






题目:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
作者:谷歌大脑团队(Dosovitskiy, A., Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, M. Dehghani, Matthias Minderer, Georg Heigold, S. Gelly, Jakob Uszkoreit and N. Houlsby)
发表会议及时间:ICLR2021
摘要:
Transformer在nlp领域已经有了十分不错的成绩,但是在计算机视觉领域应用还十分受限。在cnn中attention不作为一个主要的模块,即整体仍是cnn结构。但作者展示了在图像分类中单纯使用transformer也能表现得很好。在没有经过强正则化的中等数据集上时,transformer表现得没有很好,但是在足够大的数据集上训练后,VIT可以拿到和cnn中的sota差不多的结果甚至使用了更少的资源。
查询资料可知,Transformer提出后在NLP领域中取得了极好的效果,其全Attention的结构,不仅增强了特征提取能力,还保持了并行计算的特点,可以又快又好的完成NLP领域内几乎所有任务,极大地推动自然语言处理的发展。但其在计算机视觉领域应用很有限,在此之前只有目标检测(Object detection)中的DETR大规模使用了Transformer,纯Transformer结构的网络则是没有的。
拿Transformer来CV领域应用的动机(优势):
1、并行计算:RNN前后具有依赖关系,依赖于时许,不具有并行计算的能力;CNN的滑动窗口,前后不依赖因此天然具有并行计算的能力;Transformer也具有并行计算能力,不同的时序对应不同的attention权重
2、全局视野:CNN没有全局视野,都是局部的感受野,需要通过堆叠(增加深度);Transformer具有全局视野,attention机制
3、灵活的堆叠能力
论文思路:
任务a中比较好的思路可以应用到任务b去,当然也需要解决应用过程中的一些问题,比如把CV中的多维数据放到transformer中去
attention机制:
一个翻译只与有限的几个词有关,并不用完全编码,本质即加权平均,如何得到权重即相似度计算,具有并行计算和全局视野的优点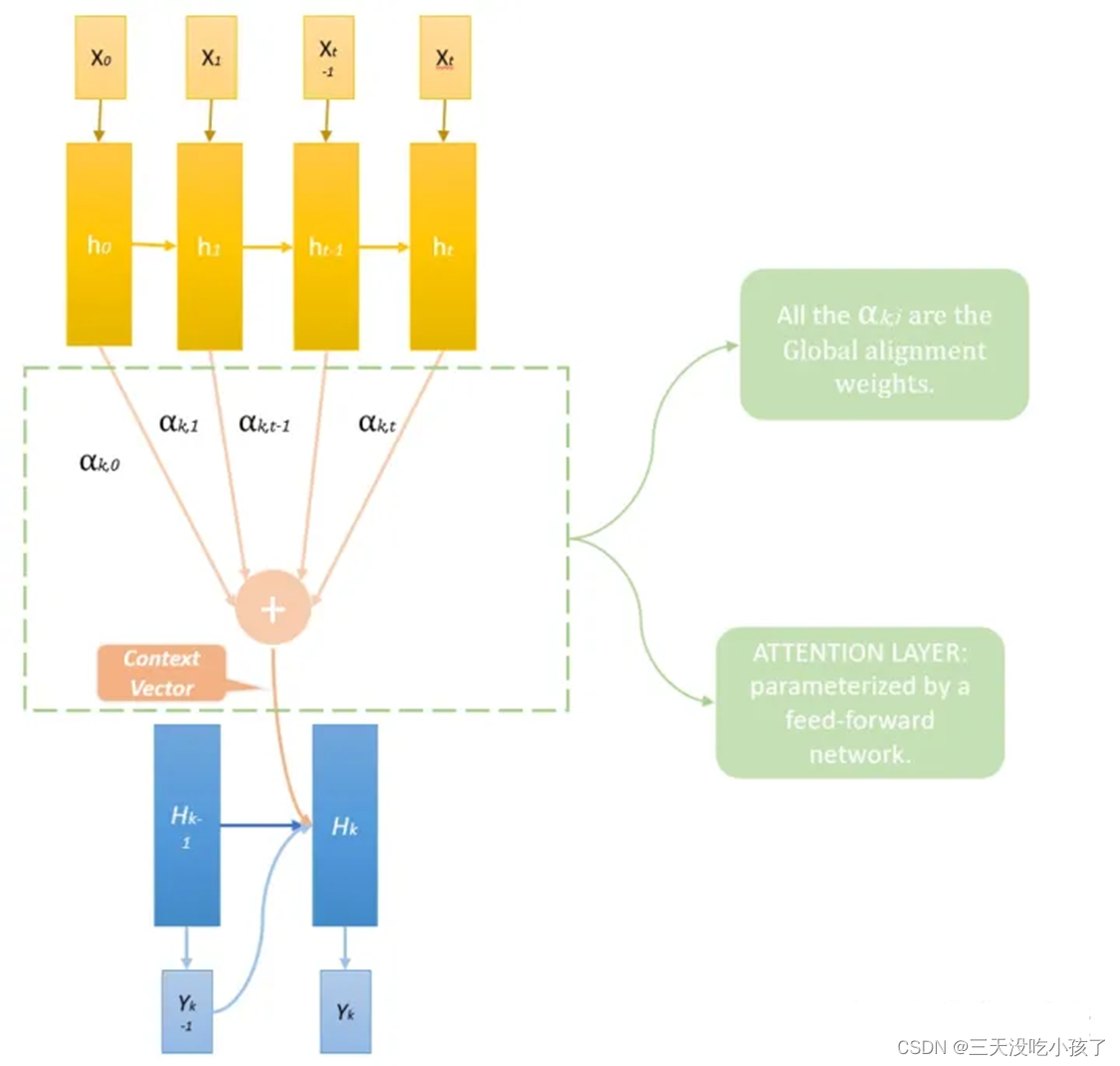
Self attention:
从一维角度讲NLP:word->vector
1、同义相近(cat,cats)
2、意思差距大距离远
计算:

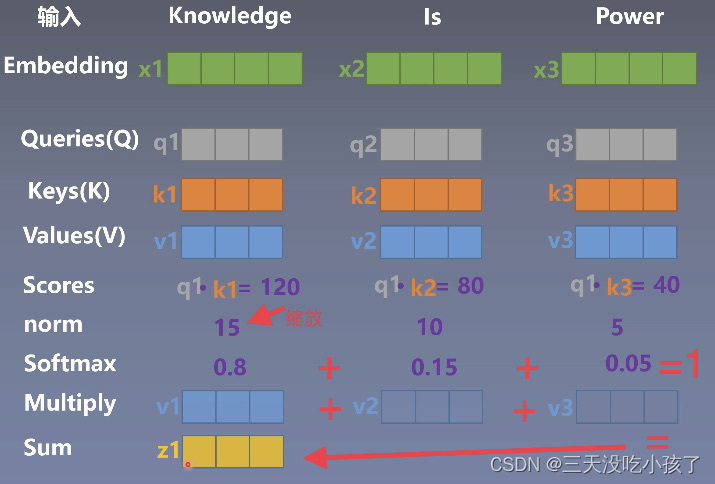
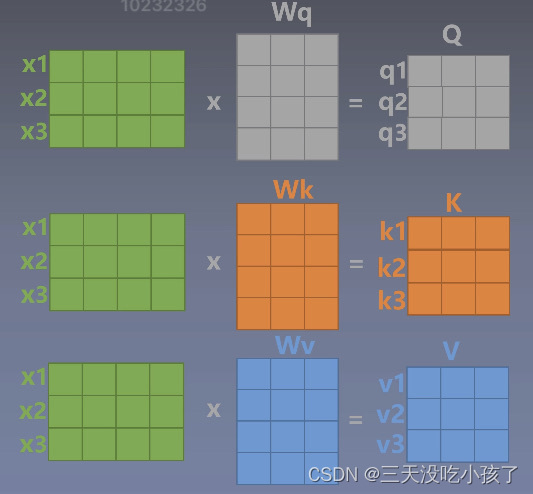
通过矩阵乘法计算出QKV(Query,Key,Value)
实际上就是计算相似度,计算每个q和每个k的相似度,逐个计算z1 z2...zn
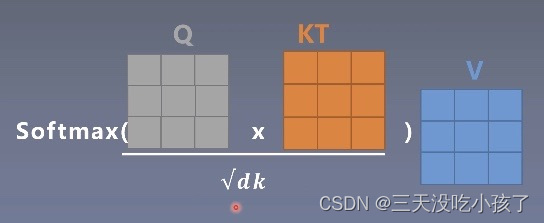
计算可以矩阵化即并行,因此不需要两层循环,效率高
multihead attention:
有多个Wq,Wk,Wv,重复多次self attention计算,结果concat到一起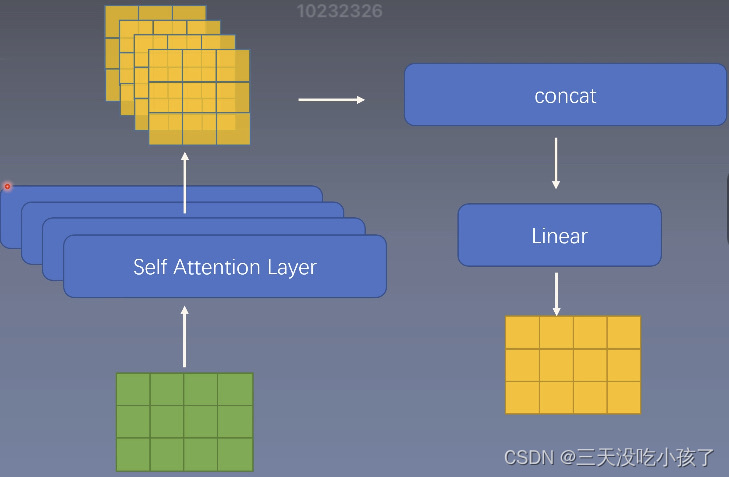
transformer encoder:
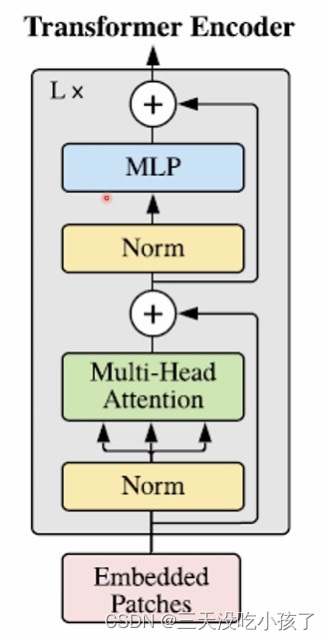
输入端适配:
CV部分,即切图重排,image->sequence
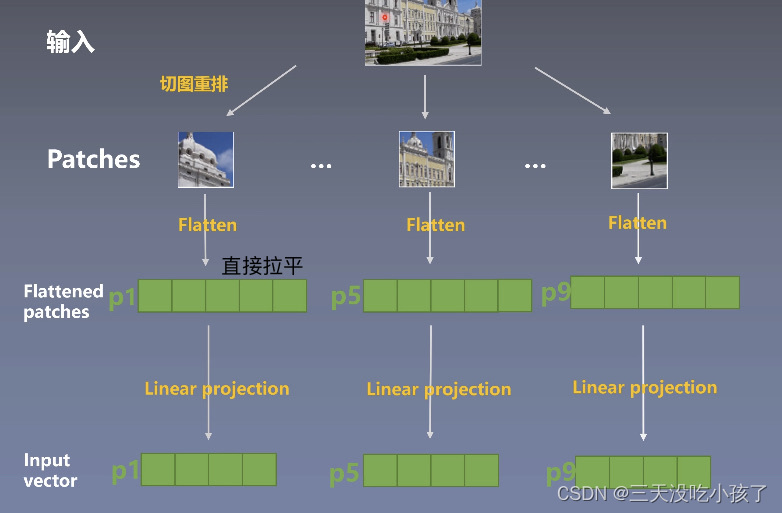
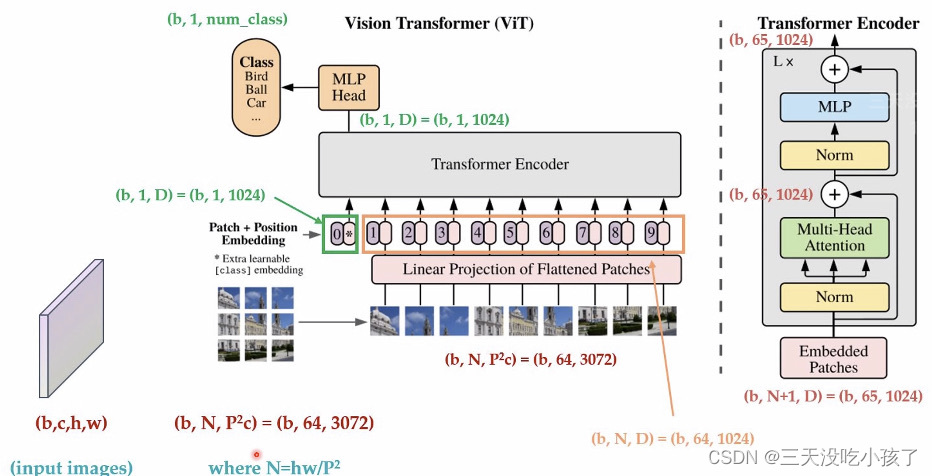
Patch 0是一个动态的pooling layer
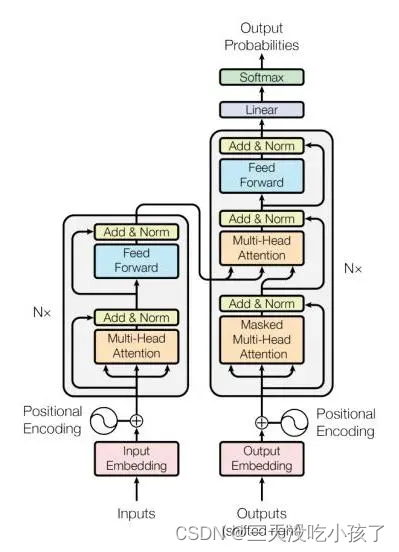
论文模型:
实验结果分析:
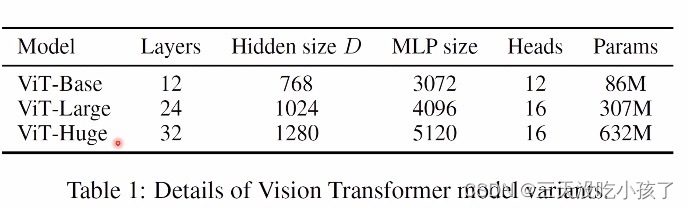
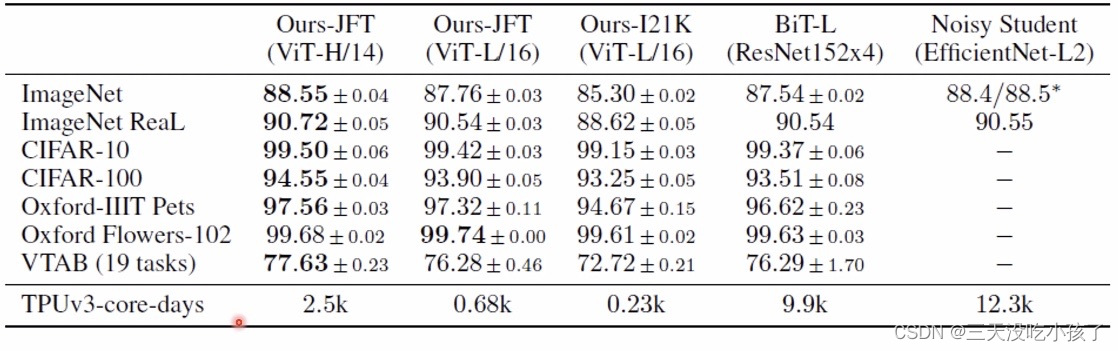
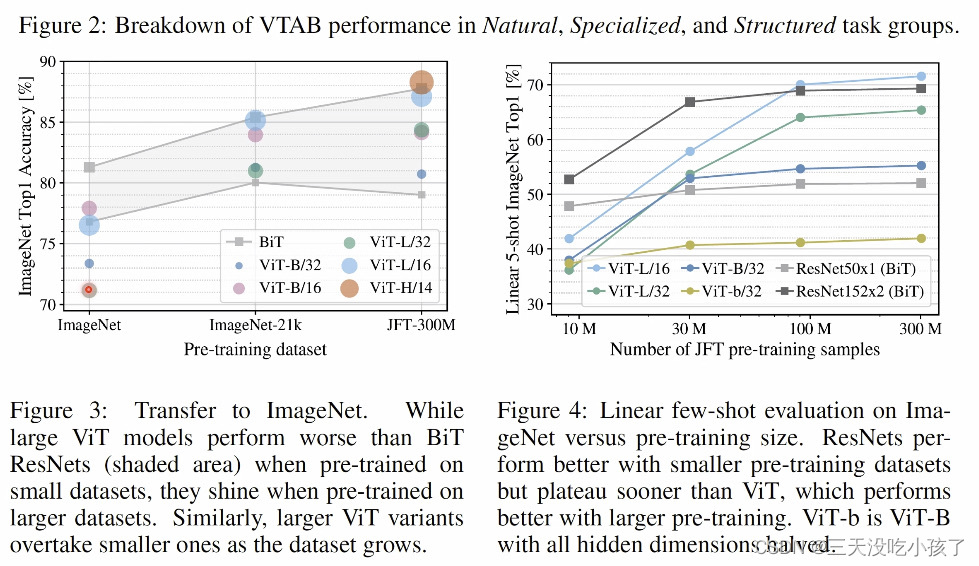
所消耗的资源更少,但是vit的性能需要大数据集
训练方式:
大规模使用Pre-Train,现在大数据集上预训练,然后到小数据集上Fine Tune
Transformer的优缺点分析:
结构优点:
简洁、大kernel、动态权重
对社区的贡献:
容易改良、容易拓展
结构代价:
O(n2)的attention复杂度(时间和空间都这么大,时间长容易炸显存)、对整体结构的造成影响、收敛问题(有大数据集的公司毕竟不多)
对社区的挑战:
下端怎么用、端上如何部署
关键点:
vit是一个用transfomer做分类的backbone
模型结构-- transform么人 encoder
multihead attention的意义及计算过程
输入端适配--切图、位置编码
创新点:
纯transformer做分类任务
简单的输入端适配即可使用
做了大量的实验揭示了纯transformer做cv的可能性














 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









