







 Noria是一个针对高读取量、高性能需求的Web应用程序设计的数据库系统,采用部分状态数据流,维护基表和派生视图,提供SQL接口。它简化了应用程序开发,避免了显式缓存管理和一致性问题,同时在性能上超越了传统的MySQL/memcached组合。Noria支持SQL DDL,接受应用程序查询和模式的演变,且能平滑地转换现有MySQL应用程序,无需停机。在Lobsters web应用的评估中,Noria表现出了优越的性能和扩展性。
Noria是一个针对高读取量、高性能需求的Web应用程序设计的数据库系统,采用部分状态数据流,维护基表和派生视图,提供SQL接口。它简化了应用程序开发,避免了显式缓存管理和一致性问题,同时在性能上超越了传统的MySQL/memcached组合。Noria支持SQL DDL,接受应用程序查询和模式的演变,且能平滑地转换现有MySQL应用程序,无需停机。在Lobsters web应用的评估中,Noria表现出了优越的性能和扩展性。
我们已经看到了流数据流引擎,它维护状态并提供SQL接口,甚至事务(例如Apache Flink和dataartian的Flinkstreaming ledger)。这里的主要模型是数据流,SQL作为状态的接口被固定。本文的标题让我开始沿着这些思路思考,但是从最终用户的角度来看,Noria看起来和感觉更像一个数据库。SQL接口是主接口,而不是辅助接口,它在基表中维护关系数据(使用RocksDB作为存储引擎)。为了维护一组(半)物化视图,Noria智能地使用SQL接口下的数据流(即,数据流不作为最终用户编程模型公开)。Noria自己找出最有效的数据流来维护这些视图,以及如何在模式/查询集更改时更新数据流图。
Noria的主要用例是为具有高性能(低延迟)需求的高读取量web应用程序而设计的。现在的这些应用程序通常包括某种缓存层(例如memcached、Redis),以提高读取性能并减轻数据库负载。应用程序开发人员的大量工作可以用于维护这些缓存,也可以用于数据库中的非规范化和计算状态。
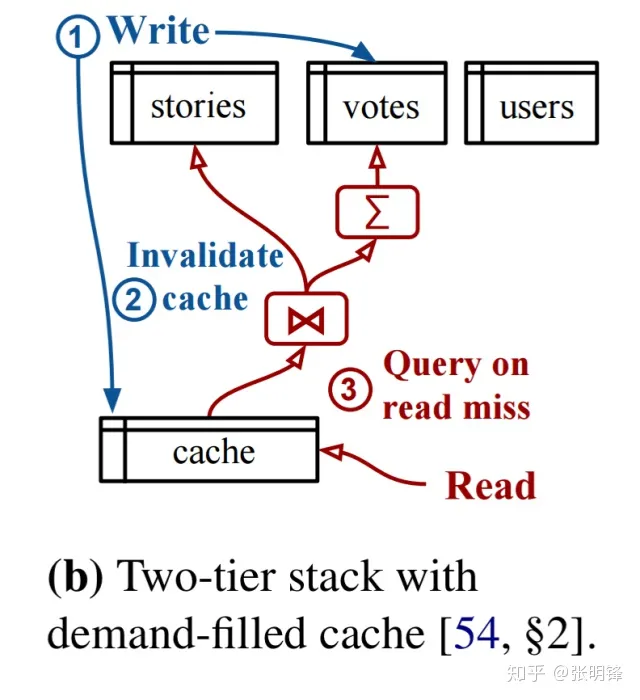
一般来说,开发人员必须在方便但缓慢的“自然”关系查询(例如,使用内联聚合)和以应用程序和部署复杂性为代价的性能提高(例如,由于缓存)之间做出选择。
Noria通过将数据保存在基表(大致上,核心持久数据)和维护派生视图(大致上,应用程序可能选择缓存的数据)来简化应用程序开发。从基表派生的任何计算信息都不在这些表中。程序员不需要担心显式的缓存管理/失效、计算和存储派生值以及保持这些值的一致性。诺里亚为他们做了这些。
在其核心,Noria运行一个连续但动态变化的数据流计算,它结合了持久存储、缓存和应用程序逻辑元素。对Noria的每次写入都通过当前查询的联合数据流图进行流式处理,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









