









题目:Structural Deep Network Embedding
作者:Daixin Wang, Peng Cui, Wenwu Zhu
来源:KDD 2016
SDNE是第一个将深度学习应用于网络表示学习中的方法。SDNE使用一个自动编码器结构来同时优化1阶和2阶相似度(LINE是分别优化的),学习得到的向量表示能够保留局部和全局结构,并且对稀疏网络具有鲁棒性。
和之前使用浅层神经网络的方法(deepwalk)不同, SDNE使用深层神经网络对节点表示间的非线性进行建模。整个模型可以被分为两个部分: 一个是由 Laplace 矩阵监督的建模第一级相似度的模块, 另一 个是由无监督的深层自编码器对第二级相似度关系进行建模. 最终 SDNE 算法将深层自编码器的中间层作为节点的网络表示。
模型
相似度定义
SDNE可以看做是基于LINE的扩展,相似度定义和LINE是一样的。1阶相似度衡量的是相邻的两个顶点对之间相似性(本地网络结构)。2阶相似度衡量的是,两个顶点他们的邻居集合的相似程度(全局网络结构)。
SDNE是一个半监督模型,其中无监督的部分通过重建每个节点的邻居结构保留图的二阶相似度;对于小部分节点对,利用其一阶相似度作为监督信息进行优化。
二阶相似度优化目标
L = ∑ i = 1 n ∥ x ^ i − x i ∥ 2 2 \mathcal{L}=\sum_{i=1}^{n}\left\|\hat{\mathbf{x}}_{i}-\mathbf{x}_{i}\right\|_{2}^{2} L=i=1∑n∥x^i−xi∥22
这里我们使用图的邻接矩阵进行输入,对于第 i i i 个顶点,有 x i = s i x_i = s_i xi=si,每一个 s i s_i si 都包含了顶点 i i i 的邻居结构信息,所以这样的重构过程能够使得结构相似的顶点具有相似的embedding。
这里存在的一个问题是由于图的稀疏性,邻接矩阵 S S S中的非零元素是远远少于零元素的,那么对于神经网络来说只要全部输出0也能取得一个不错的效果,这不是我们想要的。
文章给出的一个方法是使用带权损失函数,对于非零元素具有更高的惩罚系数。 修正后的损失函数为
L
2
n
d
=
∑
i
=
1
n
∥
(
x
^
i
−
x
i
)
⊙
b
i
∥
2
2
=
∥
(
X
^
−
X
)
⊙
B
∥
F
2
\begin{aligned} \mathcal{L}_{2 n d} &=\sum_{i=1}^{n}\left\|\left(\hat{\mathbf{x}}_{i}-\mathbf{x}_{i}\right) \odot \mathbf{b}_{\mathbf{i}}\right\|_{2}^{2} \\ &=\|(\hat{X}-X) \odot B\|_{F}^{2} \end{aligned}
L2nd=i=1∑n∥(x^i−xi)⊙bi∥22=∥(X^−X)⊙B∥F2
其中
⊙
\odot
⊙ 为逐元素积,
b
i
=
{
b
i
,
j
}
j
=
1
n
\mathbf{b}_{\mathbf{i}}=\left\{b_{i, j}\right\}_{j=1}^{n}
bi={bi,j}j=1n 。如果
s
i
,
j
=
0
,
b
i
,
j
=
1
s_{i,j} = 0, b_{i,j} =1
si,j=0,bi,j=1,否则
b
i
,
j
=
β
>
1
b_{i,j} = \beta >1
bi,j=β>1。
一阶相似度优化目标
L 1 s t = ∑ i , j = 1 n s i , j ∥ y i ( K ) − y j ( K ) ∥ 2 2 = ∑ i , j = 1 n s i , j ∥ y i − y j ∥ 2 2 \begin{aligned} \mathcal{L}_{1 s t} &=\sum_{i, j=1}^{n} s_{i, j}\left\|\mathbf{y}_{i}^{(K)}-\mathbf{y}_{j}^{(K)}\right\|_{2}^{2} \\ &=\sum_{i, j=1}^{n} s_{i, j}\left\|\mathbf{y}_{i}-\mathbf{y}_{j}\right\|_{2}^{2} \end{aligned} L1st=i,j=1∑nsi,j∥∥∥yi(K)−yj(K)∥∥∥22=i,j=1∑nsi,j∥yi−yj∥22
其中 y i ( K ) \mathbf{y}_i^{(K)} yi(K) 是第 i i i个节点第 k k k层的输出,即隐含空间表示。该损失函数可以让图中的相邻的两个顶点对应的embedding vector在隐含空间接近。
L
1
s
t
\mathcal{L}_{1 s t}
L1st 还可以表示为
L
1
s
t
=
∑
i
,
j
=
1
n
s
i
,
j
∥
y
i
−
y
j
∥
2
2
=
2
tr
(
Y
T
L
Y
)
\mathcal{L}_{1 s t}=\sum_{i, j=1}^{n} s_{i, j}\left\|\mathbf{y}_{i}-\mathbf{y}_{j}\right\|_{2}^{2}=2 \operatorname{tr}\left(Y^{T} L Y\right)
L1st=i,j=1∑nsi,j∥yi−yj∥22=2tr(YTLY)
其中L是图对应的拉普拉斯矩阵,
L
=
D
−
S
L=D-S
L=D−S,
D
i
,
i
=
∑
j
s
i
,
j
D_{i, i}=\sum_{j} s_{i, j}
Di,i=∑jsi,j。
整体优化目标
联合优化目标函数
L
m
i
x
=
L
2
n
d
+
α
L
1
s
t
+
ν
L
r
e
g
=
∥
(
X
^
−
X
)
⊙
B
∥
F
2
+
α
∑
i
,
j
=
1
n
s
i
,
j
∥
y
i
−
y
j
∥
2
2
+
ν
L
r
e
g
\begin{aligned} \mathcal{L}_{m i x} &=\mathcal{L}_{2 n d}+\alpha \mathcal{L}_{1 s t}+\nu \mathcal{L}_{r e g} \\ &=\|(\hat{X}-X) \odot B\|_{F}^{2}+\alpha \sum_{i, j=1}^{n} s_{i, j}\left\|\mathbf{y}_{i}-\mathbf{y}_{j}\right\|_{2}^{2}+\nu \mathcal{L}_{r e g} \end{aligned}
Lmix=L2nd+αL1st+νLreg=∥(X^−X)⊙B∥F2+αi,j=1∑nsi,j∥yi−yj∥22+νLreg
L
r
e
g
\mathcal{L}_{r e g}
Lreg 是L2正则化项,
α
\alpha
α 为控制1阶损失的参数,
ν
\nu
ν 为控制正则化项的参数。
L
reg
=
1
2
∑
k
=
1
K
(
∥
W
(
k
)
∥
F
2
+
∥
W
^
(
k
)
∥
F
2
)
\mathcal{L}_{\text {reg}}=\frac{1}{2} \sum_{k=1}^{K}\left(\left\|W^{(k)}\right\|_{F}^{2}+\left\|\hat{W}^{(k)}\right\|_{F}^{2}\right)
Lreg=21k=1∑K(∥∥∥W(k)∥∥∥F2+∥∥∥W^(k)∥∥∥F2)
模型结构
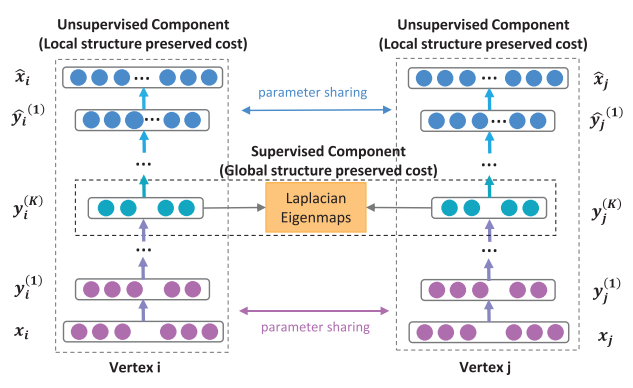
先看左边,是一个自动编码器的结构,输入输出分别是邻接矩阵和重构后的邻接矩阵。通过优化重构损失可以保留顶点的全局结构特性(论文的图画错了,上面应该是Global structure preserved cost)。
再看中间一排, y i ( K ) y_{i}^{(K)} yi(K) 就是我们需要的embedding向量,模型通过1阶损失函数使得邻接的顶点对应的embedding向量接近,从而保留顶点的局部结构特性(中间应该是 Local structure preserved cost)
SDNE在工业界的应用: 凑单算法——基于Graph Embedding的bundle mining
参考资料
https://zhuanlan.zhihu.com/p/56637181
问题
-
为什么重构邻接矩阵可以优化二阶相似度,保留节点的全局结构特性
邻接矩阵中i节点的向量 s i s_i si 包含节点 i 与所有邻居节点的相似度














 1576
1576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









