







多标签学习算法分为量大类:
1)改造数据适应算法
2)改造算法适应数据
1 改造数据
(1)二分类
用L个分类器,分别对应L个标签,进行训练。
(2)标签排序+二分类
利用“成对比较”(pairwise comparison),获得L(L-1)/2个分类器,然后利用投票,得到标签的排序。接着,利用二分类,补充标签排序的投票结果,提高准确性。
(3)随机k标签
从L个标签随机取得k个标签,重复n次,获得n个分类器。这个过程有点类似随机森林。然后利用多类分类器(multi-class,与multi-label是有区别的),训练数据,最后通过投票,如果对于某一标签,其实际获得的投票数占到最大可能的投票数一半以上,那么就认为当前实例属于该标签。
实验中,通常k设为3,n设为2L。
举个例子:
【数据集】
x1, (l1,l2,l3)
x2, (l1,l2)
x3, (l2,l4)
当前数据集,总共标签数为4个,那么所有标签组合为24=16。将((l1,l2,l3))转为新类l1’,(l1,l2)转为一个新类l2’,(l2,l4)转为一个新类l3’,得到3个新类,这样就能利用多类分类器训练转换后的数据集。
2 改造算法
(1)ML-knn
机器学习-k最近邻
首先,利用knn获得未知实例x的k个近邻。针对标签j,在该k个近邻中出现cj次。
其次,利用条件概率,判断x赋予标签j的可能性。假设hj表示x属于标签j事件,¬hj表示x不属于标签j事件。那么假定x要属于标签j,需要满足:
P(hj|cj)/P(¬hj|cj)>1




(2)RankSVM
用wj和wk分别代表标签j和k的权重,按照类似排序的算法,在标签中,以相关或不相关作为判断。假定实例x与标签j相关,与标签k不相关,那就会转换成新的标签1;反之,就会转换成新的标签-1。


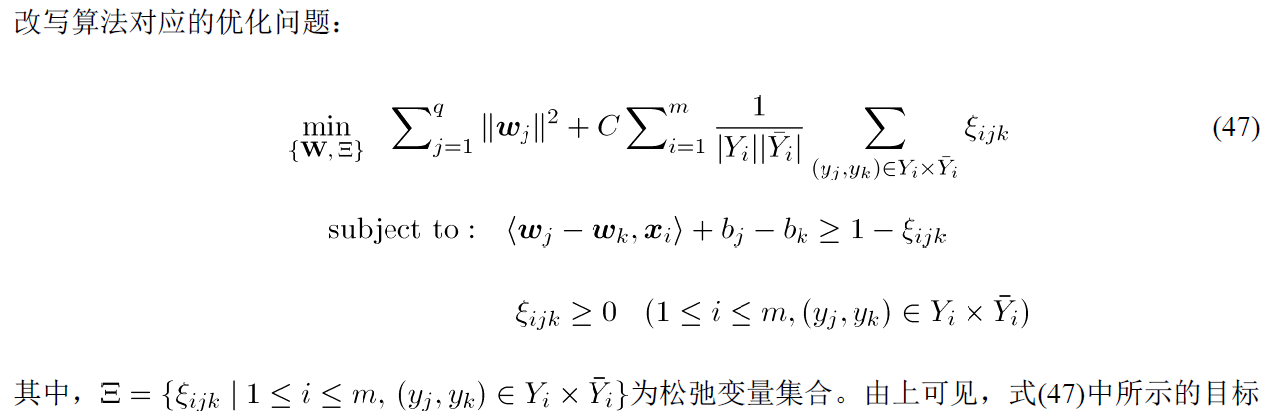

3 评价指标
目前并不存在适用于所有问题的“通用的(general-purpose)”多标记评价指标,其选择依赖于具体的学习任务。例如,对于“分类(classification)”任务而言,采用基于样本的评价指标如hamming loss可能比较合适;而对于“检索(retrieval)”任务而言,采用基于类别的评价指标如micro-averaged precision 可能比较合适。
(1)hamming loss
采用预测的标签集合与实际的标签集合按汉明距离的相似度来衡量。汉明距离值越小说明越相似,即hamming loss越小,从而学习系统的性能越好。
(2)micro-averaging

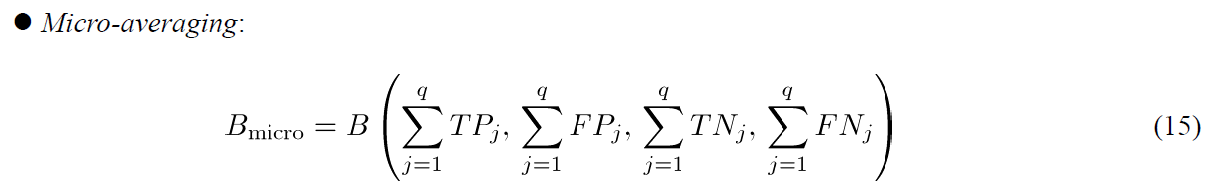
(3)ranking loss
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









