









 随着移动设备和物联网的发展,流数据聚类成为数据分析的关键。文章提出了一种名为DISC的新算法,专门针对滑动窗口模型优化,旨在解决基于密度的聚类算法在处理流数据时的效率问题。DISC在保持聚类质量的同时,能以更快的速度产生与增量DBSCAN等现有方法相当的结果。该算法包括收集和聚类两个步骤,通过核心点的可达性分析处理簇分裂和合并,有效地处理大规模流数据的聚类任务。
随着移动设备和物联网的发展,流数据聚类成为数据分析的关键。文章提出了一种名为DISC的新算法,专门针对滑动窗口模型优化,旨在解决基于密度的聚类算法在处理流数据时的效率问题。DISC在保持聚类质量的同时,能以更快的速度产生与增量DBSCAN等现有方法相当的结果。该算法包括收集和聚类两个步骤,通过核心点的可达性分析处理簇分裂和合并,有效地处理大规模流数据的聚类任务。
DISC: Density-Based Incremental Clustering by Striding over Streaming Data
随着移动设备和物联网设备的普及,对流数据进行连续聚类已经成为数据分析的重要工具。在众多聚类算法中,基于密度的聚类算法因其独特的优点而受到广泛关注。然而,它的主要缺点是由于相对较高的计算成本而限制了可扩展性,当它必须随着数据的变化不断更新集群时,这一问题进一步恶化。提出了一种新的基于密度的增量聚类算法DISC optimized for sliding window model。DISC能够以更快、更高效的速度产生与现有方法(如针对流数据的增量DBSCAN)完全相同的聚类结果。
主要目标:
针对基于密度的流数据聚类存在的局限性,在不影响聚类结果质量或消耗过多计算资源的前提下,使得流数据的聚类任务能够及时完成。本文提出的基于密度的聚类算法称为基于密度的增量跨步聚类(density-based Incremental Striding Cluster,简称DISC)。它能够以更快、更有效的方式产生与现有方法(如增量DBSCAN)完全相同的聚类结果。
A. Density-Based Clustering
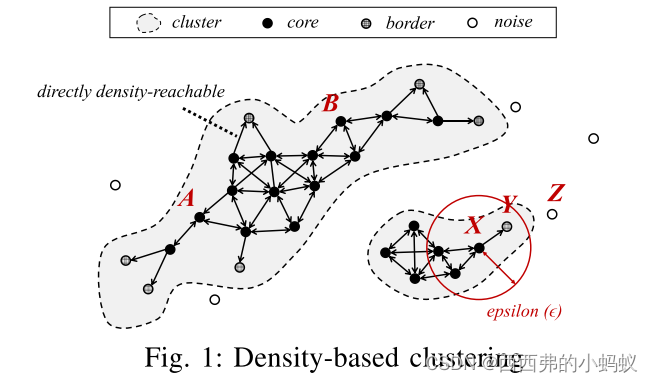
B. Sliding Windows
THE DISC ALGORITHM
介绍了一种新的增量式聚类算法DISC,它是针对大规模流数据在滑动窗口模型下的聚类问题而提出的。首先对算法进行了概述,然后描述了算法的两个主要步骤:收集和聚类。
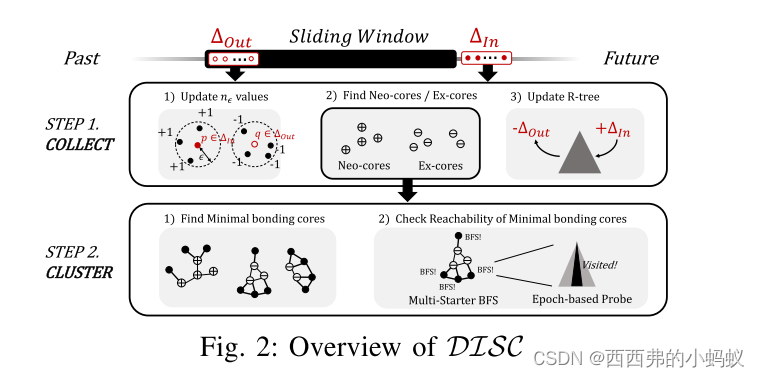
这将在两个单独的步骤中进行,称为COLLECT和CLUSTER
聚类步骤寻找每个前核和新核的最小连接核,通过检查可达性来确定簇演化的类型,最后重新计算当前窗口中每个点的簇标签。
B. COLLECT

CLUSTER
本节介绍的聚类步骤提供了一个复杂但高效的过程,以加快聚类演化的处理。算法2给出了该过程的高层描述。从伪代码中可以看出,前核用于处理簇分裂,而新核用于处理簇合并。在这两种主要操作之间,划分cluster的计算量要比增量更新集群大得多。本节将详细描述算法的每个子过程
1)Splitting a Cluster
簇分裂涉及核心点之间密度可达性的分裂。当核心点失去成为前核的状态时,它可能会在同一簇中的核之间切割一条密度可达路径,这反过来可能会导致簇分裂事件。本质上,只有当前核破坏了同一簇中的两个核心点之间的密度可达路径,并且它们之间不再有路径时,簇才能被拆分。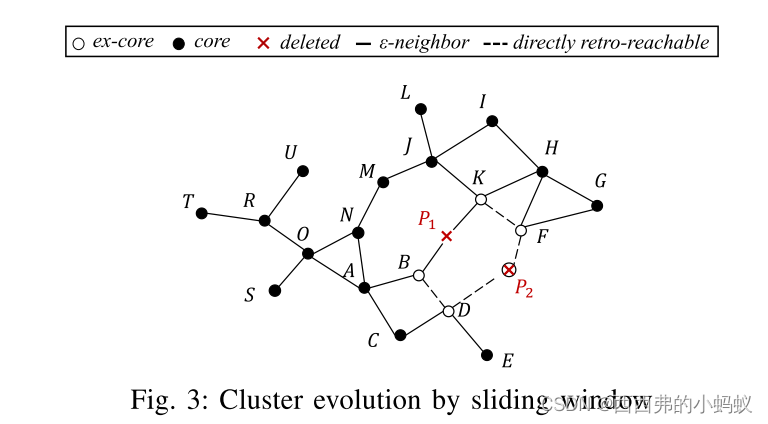
2)Merging Clusters
当不同簇的核心变得密度可达时,簇被合并。因为只有新核心才能有助于创建新的密度可达路径,所以只有当现有点获得核心状态或新核心进入当前窗口时,现有集群才能合并



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









