






在这篇关于使用 Python 进行网页抓取的文章中,您将简要了解网页抓取,并通过演示了解如何从网站中提取数据。 我将介绍以下主题:
目录
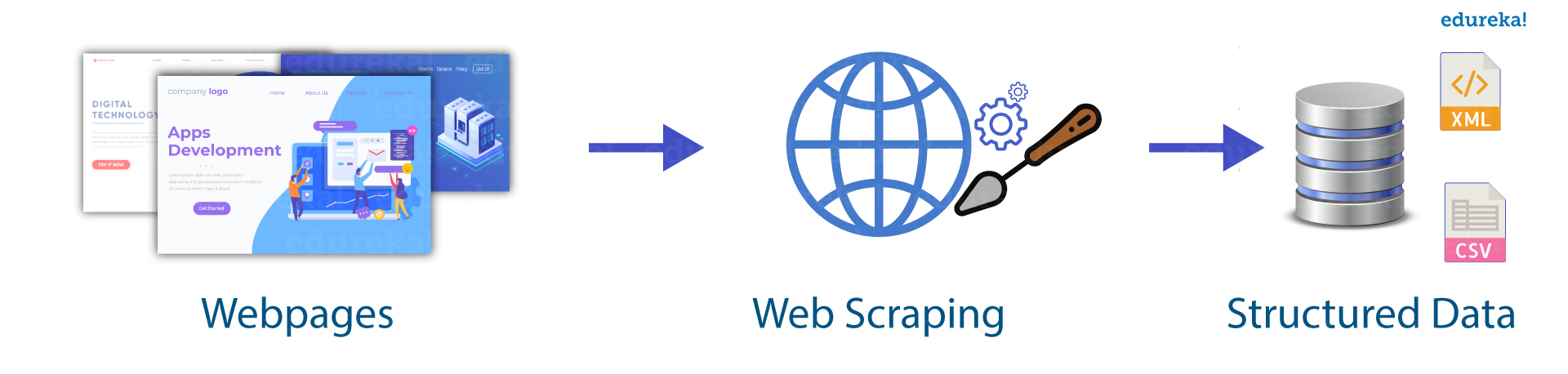
什么是网页抓取?
网页抓取是一种用于从网站中提取大量数据的自动化方法。网站上的数据是非结构化的。网页抓取有助于收集这些非结构化数据并以结构化形式存储。有不同的方法可以抓取网站,例如在线服务、API 或编写自己的代码。在本文中,我们将了解如何使用 python 实现网页抓取。
为什么使用网页抓取?
网页抓取用于从网站收集大量信息。但是为什么有人必须从网站收集如此大的数据呢?要了解这一点,let看看网页抓取的应用:
- 价格比较:ParseHub等服务使用网络抓取从在线购物网站收集数据,并使用它来比较产品的价格。
- 电子邮件地址收集:许多使用电子邮件作为营销媒介的公司使用网络抓取来收集电子邮件 ID,然后发送批量电子邮件。
- 社交媒体抓取:网络抓取用于从 Twitter 等社交媒体网站收集数据,以了解趋势。
- 研究与开发:网页抓取用于从网站收集大量数据(统计数据、一般信息、温度等),这些数据被分析并用于进行调查或研发。
- 职位列表:有关职位空缺、面试的详细信息从不同的网站收集,然后列在一个地方,以便用户轻松访问。
网页抓取合法吗?
谈到网络抓取是否合法,有些网站允许网络抓取,有些则不允许。要了解网站是否允许网页抓取,您可以查看该网站的“robots.txt”文件。您可以通过将“/robots.txt”附加到要抓取的 URL 来找到此文件。对于这个例子,我正在抓取Flipkart网站。因此,要查看“robots.txt”文件。
为什么 Python 对网页抓取有好处?
这是Python的功能列表,使其更适合网页抓取。
- 易用性:Python编程易于编码。您不必在任何地方添加分号 “;” 或大括号 “{}”。这使得它不那么混乱且易于使用。
- 大量图书馆:Python拥有大量的库,如Numpy,Matlplotlib,Pandas等,它们为各种目的提供了方法和服务。因此,它适用于网络抓取和进一步操作提取的数据。
- 动态类型:在 Python 中,您不必为变量定义数据类型,您可以在需要时直接使用变量。这样可以节省时间并使您的工作更快。
- 易于理解的语法:Python 语法很容易理解,主要是因为阅读 Python 代码与阅读英语语句非常相似。它具有表现力且易于阅读,Python 中使用的缩进还有助于用户区分代码中的不同范围/块。
- 小代码,大任务:网页抓取用于节省时间。但是,如果您花更多时间编写代码,那有什么用呢?好吧,你不必。在 Python 中,你可以编写小代码来执行大任务。因此,即使在编写代码时也可以节省时间。
- 社区:如果在编写代码时遇到困难怎么办?你不必担心。Python 社区拥有最大、最活跃的社区之一,您可以在其中寻求帮助
如何从网站抓取数据?
当您运行网络抓取代码时,请求将发送到您提到的 URL。作为对请求的响应,服务器发送数据并允许您读取 HTML 或 XML 页面。然后,代码解析 HTML 或 XML 页面,查找数据并将其提取。
要使用python进行网络抓取来提取数据,您需要遵循以下基本步骤:
- 找到您要抓取的网址
- 检查页面
- 查找要提取的数据
- 编写代码
- 运行代码并提取数据
- 以所需格式存储数据
现在让我们看看如何使用Python从Flipkart网站中提取数据。

用于网页抓取的库
众所周知,Python具有各种应用程序,并且有不同的库用于不同的目的。在我们的进一步演示中,我们将使用以下库:
- Selenium:Selenium是一个Web测试库。它用于自动化浏览器活动。
- BeautifulSoup:Beautiful Soup是一个用于解析HTML和XML文档的Python包。它创建有助于轻松提取数据的解析树。
- 熊猫:熊猫是一个用于数据操作和分析的库。它用于提取数据并以所需的格式存储。
网页抓取示例:抓取 Flipkart 网站
先决条件:
- Python 2.x 或 Python 3.x 安装了 Selenium、BeautifulSoup、pandas 库
- 谷歌浏览器
- 乌班图操作系统
让我们开始吧!
步骤1:找到您要抓取的网址
对于此示例,我们将抓取 Flipkart 网站以提取笔记本电脑的价格、名称和评级。此页面的网址为 Buyback Guarantee On Laptops - Buy Buyback Guarantee On Laptops Online at Low Prices In India | Flipkart.com
步骤 2:检查页面
数据通常嵌套在标签中。因此,我们检查页面以查看我们要抓取的数据嵌套在哪个标签下。要检查页面,只需右键单击该元素,然后单击“检查”。
当您单击“检查”选项卡时,您将看到打开的“浏览器检查器框”。

步骤3:查找要提取的数据
分别提取“div”标签中的价格、名称和评级
步骤4:编写代码
首先,让我们创建一个 Python 文件。为此,请在 Ubuntu 中打开终端并键入 gedit<您的文件名>,扩展名 为.py。
我要 将文件命名为“web-s”。这是命令:
| 1 |
|
现在,让我们在此文件中编写代码。
首先,让我们导入所有必要的库:
| 1 2 3 |
|
要将 网络驱动程序配置为使用 Chrome 浏览器,我们必须将路径设置为 chromedriver
| 1 |
|
请参阅以下代码以打开 URL:
| 1 2 3 4 |
|
现在我们已经编写了打开 URL 的代码,是时候从网站中提取数据了。如前所述,我们要提取的数据嵌套 在 <div> 标签中。因此,我将找到带有这些相应类名的 div 标签,提取数据并将数据存储 请参阅以下代码:
| 1 2 3 4 5 6 7 8 9 |
|
步骤 5:运行代码并提取数据
若要运行代码,请使用以下命令:
| 1 |
|
步骤 6:以所需格式存储数据
提取数据后,您可能希望将其存储为某种格式。此格式因您的要求而异。对于此示例,我们将以 CSV(逗号分隔值)格式存储提取的数据。为此,我将在代码中添加以下行:
| 1 2 |
|
再次运行整个代码。
创建文件名“products.csv”,此文件包含提取的数据。
















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











