







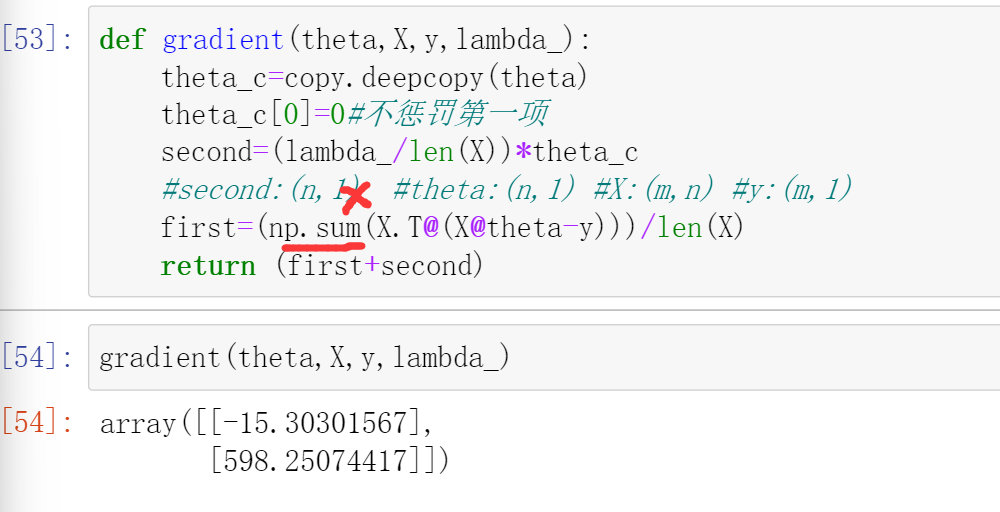
①.2022/07/16 正则化逻辑回归的gradient descent函数。
不改加上sum的,用是矩阵的乘法了!!!乘完后已经累加完毕了。!!
修改后:
precision大大提升!!!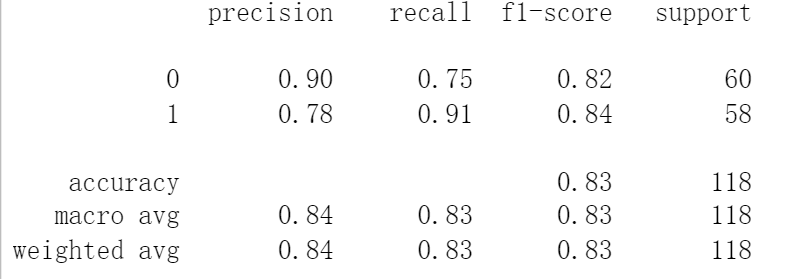

②机器学习笔记:决策边界的绘制
③numpy的argmax返回的是一维数组(n,) !
④七月二十九:已经使用向量化了,此处就无须再用np.sum()了去求和了->矩阵乘法自动相加
⑤传入函数的向量(size=(n,1))之后,其shape自动变成一维的(n,)---->记得在函数中reshape一下就好(在十一点也有所体现)
⑥在使用scipy.optimize.minimize的时候,其中jac参数是gradient,其返回值一定注意是一个一维的向量--->可以用flatten()进行降维
⑦在逐一增大train set的时候,theta始终的第一维大小为X.shape[1]
⑧numpy中的ndarray对象的切片a[1:2]是闭区间->区分range!!!!
⑨当你发现,数据很奇怪的一致的时候,很可能变量名用错了。。。
⑩在画学习曲线的时候,error_train中传入X_train的时候,一定是传入训练时那一部分用到的!
(11)在feature_map的时候,一个细节处理不当!!导致NaN \INF
仔细想想看,这样做合不合理->明显会爆掉!!!重复添加一部分!!!
(12)画出拟合的曲线!!!!,x坐标的位置传参细点心,应该传入x,而xx是用来得到y_的。其次注意下np.linspace的用法 (13)希望用bool索引一个ndarray对象的时候,出问题:(原理见下)
(13)希望用bool索引一个ndarray对象的时候,出问题:(原理见下)

![]()
这边i 是一个常量,但是idx一定要是一个ndarray对象,才能进行相应的bool索引。
(14)[报错]list indices must be integers or slices, not tuple
错误代码:
data=[[0,1],[2,3],[4,5]]
print(data[:,1])解决:
使用numpy中的array,将列表转化为标准的数组:
import numpy as np
data=[[0,1],[2,3],[4,5]]
data=np.array(data)
print(data[:,1])
















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











