









Alertmanger作为与Prometheus不可分割的一部分,本着单一性功能的原则,它们的配置都是有上下文关系的。有些Alertmanagerd配置,是基于Prometheus配置的前提下进行的。
所以在这个专题中,我会尽量以“假如现在Prometheus的告警规则配置文件中进行了如下配置,那么Alertmanager的配置文件中应该...” 这样的方式进行描述。从全局的角度为大家讲解我在使用过程中的一些心得体会。
AlertManager 架构图
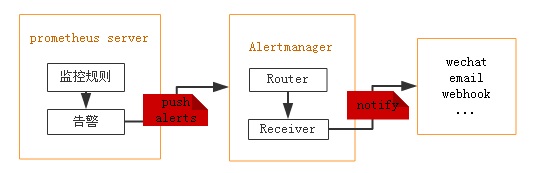
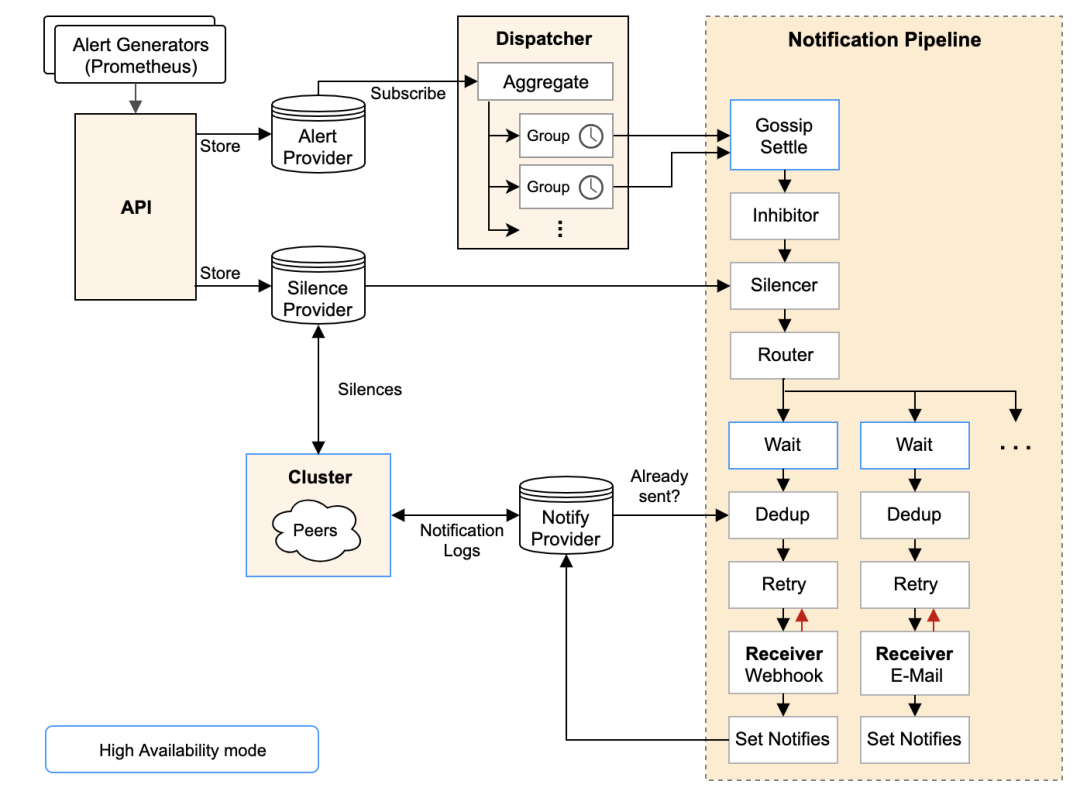
更多关于监控告警项目内容请参考:【监控告警】01-网关的需求与改造
告警分组
Alertmanager 告警分组:
比如:我们有3台服务器都接入了Prometheus,这3台服务器同时宕机了,那么如果不分组可能会发送3个告警信息;如果分组了,那么会合并成一个大的告警信息。
假如现在Prometheus的告警规则配置文件中进行了如下配置:
groups:
- name: Test-001 # 组的名字,在这个文件中必须要惟一
rules:
- alert: InstanceDown # 告警的名字,在组中须要惟一
expr: up == 0 # 表达式, 执行后果为true: 示意须要告警
# 超过多少工夫才认为须要告警(即up==0须要持续的时间) 这个参数主要用于降噪
# 很多类似响应时间这样的指标都是有抖动的,通过指定 Pending Duration,我们可以 过滤掉这些瞬时抖动,让 on-call 人员能够把注意力放在真正有持续影响的问题上。
for: 1m
labels:
severity: warning # 定义标签
annotations:
summary: "服务 {{ $labels.instance }} 下线了"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- name: Cpu
rules:
- alert: Cpu01
expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 80"
for: 1m
labels:
service: demo
severity: info # 自定一个一个标签 info 级别
annotations:
summary: "服务 {{ $labels.instance }} cpu 使用率过高"
description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过来5分钟内应用过高,cpu 使用率 {{humanize $value}}."
- alert: Cpu02
expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 90"
for: 1m
labels:
service: demo
severity: warning # 自定一个一个标签 warning 级别
annotations:
summary: "服务 {{ $labels.instance }} cpu 使用率过高"
description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过来5分钟内应用过高,cpu 使用率 {{humanize $value}}."完成上述配置后,我们在Alertmanager中进行配置:
group_by: ['alertname',‘severity’]这样在产生告警信息时:Alertmanger会按照alertname、severity 这两个维度,对告警信息进行聚合。
告警抑制
Alertmanager 告警抑制:
告警方法中最常见的反模式是发送过多的警报。对于监控来说,过多的警报相当于“狼来了”的故事。收件人会对警报变得麻木,然后将其拒之门外,而重要的警报尝尝被淹没在无关紧要的更新中。
指的是当某类告警产生的时候,与此相关的别的告警就不用发送告警信息了。
假设有如下场景:
1、如果 cpu 在5分钟的使用率超过 80% 则产生告警信息。
2、如果 cpu 在5分钟的使用率超过 90% 则产生告警信息。
假如现在Prometheus中进行了如下配置:
groups:
- name: Test-001 # 组的名字,在这个文件中必须要惟一
rules:
- alert: InstanceDown # 告警的名字,在组中须要惟一
expr: up == 0 # 表达式, 执行后果为true: 示意须要告警
# 超过多少工夫才认为须要告警(即up==0须要持续的时间) 这个参数主要用于降噪
# 很多类似响应时间这样的指标都是有抖动的,通过指定 Pending Duration,我们可以 过滤掉这些瞬时抖动,让 on-call 人员能够把注意力放在真正有持续影响的问题上。
for: 1m
labels:
severity: warning # 定义标签
annotations:
summary: "服务 {{ $labels.instance }} 下线了"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- name: Cpu
rules:
- alert: Cpu01
expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 80"
for: 1m
labels:
service: demo
severity: info # 自定一个一个标签 info 级别
annotations:
summary: "服务 {{ $labels.instance }} cpu 使用率过高"
description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过来5分钟内应用过高,cpu 使用率 {{humanize $value}}."
- alert: Cpu02
expr: "(1 - avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance,job)) * 100 > 90"
for: 1m
labels:
service: demo
severity: warning # 自定一个一个标签 warning 级别
annotations:
summary: "服务 {{ $labels.instance }} cpu 使用率过高"
description: "{{ $labels.instance }} of job {{ $labels.job }} 的 cpu 在过来5分钟内应用过高,cpu 使用率 {{humanize $value}}."完成上述配置后,我们在Alertmanager中进行配置:
inhibit_rules:
#下面配置的含义:当有多条告警在告警组里时,并且他们的标签alertname都相等,如果severity: 'warning'的告警产生了,那么就会抑制severity: 'info'的告警。
- source_match: # 源告警(我理解是根据这个报警来抑制target_match中匹配的告警)
severity: 'warning' # 标签匹配满足severity=warning的告警作为源告警
target_match: # 目标告警(被抑制的告警)
severity: 'info' # 告警必须满足标签匹配severity=info才会被抑制。
equal: ['service'] # 必须在源告警和目标告警中具有相等值的标签才能使抑制生效。(即源告警和目标告警中这三个标签的值相等'alertname')上述配置可以实现:
当收到告警的标签中severity=warning时,触发抑制规则,包含severity=info的告警将被抑制。需要注意的是,还添加了一个equal标签,作用就是source和target中都包含service这个标签,且他们的值一致时,才会抑制(也就是抑制service为demo告警)
告警静默
Alertmanager 告警静默:
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
静默设置需要在Alertmanager的Web页面上进行设置。
接口支持
Alertmanager提供了API组件
用于接收Prometheus服务器的Http请求、获取Alertmanger内部的告警信息等等。
第三方程序如果需要获取Alertmanager的告警记录与告警信息,可以参考如下配置:
官方地址:
https://github.com/prometheus/alertmanager/blob/main/api/v2/openapi.yaml
其中/alert 接口支持添加filter参数进行条件查询。例如:
http://192.168.2.80:9093/api/v2/alerts?filter=alertname=%22NodeAgentStatus%22测试支持
Alertmanager本地测试支持:
当进行 Alertmanager 设置之后,我们希望能够发送告警消息进行测试,以验证配置已生效。但是我们又不能直接关闭服务等待 Prometheus 触发告警消息。
好在 Alertmanager 提供告警接口,允许我们以 HTTP 协议进行调用,来要求其发送告警信息。
该笔记将记录:在 Shell 中,调用 Alertmanager 服务来发送通知的方法,以及相关问题的处理方法。
官方参考: https://prometheus.io/docs/alerting/latest/clients/
发送告警的简单示例:
#!/usr/bin/env bash
alerts_message='[
{
"labels": {
"alertname": "DiskRunningFull",
"dev": "sda1",
"instance": "example1",
"msgtype": "testing"
},
"annotations": {
"info": "The disk sda1 is running full",
"summary": "please check the instance example1"
}
},
{
"labels": {
"alertname": "DiskRunningFull",
"dev": "sda2",
"instance": "example1",
"msgtype": "testing"
},
"annotations": {
"info": "The disk sda2 is running full",
"summary": "please check the instance example1",
"runbook": "the following link http://test-url should be clickable"
}
}
]'触发调用:
curl -XPOST -d"$alerts_message" http://127.0.0.1:9093/api/v1/alertsamtool
Alertmanager AMTool相关内容:
通过这种方式,我们可以模拟测试Alertmanager触发报警。
#触发web报警
./amtool --alertmanager.url=http://10.10.10.22:9093 alert add department=web alertname="xxx流量告警" --annotation=description='xxx每分钟访问量超过15000' --annotation=summary = "xxx流量告警"
#触发api报警
./amtool --alertmanager.url=http://10.10.10.22:9093 alert add department=api alertname="xxx流量告警" --annotation=description='xxx每分钟访问量超过15000' --annotation=summary = "xxx流量告警"除此之外,amtool还可以:
查看当前触发的告警信息(支持查询语句)
告警静默
查看静默信息
告警路由
Alertmanager 告警路由:
其中告警的匹配有两种方式可以选择。
一种方式基于字符串验证:通过设置match规则判断当前告警中是否存在标签labelname并且其值等于labelvalue
第二种方式则基于正则表达式:通过设置match_re验证当前告警标签的值是否满足正则表达式的内容。
# The root route with all parameters, which are inherited by the child
# routes if they are not overwritten.
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [cluster, alertname]
# All alerts that do not match the following child routes
# will remain at the root node and be dispatched to 'default-receiver'.
routes:
# All alerts with service=mysql or service=cassandra
# are dispatched to the database pager.
- receiver: 'database-pager'
group_wait: 10s
matchers:
- service=~"mysql|cassandra"
# All alerts with the team=frontend label match this sub-route.
# They are grouped by product and environment rather than cluster
# and alertname.
- receiver: 'frontend-pager'
group_by: [product, environment]
matchers:
- team="frontend"如果route中设置continue的值为false,那么告警在匹配到第一个子节点之后就直接停止。如果continue为true,报警则会继续进行后续子节点的匹配。
参数理解
对 alertmanager.yml 三种等待时间的理解:
group_wait(首次等待时间)
当alertmanager接收到一条新的alert时,会先根据group_by为其确定一个聚合组group,然后等待group_wait时间,如果在此期间接收到同一group的其他alert,则这些alert会被合并,然后再发送(alertmanager发送消息单位是group)。此参数的作用是防止短时间内出现大量告警的情况下,接收者被告警淹没。
group_interval( 变化等待时间)
在该组的alert第一次被发送后,该组会进入睡眠/唤醒周期,睡眠周期将持续group_interval时间,在睡眠状态下该group不会进行任何发送告警的操作(但会插入/更新(根据fingerprint)group中的内容),睡眠结束后进入唤醒状态,然后检查是否需要发送新的alert或者重复已发送的alert(resolved类型的alert在发送完后会从group中剔除)。这就是group_interval的作用。
repeat_interval(重复等待时间)
聚合组在每次唤醒才会检查上一次发送alert是否已经超过repeat_interval时间,如果超过则再次发送该告警。因此repeat_interval并不代表告警的实际重复间隔,因为在第一次发送告警的repeat_interval时间后,聚合组可能还处在睡眠状态,所以实际的告警间隔应该大于repeat_interval且小于repeat_interval+group_interval。因此实际生产中group_interval值不可设得太大。

labels 与 webhook
使用webhook方式调用第三方服务时,Alertmanager会给配置的webhook地址发送一个http类型的post请求,参数为json字符串,格式如下:
{
"receiver":"webhook",
"status":"resolved",
"alerts":[
{
"status":"resolved",
"labels":{
"alertname":"hostCpuUsageAlert",
"instance":"192.168.199.24:9100",
"severity":"page"
},
"annotations":{
"description":"192.168.199.24:9100 CPU 使用率超过 85% (当前值为: 0.9973333333333395)",
"summary":"机器 192.168.199.24:9100 CPU 使用率过高"
},
"startsAt":"2020-02-29T19:45:21.799548092+08:00",
"endsAt":"2020-02-29T19:49:21.799548092+08:00",
"generatorURL":"http://localhost.localdomain:9090/graph?g0.expr=sum+by%28instance%29+%28avg+without%28cpu%29+%28irate%28node_cpu_seconds_total%7Bmode%21%3D%22idle%22%7D%5B5m%5D%29%29%29+%3E+0.85&g0.tab=1",
"fingerprint":"368e9616d542ab48"
}
],
"groupLabels":{
"alertname":"hostCpuUsageAlert"
},
"commonLabels":{
"alertname":"hostCpuUsageAlert",
"instance":"192.168.199.24:9100",
"severity":"page"
},
"commonAnnotations":{
"description":"192.168.199.24:9100 CPU 使用率超过 85% (当前值为: 0.9973333333333395)",
"summary":"机器 192.168.199.24:9100 CPU 使用率过高"
},
"externalURL":"http://localhost.localdomain:9093",
"version":"4",
"groupKey":"{}:{alertname="hostCpuUsageAlert"}"
}下面labels中包含的标签,同样也是Prometheus的规则文件中配置的,标签在Prometheus中的rules中定义的label,在Alertmanager告警中可以用作分组(group by)操作。
Labels来源
Alertmanager告警中,labels中的标签包含三个部分:
1. 来自promtheus.yml中target配置Label
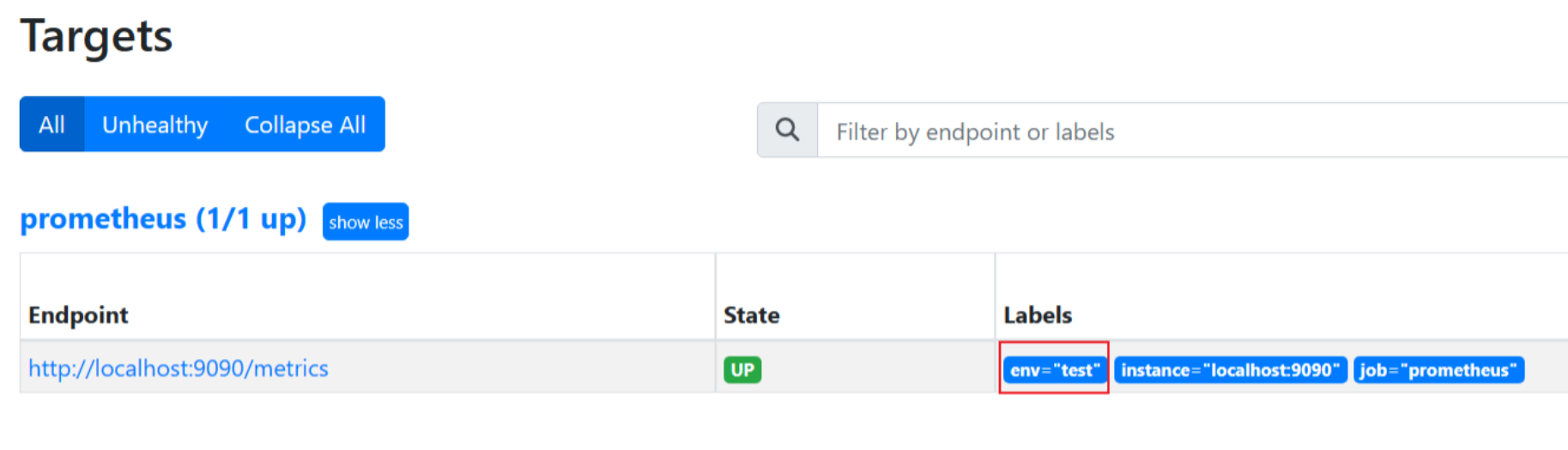
2. 来自Prometheus告警策略yml文件中我们添加进去的label

3. 来自Alertmanger的 label.alertname,可以理解为内置的参数。
启动参数
Alertmanager 常用的启动参数:
#启动alertmanager软件指定配置文件设置监听为0.0.0.0:9093设置日志级别
nohup ./alertmanager --config.file=/software/alertmanager/alertmanager.yml --cluster.advertise-address=0.0.0.0:9093 --log.level=debug > /software/alertmanager/alertmanager.log 2>&1 &
#确认9093端口是否启动,此时命令应该有输出。
ss -alntup | grep -i 9093 生产推荐配置
Alertmanager 生产推荐配置:
group_wait: 1m
group_interval: 15m
repeat_interval: 4h配置文件解析(全)
Alertmanager 配置文件全解析
global:
#该参数定义了当Alertmanager持续多长时间未接收到告警后标记告警状态为resolved。 (即prometheus没有向alertmanager发送告警了)
#该参数的定义可能会影响到告警恢复通知的接收时间,可根据自己的实际场景进行定义,其默认值为5分钟。
resolve_timeout: 5m
# 配置发送邮件信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '742899387@qq.com'
smtp_auth_username: '742899387@qq.com'
smtp_auth_password: 'password'
smtp_require_tls: false
# 读取告警通知模板的目录。
templates:
- '/etc/alertmanager/template/*.tmpl'
# 所有报警都会进入到这个根路由下,可以根据根路由下的子路由设置报警分发策略
route:
# 先解释一下分组,分组就是将多条告警信息聚合成一条发送,这样就不会收到连续的报警了。
# 将传入的告警按标签分组(标签在prometheus中的rules中定义),例如:
# 接收到的告警信息里面有许多具有cluster=A 和 alertname=LatencyHigh的标签,这些个告警将被分为一个组。
#
# 如果不想使用分组,可以这样写group_by: [...]
group_by: ['alertname', 'cluster', 'service']
# 第一组告警发送通知需要等待的时间,这种方式可以确保有足够的时间为同一分组获取多个告警,然后一起触发这个告警信息。
group_wait: 30s
# 发送第一个告警后,等待"group_interval"发送一组新告警。
group_interval: 5m
# 分组内发送相同告警的时间间隔。这里的配置是每3小时发送告警到分组中。举个例子:收到告警后,一个分组被创建,等待5分钟发送组内告警,如果后续组内的告警信息相同,这些告警会在3小时后发送,但是3小时内这些告警不会被发送。
repeat_interval: 3h
# 这里先说一下,告警发送是需要指定接收器的,接收器在receivers中配置,接收器可以是email、webhook、pagerduty、wechat等等。一个接收器可以有多种发送方式。
# 指定默认的接收器
receiver: team-X-mails
# 下面配置的是子路由,子路由的属性继承于根路由(即上面的配置),在子路由中可以覆盖根路由的配置
# 下面是子路由的配置
routes:
# 使用正则的方式匹配告警标签
- match_re:
# 这里可以匹配出标签含有service=foo1或service=foo2或service=baz的告警
service: ^(foo1|foo2|baz)$
# 指定接收器为team-X-mails
receiver: team-X-mails
# 这里配置的是子路由的子路由,当满足父路由的的匹配时,这条子路由会进一步匹配出severity=critical的告警,并使用team-X-pager接收器发送告警,没有匹配到的告警会由父路由进行处理。
routes:
- match:
severity: critical
receiver: team-X-pager
# 这里也是一条子路由,会匹配出标签含有service=files的告警,并使用team-Y-mails接收器发送告警
- match:
service: files
receiver: team-Y-mails
# 这里配置的是子路由的子路由,当满足父路由的的匹配时,这条子路由会进一步匹配出severity=critical的告警,并使用team-Y-pager接收器发送告警,没有匹配到的会由父路由进行处理。
routes:
- match:
severity: critical
receiver: team-Y-pager
# 该路由处理来自数据库服务的所有警报。如果没有团队来处理,则默认为数据库团队。
- match:
# 首先匹配标签service=database
service: database
# 指定接收器
receiver: team-DB-pager
# 根据受影响的数据库对告警进行分组
group_by: [alertname, cluster, database]
routes:
- match:
owner: team-X
receiver: team-X-pager
# 告警是否继续匹配后续的同级路由节点,默认false,下面如果也可以匹配成功,会向两种接收器都发送告警信息
continue: true
- match:
owner: team-Y
receiver: team-Y-pager
# 下面是关于inhibit(抑制)的配置,先说一下抑制是什么:抑制规则允许在另一个警报正在触发的情况下使一组告警静音。其实可以理解为告警依赖。比如一台数据库服务器掉电了,会导致db监控告警、网络告警等等,可以配置抑制规则如果服务器本身down了,那么其他的报警就不会被发送出来。
inhibit_rules:
#下面配置的含义:当有多条告警在告警组里时,并且他们的标签alertname,cluster,service都相等,如果severity: 'critical'的告警产生了,那么就会抑制severity: 'warning'的告警。
- source_match: # 源告警(我理解是根据这个报警来抑制target_match中匹配的告警)
severity: 'critical' # 标签匹配满足severity=critical的告警作为源告警
target_match: # 目标告警(被抑制的告警)
severity: 'warning' # 告警必须满足标签匹配severity=warning才会被抑制。
equal: ['alertname', 'cluster', 'service'] # 必须在源告警和目标告警中具有相等值的标签才能使抑制生效。(即源告警和目标告警中这三个标签的值相等'alertname', 'cluster', 'service')
# 下面配置的是接收器
receivers:
# 接收器的名称、通过邮件的方式发送、
- name: 'team-X-mails'
email_configs:
# 发送给哪些人
- to: 'team-X+alerts@example.org'
# 是否通知已解决的警报
send_resolved: true
# 接收器的名称、通过邮件和pagerduty的方式发送、发送给哪些人,指定pagerduty的service_key
- name: 'team-X-pager'
email_configs:
- to: 'team-X+alerts-critical@example.org'
pagerduty_configs:
- service_key: <team-X-key>
# 接收器的名称、通过邮件的方式发送、发送给哪些人
- name: 'team-Y-mails'
email_configs:
- to: 'team-Y+alerts@example.org'
# 接收器的名称、通过pagerduty的方式发送、指定pagerduty的service_key
- name: 'team-Y-pager'
pagerduty_configs:
- service_key: <team-Y-key>
# 一个接收器配置多种发送方式
- name: 'ops'
webhook_configs:
- url: 'http://prometheus-webhook-dingtalk.kube-ops.svc.cluster.local:8060/dingtalk/webhook1/send'
send_resolved: true
email_configs:
- to: '742899387@qq.com'
send_resolved: true
- to: 'soulchild@soulchild.cn'
send_resolved: true















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









