







本次所讲的内容为Batch Normalization,简称BN,来源于《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》,是一篇很好的paper。
1-Motivation
作者认为:网络训练过程中参数不断改变导致后续每一层输入的分布也发生变化,而学习的过程又要使每一层适应输入的分布,因此我们不得不降低学习率、小心地初始化。作者将分布发生变化称之为 internal covariate shift。
大家应该都知道,我们一般在训练网络的时会将输入减去均值,还有些人甚至会对输入做白化等操作,目的是为了加快训练。为什么减均值、白化可以加快训练呢,这里做一个简单地说明:
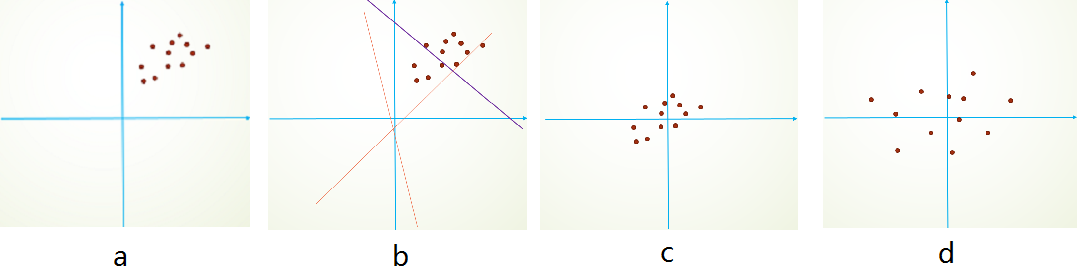
首先,图像数据是高度相关的,假设其分布如下图a所示(简化为2维)。由于初始化的时候,我们的参数一般都是0均值的,因此开始的拟合y=Wx+b,基本过原点附近,如图b红色虚线。因此,网络需要经过多次学习才能逐步达到如紫色实线的拟合,即收敛的比较慢。如果我们对输入数据先作减均值操作,如图c,显然可以加快学习。更进一步的,我们对数据再进行去相关操作,使得数据更加容易区分,这样又会加快训练,如图d。
白化的方式有好几种,常用的有PCA白化:即对数据进行PCA操作之后,在进行方差归一化。这样数据基本满足0均值、单位方差、弱相关性。作者首先考虑,对每一层数据都使用白化操作,但分析认为这是不可取的。因为白化需要计算协方差矩阵、求逆等操作,计算量很大,此外,反向传播时,白化操作不一定可导。于是,作者采用下面的Normalization方法。
2-Normalization via Mini-Batch Statistics
数据归一化方法很简单,就是要让数据具有0均值和单位方差,如下式:
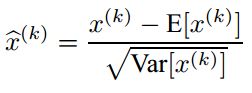
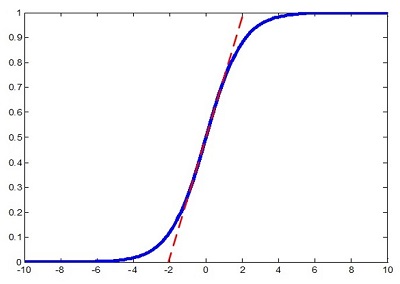
但是作者又说如果简单的这么干,会降低层的表达能力。比如下图,在使用sigmoid激活函数的时候,如果把数据限制到0均值单位方差,那么相当于只使用了激活函数中近似线性的部分,这显然会降低模型表达能力。
为此,作者又为BN增加了2个参数,用来保持模型的表达能力。
于是最后的输出为:
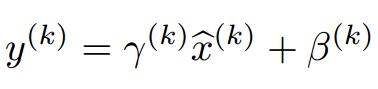
上述公式中用到了均值E和方差Var,需要注意的是理想情况下E和Var应该是针对整个数据集的,但显然这是不现实的。因此,作者做了简化,用一个Batch的均值和方差作为对整个数据集均值和方差的估计。
整个BN的算法如下:

求导的过程也非常简单,有兴趣地可以自己再推导一遍或者直接参见原文。
测试
实际测试网络的时候,我们依然会应用下面的式子:
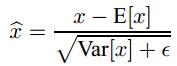
特别注意: 这里的均值和方差已经不是针对某一个Batch了,而是针对整个数据集而言。因此,在训练过程中除了正常的前向传播和反向求导之外,我们还要记录每一个Batch的均值和方差,以便训练完成之后按照下式计算整体的均值和方差:
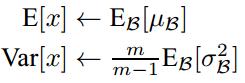
BN before or after Activation
作者在文章中说应该把BN放在激活函数之前,这是因为Wx+b具有更加一致和非稀疏的分布。但是也有人做实验表明放在激活函数后面效果更好。这是实验链接,里面有很多有意思的对比实验:https://github.com/ducha-aiki/caffenet-benchmark
3-Experiments
作者在文章中也做了很多实验对比,我这里就简单说明2个。
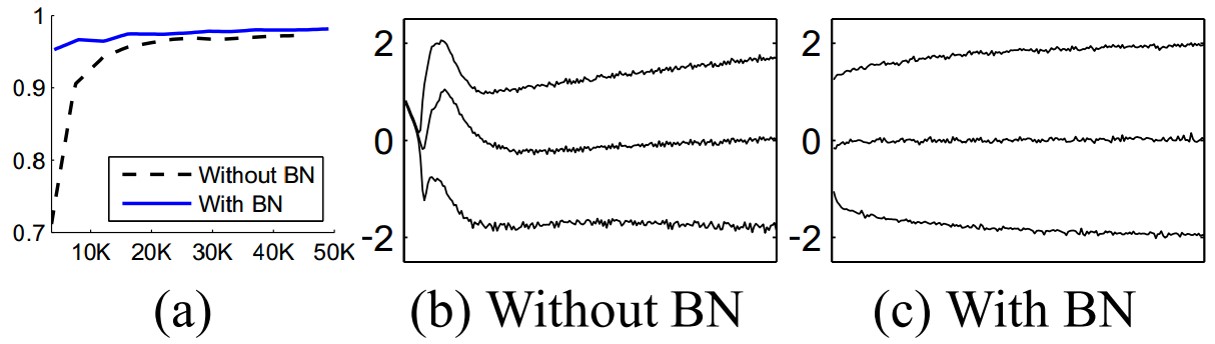
下图a说明,BN可以加速训练。图b和c则分别展示了训练过程中输入数据分布的变化情况。
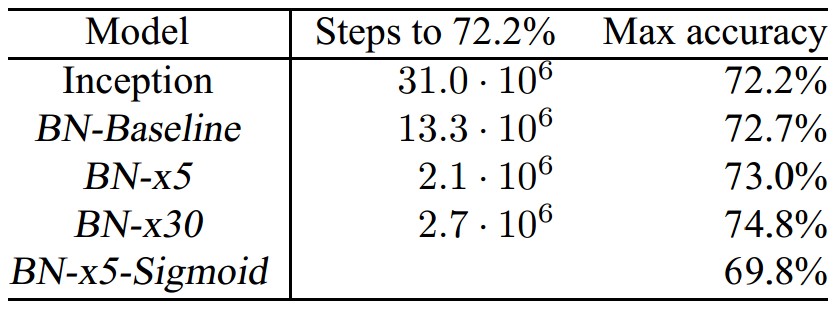
下表是一个实验结果的对比,需要注意的是在使用BN的过程中,作者发现Sigmoid激活函数比Relu效果要好。
3、实战使用
(1)可能学完了上面的算法,你只是知道它的一个训练过程,一个网络一旦训练完了,就没有了min-batch这个概念了。测试阶段我们一般只输入一个测试样本,看看结果而已。因此测试样本,前向传导的时候,上面的均值u、标准差σ 要哪里来?其实网络一旦训练完毕,参数都是固定的,这个时候即使是每批训练样本进入网络,那么BN层计算的均值u、和标准差都是固定不变的。我们可以采用这些数值来作为测试样本所需要的均值、标准差,于是最后测试阶段的u和σ 计算公式如下:
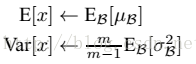
上面简单理解就是:对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:
(2)根据文献说,BN可以应用于一个神经网络的任何神经元上。文献主要是把BN变换,置于网络激活函数层的前面。在没有采用BN的时候,激活函数层是这样的:
z=g(Wu+b)
也就是我们希望一个激活函数,比如s型函数s(x)的自变量x是经过BN处理后的结果。因此前向传导的计算公式就应该是:
z=g(BN(Wu+b))
其实因为偏置参数b经过BN层后其实是没有用的,最后也会被均值归一化,当然BN层后面还有个β参数作为偏置项,所以b这个参数就可以不用了。因此最后把BN层+激活函数层就变成了:
z=g(BN(Wu))
四、Batch Normalization在CNN中的使用
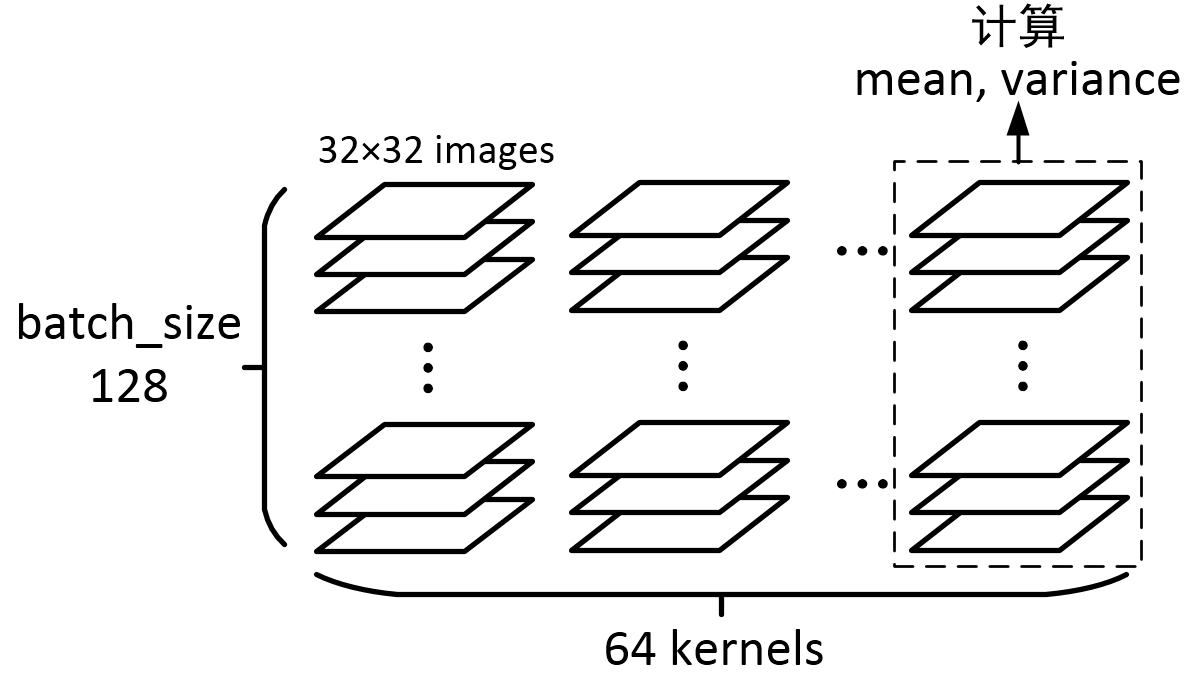
通过上面的学习,我们知道BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上要怎么搞?假如某一层卷积层有6个特征图,每个特征图的大小是100*100,这样就相当于这一层网络有6*100*100个神经元,如果采用BN,就会有6*100*100个参数γ、β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为特征图个数,p、q分别为特征图的宽高。在cnn中我们可以把每个特征图看成是一个特征处理(一个神经元),因此在使用Batch Normalization,mini-batch size 的大小就是:m*p*q,于是对于每个特征图都只有一对可学习参数:γ、β。说白了吧,这就是相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个特征图神经元做归一化。
转载自:http://blog.csdn.net/elaine_bao/article/details/50890491
http://blog.csdn.net/hjimce/article/details/50866313















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









