







 E2DTC是一个端到端的深度轨迹聚类框架,旨在解决传统轨迹聚类方法对手工相似性度量的依赖和效率问题。通过自训练的深度学习方法,E2DTC能够学习面向簇的轨迹表示,同时进行聚类分析,无需手动特征提取。在多个真实数据集上的实验表明,E2DTC相比于经典和先进方法,如K-Medoids和t2vec,表现出更高的准确性和效率。
E2DTC是一个端到端的深度轨迹聚类框架,旨在解决传统轨迹聚类方法对手工相似性度量的依赖和效率问题。通过自训练的深度学习方法,E2DTC能够学习面向簇的轨迹表示,同时进行聚类分析,无需手动特征提取。在多个真实数据集上的实验表明,E2DTC相比于经典和先进方法,如K-Medoids和t2vec,表现出更高的准确性和效率。
E2DTC: An End to End Deep Trajectory Clustering Framework via Self-Training
现有的基于原始轨迹表示的传统轨迹聚类方法高度依赖于手工相似性度量,无法捕捉到轨迹数据中隐藏的空间相关性,导致聚类分析效率低、不灵活。为此,受深度神经网络数据驱动能力的启发,我们提出了一种通过自训练的端到端深度轨迹聚类框架,称为E2DTC。E2DTC不需要任何额外的手动特征提取操作,可以很容易地适应于任何轨迹数据集上的轨迹聚类分析。在三个真实数据集上的广泛实验评估表明,与经典的聚类方法(即K-Medoids)和最先进的基于神经网络的方法(即t2vec)相比,我们的框架E2DTC具有更高的准确性和效率。
背景:
1. 首先,现有的轨迹聚类方法局限于基于原始轨迹的表示。很少有人关注轨迹聚类分析的深度表示。因此,我们的目标是学习一种深度的面向簇表示,并同时进行无监督轨迹聚类。
2. 其次,现有的轨迹聚类方法的结果质量主要依赖于距离(或相似度)度量。然而,对于复杂的轨迹数据集,很难找到合适的距离度量。相比之下,我们选择将原始轨迹嵌入到向量空间中,同时进行深度聚类。在嵌入向量空间中,欧氏度规可以很容易地用于计算。实验评估表明,基于距离度量的经典聚类方法在不同的轨迹数据集上可能具有完全的对比性能,这暴露了传统聚类方法对距离度量的高度依赖性。然而,深度聚类方法往往表现出较好的性能。
3.最后,传统的轨迹聚类处理流程不灵活,无法支持各种轨迹数据集。我们的目标是提出一个由神经网络训练的端到端深度轨迹聚类框架。一旦精细地建立并训练了深度聚类模型,轨迹聚类分析任务就可以高效地执行,以响应不同数据集的聚类请求。在本文中,我们利用深度神经网络的数据驱动能力,实现了一个无监督的聚类,而不需要手工的特征提取操作。
主要贡献:
我们重新审视了轨迹聚类问题,提出了一种端到端的深度轨迹聚类框架,称为E2DTC。在这里,端到端意味着在整个轨迹聚类管道中不需要进行分离和人工特征提取。给定一个纯轨迹数据集的输入,我们的目标是将每个原始轨迹嵌入到面向集群的表示中,同时联合进行轨迹聚类。
具体来说,我们的框架E2DTC主要包括三个阶段:(1)原始数据的轨迹嵌入;(2)初始化轨迹表示的预训练;(3)联合学习面向集群表示并进行聚类分析的自训练。
PROBLEM DEFINITIONS
Trajectory Representation Learning: 表示学习训练深神经网络(例如,fθ:O→Z)将每一个原始轨迹T∈O轨迹表示vT∈Z,θ表示神经网络的参数,O表示一组原始轨迹,和Z表示一组轨迹表示
Deep Trajectory Clustering:给定一组轨迹O,深度轨迹聚类在迭代优化聚类目标的同时,学习从原始轨迹到深度表示的映射。
在这里,我们用其质心Cj(1jk)表示每个学习到的聚类。深度轨迹聚类的目标是最小化不同聚类中轨迹之间的相似性,最大化同一聚类中轨迹之间的相似性。值得一提的是,我们的E2DTC模型是联合学习轨迹表示,并在一个统一的深度神经网络中进行轨迹聚类,而不是使用分离的模型进行这些任务。
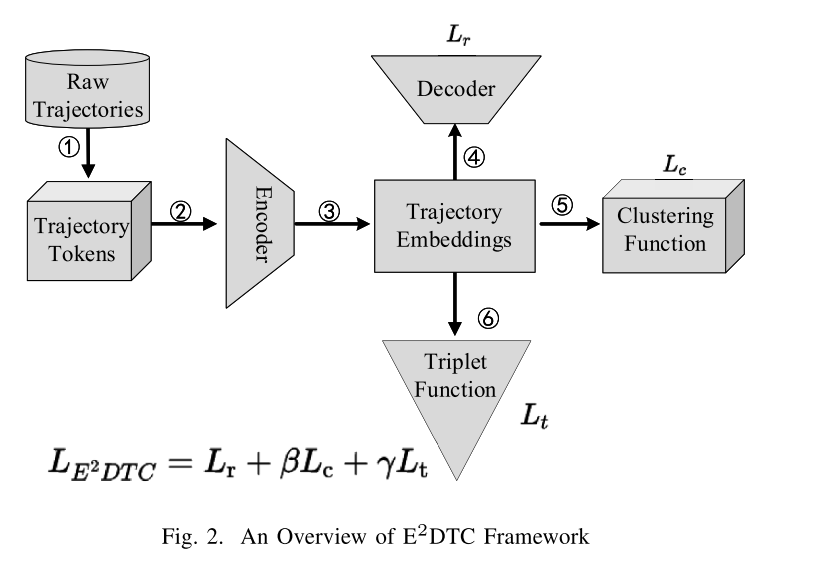
E2DTC框架建立在编码器-解码器体系结构上,主要包括三个处理阶段:(1)轨迹嵌入;(2)训练的;(3)自我训练。
在第一个轨迹嵌入阶段(包括图2中的x),将每个原始轨迹T转换成离散标记序列作为数据输入。在第二个训练前阶段(包括图2中的y、z和{),我们受到t2vec方法[16]的启发,利用Seq2Seq模型学习初始轨迹表示vT,该模型对原始轨迹数据的可变采样率和噪声点具有鲁棒性。在深度轨迹聚类的最后阶段(包括图2中的y, z,{, |和}),我们利用软聚类分配进行自训练,考虑深度表示vT和深度聚类Cj(1jk),联合调整深度神经网络θ。
E2DTC的整个训练可以提供一个鲁棒的编码器,它被精细地调整为面向集群的表示,并可以用于其他轨迹数据集上的无监督轨迹聚类任务,而无需额外的手动特征提取操作。换句话说,E2DTC是一个端到端深度轨迹聚类框架,充分释放轨迹的数据驱动能力
源码https://github.com/Database-and-Big-Data-Analytics-Lab/E2DTC


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









