







Slalom: Coasting Through Raw Data via Adaptive Partitioning and Indexing
数据和查询的不断流动正在不断突破数据分析系统的边界。原始数据文件的增大使得数据加载成为一项昂贵的操作,延迟了数据洞察的时间。因此,最近的原位查询处理系统直接在原始数据上操作,从而减轻了加载成本。与此同时,分析工作负载的查询数量越来越多。通常,每个查询都关注一个不断变化的-但很小的-范围。现在,最小化工作负载延迟需要在原地查询处理中使用索引。
本文提出Slalom,一种原位查询引擎,通过监测用户访问模式来适应工作负载的转移。Slalom基于轻量级监控收集的信息实时做出分区和索引决策。Slalom有两个关键部分:(i)一个在线分区和索引方案,(ii)一个为原位查询引擎量身定制的分区和索引调谐器。与最新的技术相比,Slalom通过考虑用户查询模式来提供性能优势(a)对原始数据文件进行逻辑分区,(b)为每个分区构建轻量级分区特定的索引。由于其轻量级和自适应特性,Slalom以最小的内存消耗实现了对原始数据的高效访问。在微基准测试和真实工作负载上的实验表明,Slalom的性能优于最先进的原位引擎(3 ~ 10倍),并实现了与完全索引DBMS相当的查询响应时间,对于规模不断增长和访问模式不可预测的查询工作负载,提供了低得多的(~ 3倍)累积查询执行时间。
一研究问题
1. Big Data, Small Queries.
2. The Cost of Loading, Indexing, and Tuning
3. Querying Raw Data Files Is Not Enough.
4. 自适应分区和细粒度索引
我们使用第一次表扫描来生成分区和轻量级的索引提示,这些提示通过后续查询的数据访问(只有少量)进一步细化。在这个精化过程中,数据集被动态地部分索引,以适应三个关键的工作负载特征:(i)数据分布,(ii)查询类型(例如,点查询、范围查询)和(iii)投影属性。工作负载的变化会导致不同的选择值范围、选择性、数据集中哪些区域与查询相关以及投影属性。
二研究内容
THE SLALOM SYSTEM
Slalom使用自适应的分区和索引为原位查询处理提供廉价的索引支持,同时适应工作负载的变化。Slalom通过跳过数据来加速查询处理,并在不可避免的情况下最小化数据访问成本。同时,它直接对原始数据文件进行操作,而不需要进行物理重构(即复制、排序)。
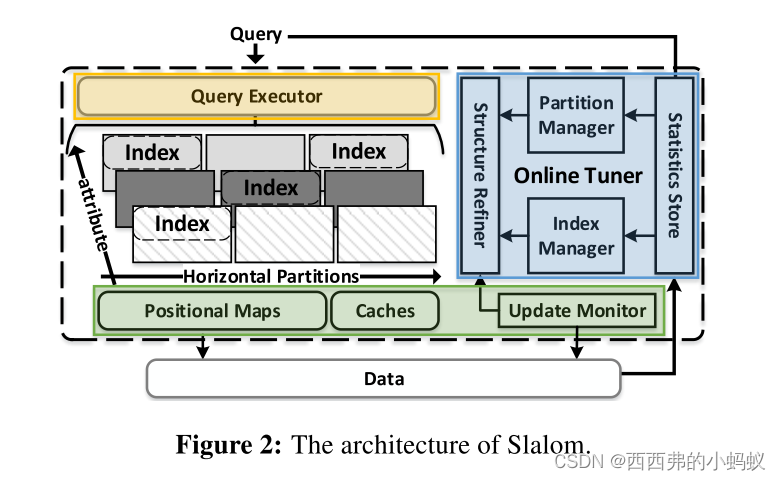
调优器的核心组件是Partition Manager,Index Manager。
总结:整个系统的结构构建的不是很明晰


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









