







基于WIN10的64位系统演示
一、写在前面
至今为止,我们已经讨论了4期的时间序列建模。所有这些都有一个共同特点:它们只包含一个变量,或者用更通俗的话说,就是只有一列数据(不包括时间那一列)。例如,对于某种疾病的发病率的时间序列数据,实际上我们能够使用的就是那一列发病率数据。一些敏锐的读者可能会想,能否添加更多其他变量进行预测,毕竟大力出奇迹嘛。
答案当然是肯定的,否则我们也不会专门讨论这个问题。这些额外添加的数据被称为解释变量。基于这些解释变量构建的模型,我将其称为多变量时间序列预测模型。
二、数据介绍
我们换数据了哈:
使用的是一个公共数据集,主要用于做风速预测,包含一个气象站内的5个天气变量传感器的6574个样本数据,如下表:

从数据中,我们可以看到以下几列:
DATE:日期。
WIND:风速。
IND 和 IND.1:指标0和指标1(具体啥意思我也不懂)。
RAIN:降雨量。
T.MAX:最高温度。
IND.2:指标2(具体啥意思我也不懂)。
T.MIN:最低温度。
T.MIN.G:09UTC草最低温度(我也不懂是啥意思)。
使用GPT-4分析画个图看看:
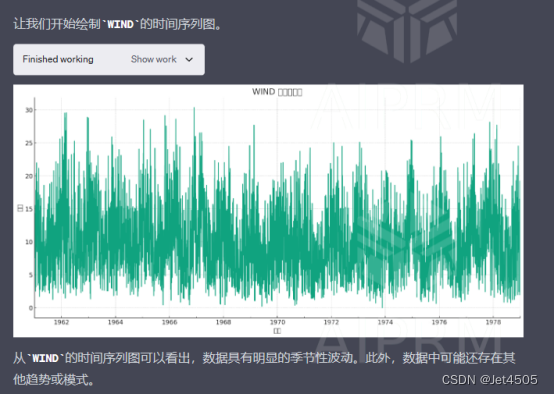
看起来,数据比较潦草。
附上python的代码:
import matplotlib.pyplot as plt
# 将日期列转换为datetime格式,并设置为索引
data['DATE'] = pd.to_datetime(data['DATE'])
data.set_index('DATE', inplace=True)
# 绘制WIND的时间序列图
plt.figure(figsize=(14, 7))
data['WIND'].plot(title='WIND 时间序列图')
plt.ylabel('风速')
plt.xlabel('日期')
plt.grid(True)
plt.tight_layout()
plt.show()三、相关性分析
这一步,有点类似特征工程。
这七个额外变量,哪一个对于风速的预测起到正向作用呢?是需要筛选的,大力不一定出奇迹,还得使用巧劲哈。
下面是我和GPT-4的学术探讨:
GPT:接下来,我们将计算WIND与其他变量之间的相关性,以确定哪些变量可能与WIND有关。这可以帮助我们在建模时选择适当的特征。代码为:
# 计算WIND与其他变量之间的相关性
correlations = data.corr()['WIND'].drop('WIND')
correlations以下是WIND与其他变量之间的相关性:
IND:-0.0386(较低的负相关性)
RAIN:0.1209(正相关性)
IND.1:0.0705(正相关性)
T.MAX:-0.2426(质的负相关性,与最高温度负相关意味着温度越高,风速可能越低)
IND.2:0.0479(正相关性)
T.MIN:-0.0930(较低的负相关性)
T.MIN.G:0.0128(几乎无关)
从这些结果中,我们可以看到T.MAX与风速具有中度的负相关性,而RAIN与风速具有较低的正相关性。其他变量与风速的相关性较弱。
所以GPT的逻辑是通过相关性分析筛选额外变量进行后续的模型构建。我觉得有一点瑕疵,就是时间序列的滞后性问题!!!
比如,就温度来说,有没有可能今天的温度会影响明天的风速(此时滞后期数为1)?可能这个例子不太科学,但差不多是这个意思。因此,在做变量筛选的时候,需要考虑滞后性的问题。然后,我请教了GPT。
GPT:您说得对,时间序列数据中的滞后效应是非常重要的。在某些情况下,一个变量的过去值可能会影响另一个变量的未来值。例如,今天的温度可能会影响明天的风速,或者昨天的降雨量可能会影响今天的湿度。这种滞后效应在气象、经济和其他许多领域都是非常常见的。
为了捕捉这种滞后效应,我们可以计算WIND与其他变量的滞后值之间的相关性。通过这种方法,我们可以确定在哪个滞后期数下,各个变量与WIND之间的相关性最强。
让我们为其他变量的滞后值(例如滞后1天、2天等)计算与WIND之间的相关性,并确定哪些滞后值最相关。代码如下:
# 设置最大滞后期数为7,并包括0(表示当天)
max_lag_including_today = 7
correlation_results_0_to_7 = {}
for lag in range(0, max_lag_including_today + 1):
lagged_correlations = {}
for column in exog_variables:
column_name = f'{column}_lag_{lag}'
data[column_name] = data[column].shift(lag)
correlation = data['WIND'].corr(data[column_name])
lagged_correlations[column] = correlation
correlation_results_0_to_7[lag] = lagged_correlations
correlation_df_0_to_7 = pd.DataFrame(correlation_results_0_to_7).T
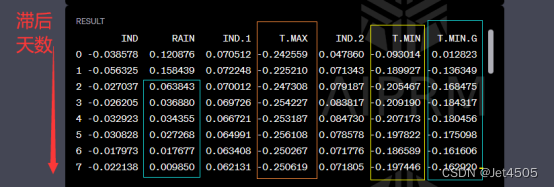
correlation_df_0_to_7看结果:
从上表可以看出:
(1)RAIN在当天和滞后1天还不错,在之后就不行了;
(2)T.MAX不管滞后多久,依旧相关;
(3)T.MIN滞后1天之后,开始展现出相关。
综上,我们尝试使用RAIN、T.MAX、T.MIN(lag3)和T.MIN.G(lag3)建立多因素预测模型。
四、尝鲜ARIMAX模型
我们全程采用GPT运行:
(1)使用RAIN、T.MAX、滞后3天的T.MIN以及滞后3天的T.MIN.G作为外部解释变量,建立多因素ARIMAX预测模型
首先,我会创建这些滞后特征。然后,我们会使用ARIMAX模型进行拟合。由于ARIMA和ARIMAX模型的参数(如差分阶数、AR阶数和MA阶数)通常需要一定的调整,我会使用之前确定的参数(p=1, d=1, q=1)进行建模:
import pandas as pd
import statsmodels.api as sm
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
# 1. 加载数据
data = pd.read_csv('/mnt/data/wind_dataset.csv')
data['DATE'] = pd.to_datetime(data['DATE'])
data.set_index('DATE', inplace=True)
# 2. 创建滞后3天的特征
data['T.MIN_lag_3'] = data['T.MIN'].shift(3)
data['T.MIN.G_lag_3'] = data['T.MIN.G'].shift(3)
# 3. 分割训练集和测试集
train = data.iloc[:-30] # 使用数据集中除最后30天的部分作为训练集
test = data.iloc[-30:] # 使用数据集中最后30天的部分作为测试集
# 4. 定义外部解释变量(训练集和测试集)
exog_train = train[['RAIN', 'T.MAX', 'T.MIN_lag_3', 'T.MIN.G_lag_3']].dropna()
exog_test = test[['RAIN', 'T.MAX', 'T.MIN_lag_3', 'T.MIN.G_lag_3']].dropna()
# 5. 定义因变量
endog_train = train.loc[exog_train.index, 'WIND']
endog_test = test.loc[exog_test.index, 'WIND']
# 6. 拟合ARIMAX模型
model = sm.tsa.ARIMA(endog=endog_train, exog=exog_train, order=(1, 1, 1))
fit_model = model.fit(disp=0)
# 7. 进行预测
forecast = fit_model.forecast(steps=len(endog_test), exog=exog_test)
forecasted_values = forecast[0]
# 使用模型在训练集上进行预测
train_forecast = fit_model.predict(start=exog_train.index[0], end=exog_train.index[-1], exog=exog_train)
# 计算训练集的误差
train_mae = mean_absolute_error(endog_train, train_forecast)
train_mse = mean_squared_error(endog_train, train_forecast)
train_rmse = np.sqrt(train_mse)
train_mape = np.mean(np.abs((endog_train - train_forecast) / endog_train)) * 100
# 计算测试集的误差
test_mae = mean_absolute_error(endog_test, forecasted_values)
test_mse = mean_squared_error(endog_test, forecasted_values)
test_rmse = np.sqrt(test_mse)
test_mape = np.mean(np.abs((endog_test - forecasted_values) / endog_test)) * 100
(train_mae, train_mape, train_mse, train_rmse), (test_mae, test_mape, test_mse, test_rmse)结果:
训练集:
MAE (平均绝对误差):3.13
MAPE (平均绝对百分比误差):无法计算
MSE (均方误差):15.69
RMSE (均方根误差):3.96
测试集:
MAE (平均绝对误差):4.61
MAPE (平均绝对百分比误差):无法计算
MSE (均方误差):32.66
RMSE (均方根误差):5.71
很抱歉,我们在计算MAPE(平均绝对百分比误差)时遇到了问题,导致了一个无穷大的值。这可能是由于数据集中有些值为0,导致在计算MAPE时出现了除以0的情况。
(2)使用RAIN、T.MAX作为外部解释变量,建立多因素ARIMAX预测模型
结果:
训练集:
MAE (平均绝对误差):3.13
MAPE (平均绝对百分比误差):无法计算
MSE (均方误差):15.64
RMSE (均方根误差):3.95
测试集:
MAE (平均绝对误差):4.57
MAPE (平均绝对百分比误差):66.35%
MSE (均方误差):31.82
RMSE (均方根误差):5.64
没什么变化,哈哈哈。
(3)不使用任何外部解释变量,建立多因素ARIMAX预测模型
结果:
训练集:
MAE (平均绝对误差):3.13
MAPE (平均绝对百分比误差):无法计算
MSE (均方误差):15.68
RMSE (均方根误差):3.96
测试集:
MAE (平均绝对误差):4.76
MAPE (平均绝对百分比误差):无法计算
MSE (均方误差):33.76
RMSE (均方根误差):5.81
没什么变化,哈哈哈。
五、总结
(1)纯ARIMA模型的性能与之前的ARIMAX模型相似。在选择使用或不使用外部解释变量时,可以根据具体情况和业务需求进行权衡。有时候为了GUANSHUI文章,可以放进去,美其名曰考虑其他变量?
(2)本期代码全部由GPT-4运行代码并得出结果,这种体验很神奇。
六、数据
链接:https://pan.baidu.com/s/1jnaiJHsPhY9lHDmZsKPuCw?pwd=pr13
提取码:pr13

















 3798
3798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











