










目录
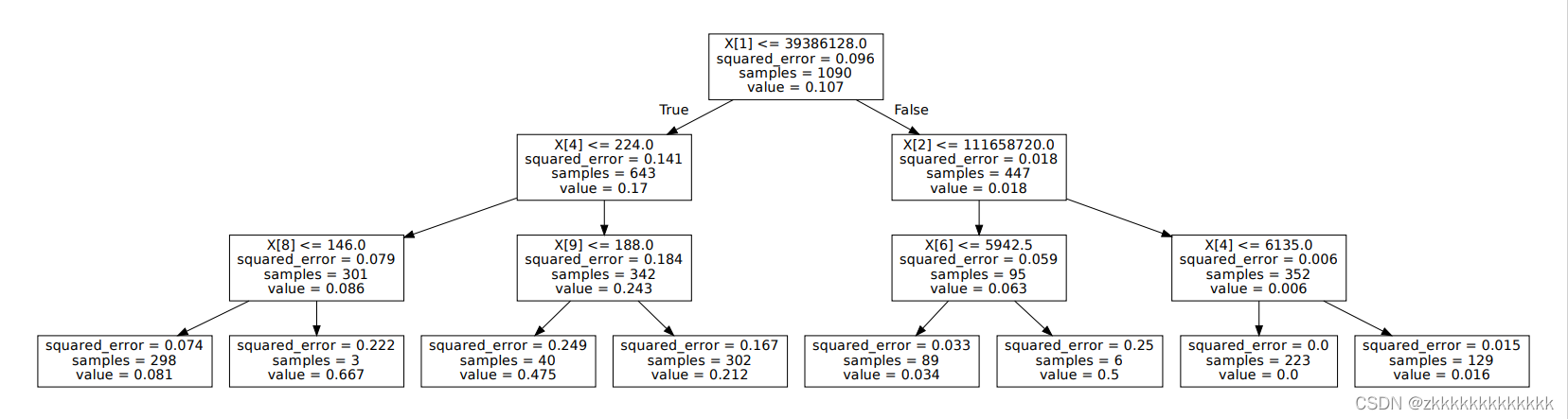
大致表达的意思是,对流水数据聚合特征。然后特征衍生,接着对衍生后的特征决策树训练,输出对应的特征组合。
上图中,x1,x4,x8是叶子结点到根结点的路径,也就是说可以看成一组特征组合。同样,x1,x4,x9为一组。x1,x2,x6为一组。x1,x7,x6为一组,x1,x7,x4为一组。共四组,只需要解析出这几组数,然后去我们训练决策树的样本特征中把对应的特征提取出来,并返回就可以了。
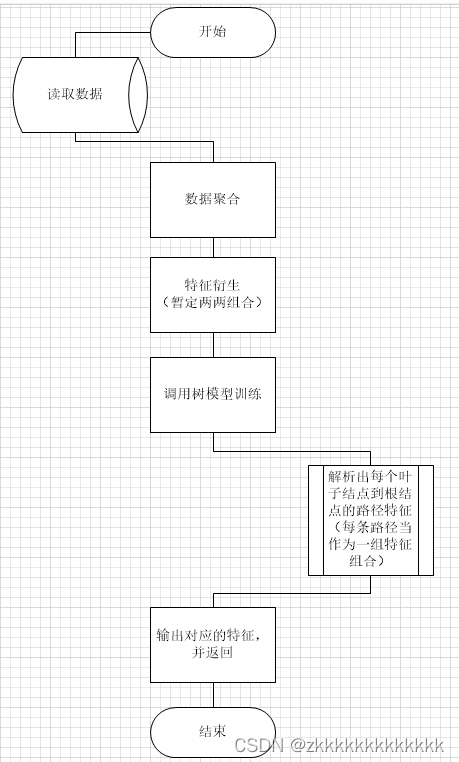
一、基本流程
二、实现代码
因为我这边是用的notebook写的,所以代码一段一段截取。
2.1、导包
import pymysql
import sys
from sqlalchemy import create_engine
from sklearn.ensemble import GradientBoostingClassifier
import pandas as pd
import sys
from sklearn.metrics import classification_report
from sklearn import tree
from sklearn.tree import _tree
from graphviz import Source
from ipywidgets import interactive
from IPython.display import SVG, display
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor, export_graphviz
from sklearn import tree
import graphviz
from collections import deque
import re2.2、读取数据
def query_sql(cursor,sql):
cursor.execute(sql)
res = cursor.fetchall()
col = [item[0] for item in cursor.description]
crash_result = pd.DataFrame(res, columns=col)
return crash_result2.3、特征聚合及衍生
connection = pymysql.connect(host='ip', user='root', password='password', database='xxx',
port=端口)
cursor = connection.cursor()
# 读取标签数据
target_info = pd.read_excel(r'样本标签.xlsx')
target_info = target_info[['卡号','是否可疑(人工)']]
# 计算特征 —— 交易总金额
sql = '''
select `客户名称`,`查询账号`,`查询卡号`,sum(`交易金额`) `交易总金额`
from `trade1`
group by `客户名称`,`查询账号`,`查询卡号`
'''
df_sum_money = query_sql(cursor,sql)
# 交易次数
sql = '''
select `客户名称`,`查询账号`,`查询卡号`,count(1) `交易笔数`
from `trade1`
group by `客户名称`,`查询账号`,`查询卡号`
'''
df_trade_count = query_sql(cursor,sql)
# 入向交易笔数
sql = '''
select `客户名称`,`查询账号`,`查询卡号`,count(1) `入向交易笔数`
from `trade1`
where 借贷标志 = '进'
group by `客户名称`,`查询账号`,`查询卡号`
'''
df_in_num = query_sql(cursor,sql)
# 出向交易笔数
sql = '''
select `客户名称`,`查询账号`,`查询卡号`,count(1) `出向交易笔数`
from `trade1`
where 借贷标志 = '出'
group by `客户名称`,`查询账号`,`查询卡号`
'''
df_out_num = query_sql(cursor,sql)
# 交易总天数
sql = '''
select `客户名称`,`查询账号`,`查询卡号`,count(1) '交易总天数'
from
(
select `客户名称`,`查询账号`,`查询卡号`,substring(`交易时间`,1,10)
from trade1
group by `客户名称`,`查询账号`,`查询卡号`,substring(`交易时间`,1,10)
) a
group by `客户名称`,`查询账号`,`查询卡号`
'''
df_sum_day = query_sql(cursor,sql)
merge1 = pd.merge(df_sum_money,df_trade_count,on=['客户名称', '查询账号', '查询卡号'], how='inner')
merge2 = pd.merge(merge1,df_in_num,on=['客户名称', '查询账号', '查询卡号'], how='inner')
merge3 = pd.merge(merge2,df_out_num,on=['客户名称', '查询账号', '查询卡号'], how='inner')
merge = pd.merge(merge3,df_sum_day,on=['客户名称', '查询账号', '查询卡号'], how='inner')
final_result = pd.merge(target_info,merge,left_on=['卡号'],right_on=['查询卡号'],how='inner')
final_result = final_result.iloc[:,1:]
final_result['是否可疑(人工)'] = final_result['是否可疑(人工)'].apply(lambda x:1 if x == '可疑' else 0)
print(final_result)
print(final_result.info())
x = final_result[['交易总金额','交易笔数','入向交易笔数','出向交易笔数','交易总天数']]
y = final_result['是否可疑(人工)']
print(x[['交易总金额','交易笔数']])
# 两两组合新特征
new_x = pd.DataFrame()
new_x['交易总金额_交易笔数'] = x['交易总金额']+x['交易笔数']
new_x['交易总金额_入向交易笔数'] = x['交易总金额']+x['入向交易笔数']
new_x['交易总金额_出向交易笔数'] = x['交易总金额']+x['出向交易笔数']
new_x['交易总金额_交易总天数'] = x['交易总金额']+x['交易总天数']
new_x['交易笔数_入向交易笔数'] = x['交易笔数']+x['入向交易笔数']
new_x['交易笔数_出向交易笔数'] = x['交易笔数']+x['出向交易笔数']
new_x['交易笔数_交易总天数'] = x['交易笔数']+x['交易总天数']
new_x['入向交易笔数_出向交易笔数'] = x['入向交易笔数']+x['出向交易笔数']
new_x['入向交易笔数_交易总天数'] = x['入向交易笔数']+x['交易总天数']
new_x['出向交易笔数_交易总天数'] = x['出向交易笔数']+x['交易总天数']
print(new_x)
2.4、训练决策树
Dtree = tree.DecisionTreeRegressor(max_depth=3,random_state=111)
dtree = Dtree.fit(new_x, y)
n_nodes = dtree.tree_.node_count
children_left = dtree.tree_.children_left
children_right = dtree.tree_.children_right
feature = dtree.tree_.feature
threshold = dtree.tree_.threshold
dot_data = tree.export_graphviz(dtree, out_file=None, )
graph = graphviz.Source(dot_data)
graph.render("dt")
'''
在文件的同级目录上生成一个dt和dt.pdf文件。
dt.pdf文件存储树模型的可视化
dt文件则是树模型对应的原始数据(非结构化)
'''2.5、解析树模型
relation = []
node = []
for c,i in enumerate(dot_data.replace('\n','').split(';')):
if c == 0 or c == 1:
continue
if '->' in i:
relation.append(i.split('[')[0].strip())
else:
if 'X[' not in i:
i = i.split(' ')[0] + ' None'
node.append(i)
else:
node.append(i)
# 将结点信息转换为字典,方便后续拿取
node_dict = {}
for i in node:
key = i[0:2]
value = i[2:]
node_dict[key.strip()] = value.strip()
# 将结点指针信息转为字典,方便组合特征
relation_dict = {}
agg = []
other = ''
for c,i in enumerate(relation):
i_info = i.replace(' ','').split('->')
if i_info[0] == '0':
agg.append(i_info[0])
agg.append(i_info[-1])
elif i_info[0] == agg[-1] and int(i_info[-1]) - int(i_info[0]) == 1:
agg.append(i_info[-1])
# elif int(i_info[-1]) - int(i_info[0]) != 1:
else:
# 同路径不同结点 与 其子结点
other += f'{i_info[0]}' + f' {i_info[-1]}|'
# 记录根结点位置
node = []
for c,i in enumerate(agg):
if i == '0':
node.append(c)
node.append(len(agg))
# 解析出组合
agg_feature_index = []
for c in range(0,len(node)-1,1):
agg_feature_index.append(agg[node[c]:node[c+1]])
# 合并不同路径下的所有相邻结点
# 记录上一个结点的尾巴
last = ['0']
head = ['0']
new_other = ''
for i in other.split('|')[0:-1]:
i = i.split(' ')
if i[0] == last[-1]:
new_other += f'{head[-1],i[0],i[-1]}|'
else:
new_other += f'{i[0],i[-1]}|'
last.append(i[-1])
head.append(i[0])
# 筛选出重复的数据
new_other_len = len(new_other.split('|'))
# 因为有一个 | 。所以要多减去一个自然数
all_other = []
repetition = []
for i in range(new_other_len-2):
f1 = eval(tuple(new_other.split('|'))[i])
f2 = eval(tuple(new_other.split('|'))[i+1])
all_other.append(f1)
if set(f1).issubset(f2) == True:
repetition.append(f1)
all_other.append(eval(tuple(new_other.split('|'))[new_other_len-2]))
# 去掉重复的
final_other = []
for i in range(len(all_other)):
if all_other[i] not in repetition:
final_other.append(all_other[i])
# 组合特征所在下标
for i in final_other:
try:
head_index = agg_feature_index[0].index(i[0])
result = agg_feature_index[0][:head_index+1]
for j in i[1:]:
result.append(j)
except:
head_index = agg_feature_index[1].index(i[0])
result = agg_feature_index[1][:head_index+1]
for j in i[1:]:
result.append(j)
finally:
agg_feature_index.append(result)
# 找出下标对应的特征
feature_index = []
for i in agg_feature_index:
if i[:-1] in feature_index:
continue
else:
feature_index.append(i[:-1])
# 组合特征,结果输出
feature = {}
for c,i in enumerate(feature_index):
f = []
for j in i:
for k in re.findall('\[.*\]',node_dict.get(j)):
if len(k.split('\\n')[0].split('[')) == 3:
# 取出对应下标
fn = int(k.split('\\n')[0].replace('[label="','').split('<=')[0].strip().replace('X[','').replace(']',''))
# 取出对应特征名称
f.append(new_x.columns.tolist()[fn])
feature[f'feature_{c+1}'] = f
print(feature)
# 最终输出从根结点到叶子结点的四种特征组合
'''
{'feature_1': ['交易总金额_入向交易笔数', '交易笔数_入向交易笔数', '入向交易笔数_交易总天数'], 'feature_2': ['交易总金额_入向交易笔数', '交易总金额_出向交易笔数', '交易笔数_交易总天数'], 'feature_3': ['交易总金额_入向交易笔数', '交易笔数_入向交易笔数', '出向交易笔数_交易总天数'], 'feature_4': ['交易总金额_入向交易笔数', '交易总金额_出向交易笔数', '交易笔数_入向交易笔数']}
'''
三、总结
以上只不过是在做需求时想到的一些办法,具体效果不敢保证,只能说是提供一种特征组合的思想。但是具体得到那n个特征后,是加?是减?就不能确定了。

















 3489
3489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









