





一、基础
设X是一串已经观察的听觉特征向量,W表示一个词序列。那么最可能的词序列就是W*:
贝叶斯准则
其中P(X|W)是声学模型,P(W)是语言模型。
Lexicon是字典。HMM模型就是一种声学模型。
‘下面举个例子:
“NO right”分为两个词,每个词又分为几个音素。对于每个音素跑HMM模型。
HMM模型如下:
参数 入 :
转移概率是akj,表示从sk状态转移到sj状态的概率。
输出概率密度函数bj(x)表示,在隐藏状态的sj的情况下,观测值是x的概率。
当然也可能一个状态对应的观测值有很多。
统计独立性:一个观测状态x是与生成他的状态的其他观测值独立(简称,不同时间的观测值相互独立)
马尔科夫过程:一个状态和它以前的状态统计独立。
一元高斯函数,如第一个,有协方差矩阵和均值向量。
上图给出矢量高斯函数。P是维数
通常实际应用中,一元的高斯函数是不够的需要很多元。比如M=8以上。
高斯分布的具体指示不在介绍。
下面具体说明一下对于均值向量和协方差矩阵的估计。
我们一般使用已知的n个X的值进行估计。
下面我们求最大似然估计:
解得这两种估计确实是最大似然估计。
概率密度函数由方差和均值确定,注意
是一个二次型。
训练序列可以对参数进行估计,估计值:
二、聚类算法
k-means是一个自动对无标签数据进行聚类的算法。
保证收敛,结果与初始化的设置有关。
对上图进行聚类。
选初始化3个点。
第一次聚类 并找到中心。
再聚类 继续找中心。直到下图收敛。
更复杂的情况是,一个M维的高斯分布是M个函数的线性组合。
P(j)是参数,p(x|j)相当于第J个的高斯分布PDF。
我们可以根据贝叶斯公式:
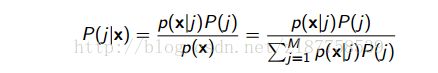
p(x|j)表示在已知观察序列的情况下是第J个高斯函数产生的观察序列的概率。
而且。
如果我们知道是哪个混合高斯元,产生的观察值X
那么我们可以分配每个每一个点给对应的混合高斯元
而且我们可以估计均值(比如用K-MEANS聚类算法)
然后在计算协方差。
但我们还不知道,观测数据点来自哪个混合高斯元,因此我们要用上面的概率进行计算。
===============================================================================
三、GMM
通常的混合模型是高斯混合模型:也就是说p(x|j)是高斯函数。
假设一个GMM模型,每个N(x;uj;oj2),都有

那么产生x的概率是等于每个高斯元产生的概率乘以相应的高斯函数概率值的和。
。
设置一个变量zjn。如果j产生了xn那么为1,否则为0.
如果zjn不是隐藏的那么我们可以计算出j状态可以产生多少个xn观测点:
并且估测他们的均值:
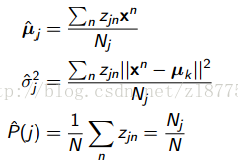
但是我们不知道这些,所以没用。
当我们不知道X是由哪个状态J产生的时候,还有软分配:

就是说对各数进行概率的加权分配而不是只有0,1的分配。
问题又回到了P(j|X)是如何得到的呢。
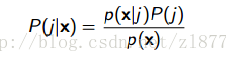
我们需要p(x|j)和P(j)去估计p(x|j)和P(j)的参数。
因此我们就需要用一个迭代算法(E-M算法):
E-step:计算P(j|x)用当前的GMM参数(均值,方差,p(j))
M-step:计算参数用刚才E步求的P(j|x)
开始 利用如k-means算法进行初始化,然后这样迭代知道收敛。
EM算法也可以用最大似然表示。

让产生观察序列的概率最大,进而估计这些参数。就是训练,意思就是通过已知的观察序列,进而求得参数 如均值和协方差还有权值。
四。HMM
回到HMM
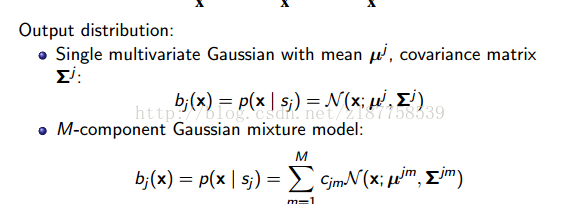
使用HMM有三个问题。
1.计算产生X序列的全部概率。
2.识别,就是给定一个HMM和观察变量(如MFCC提取后的序列)选出最大可能的隐含状态。
3.训练,给定一组观察序列,和HMM,求出最佳的HMM参数。
1.概率:前向算法。
目标是:求出P(X|入)
计算所有的可能导致X的状态序列。S1S2S3...ST
不是枚举所有序列而是递归的计算概率















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









