






RDD依赖关系
1 Lineage
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
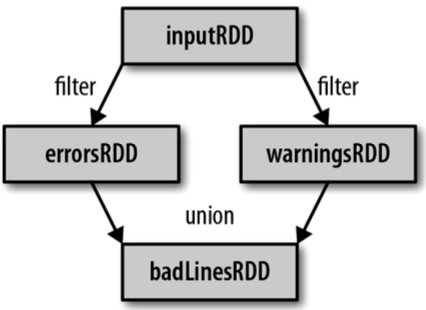
(1)读取一个HDFS文件并将其中内容映射成一个个元组
scala> val wordAndOne = sc.textFile(“/fruit.tsv”).flatMap(_.split(“\t”)).map((_,1))
wordAndOne: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[22] at map at <console>:24
(2)统计每一种key对应的个数
scala> val wordAndCount = wordAndOne.reduceByKey(_+_)
wordAndCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[23] at reduceByKey at <console>:26
(3)查看“wordAndOne”的Lineage
scala> wordAndOne.toDebugString
res5: String =
(2) MapPartitionsRDD[22] at map at <console>:24 []
| MapPartitionsRDD[21] at flatMap at <console>:24 []
| /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 []
| /fruit.tsv HadoopRDD[19] at textFile at <console>:24 []
(4)查看“wordAndCount”的Lineage
scala> wordAndCount.toDebugString
res6: String =
(2) ShuffledRDD[23] at reduceByKey at <console>:26 []
+-(2) MapPartitionsRDD[22] at map at <console>:24 []
| MapPartitionsRDD[21] at flatMap at <console>:24 []
| /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 []
| /fruit.tsv HadoopRDD[19] at textFile at <console>:24 []
(5)查看“wordAndOne”的依赖类型
scala> wordAndOne.dependencies
res7: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@5d5db92b)
(6)查看“wordAndCount”的依赖类型
scala> wordAndCount.dependencies
res8: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@63f3e6a8)
注意:RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
想要了解跟多关于大数据培训课程内容欢迎关注尚硅谷大数据培训,尚硅谷除了这些技术文章外还有免费的高质量大数据培训课程视频供广大学员下载学习。















 5708
5708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









