






超分辨率学习
开始学习超分辨率相关内容,笔记记录如下
传统图像超分辨率重建方法
基于插值
- 最邻近插值法(Nearest neighbor):令变换后像素灰度值等于离它最近的输入像素的灰度值
- 双线性插值法(Bilinear interpolation algorithm):通过中心像素点旁边四个相邻点的像素分别在水平和垂直两个方向上做线性内插得到最终待插值点的像素值。
- 双三次插值法(bicubic interpolation):双三次插值将带采样点旁的4个邻点扩展为16个,对这16个邻点灰度值做三次插值。
用插值的方法进行图像超分辨(python实现)
图像超分辨——基于插值的方法(个人总结)(matlab实现)
基于重建
图像超分辨率重建简介
基于重建的超分辨率方法的基础是均衡及非均衡采样定理。它假设低分辨率的输入采样信号(图像)能很好地预估出原始的高分辨率信号(图像)。绝大多数超分辨率算法都属于这一类,其中主要包括频域法和空域法。
频率域方法是图像超分辨率重建中一类重要方法,其中最主要的是消混叠重建方法。消混叠重建方法是通过解混叠而改善图像的空间分辨率实现超分辨率复原,最早的研究工作是由Tsai 和 Huang在1984年进行的。在原始场景信号带宽有限的假设下,利用离散傅立叶变换和连续傅立叶变换之间的平移、混叠性质,给出了一个由一系列欠采样观察图像数据复原高分辨率图像的公式。多幅观察图像经混频而得到的离散傅立叶变换系数与未知场景的连续傅立叶变换系数以方程组的形式联系起来,方程组的解就是原始图像的频率域系数,再对频率域系数进行傅立叶逆变换就可以实现原始图像的准确复原。
在空域类方法中,其线性空域观测模型涉及全局和局部运动、光学模糊、帧内运动模糊、空间可变点扩散函数、非理想采样等内容。空域方法具有很强的包含空域先验约束的能力,主要包括非均匀空间样本内插、迭代反投影方法、凸集投影法、最大后验概率以及混合MAP/ POCS 方法、最优和自适应滤波方法、确定性重建方法等。
基于学习(机器学习)
降秩产生训练集训练或者采用字典学习的方法学习稀疏表达
example-based方法、领域嵌入、支持向量回归、稀疏表示
基于深度学习
是一个监督学习,将高分图像下采样成低分图像,再将低分图像放到神经网络中训练出超分图像,最小化超分图像和高分图像的误差
获取低分图像的方法
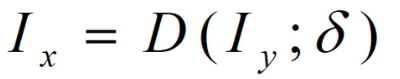
Ix是低分图像,Iy是高分图像,D是降级函数
获取低分图像的过程中可能遇到的问题:散焦、噪点、压缩失真、传感器噪声
简单下采样

s表示下采样倍数
加入模糊和噪声的下采样
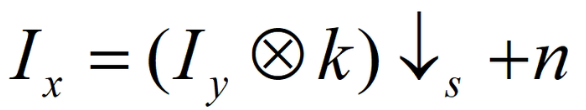
高分图像Iy做以k为卷积核的卷积操作下采样后加上噪声n

超分图像的评价指标
客观
峰值信噪比PSNR(DB)

第一个公式是求高分图像和超分图像对应像素点像素值的均方误差(越小越好)
第二个公式中 L表示像素点取值范围的上限(eg.255)(越大越好)
缺点:仅评价两幅图的平均像素差 无法评价两幅图之间的感知差异
结构相似度SSIM
亮度(像素点均值)、对比度(像素点方差)、结构(像素点协方差),C1、C2、C3为常数

范围[0,1],越接近1图像越相似
主观:意见平均分MOS
人工打分
超分网络结构分类
预上采样

一开始使用固定的上采样方式将低分图像放大到指定尺寸,然后将图片放入卷积层中,由模糊图像向高清图像映射
优点:无需考虑输入输出图像尺寸不匹配问题,简化建模过程
缺点:固定上采样过程可能产生虚假纹理,所有计算都在高维空间中执行,增加计算成本
后上采样

先进行卷积,再做上采样,可以让网络自适应的学习上采样的过程,还能让特征提取过程在低维空间中完成,降低计算成本。但是当上采样的倍数过大时,过多的信息缺失可能会导致上采样层学习难度太高,而且由于上采样层固定,所以不能适应不同的输入输出尺寸,放大倍数改变都要重新训练。
逐步上采样

通过多次上采样逐步获得目标尺寸的超分图片。降低训练难度,一定程度上适配各种放大倍数。多阶段训练可以结合一些特定的方法进一步减小训练难度。但由于他本来结构就比较复杂,所以训练难度还是很高。
交替式上下采样

新方法。挖掘低分和高分图像之间的依赖关系。但是上下采样层的结构比较复杂。
SRCNN

将低分图像,进行插值放大(双三次),经过9×9的卷积和relu激活,提取特征,再经过1×1的卷积层和激活函数进行非线性的映射,最后输入到5×5的卷积层+relu层中,重建出SR图片。
深度学习图像超分辨率开山之作SRCNN(一)原理分析
深度学习图像超分辨率开山之作SRCNN(二)pytorch实现
未来研究方向
1)发展和寻求新的退化模型,使成像模型更加精确和全面,实现对点扩散函数和噪声的精确估计。图像超分辨率增强的成功依赖于准确的、符合实际成像系统特性和成像条件的降模型,而要获得符合实际成像过程的降质模型是十分困难的,通常采用简单、确定的降质模型进行近似,这样的近似模型与实际成像过程差距较大。
2)压缩域的超分辨率重建。传统的超分辨率算法都是针对图像序列,而实际中最常见的图像序列是视频文件。因而下一步的工作可以针对不同的视频压缩格式和编解码技术,在超分辨率算法中综合考虑成像模型和压缩算法带来的图像降质效果,以及运动补偿和编码传输机制,实现压缩域的超分辨率重建。
3)效率和鲁棒性问题。目前的超分辨率算法具有很高的计算复杂度,如何减少计算量,提高算法速度,是下一步值得研究问题。同时,在目前很多算法中都做了各种假设,如照度变等,这在实际应用中是很难满足的,因此需要研究稳健的算法满足实际应用的需要。
4)模糊图像和三维图像的超分辨率研究。模糊一直是图像处理中的一个难点,如何对模糊图像进行超分辨率需要进一步研究。目前针对三维图像的超分辨率研究还很少,如何对三维图像进行建模也是一个值得研究的课题。
5)超分辨率客观评价标准研究。目前对于图像超分辨率结果主要依靠人的主观评价,缺少一种客观的评价标准,现有的PSNR、MSE等并不能很好的反映超分辨率效果,需要发展一种客观的评价机制。















 8004
8004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









