










Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba,KDD 2018
Abstract
该工作来自阿里和港科大,主要关注通过用户行为历史构建item图,学习图上所有item的embedding。为了图表示学习中稀疏性和冷启动问题,提出了两种方法结合item embedding和side information。该方法部署在淘宝平台,CTR取得了明显提高。
淘宝平台推荐的三个问题:
1)数据量大:已有的推荐算法可以在小数据集上有不错效果,但是对于百万用户,20亿商品这样海量的数据集上效果差。
2)稀疏性:用户仅与小部分商品交互,难以训练准确的推荐模型。
3)物品冷启动问题:物品上新频繁
本文根据为了解决这三个问题分别提出了三个模型:BES,GES,EGES
淘宝的首页推荐是基于用户过去的行为进行推荐。本文关注的问题在推荐系统的matching,也就是从商品池中召回候选商品的阶段。核心的任务是计算所有item的pairwise similarity。本文提出根据用户行为历史构建一个item graph,然后使用state-of-the-art的graph embedding方法学习每个item的embedding,这被称为Base Graph Embedding(BGE)。在该方式下,可以基于items的embeddings向量进行点积计算pairwise similarity。BGE优于CF,但是对于少量或者没有交互行为的item,仍然难以得到准确的embedding。为了减轻该问题,本文提出使用side information来增强embedding过程,提出了Graph Embedding with Side information (GES)。例如,属于相似类别或品牌的item的embedding应该相近。在这种方式下,即使item只有少量交互或没有交互,也可以得到准确的item embedding。在淘宝场景下,side information包括:category,brand,price等。不同的side information对于最终表示的贡献应该不同,于是本文进一步提出一种加权机制用于学习embedding with side information,称为Enhanced Graph Embedding with Side information (EGES)。
根据用户行为历史构建item graph
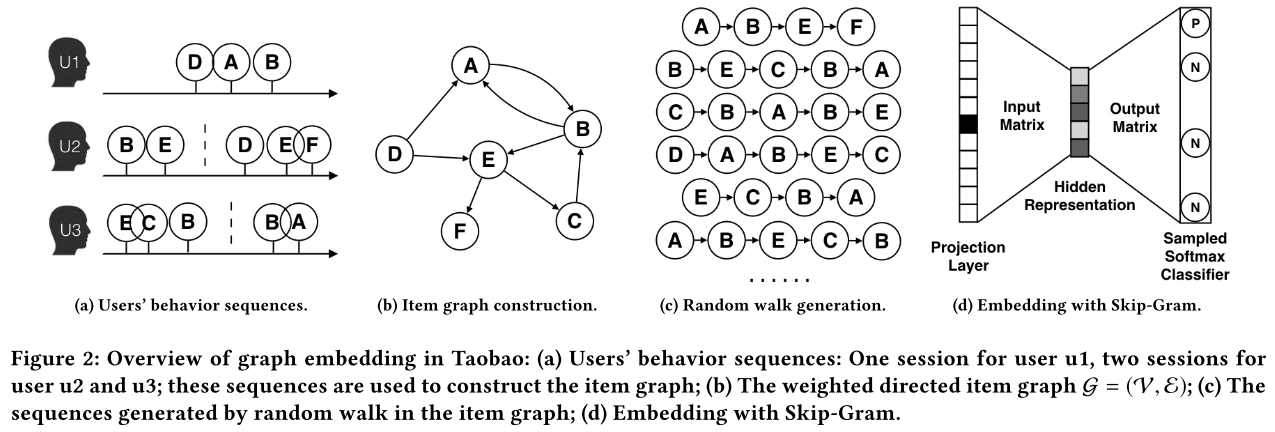
之前基于CF的方法只考虑了项目的共现,但忽略了序列信息(可以更精准地影响使用者的偏好)。在实际中不可能使用用户的全部历史,因为(1)计算复杂度大(2)用户兴趣随着时间改变。在实际中设置一个时间窗口,只选取窗口内的用户行为,通常选取窗口大小为1个小时。这样取得的用户行为称为session-based users’ behavior。
如果两个item连续出现,则有一条有向边连接。基于在所有用户行为中这两个item出现的总次数,为每条边 e i j e_{ij} eij分配权重,该权重等于item i转移到item j的频次。 在抽取用户行为序列时,需要过滤掉噪声行为(无效/异常数据):
- 停留时长少于1s
- 过度活跃用户,可能是spam user
- 同一个商品多次更新后id相同,但是可能变成不同item
BGE(Base Graph Embedding)
本文的基础框架,通过上述方法得到ietm graph。使用deep walk算法,经过随机游走得到序列,输入skip-gram进行训练。
GES(Graph Embedding with Side information)
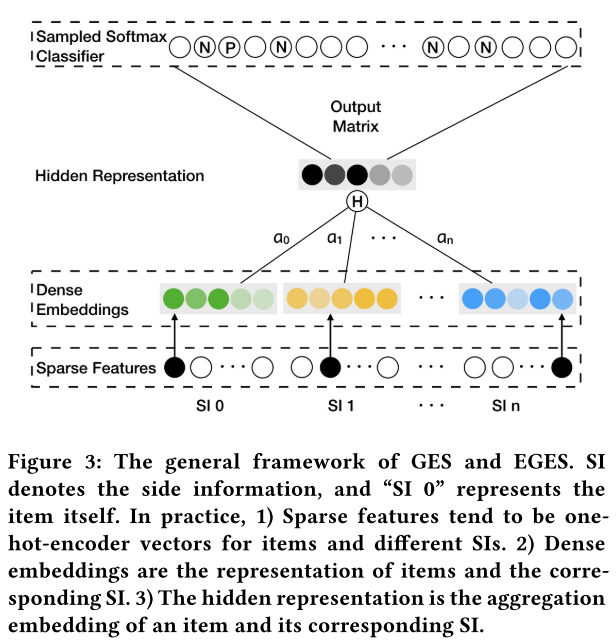
W v 0 {\bf W}_v^0 Wv0 表示item v的embedding; W v s {\bf W}_v^s Wvs表示item v的s-th类型的side information的embedding。由此得到 n + 1 个向量 W v 0 , . . . , . . . W v n ∈ R d {\bf W}_v^0,...,...{\bf W}_{v}^{n} \in \mathbb{R}^d Wv0,...,...Wvn∈Rd ,其中d为embedding维度。通常设置item和side information的embedding维度相同。
将item和side information的embedding结合,采用average-pooling操作,得到item v聚合后的embedding:
H
v
=
1
n
+
1
∑
s
=
0
n
W
v
s
{\bf H}_v = \frac{1}{n+1} \sum_{s=0}^{n}{\bf W}_v^s
Hv=n+11s=0∑nWvs
相似side information的item在embedding空间中会更接近。在网路输入时,将item的one-hot和各个属性的one-hot作为输入,得到embedding后进行平均,然后通过一个隐含层。
EGES(Enhanced Graph Embedding with Side Information)
在GES中,假设不同类型的side information对最终embedding的贡献相同,这并不符合实际。例如,一个买了iPhone的用户购买Apple品牌的Macbook或者iPad;而一个购买不同品牌衣服的用户,出于便利和低价的原因会在相同的淘宝店上锦绣购买。因此不同类的side information对于用户行为中item共现关系的贡献是不同的。在得到item和SI的embedding后,加权平均进入隐含层。
给定一个item v,
A
∈
R
∣
V
∣
×
(
n
+
1
)
{\bf A} \in \mathbb R ^{|V| \times (n+1)}
A∈R∣V∣×(n+1) 是权重矩阵,其中
A
i
j
{\bf A}_{ij}
Aij 是i-th item的j-th SI的权重。为了方便用
a
v
s
a_v^{s}
avs 表示item v和s-th SI的权重。
H
v
=
∑
j
=
0
n
e
a
v
j
W
v
j
∑
j
=
0
n
e
a
v
j
{\bf H}_v = \frac{\sum_{j=0}^n e^{a_v^j} {\bf W}_v^j}{\sum_{j=0}^ne^{a_v^j}}
Hv=∑j=0neavj∑j=0neavjWvj
其中使用
e
a
v
j
e^{a_v^j}
eavj 替代
a
v
j
a_v^j
avj 是为了保证每个SI的贡献都大于0;
∑
j
=
0
n
e
a
v
j
\sum_{j=0}^ne^{a_v^j}
∑j=0neavj 用于归一化不同SI的权重















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









