'utf-8')
return unicode_url.encode('GB2312')
def load_url(keyword, folder):
#"""搜索关键字 得到图片img元素列表"""
local_url = join_url(keyword, 1)
soup = make_soup(local_url)
img_list = []
if soup is None:
print '无法建立链接",请重试其他关键词'
return img_list
result = soup.find('td', style=True)
if result is None:
print '没有找到任何关于"%s"的图片,请重试其他关键词' % keyword
return img_list
result_string = unicode(result.get_text()).encode('utf-8') # 例如 共计:2307个 分为145页 每页16条
p = re.compile(r'\d+')
count_list = [int(x) for x in p.findall(result_string)] # 计数例如 ['2307', '145', '16']
print '已经找到%d张"%s"图片,共%d页' % (count_list[0], keyword,count_list[1])
url_bar = Bar('正在解析图片地址', max=count_list[1])
for x in range(count_list[1]):
page_soup = make_soup(join_url(keyword, x+1))
images = page_soup.find_all('img', alt=True)
img_list.extend([img for img in images if img.has_attr('src') and img.has_attr('alt')])
url_bar.next()
return img_list
class DownImage(threading.Thread):
#"""下载图片线程类"""
#类属性
folder = "" # 存储路径
bar = None # 通知状态条
is_load_small = True # 默认下载小图
def __init__(self, img_list,):
threading.Thread.__init__(self)
self.img_list = img_list
def run(self):
global is_exit
for img in self.img_list:
if is_exit: # 停止下载工作
break
photo_url = img['src']
photo_name = img['alt']+'.'+photo_url.split('.')[-1]
if not self.is_load_small:
photo_url = re.sub('simg', r'bimg', photo_url) # 下载大图
try:
u = urllib2.urlopen(photo_url)
# 使用图片说明作为图片文件名
with open(os.path.join(self.folder, photo_name), "wb") as local_file:
local_file.write(u.read())
self.bar.next()
u.close()
except (KeyError, urllib2.HTTPError):
print '\t下载图片 "%s" 时出错' % photo_name.encode('utf-8')
def handler(signum, frame):
# """键盘中断或者系统结束信号处理器"""
global is_exit
is_exit = True
print "\n正在取消任务..."
def main():
#"""使用新线程开始获取数据"""
max_thread = 5 # 最多同时开启5个线程下载
image_list = []
threads = []
signal.signal(signal.SIGINT, handler) # Ctrl+C中断信号处理器
signal.signal(signal.SIGTERM, handler) # kill信号处理器
folder = raw_input('请输入图片存储路径:').strip()
if not os.path.exists(folder):
print '文件夹"%s"不存在' % folder
exit()
DownImage.folder = folder
small_or_big = raw_input('是否下载大尺寸图片(默认下载小图片)? Y)是 N)否') or 'N'
if re.match(r'^[Yy]', small_or_big.strip()):
DownImage.is_load_small = False
while not image_list:
key = raw_input('请输入搜索图片的关键词:')
image_list = load_url(key, folder)
try:
down_count = len(image_list)
DownImage.bar = Bar('正在下载图片', max=down_count)
unit_size = len(image_list) / max_thread # 每个线程承担任务量
for i in xrange(0, len(image_list), unit_size):
thread = DownImage(image_list[i:i+unit_size])
thread.setDaemon(True)
thread.start()
threads.append(thread)
while 1: # 主线程等待子线程结束
alive = False
for i in range(len(threads)):
alive = alive or threads[i].isAlive()
if not alive:
break
except threading.ThreadError:
print '抱歉,发生了错误.'
print '\n下载结束!'
if __name__ == "__main__":
print __doc__
main()
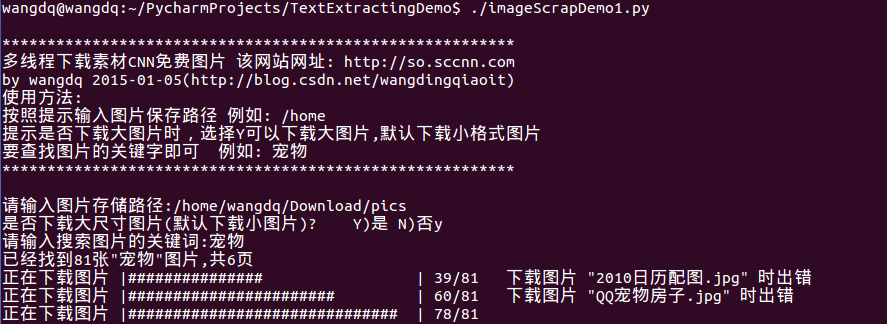
用户键盘终止效果如下图:

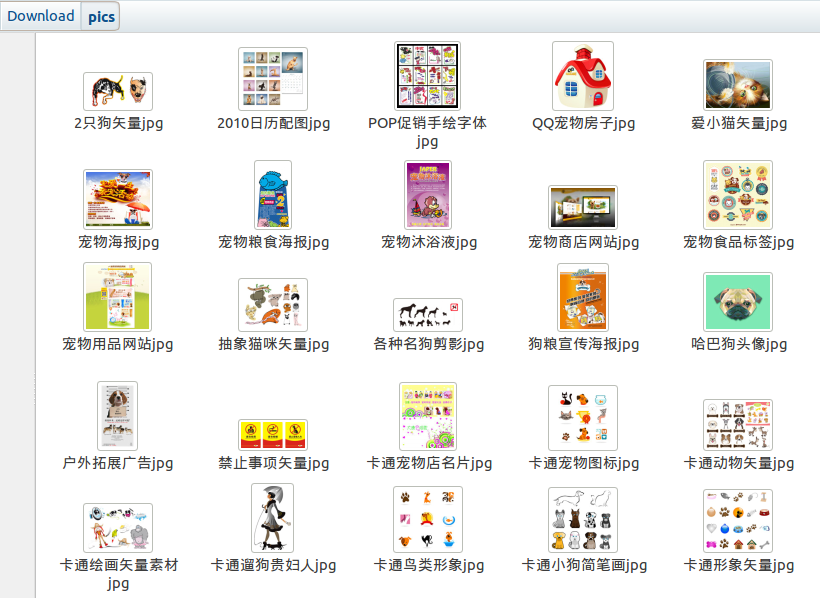
下载小图后的图片如下图所示:
小节
通过使用BeautifulSoup+urllib2库,我们熟悉了一般爬虫技术。通过本节的两个示例,我们可以拓展到一般情况下的抓取,只是具体问题要具体分析,在规则、效率等方面要仔细考虑。















 887
887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









