







DeepLearning-多种因素影响下的Logistic Regression Model
主要来源于刘二大人的 Lesson7 多因素影响下的逻辑回归
https://www.bilibili.com/video/BV1Y7411d7Ys?p=7&vd_source=23209a5301e1e153f6f18b8234c3f5d1
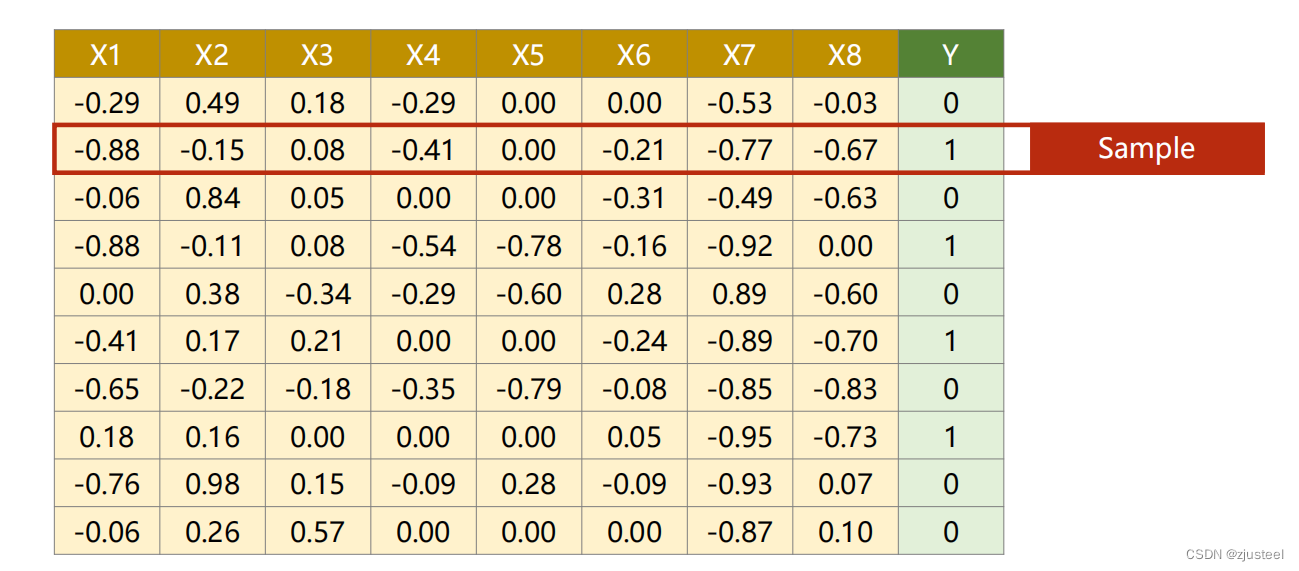
1. 解决的问题
X1-X8种因素共同影响 Y的0-1 分布
该问题为 多自变量的 Logistic Regression Model
2. 模型
2.1 基础模型
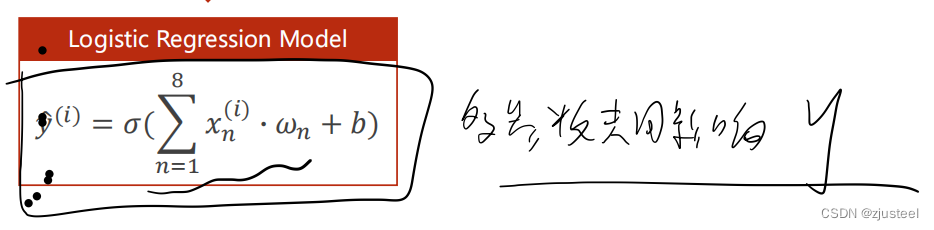
多权重问题 外面的函数使得归为 0-1之间
2.2 归为矩阵
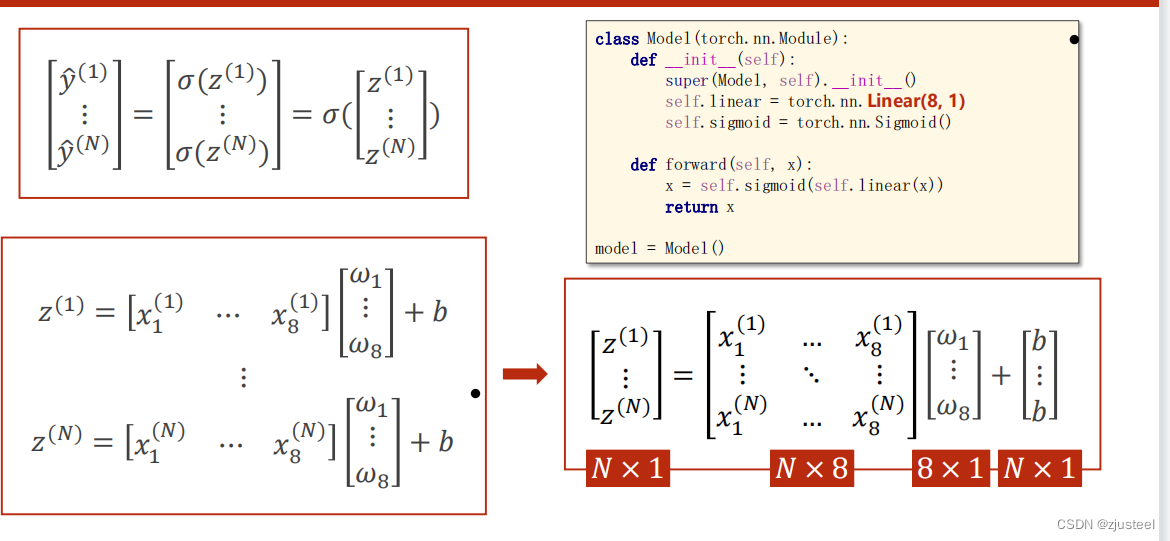
Linear(8,1) 就是线性的8维度缩减为1维度 ,也可以理解为8个因素共同线性地影响1个因素
要考虑非线性以及归于0,1 外面需要嵌套 Sigmoid函数或者 Relu函数
2.3 什么叫做 ANN Artificial Neural Network
线形层多嵌套,Z1=WX1+B 然后把计算的 Z1作为 X2输入 Z2=WZ1+B
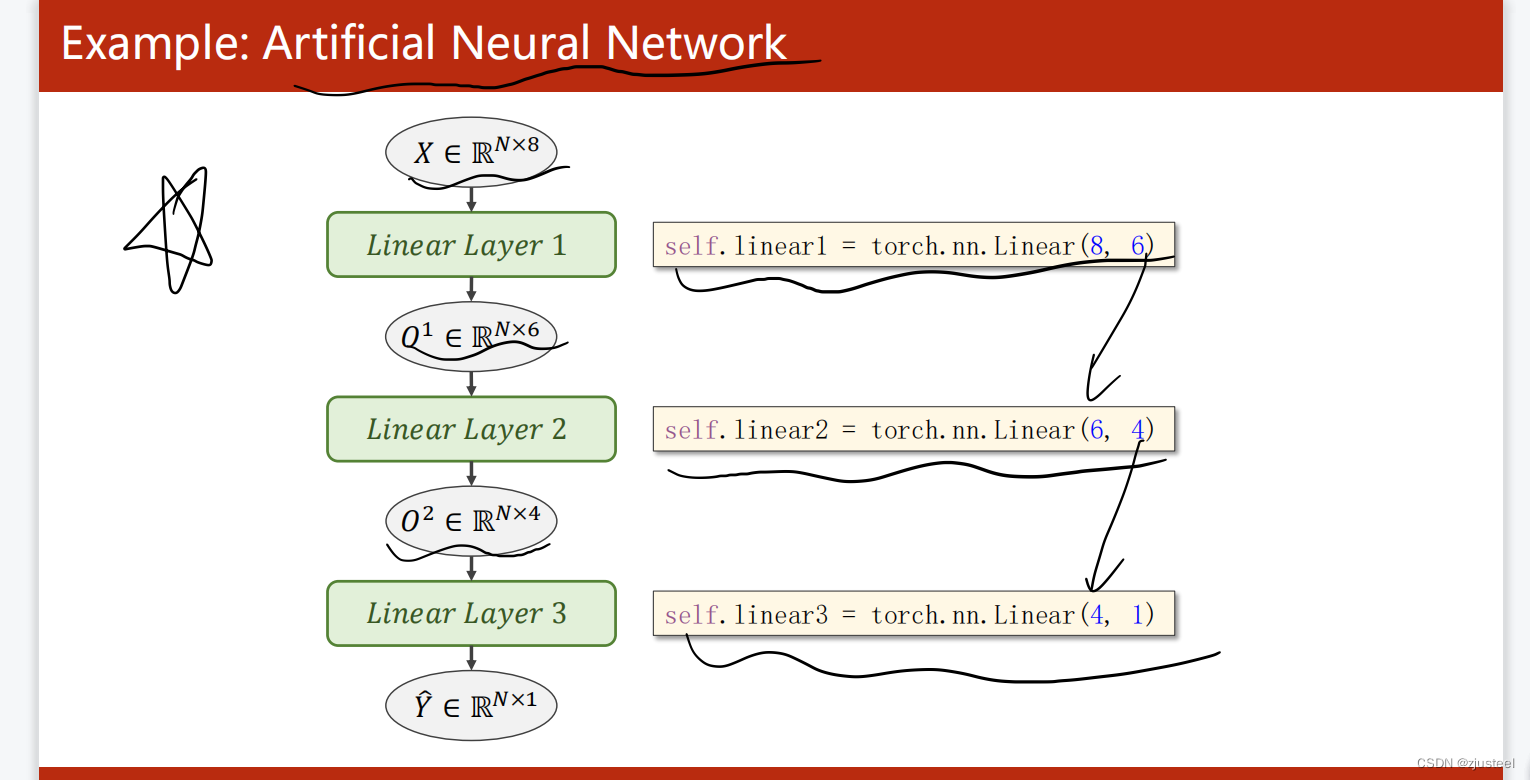
2.4 pytorch程序计算框图
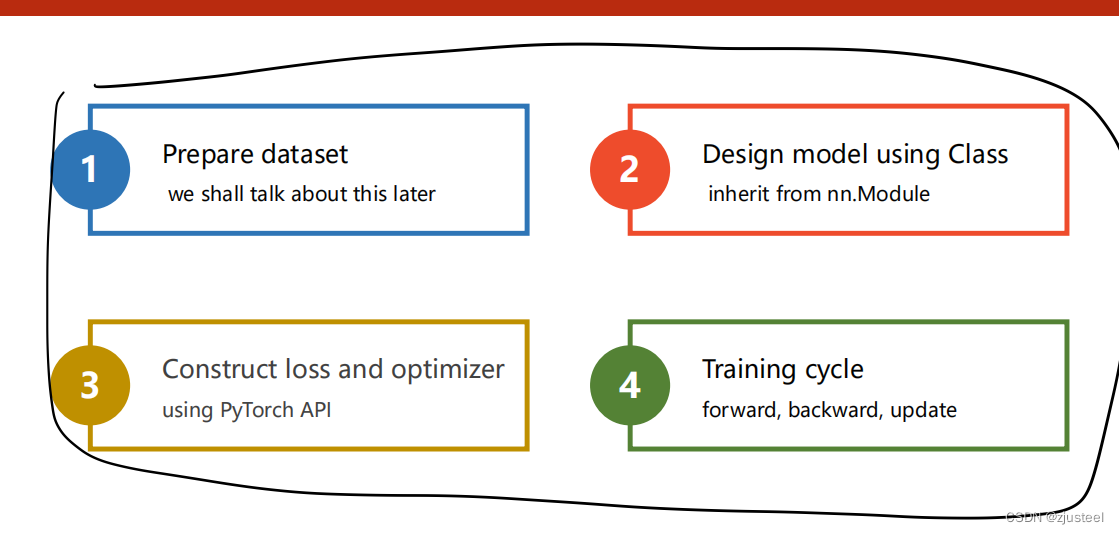
3. 代码实现
输出一个excel表格(也就是训练的y表格 最后一组)
输出一个 Loss-epoch曲线
# 我电脑上pytorch报错,OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized
# 下面两行代码放到程序最上面
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
# 典型计算package
import torch
import matplotlib.pyplot as plt
import numpy as np
# 1. 加载数据集
# 调用 numpy 加载 csv 文件 并且tensor可以直接从numpy中导出
# numpy的laod函数 delimeter 分隔符,csv按照逗号分割 dtype导入的数据类型
xy=np.loadtxt("E:\机器学习与python\PyTorch深度学习实践-刘二大人\diabetes.csv.gz", delimiter="," ,dtype=np.float32)
# xy=np.loadtxt("E:\机器学习与python\PyTorch深度学习实践-刘二大人\diabetes.csv.gz", delimiter=",",dtype=np.float32)
x_data=torch.from_numpy(xy[:,:-1]) #所有的行和 除了最后一列
y_data=torch.from_numpy(xy[:,[-1]])
print('input x shape=',x_data.shape)
print('input y shape=',y_data.shape)
# 2. 定义模型类 两部分 定义方法和forward方法
class Mymoel(torch.nn.Module):
def __init__(self):
super(Mymoel, self).__init__()
self.linear1=torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 2)
self.linear4 = torch.nn.Linear(2, 1)
self.sigmoid=torch.nn.Sigmoid()
def forward(self,x):
# 每一次都要嵌套sigmoid函数
x=self.sigmoid(self.linear1(x))
x=self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
x = self.sigmoid(self.linear4(x))
return x
model=Mymoel()
# 3. 损失和优化器
# 损失共19种,本次采用BCEloss方法 https://blog.csdn.net/shanglianlm/article/details/85019768
criterion=torch.nn.BCELoss(reduction='mean') # 除了mean 还有sum
# 优化器 本次使用SGD优化器 但是还有Adam优化器可以换着来 https://www.jianshu.com/p/39dac1e24709 十种优化器
optimzer=torch.optim.SGD(model.parameters(),lr=0.1)
# 4. 开始训练
epocharr=[]
lossarr=[]
# 5. 输出结果
for epoch in range(500000):
# forward process
y_pred=model.forward(x_data)
loss=criterion(y_pred,y_data)
epocharr.append(epoch)
lossarr.append(loss.item())
# backward process
optimzer.zero_grad()
loss.backward()
# 更新权重
optimzer.step()
# py中 %是取余地意思 那么我想实现隔着一定数量打印
if epoch % 10000 == 999:
# 此时 y——pred向量 如果大于0.5 我认为是1 否则认为是0
y_label=torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.tensor([0.0]))
# 判断整个的重合率
# torch.eq比较两个tensor的每个元素,哪个位置一样返回True 否则返回False
acc=torch.eq(y_label,y_data).sum().item()/y_data.size(0)
print('loss=',loss.item(),'acc=',acc)
np.savetxt("E:\机器学习与python\PyTorch深度学习实践-刘二大人\pred.csv",y_label.detach().numpy())
plt.plot(epocharr,lossarr)
plt.ylabel("Loss")
plt.xlabel("epoch")
plt.show()
结果输出
训练结论
当训练次数1e6 时候 尽管损失0.28 但是图像发现明显有上升,说明不收敛
当训练次数1e5 时候 损失 0.42 损失太大,而且函数在处于下降阶段,可以继续尝试
当训练次数5e5 时候 损失 0.31 而且函数在处于下降阶段,可以继续尝试 此时其实较好,准确性在0.868
本模型SGD优化器比较好
0.1的学习率收敛效果比较好
训练结果
损失:0.277
平均准确率: 0.866
过程输出
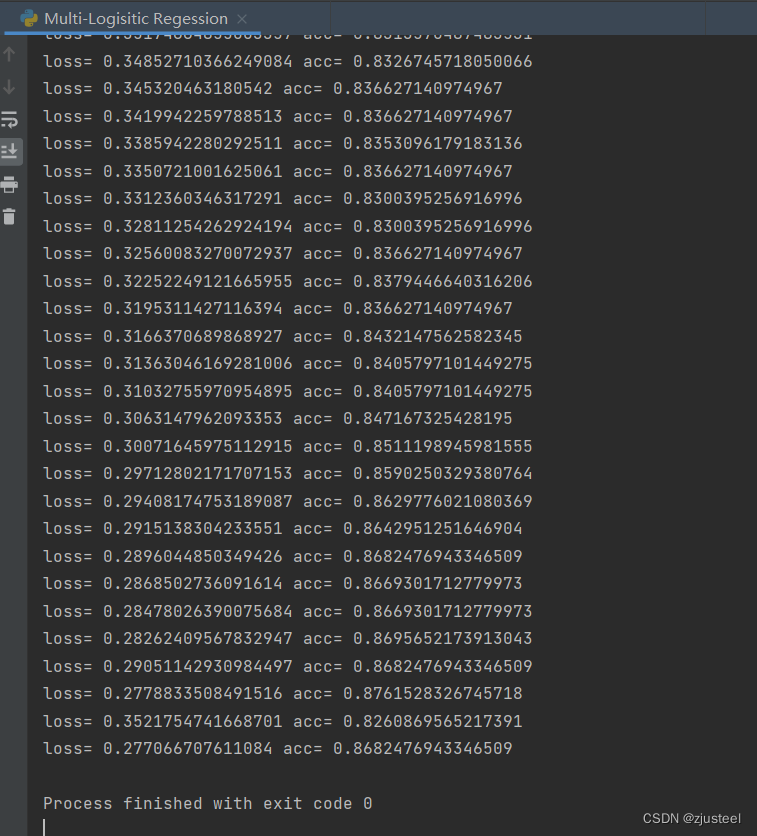
图片
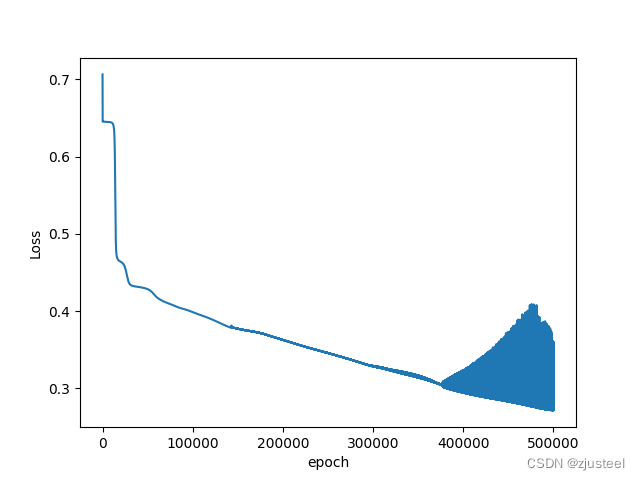
最后貌似不收敛了,可以减少学习次数
excel文件















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









