







论文名:SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation (NeurIPS 2022)
代码:https://github.com/visual-attention-network/segnext
前言
SegNeXt是一个用于语义分割(Semantic Segmentation)的网络模型,它是纯卷积(Convolution)的,结构简单明了。当下,Transformer在计算机视觉领域表现出强大的实力,大量的研究者使用Transformer取代Convolution来解决语义分割等视觉任务,本文则重新审视卷积的结构,用纯卷积网络设计出一个极具竞争力的语义分割模型,在性能上表现优秀。
模型介绍
Transformer中通过使用QKV来实现注意力(Attention)机制,SegNeXt则是使用卷积来实现,即卷积注意力(Convolutionnal Attention),它主要是在VAN(Visual Attention Network)模型的基础上改进的,能更好的捕获多尺度信息,以提高语义分割的精度。
SegNeXt的核心结构如下图:
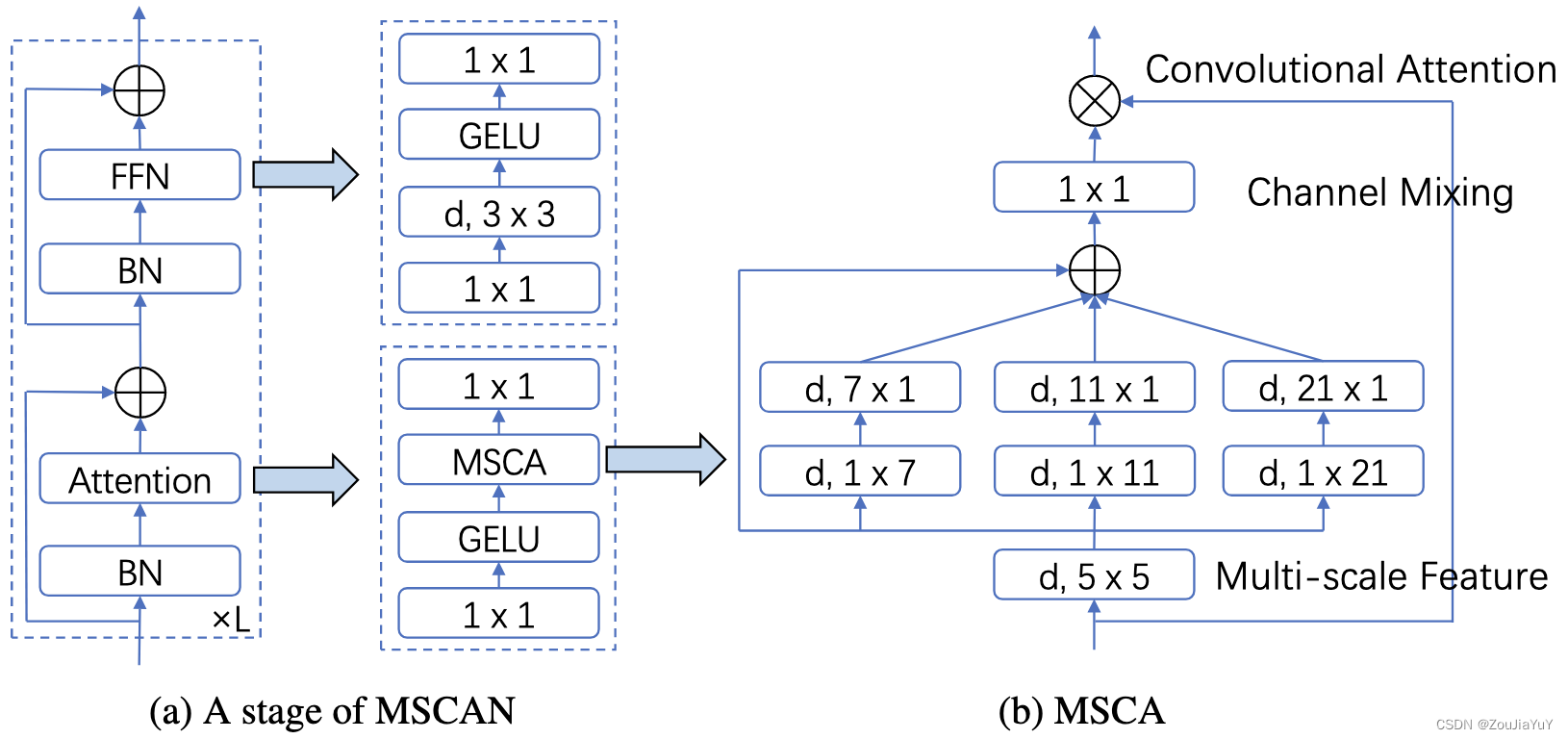
论文最关键的创新就是 multi-scale convolutional attention (MSCA) ,它包含了3个部分:
- depth-wise convolution:获取局部信息;
- multi-branch depth-wise strip convolution:捕获多尺度的上下文信息;
- 1×1 convolution:协调通道之间的信息。
其中,(d, k1×k2) 表示一个卷积核大小为(k1×k2)的depth-wise convolution(DW-Conv)。
MSCA首先将输入进行 5×5 DW-Conv,然后分为3组,分别进行 DW-Conv,以捕获多尺度信息,但这里将设置的7×7、11×11、21×21大小卷积核拆成了两个部分,变成条带卷积(strip convolution)。论文认为,strip convolution有两个优势,一是更加轻量,二是有助于提取带状特征。将各个尺度上的结果相加,送入1×1 Conv,最后与原始输入相乘,实现卷积注意力。
MSCA的原论文代码如下:
class AttentionModule(BaseModule):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv3 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
attn = self.conv3(attn)
return attn * uSegNeXt采用的是经典Encoder-Decoder结构,Enconder为论文提出的MSCAN,由4个阶段构成,Decoder使用了一个轻量级的LightHamHead(来自“Is Attention Better Than Matrix Decomposition?”),如下图 (c) 所示:
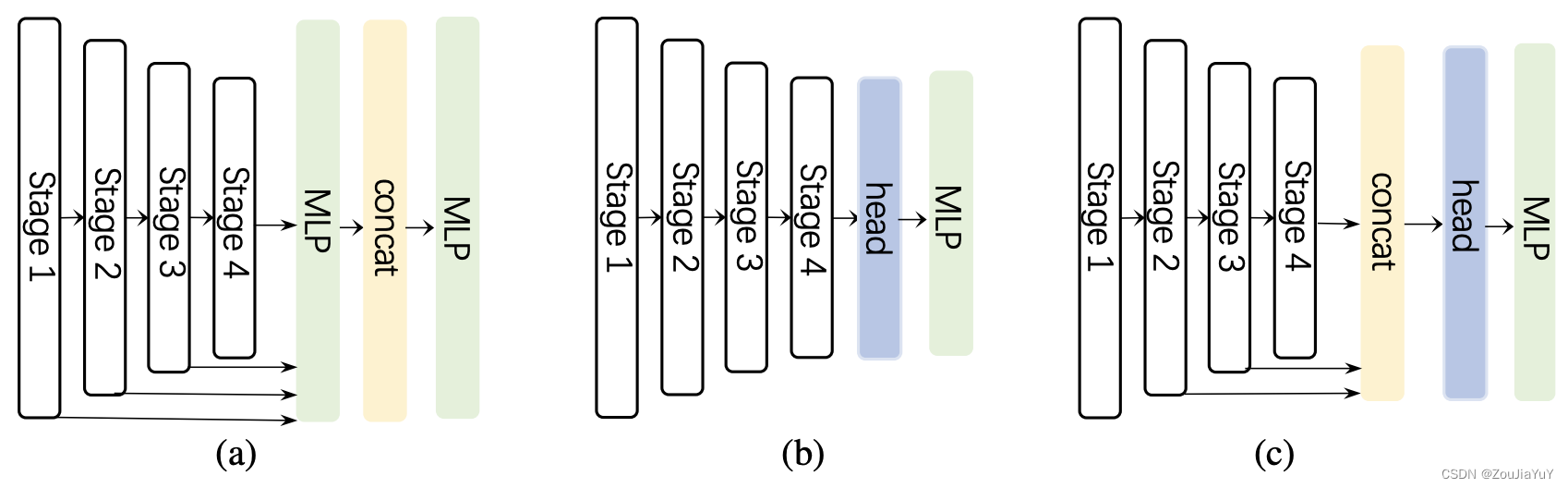
上图中的 (a) 是完全基于MLP的(Segformer),(b) 也是十分常见的将Encoder输出直接用于Decoder的结构。在 (c) 中,Decoder并没有接收Stage1的结果,论文作者发现只使用最后3个Stage的结果获得的最终精度会更好,认为由于SegNeXt是基于卷积的,Stage1包含太多低级信息而影响表现。
对于Encoder部分,论文设计了4个不同大小的模型配置,给出了如下参数:
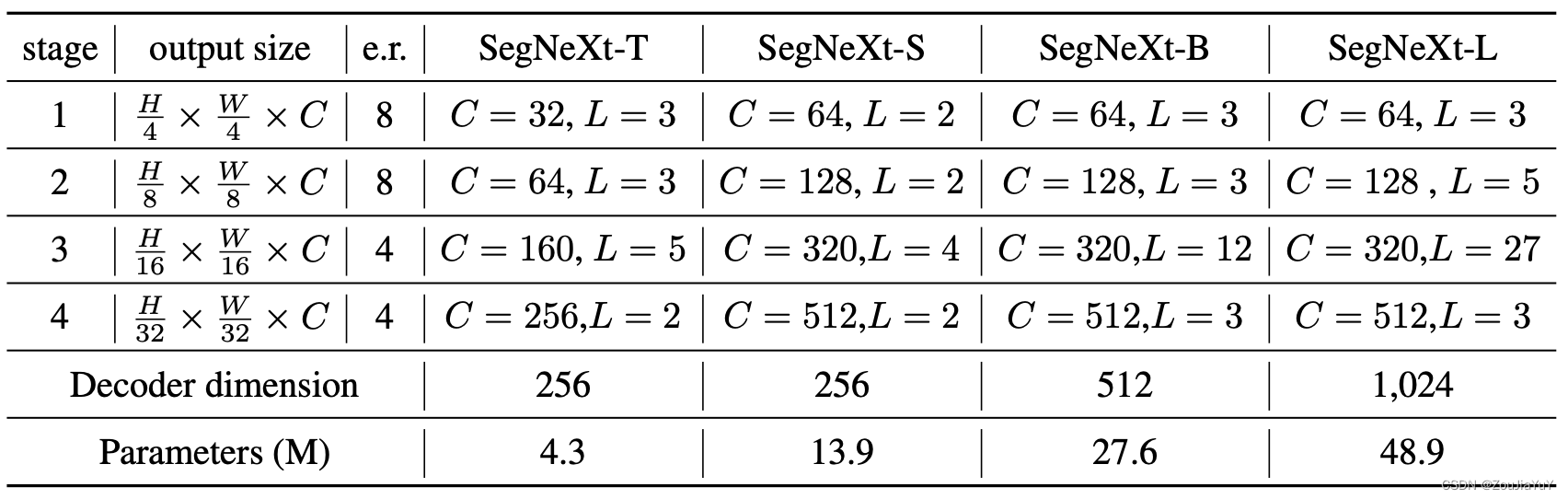
e.r.表示FFN中的膨胀量(通过MLP将输入的通道数in_channels,先扩大,再变为out_channels),C表示通道数,L表示MSCAN的迭代次数。
实验结果分析
下图是论文给出的实验效果图:
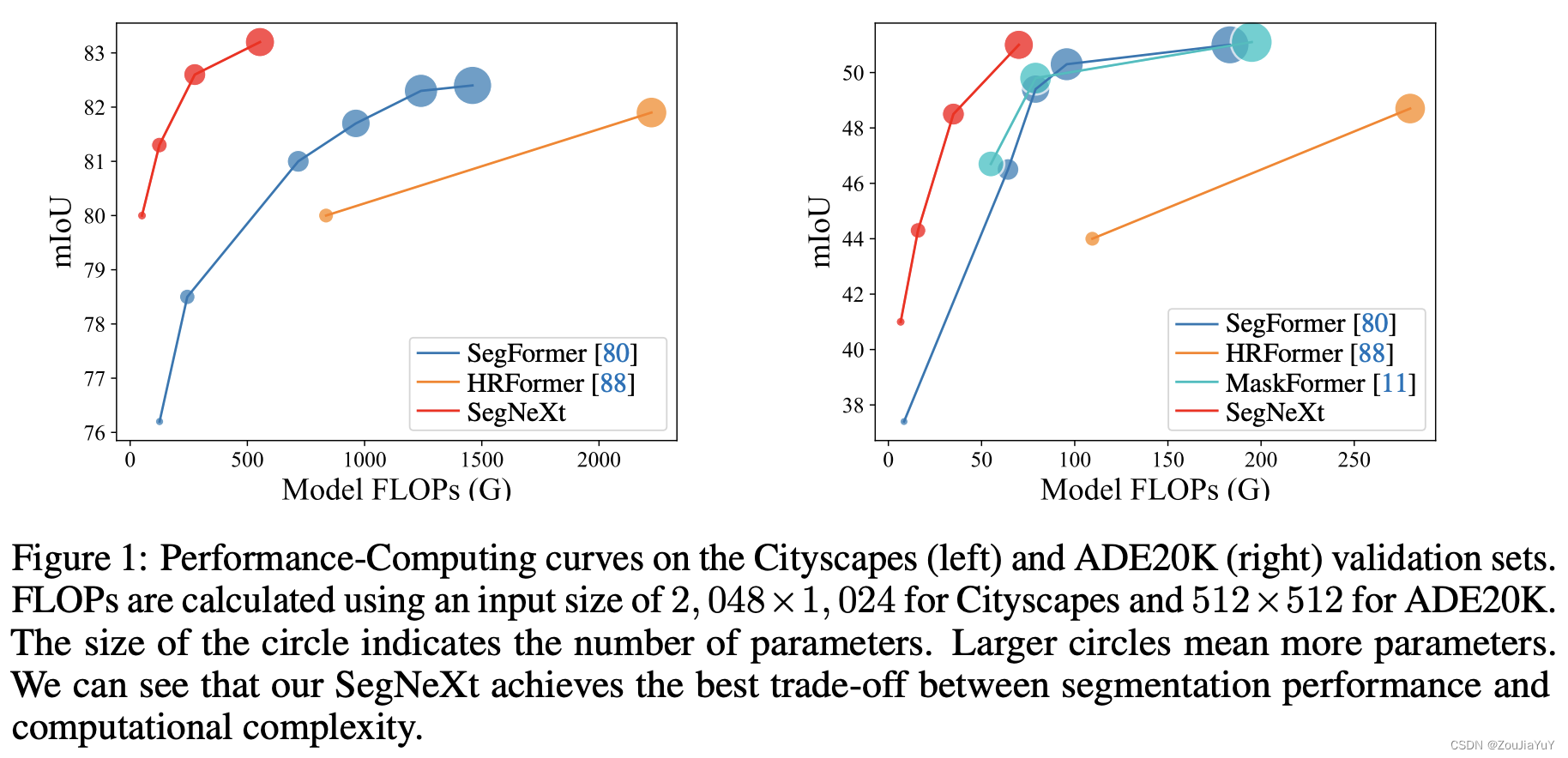
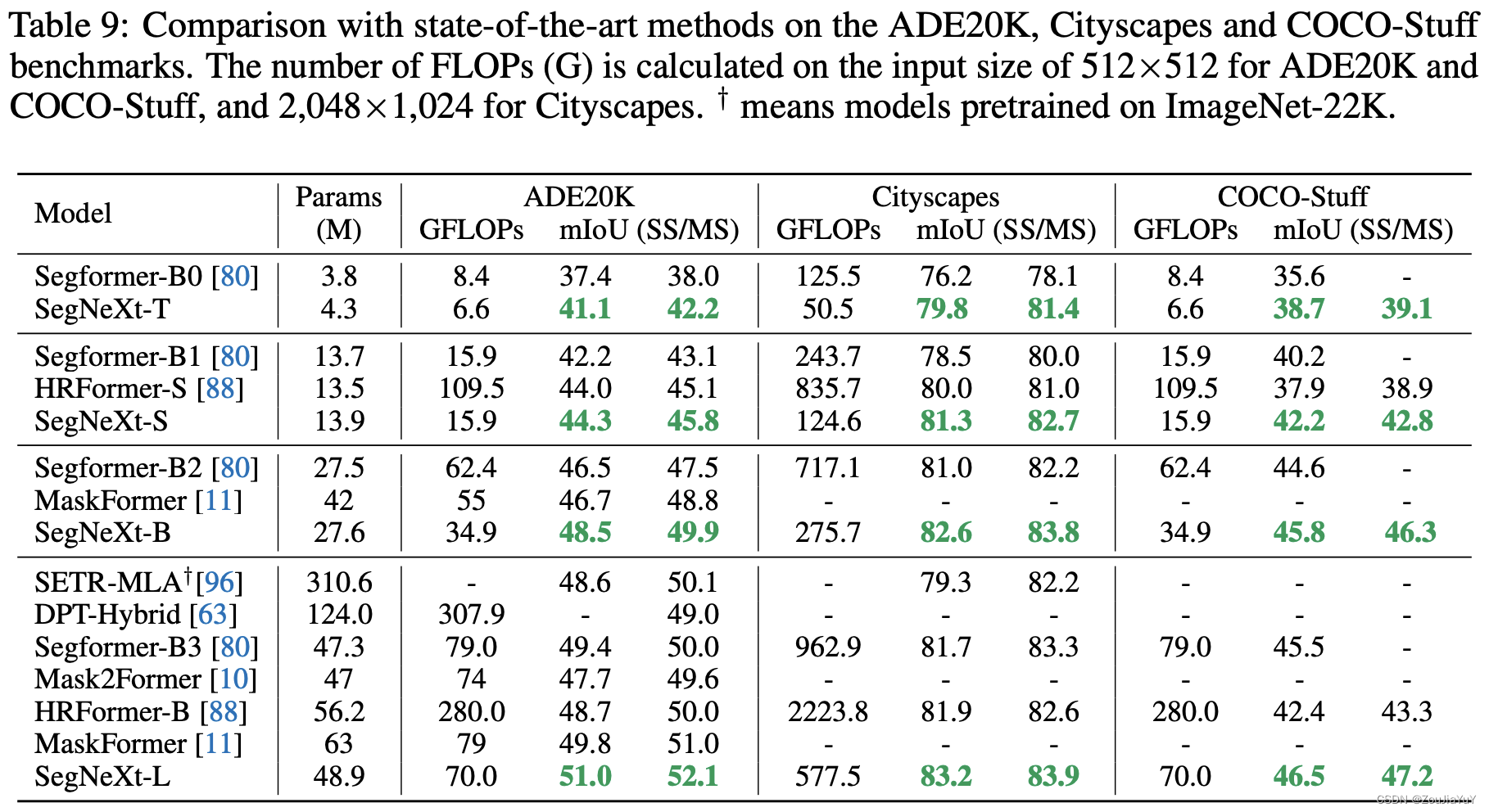
Transformer很大的一个问题就是参数量大,训练成本很高,从上图,我们可以看到,SegNeXt能在保持一个较少参数量的同时,表现出优异的效果,这说明了卷积注意力是一个相当不错的研究方向,我们可以多往这方面思考。
唠叨
对比LKA(VAN中)和MSCA,就有点像ResNet到ResNeXt,将单个的卷积进行分组,实现了性能的提升,但MSCA的分组数量、各组的卷积核大小是遵守什么设计理论得出的?再就是Convolutional Attention,MSCA最后用的乘法,这个又怎么理解?















 2541
2541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









