







 本文介绍了GMM-HMM在语音识别中的应用,包括HMM的基本概念、GMM的原理以及如何利用GMM和HMM进行语音识别。内容涵盖HMM的似然性、解码和训练问题,GMM的混合高斯模型解释,以及GMM-HMM在识别和训练过程中的详细步骤。
本文介绍了GMM-HMM在语音识别中的应用,包括HMM的基本概念、GMM的原理以及如何利用GMM和HMM进行语音识别。内容涵盖HMM的似然性、解码和训练问题,GMM的混合高斯模型解释,以及GMM-HMM在识别和训练过程中的详细步骤。
本文简明讲述GMM-HMM在语音识别上的原理,建模和测试过程。这篇blog只回答三个问题:
1. 什么是Hidden Markov Model?
HMM要解决的三个问题:
1) Likelihood
2) Decoding
3) Training
2. GMM是神马?怎样用GMM求某一音素(phoneme)的概率?
3. GMM+HMM大法解决语音识别
3.1 识别
3.2 训练
3.2.1 Training the params of GMM
3.2.2 Training the params of HMM
首先声明我是做视觉的不是做语音的,迫于**需要24小时速成语音。上网查GMM-HMM资料中文几乎为零,英文也大多是paper。苦苦追寻终于貌似搞懂了GMM-HMM,感谢语音组老夏(http://weibo.com/ibillxia)提供资料给予指导。本文结合最简明的概括还有自己一些理解应运而生,如有错误望批评指正。
====================================================================
1. 什么是Hidden Markov Model?
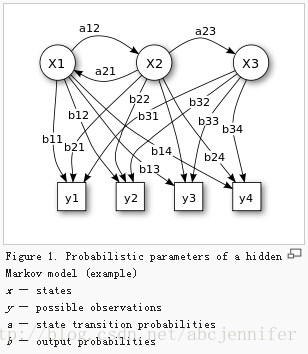
ANS:一个有隐节点(unobservable)和可见节点(visible)的马尔科夫过程(见详解)。
隐节点表示状态,可见节点表示我们听到的语音或者看到的时序信号。
最开始时,我们指定这个HMM的结构,训练HMM模型时:给定n个时序信号y1...yT(训练样本), 用MLE(typically implemented in EM) 估计参数:
1. N个状态的初始概率
2. 状态转移概率a
3. 输出概率b
--------------
- 在语音处理中,一个word由若干phoneme(音素)组成;
- 每个HMM对应于一个word或者音素(phoneme)
- 一个word表示成若干states,每个state表示为一个音素
用HMM需要解决3个问题:
1). Likelihood: 一个HMM生成一串observation序列x的概率< the Forward algorithm>

其中,αt(sj)表示HMM在时刻t处于状态j,且observation = {x1,...,xt}的概率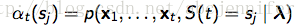
aij是状态i到状态j的转移概率,
bj(xt)表示在状态j的时候生成xt的概率,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









