









认识CPU Cache
CPU Cache概述
随着CPU的频率不断提升,而内存的访问速度却没有质的突破,为了弥补访问内存的速度慢,充分发挥CPU的计算资源,提高CPU整体吞吐量,在CPU与内存之间引入了一级Cache。随着热点数据体积越来越大,一级Cache L1已经不满足发展的要求,引入了二级Cache L2,三级Cache L3。(注:若无特别说明,本文的Cache指CPU Cache,高速缓存)CPU Cache在存储器层次结构中的示意如下图:
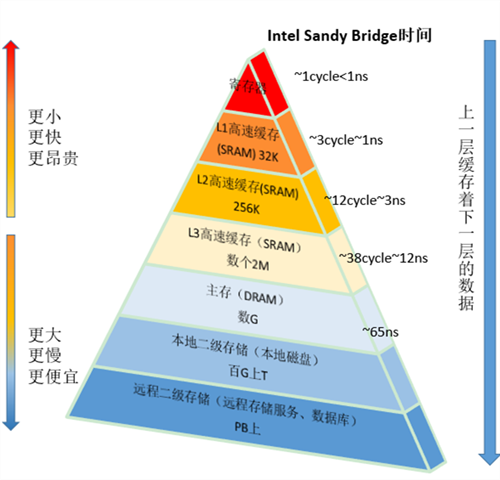
计算机早已进入多核时代,软件也越来越多的支持多核运行。一个处理器对应一个物理插槽,多处理器间通过QPI总线相连。一个处理器包含多个核,一个处理器间的多核共享L3 Cache。一个核包含寄存器、L1 Cache、L2 Cache,下图是Intel Sandy Bridge CPU架构,一个典型的NUMA多处理器结构:
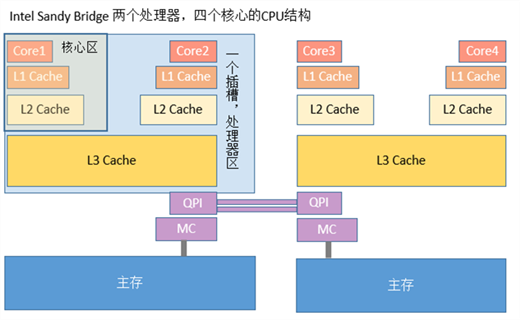
作为程序员,需要理解计算机存储器层次结构,它对应用程序的性能有巨大的影响。如果需要的程序是在CPU寄存器中的,指令执行时1个周期内就能访问到他们。如果在CPU Cache中,需要1~30个周期;如果在主存中,需要50~200个周期;在磁盘上,大概需要几千万个周期。充分利用它的结构和机制,可以有效的提高程序的性能。
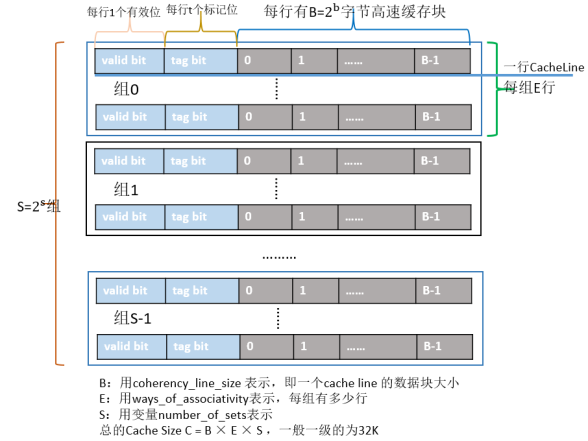
以我们常见的X86芯片为例,Cache的结构下图所示:整个Cache被分为S个组,每个组是又由E行个最小的存储单元——Cache Line所组成,而一个Cache Line中有B(B=64)个字节用来存储数据,即每个Cache Line能存储64个字节的数据,每个Cache Line又额外包含一个有效位(valid bit)、t个标记位(tag bit),其中valid bit用来表示该缓存行是否有效;tag bit用来协助寻址,唯一标识存储在CacheLine中的块;而Cache Line里的64个字节其实是对应内存地址中的数据拷贝。根据Cache的结构题,我们可以推算出每一级Cache的大小为B×E×S。
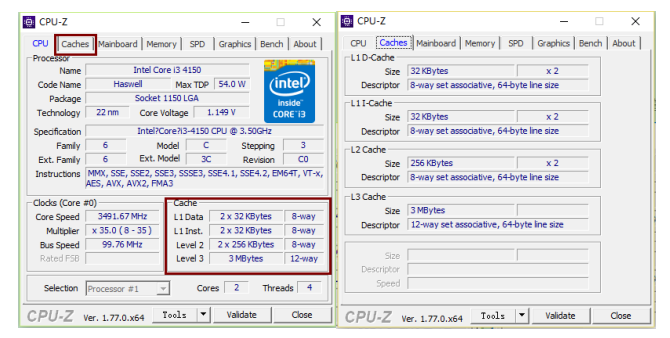
那么如何查看自己电脑CPU的Cache信息呢?
在windows下查看方式有多种方式,其中最直观的是,通过安装CPU-Z软件,直接显示Cache信息,如下图:
此外,Windows下还有两种方法:
①Windows API调用GetLogicalProcessorInfo。
②通过命令行系统内部工具CoreInfo。
如果是Linux系统, 可以使用下面的命令查看Cache信息:
ls /sys/devices/system/cpu/cpu0/cache/index0
还有lscpu等命令也可以查看相关信息,如果是Mac系统,可以用sysctl machdep.cpu 命令查看cpu信息。

如果我们用Java编程,还可以通过CacheSize API方式来获取Cache信息, CacheSize是一个谷歌的小项目,java语言通过它可以进行访问本机Cache的信息。示例代码如下:
public static void main(String[] args) throws CacheNotFoundException {
CacheInfo info = CacheInfo.getInstance();
CacheLevelInfo l1Datainf = info.getCacheInformation(CacheLevel.L1, CacheType.DATA_CACHE);
System.out.println("第一级数据缓存信息:"+l1Datainf.toString());
CacheLevelInfo l1Instrinf = info.getCacheInformation(CacheLevel.L1, CacheType.INSTRUCTION_CACHE);
System.out.println("第一级指令缓存信息:"+l1Instrinf.toString());
}打印输出结果如下:
第一级数据缓存信息:CacheLevelInfo [cacheLevel=L1, cacheType=DATA_CACHE, cacheSets=64, cacheCoherencyLineSize=64, cachePhysicalLinePartitions=1, cacheWaysOfAssociativity=8, isFullyAssociative=false, isSelfInitializing=true, totalSizeInBytes=32768]
第一级指令缓存信息:CacheLevelInfo [cacheLevel=L1, cacheType=INSTRUCTION_CACHE, cacheSets=64, cacheCoherencyLineSize=64, cachePhysicalLinePartitions=1, cacheWaysOfAssociativity=8, isFullyAssociative=false, isSelfInitializing=true, totalSizeInBytes=32768]还可以查询L2、L3级缓存的信息,这里不做示例。从打印的信息和CPU-Z显示的信息可以看出,本机的Cache信息是一致的,L1数据/指令缓存大小都为:C=B×E×S=64×8×64=32768字节=32KB。
Cache Line伪共享及解决方案
Cache Line伪共享分析
说伪共享前,先看看Cache Line 在java编程中使用的场景。如果CPU访问的内存数据不在Cache中(一级、二级、三级),这就产生了Cache Line miss问题,此时CPU不得不发出新的加载指令,从内存中获取数据。通过前面对Cache存储层次的理解,我们知道一旦CPU要从内存中访问数据就会产生一个较大的时延,程序性能显著降低,所谓远水救不了近火。为此我们不得不提高Cache命中率,也就是充分发挥局部性原理。
局部性包括时间局部性、空间局部性。时间局部性:对于同一数据可能被多次使用,自第一次加载到Cache Line后,后面的访问就可以多次从Cache Line中命中,从而提高读取速度(而不是从下层缓存读取)。空间局部性:一个Cache Line有64字节块,我们可以充分利用一次加载64字节的空间,把程序后续会访问的数据,一次性全部加载进来,从而提高Cache Line命中率(而不是重新去寻址读取)。
看个例子:内存地址是连续的数组(利用空间局部性),能一次被L1缓存加载完成。
如下代码,长度为16的row和column数组,在Cache Line 64字节数据块上内存地址是连续的,能被一次加载到Cache Line中,所以在访问数组时,Cache Line命中率高,性能发挥到极致。
public int run(int[] row, int[] column) {
int sum = 0;
for(int i = 0; i < 16; i++ ) {
sum += row[i] * column[i];
}
return sum;
}而上面例子中变量i则体现了时间局部性,i作为计数器被频繁操作,一直存放在寄存器中,每次从寄存器访问,而不是从主存甚至磁盘访问。虽然连续紧凑的内存分配带来高性能,但并不代表它一直都能带来高性能。如果把它放在多线程中将会发生什么呢?如图:
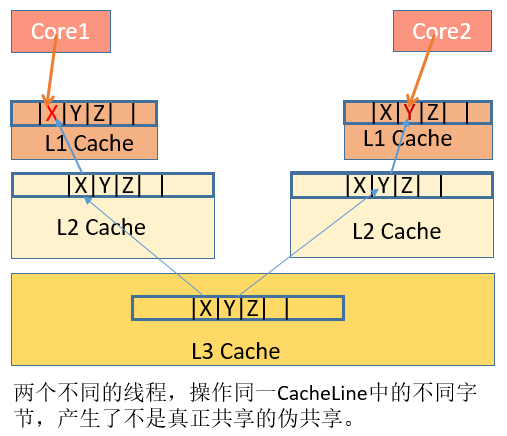
数据X、Y、Z被加载到同一Cache Line中,线程A在Core1修改X,线程B在Core2上修改Y。根据MESI大法,假设是Core1是第一个发起操作的CPU核,Core1上的L1 Cache Line由S(共享)状态变成M(修改,脏数据)状态,然后告知其他的CPU核,图例则是Core2,引用同一地址的Cache Line已经无效了;当Core2发起写操作时,首先导致Core1将X写回主存,Cache Line状态由M变为I(无效),而后才是Core2从主存重新读取该地址内容,Cache Line状态由I变成E(独占),最后进行修改Y操作, Cache Line从E变成M。可见多个线程操作在同一Cache Line上的不同数据,相互竞争同一Cache Line,导致线程彼此牵制影响,变成了串行程序,降低了并发性。此时我们则需要将共享在多线程间的数据进行隔离,使他们不在同一个Cache Line上,从而提升多线程的性能。
Cache Line伪共享处理方案
处理伪共享的两种方式:
- 增大数组元素的间隔使得不同线程存取的元素位于不同的cache line上。典型的空间换时间。(Linux cache机制与之相关)
- 在每个线程中创建全局数组各个元素的本地拷贝,然后结束后再写回全局数组。
在Java类中,最优化的设计是考虑清楚哪些变量是不变的,哪些是经常变化的,哪些变化是完全相互独立的,哪些属性一起变化。举个例子:
public class Data{
long modifyTime;
boolean flag;
long createTime;
char key;
int value;
}假如业务场景中,上述的类满足以下几个特点:
- 当value变量改变时,modifyTime肯定会改变
- createTime变量和key变量在创建后,就不会再变化。
- flag也经常会变化,不过与modifyTime和value变量毫无关联。
当上面的对象需要由多个线程同时的访问时,从Cache角度来说,就会有一些有趣的问题。当我们没有加任何措施时,Data对象所有的变量极有可能被加载在L1缓存的一行Cache Line中。在高并发访问下,会出现这种问题:
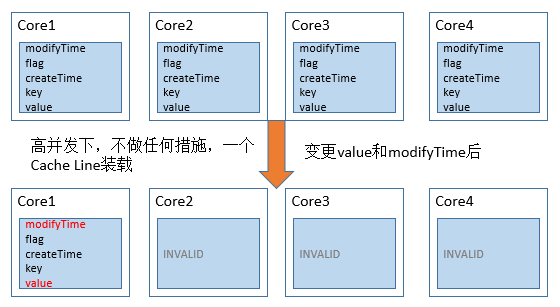
如上图所示,每次value变更时,根据MESI协议,对象其他CPU上相关的Cache Line全部被设置为失效。其他的处理器想要访问未变化的数据(key 和 createTime)时,必须从内存中重新拉取数据,增大了数据访问的开销。
Padding 方式
正确的方式应该将该对象属性分组,将一起变化的放在一组,与其他属性无关的属性放到一组,将不变的属性放到一组。这样当每次对象变化时,不会带动所有的属性重新加载缓存,提升了读取效率。在JDK1.8以前,我们一般是在属性间增加长整型变量来分隔每一组属性。被操作的每一组属性占的字节数加上前后填充属性所占的字节数,不小于一个cache line的字节数就可以达到要求:
public class DataPadding{
long a1,a2,a3,a4,a5,a6,a7,a8;//防止与前一个对象产生伪共享
int value;
long modifyTime;
long b1,b2,b3,b4,b5,b6,b7,b8;//防止不相关变量伪共享;
boolean flag;
long c1,c2,c3,c4,c5,c6,c7,c8;//
long createTime;
char key;
long d1,d2,d3,d4,d5,d6,d7,d8;//防止与下一个对象产生伪共享
}通过填充变量,使不相关的变量分开
Contended注解方式
在JDK1.8中,新增了一种注解@sun.misc.Contended,来使各个变量在Cache line中分隔开。注意,jvm需要添加参数-XX:-RestrictContended才能开启此功能
用时,可以在类前或属性前加上此注释:
// 类前加上代表整个类的每个变量都会在单独的cache line中
@sun.misc.Contended
@SuppressWarnings("restriction")
public class ContendedData {
int value;
long modifyTime;
boolean flag;
long createTime;
char key;
}
或者这种:
// 属性前加上时需要加上组标签
@SuppressWarnings("restriction")
public class ContendedGroupData {
@sun.misc.Contended("group1")
int value;
@sun.misc.Contended("group1")
long modifyTime;
@sun.misc.Contended("group2")
boolean flag;
@sun.misc.Contended("group3")
long createTime;
@sun.misc.Contended("group3")
char key;
}采取上述措施图示:
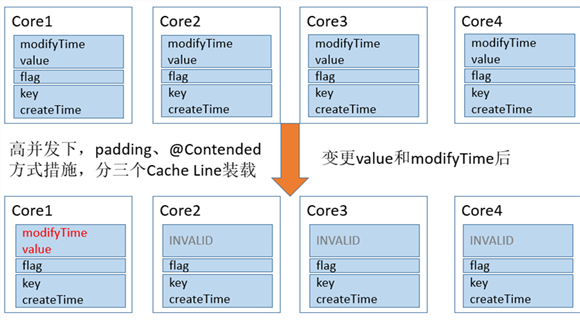
JDK1.8 ConcurrentHashMap的处理
java.util.concurrent.ConcurrentHashMap在这个如雷贯耳的Map中,有一个很基本的操作问题,在并发条件下进行++操作。因为++这个操作并不是原子的,而且在连续的Atomic中,很容易产生伪共享(false sharing)。所以在其内部有专门的数据结构来保存long型的数据:
(openjdk\jdk\src\share\classes\java\util\concurrent\ConcurrentHashMap.java line:2506):
/* ---------------- Counter support -------------- */
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}我们看到该类中,是通过@sun.misc.Contended达到防止false sharing的目的
JDK1.8 Thread 的处理
java.lang.Thread在java中,生成随机数是和线程有着关联。而且在很多情况下,多线程下产生随机数的操作是很常见的,JDK为了确保产生随机数的操作不会产生false sharing ,把产生随机数的三个相关值设为独占cache line。
(openjdk\jdk\src\share\classes\java\lang\Thread.java line:2023)
// The following three initially uninitialized fields are exclusively
// managed by class java.util.concurrent.ThreadLocalRandom. These
// fields are used to build the high-performance PRNGs in the
// concurrent code, and we can not risk accidental false sharing.
// Hence, the fields are isolated with @Contended.
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;Java中对Cache line经典设计
Disruptor框架
认识Disruptor
LMAX是在英国注册并受到FCA监管的外汇黄金交易所。也是欧洲第一家也是唯一一家采用多边交易设施Multilateral Trading Facility(MTF)拥有交易所牌照和经纪商牌照的欧洲顶级金融公司。LMAX的零售金融交易平台,是建立在JVM平台上,核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单。业务逻辑处理器的核心就是Disruptor(注,本文Disruptor基于当前最新3.3.6版本),这是一个Java实现的并发组件,能够在无锁的情况下实现网络的Queue并发操作,它确保任何数据只由一个线程拥有以进行写访问,从而消除写争用的设计, 这种设计被称作“破坏者”,也是这样命名这个框架的。
Disruptor是一个线程内通信框架,用于线程里共享数据。与LinkedBlockingQueue类似,提供了一个高速的生产者消费者模型,广泛用于批量IO读写,在硬盘读写相关的程序中应用的十分广泛,Apache旗下的HBase、Hive、Storm等框架都有在使用Disruptor。LMAX 创建Disruptor作为可靠消息架构的一部分,并将它设计成一种在不同组件中共享数据非常快的方法。Disruptor运行大致流程入下图:
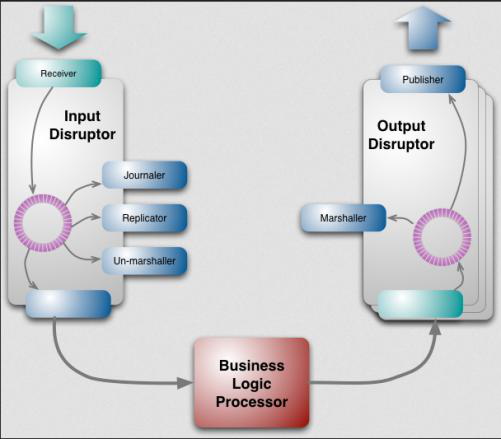
图中左侧(Input Disruptor部分)可以看作多生产者单消费者模式。外部多个线程作为多生产者并发请求业务逻辑处理器(Business Logic Processor),这些请求的信息经过Receiver存放在粉红色的圆环中,业务处理器则作为消费者从圆环中取得数据进行处理。右侧(Output Disruptor部分)则可看作单生产者多消费者模式。业务逻辑处理器作为单生产者,发布数据到粉红色圆环中,Publisher作为多个消费者接受业务逻辑处理器的结果。这里两处地方的数据共享都是通过那个粉红色的圆环,它就是Disruptor的核心设计RingBuffer。
Disruptor特点
- 无锁机制。
- 没有CAS操作,避免了内存屏障指令的耗时。
- 避开了Cache line伪共享的问题,也是Disruptor部分主要关注的主题。
Disruptor对伪共享的处理
RingBuffer类
RingBuffer类(即上节中粉红色的圆环)的类关系图如下:
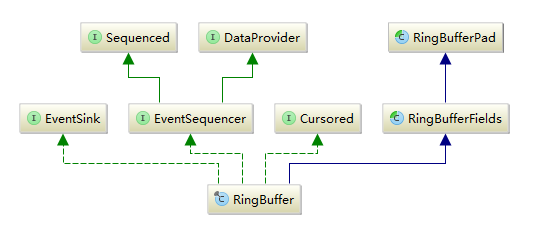
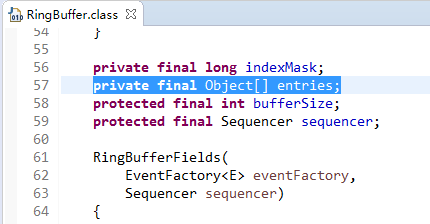
通过源码分析,RingBuffer的父类,RingBufferFields采用数组来实现存放线程间的共享数据。下图,第57行,entries数组。
前面分析过数组比链表、树更具有缓存友好性,此处不做细表。不使用LinkedBlockingQueue队列,是基于无锁机制的考虑。详细分析可参考,并发编程网的翻译。这里我们主要分析RingBuffer的继承关系中的填充,解决缓存伪共享问题。如下图:
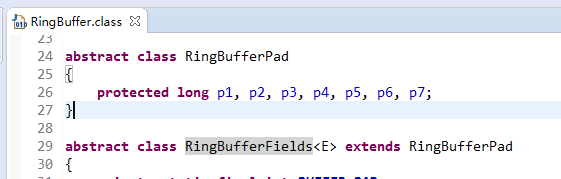
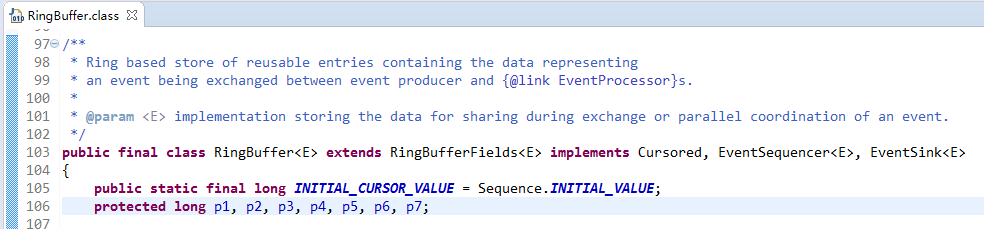
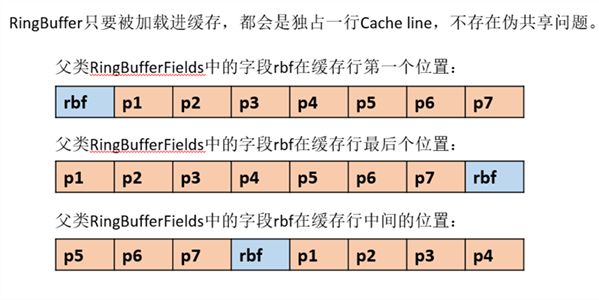
依据JVM对象继承关系中父类属性与子类属性,内存地址连续排列布局,RingBufferPad的protected long p1,p2,p3,p4,p5,p6,p7;作为缓存前置填充,RingBuffer中的protected long p1,p2,p3,p4,p5,p6,p7;作为缓存后置填充。这样任意线程访问RingBuffer时,RingBuffer放在父类RingBufferFields的属性,都是独占一行Cache line不会产生伪共享问题。如图,RingBuffer的操作字段在RingBufferFields中,使用rbf标识:
按照一行缓存64字节计算,前后填充56字节(7个long),中间大于等于8字节的内容都能独占一行Cache line,此处rbf是大于8字节的。
Sequence类
Sequence类用来跟踪RingBuffer和事件处理器的增长步数,支持多个并发操作包括CAS指令和写指令。同时使用了Padding方式来实现,如下为其类结构图及Padding的类。
Sequence里在volatile long value前后放置了7个long padding,来解决伪共享的问题。示意如图,此处Value等于8字节:
也许读者应该会认为这里的图示比上面RingBuffer的图示更好理解,这里的操作属性只有一个value,两个图相互结合就更能理解了。
Sequencer的实现
在RingBuffer构造函数里面存在一个Sequencer接口,用来遍历数据,在生产者和消费者之间传递数据。Sequencer有两个实现类,单生产者模式的实现SingleProducerSequencer与多生产者模式的实现MultiProducerSequencer。它们的类结构如图:
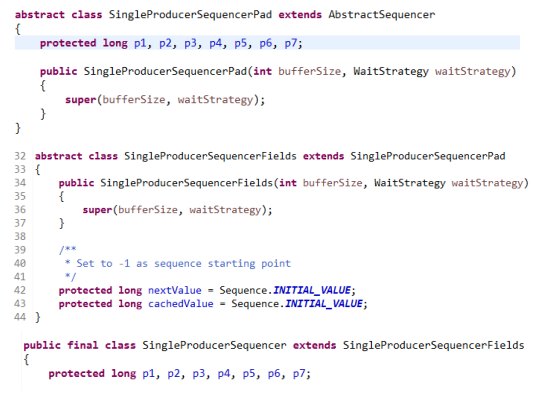
单生产者是在Cache line中使用padding方式实现,源码如下:
多生产者则是使用 sun.misc.Unsafe来实现的。如下图:

总结与使用示例
可见padding方式在Disruptor中是处理伪共享常见的方式,JDK1.8的@Contended很好的解决了这个问题,不知道Disruptor后面的版本是否会考虑使用它。
Disruptor使用示例代码参考地址。
参考资料:
7个示例科普CPU Cache:http://coolshell.cn/articles/10249.html
Linux Cache 机制:http://www.cnblogs.com/liloke/archive/2011/11/20/2255737.html
《深入理解计算机系统》:第六章部分
Disruptor官方文档:https://github.com/LMAX-Exchange/disruptor/tree/master/docs
Disruptor并发编程网文档翻译:http://ifeve.com/disruptor/
作者简介:
上海-周卫理、北京-杨珍琪、北京-冯英圣、深圳-姜寄羽 倾力合作,另外感谢惠普系统架构师吴治辉策划支持。
周卫理:本科,从事Java开发7年,热爱研究术问题,喜欢运动。目前就职于上海一家互联网公司,担任Java后端小组组长,负责分布式系统框架搭建。正往Java高性能编程,大数据中间件方向靠拢。
冯英胜:长期从事Java软件开发工作,善于复杂业务开发,6年工作经验,对大数据平台和分布式架构等有浓厚兴趣。目前就职于北京当当网。
姜寄羽:四川大学软件工程学士。目前在深圳亚略特担任Java工程师一职。负责Java方面的开发和维护以及新技术预研,对软件工程、分布式系统和高性能编程有着深厚的理论基础。
杨珍琪:硕士,会计学士,前HP工程师,参与中国移动BOSS系统开发,现为创业公司CTO。
转载请注明:冯英胜的博客 » Java专家系列:CPU Cache与高性能编程















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









