






摘要
We first assemble a large-scale dataset, called R2C7K, which consists of 7K images covering 64 object categories in real-world scenarios.
Then, we develop a simple but strong dual-branch framework, dubbed R2CNet, with a reference branch learning common representations from the referring information and a segmentation branch identifying and segmenting camouflaged objects under the guidance of the common representations.
In particular, we design a Referring Mask Generation module to generate pixel-level prior mask and a Referring Feature Enrichment module to enhance the capability of identifying camouflaged objects.
Extensive experiments show the superiority of our Ref-COD methods over their COD counterparts in segmenting specified camouflaged objects and identifying the main body of target objects.
在本文中,我们考虑了参考伪装目标检测(Ref-COD)问题,这是一种基于某种形式的参考(如图像、文本)来分割指定伪装目标的新任务。
我们首先组装了一个名为R2C7K的大规模数据集,该数据集由7K图像组成,涵盖了现实场景中的64个对象类别。
然后,我们开发了一个简单而强大的双分支框架,称为R2CNet,其中参考分支从参考信息中学习共同表征,分割分支在共同表征的指导下识别和分割伪装对象。
我们设计了参考遮罩生成模块来生成像素级的先验遮罩,设计了参考特征增强模块来增强识别伪装对象的能力。
大量的实验表明,我们的Ref-COD方法在分割指定伪装对象和识别目标对象主体方面优于其他COD方法。
Introduction
Based on the aforementioned two references, we propose a novel Ref-COD benchmark. To enable a comprehensive study on this new benchmark, we build a large-scale dataset, named R2C7K, which contains a large number of samples without copyright disputes in real-world scenarios.
And the outline of this dataset is as follows:
1) It has 7K images covering 64 object categories;
2) It consists of two subsets, i.e., the Camo-subset composed of images containing camouflaged objects and the Ref-subset composed of images containing salient objects;
3) The number of images for each category in the Ref-subset is fixed, while the one in the Camo-subset is not.
4) The expression ‘a photo of [CLASS]’ forms the textual reference for specified objects.
在上述两篇文献的基础上,我们提出了一个新的reff - cod基准。为了对这个新基准进行全面的全面研究,我们构建了一个名为R2C7K的大规模数据集,其中包含了大量在现实场景中没有版权纠纷的样本。 该数据集的概要如下:
1)拥有7K图像,覆盖64个对象类别;
2)由两个子集组成,即含有隐藏目标的图像组成的Camo-subset和含有显著目标的图像组成的Ref-subset;
3) Ref-subset中每个类别的图像数量是固定的,而Camo-subset中的图像数量是不固定的。
4)表达“a photo of [CLASS]”构成了对特定对象的文本引用。
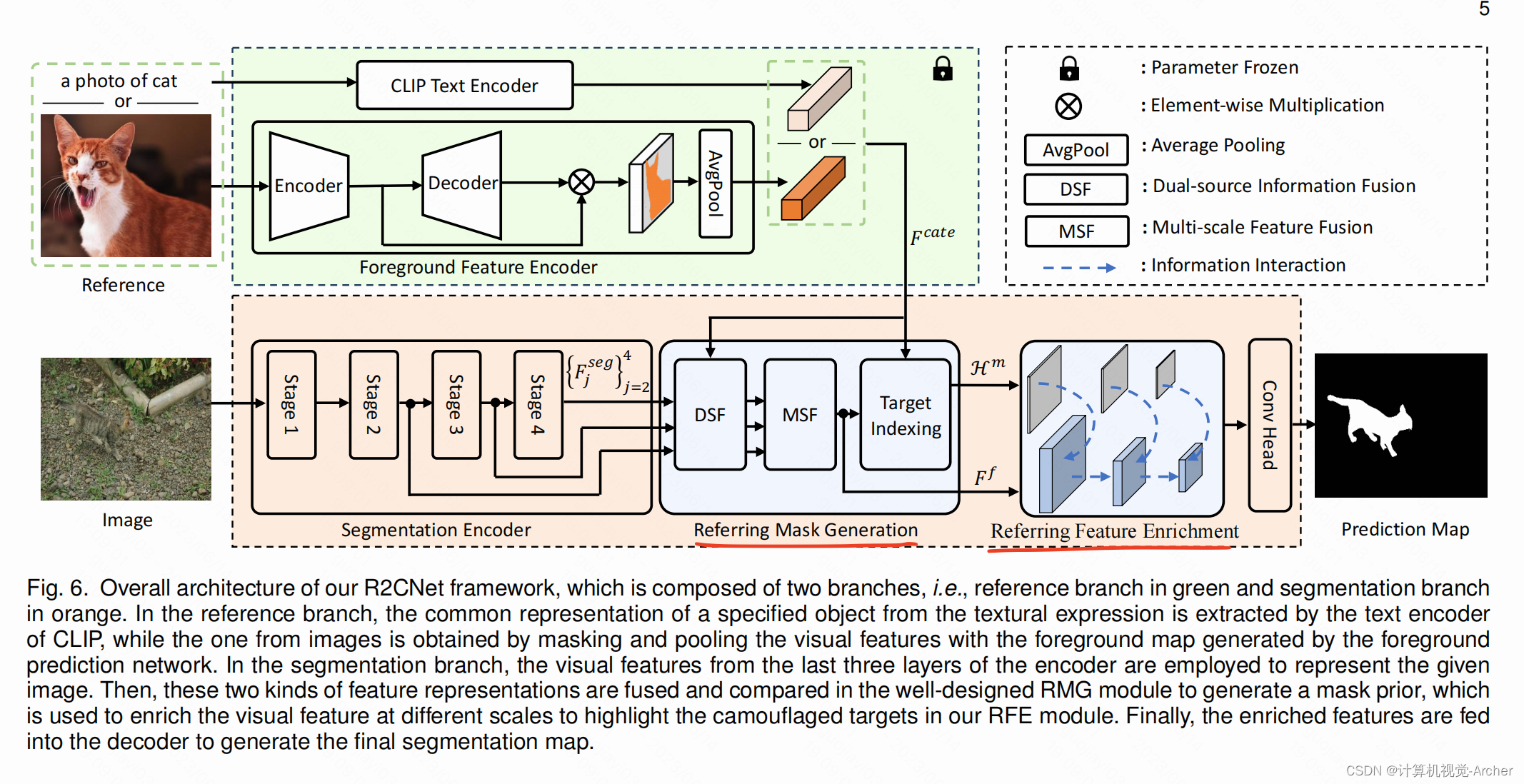
This framework includes a reference branch and a segmentation branch.
The reference branch aims to capture common feature representations of specified objects from the referring images composed of salient objects or textual descriptions, which will be used to retrieve the target objects.
Particularly, we build a Referring Mask Generation (RMG) module to generate pixel-level referring information.
In this module, a dense comparison is performed between the common representations from the reference branch and each position of the visual features from the segmentation branch to generate a referring prior mask.
However, there may exist variances in appearance between the camouflaged objects and the salient objects even though they belong to the same category, as well as modal differences between text expressions and images, which may increase the difficulty of retrieving accurate camouflaged objects.
To overcome this shortcoming, a dual-source information fusion motivated by multi-modal fusion is employed to eliminate the information differences between two information sources.
为探讨Ref-COD中参考信息的作用,
我们设计了一个双分支网络架构,并开发了一个简单而有效的框架,命名为R2CNet。
这个框架包括一个参考分支和一个分段执行分支。
参考分支旨在从由显著对象或文本描述组成的参考图像中捕获指定对象的共同特征表示,用于检索目标对象对象。
特别地,我们构建了一个参考掩码生成(RMG)模块来生成像素级参考信息。
在该模块中,将来自参考分支的常见表示与来自分割分支的视觉特征的每个位置进行密集比较,以生成参考先验掩码。
然而,尽管伪装对象与显著对象属于同一类别,但它们在外观上可能存在差异,并且文本表达和图像之间存在模态差异,这可能会增加准确检索伪装对象的难度。
为了克服这一缺点,采用多模态融合的双源信息融合动机来消除两个信息源之间的信息差异。
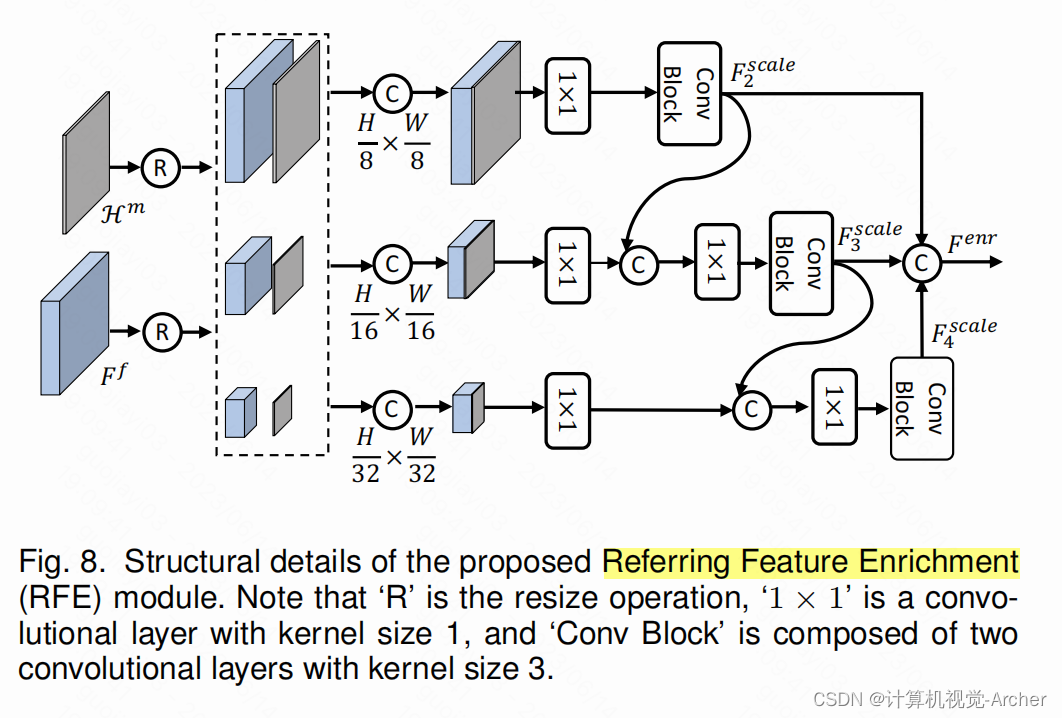
此外,我们还设计了参考特征增强(RFE)模块,实现多尺度视觉特征之间的交互,进一步突出目标对象。
To be specific, we choose the segmentation branch with multi-scale feature fusion based on feature pyramid network (FPN) [13] as the baseline COD model, and compare it with our R2CNet in terms of the common metrics [14], [15], [16], [17] of COD research on the R2C7K dataset.
Remarkably, our R2CNet outperforms the baseline model by a large margin.
Furthermore, we also apply the design of Ref-COD on recent 7 state-of-the-art COD methods, and the Ref-COD methods consistently surpass their COD counterparts without bells and whistles.
Besides, the visualization results also show quality predictions of the Ref-COD methods (e.g., R2CNet) in the segmentation of specified objects and the identification of the main body of camouflaged objects over the COD model (e.g., baseline).
进行了大量的实验来验证我们的reff - cod的有效性。
具体而言,我们选择基于特征金字塔网络(FPN)的多尺度特征融合分割分支[13FPN]作为基线COD模型,并将其与我们的R2CNet在R2C7K数据集上进行COD研究的常用指标[14]、[15]、[16]、[17]进行比较。
值得注意的是,我们的R2CNet在很大程度上优于基线模型。
此外,我们还将在最近7种最先进的COD方法上进行了ref-COD设计,re -COD方法始终优于同类方法。
此外,可视化结果还显示了Ref-COD方法(如R2CNet)在COD模型(如基线)上对指定目标的分割和伪装目标主体的识别方面的高质量预测。
综上所述,本文的贡献可以总结为如下:
1 我们提出了一个新的基准,称为Ref-COD,据我们所知,这是第一次尝试用简单的参考信息对伪装对象进行定向分割。
2 我们构建了一个名为R2C7K的大规模数据集,可以为Ref-COD的研究提供数据基础和更深入的见解。
3 我们设计了一个新的Ref-COD研究框架,称为R2CNet,其出色的实验re结果表明它可以为这一新颖的主题提供有效的解决方案
2 RELATED WORK
weakly supervised [27],
uncertainty [28], [29],[30],
foreground and background separation [31], [32], [33]
boundary [4], [37], [38], [39], [40],
texture [3], [41], [42],
frequency [43], [44]
depth [45], [46], [47],[47],
Particularly, most existing FSS networks include two branches, i.e. , support branch and query branch, to extract the features of support images and query images and achieve the interaction between them.
The pioneering work of FSS research is proposed by [67], where the support branch
Then, the masked average pooling operation is proposed by [68] to extract representative support features, which is widely adopted by subsequent works.
More recently, a large number of works [11], [69], [69] build powerful modules on the frozen backbone network to improve the adaptability of the models to unseen categories.
参考对象分割(reference Object Segmentation)是指从给定的图像中,按照一定的参考形式,如图像、文本等,分割出视觉对象。
few-shot segmentation (FSS)通过包含同一类别对象的注释图像来探索对象分段定位,其中模型在大量图像上进行训练,这些图像的像素被标记为基类(查询集),并在给定几个注释样本(支持集)的未见类上执行密集的像素预测。
特别是,大多数现有的FSS网络包括两个分支,即支持分支和查询分支,用于提取支持图像和查询图像的特征,并实现它们之间的交互。
FSS研究的开创性工作是由[67]提出的,其中支持分支机构直接预测查询分支中最后一层的权重进行分割。
然后,[68]提出了 masked average pooling operation,提取有代表性的支持特征,被后续作品广泛采用。
[67]A. Shaban, S. Bansal, Z. Liu, I. Essa, and B. Boots, “One-shot learning for semantic segmentation,” in BMVC, 2017.
[68]X. Zhang, Y. Wei, Y. Yang, and T. S. Huang, “Sg-one: Similarity guidance network for one-shot semantic segmentation,” IEEE TCYB, vol. 50, no. 9, pp. 3855–3865, 2020.
最近,大量研究[11]、[69]、[69]在冻结骨干网上构建了强大的模块,以提高模型对未知类别的适应性。
RES aims to segment visual objects based on a given textual expression, and the two-branch architecture is also adopted by the networks in this research.
The first work is introduced by [10], where the visual and linguistic features are first extracted
Subsequently, a series of methods based on multi-level visual features [70], multi-modal LSTM [71], attention mechanism [72], [73], collaborative network [74] are incorporated in RES methods successively to generate more accurate results.
In addition, the text descriptions are also adopted by [75] as references for the richness of image content to achieve a better fixation prediction.
引用表达式分割(RES)研究由文本表达式引导的对象分割。
RES的目标是基于给定的文本表达对视觉对象进行分割,net作品在本研究中也采用了双分支架构。
第一项工作由[10]介绍,其中首先提取了视觉和语言特征分别使用视觉编码器和语言编码器,并利用它们的连接生成分段定位掩码。
随后,一系列基于多层次视觉特征[70]、多模态LSTM[71]、注意机制[72]、[73]、协同网络[74]的方法被陆续纳入RES方法,以获得更准确的结果。
此外,文本描述也被[75]作为图像内容丰富程度的参考,以达到更好的注视预测。
With the rise of CLIP and prompt engineering, a series of works [76], [77] adopt image or text prompts to facilitate vision tasks.
It is noteworthy that such prompts can also be regarded as reference information.
For example, CLIPSeg [76] employs visual or text prompts from the pre-trained CLIP model as references to address image segmentation.
随着CLIP和提示工程的兴起,一系列作品[76]、[77]采用图像或文字提示来方便vi视觉任务。
值得注意的是,这些提示也可以重新视为参考信息。
例如,CLIPSeg[76]使用来自预训练CLIP模型的视觉或文本提示作为参考来解决图像分割问题。
T. Luddecke and A. Ecker, “Image segmentation using text and image prompts,” in IEEE CVPR, 2022.
Y. Rao, W. Zhao, G. Chen, Y. Tang, Z. Zhu, G. Huang, J. Zhou, and J. Lu,
“Denseclip: Language-guided dense prediction with context aware prompting,” in IEEE CVPR, 2022.
To be specific, it neither needs to collect rare and hard-to-label images containing camouflaged objects of the same category nor annotates detailed text descriptions for existing COD datasets, which is convenient for academia and industry to follow.
本文提出的Ref-COD也属于参考对象分割任务。
然而,与现有方法不同的是,它的参考信息的收集不需要太多的努力。
具体而言,它既不需要收集包含同一类别伪装对象的罕见且难以标记的图像,也不需要对现有COD数据集注释详细的文本描述,方便学术界和工业界遵循。
3 P ROPOSED D ATASET
Besides, the quality of a dataset plays an important role in its lifespan as a benchmark, as stated in [78], [79].
With this in mind, we build a large-scale dataset, named R2C7K, for the proposed Ref-COD task. In this section, we introduce the construction
一系列数据集的出现为开展人工智能研究奠定了基础,尤其是在当前数据饥渴的深度学习时代。
此外,数据集的质量在其作为基准的寿命中起着重要作用,如[78],[79]所述。
考虑到这一点,我们为建议的Ref-COD任务构建了一个名为R2C7K的大规模数据集。在本节中,我们将介绍该结构数据集的处理和统计。
To this end, we investigate the most popular datasets in COD research, i.e. ,
Considering that COD10K is the largest and most comprehensively annotated camouflage dataset, we build the Camo-subset of R2C7K mainly based on it.
Specifically, we eliminate a few unusual categories, e.g. pagurian, crocodile-fish, etc , and attain 4,966 camouflaged images covering 64 categories.
For the images containing only one camouflaged object, we directly adopt the annotations provided by COD10K, and for other images containing multiple camouflaged objects, we erase the annotated pixels except for objects of the referring category.
Note that we also supplement 49 samples from NC4K for some categories due to their extremely small sample numbers.
Next, we construct the Ref-subset of R2C7K according to the selected 64 categories.
We use these category names as keywords and search 25 images that come from real-world
In particular, these referring images, which have no copyright disputes, are collected from
For the details on the image collection scheme, we recommend the readers to refer to [82].
Finally, we present the image and annotation samples of the R2C7K dataset in Fig.2
为了构建R2C7K数据集,第一步是deter mine,其中隐藏了要检测的对象。
为此,我们调查了COD研究中最流行的数据集,即:
COD10K [1], CAMO[80],和NC4K[81]。
考虑到COD10K是目前最大、标注最全面的迷彩数据集,我们主要基于COD10K构建了R2C7K的迷彩子集。
具体来说,我们消除了一些不寻常的类别,例如pagurian,鳄鱼鱼等,并获得了覆盖64个类别的4,966张伪装图像。
对于只包含一个伪装对象的图像,我们直接采用COD10K提供的注释,对于包含多个伪装对象的其他图像,我们擦除除引用类别对象外的所有标记像素。
请注意,由于某些类别的样本数极小,我们还从NC4K中补充了49个样本。
接下来,我们根据选择的64个类别构建R2C7K的ref子集。
我们使用这些类别名称作为关键字,并搜索来自现实世界的25张图片场景,并包含来自互联网的每个类别所需的突出对象。
特别是,这些涉及到的年龄,没有版权纠纷,收集Flickr和Unsplash。
关于图像采集方案的详细信息,建议读者参考文献[82]。
最后,我们给出了R2C7K数据集的图像和标注样本,如图2所示

It can be observed that the objects in the Ref-subset are bigger than those objects in the Camo-subset, and the images in the Ref-subset contain more contrast cues.
Therefore, the objects in the Ref-subset are easier to be detected, which means that this form of referring information is readily available and suitable for the Ref-COD research.
图3给出ref -子集和camo -子集图像的4个属性对比。
具体来说,物体面积是指给定图像中物体的大小,物体比例是物体在图像中所占的比例,物体距离是物体到物体的距离
中心到图像中心,全局对比度是评估物体检测难度的度量。
可以观察到Ref-子集中的对象比camo -子集中的对象更大,Ref-子集中的图像包含更多的对比度线索。
因此,ref -子集中的对象更容易被检测到,这意味着这种形式的参考信息是现成的,适合于Ref-COD的研究。
The R2C7K dataset contains 6,615 samples covering 64 categories, where the Camo-subset consists of 5,015 samples and the Ref-subset has 1,600 samples.
R2C7K数据集包含6,615个样本,涵盖64个类别,
其中camo子集包含包含5,015个样本,
ref子集包含1,600个样本。
需要注意的是,该数据集的每个类别包含固定数量的参考图像,即25张,而每个类别的COD图像数量分布不均匀,如图4所示。

蓝色是ref-subset 红色是camo-subset
Fig. 5(a) and Fig. 5(b) shows the resolution distribution of the images in the Camo-subset and
As can be seen, these two subsets contain a large number of Full HD images, which can provide more details on the object boundaries and textures.
To facilitate the development of models for Ref-COD research, we provide a referring split for the R2C7K dataset.
For the Ref-subset, 20 samples are randomly selected from each category for training while the remaining samples in each category are used for testing;
As far as the Camo-subset, the samples coming from the training
And the samples from NC4K are randomly assigned to the training and testing sets to ensure that each category in these two splits contains at least 6 samples.
分辨率分布。Resolution Distribution
图5(a)和图5(b)显示了Camo-subset and Ref-subset的图像分辨率分布。
可以看到,这两个子集包含了大量的Full HD图像,可以提供更多关于物体边界和纹理的细节。
数据集分割。Dataset Splits.
为了方便Ref-COD研究模型的开发,我们对R2C7K数据集提供了一个参考分割。
对于Ref-subset,从每个类别中随机抽取20个样本进行训练,每个类别中剩余的样本用于测试;
至于camo子集,来自训练的样本COD10K集也用于训练,属于测试集的COD10K集用于测试。
并且将NC4K的样本随机分配到训练集和测试集,以确保这两个分裂中的每个类别至少包含6个样本。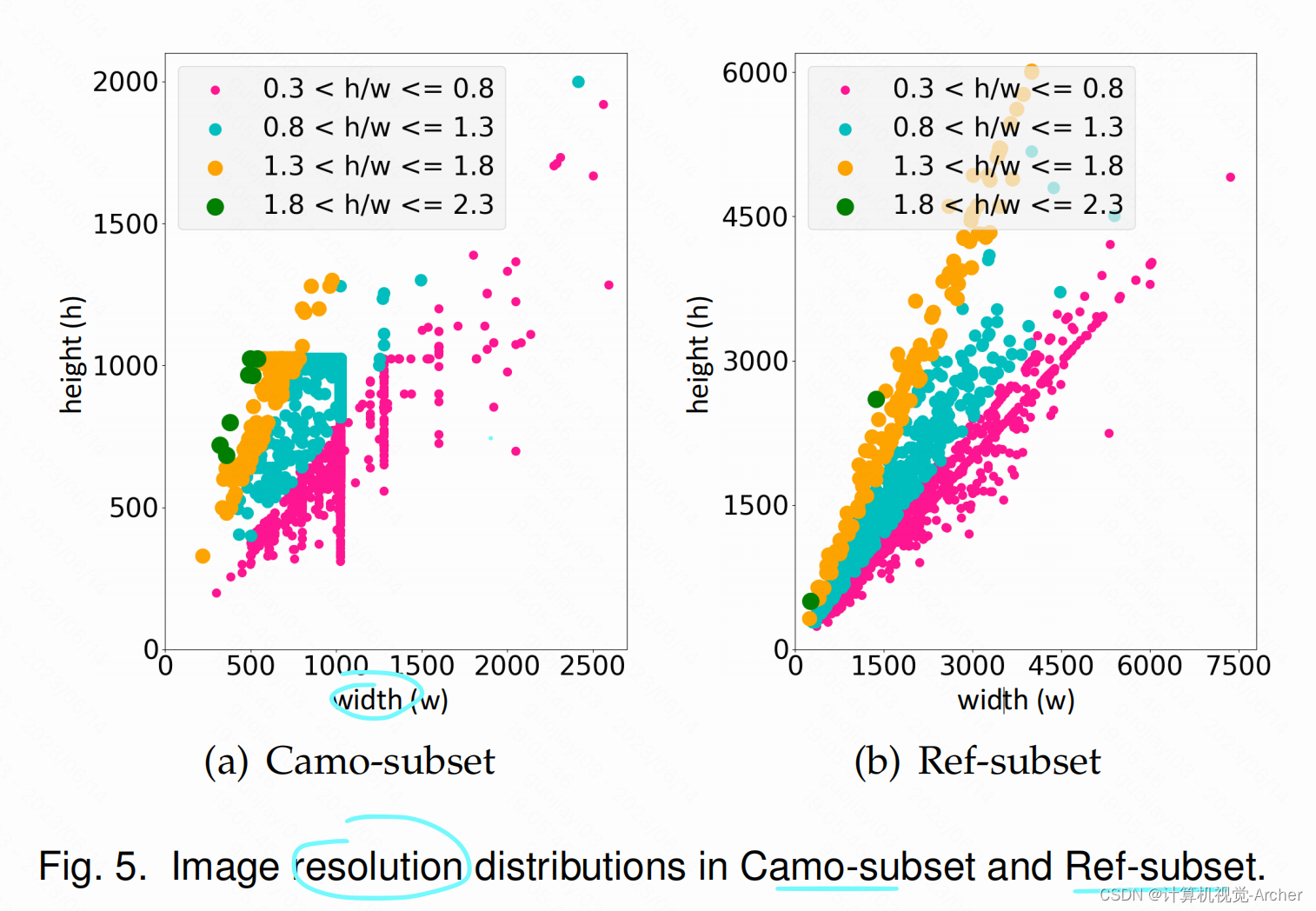
4 P ROPOSED F RAMEWORK

















 3779
3779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











