







写在前面
JADE是DE的变体,近年来优秀的算法都是以JADE为基础改进的,其最大的优势在于通过使用可选的外部归档实施新的变异策略 " DE/current-to-pbest " with optional external archive,外部归档利用历史数据提供进度方向信息。并以自适应方式更新控制参数 F,Cr 来提高优化性能。这使得算法在提高了收敛性能的同时保持了人口多样性。
接下来讲解JADE的各个阶段,与DE相似的地方不再赘述(初始化,交叉,选择),参考前一篇博客。其实只改变了变异阶段,此外将Cr参数自适应化了。
Mutation
1.DE/current-to-pbest without external archive:
Vi,g = Xi,g + Fi * (Xbest,gp - Xi,g) + Fi * (Xr1,g - Xr2,g)
上式是不带有外部归档的变异策略,p为预先设定的优秀率。举个例子,假如p=0.05,以100个个体为例,就从群体的前5%选出最优秀的个体,也就是前五名个体,组成Xbest,g参与变异。同样的 r1 != r2 != i ;
2.DE/current-to-pbest with external archive:
Vi,g = Xi,g + Fi * (Xbest,gp - Xi,g) + Fi * (Xr1,g - Xr2,g)
1与2的区别就在于上式加粗的Xr2,g部分,在带有外部归档archive的变异中,Xr2,g选取自当前群体和外部归档的∪集中,即:有一定概率从当前群体中选取,也有一定概率从外部归档中选取。
注意重点来了!!!
前一个差分向量 (Xbest,gp - Xi,g) :代表了群体中的个体都向前几名最优解学习,也即贪婪策略,加速收敛;
后一个差分向量 (Xr1,g - Xr2,g):代表了有一部分个体是从外部归档中选择的,外部归档与此时此刻的群体不相似,也即在这里扩大了群体的多样性,避免陷入局部最优。
这是我认为的JADE平衡好在提高了收敛性能的同时保持了人口多样性的关键。当然,聪明的读者发现了可以在两个差分向量之间施以不同的权重来改进算法,这也是我第一次想创新时想出的最简单的改进了。
P.S:在JADE中,外部归档有一个规定的大小,大小和初始群体大小相同。这就出现了一个问题,当外部归档的数量超出了popsize怎么办呢?简单的随机移除多余的就好。
Parameter Adaptation
1.CR
Cr 根据均值为uCr,标准差为0.1的正态分布产生。uCr初始设置为0.5。
CRi = randni( uCr , 0.1 )
将每一代成功的个体的CR值存储起来,即为SCR,在每一次迭代后,更新uCR的值为:
uCR = (1-c) * uCR + c * meanA( SCR )
uCR 的范围在[0,1] ; meanA(SCR)代表S中所有CR的算数平均数,c是权值,设置为0.5;
2.F
F 根据均值为uF,标准差为0.1的柯西分布产生。uF初始设置为0.5。
Fi = randci( uF , 0.1 )
同样的,将每一代成功的个体的F值存储起来,即为SF,在每一次迭代后,更新uF的值为:
uF = (1-c) * uF + c * meanL( SF )
meanL( SF )是 Lehmer mean:
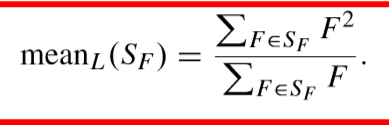
贴一下伪代码:


















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









